
外观
Python
这里介绍的知识是我当时学习的时候,书中讲授的全部知识。我觉得每一位 Python 学习者都应掌握这些基础的知识,否则你就不是真正了解这门强大的语言。
这里介绍的都是我觉得很重要的基础知识。每一位使用 Python 的开发者都知道,Python 的生态系统很强大,优秀的库也不尽其数。如果你想了解更多我认为实用的 Python 库,可以查看本站关于 Python 的剩余部分的笔记,也可以前往我的【常用库使用指南】,那里收藏着本人觉得实用的库列表,每一个都有详细的介绍和演示。
基本数据类型
数字
整数 int
- 进制表示:
- 十进制10
- 十六进制0x10
- 八进制0o10
- 二进制0b10
- bool 类型,有2个值 True、False
- 进制表示:
浮点数 float
- 1.2、3.1415、-0.12、1.46e9等价于科学计数法1.46*109
复数 complex
- 1+2j 或 +2J
字符串
- 使用‘ ”单双引号引用的字符的序列
- '''和""" 单双三引号,可以跨行、可以在其中自由的使用单双引号
- r 前缀:在字符串前面加上 r 或者 R 前缀,表示该字符串不做特殊的处理
- f 前缀:3.6版本开始,新增 f 前缀,格式化字符串
转义序列
\\\t\r\n\'\"- 上面每一个转义字符只代表一个字符,例如
\t显示时占了4个字符位置,但是它是一个字符 - 前缀 r,把里面的所有字符当普通字符对待,则转义字符就不转义了
转义:让字符不再是它当前的意义,例如 \t,t 就不是当前意义字符 t 了,而是被 \ 转成了 tab 键
续行
- 在行尾使用 \,注意 \ 之后除了紧跟着换行之外不能有其他字符
- 如果使用各种括号,认为括号内是一个整体,其内部跨行不用 \
标识符
标识符
- 一个名字,用来指代一个值
- 只能是字母、下划线和数字
- 只能以字母或下划线开头
- 不能是 python 的关键字,例如 def、class 就不能作为标识符
- Python 是大小写敏感的
False await else import pass
None break except in raise
True class finally is return
and continue for lambda try
as def from nonlocal while
assert del global not with
async elif if or yield标识符约定:
- 不允许使用中文,也不建议使用拼音
- 不要使用歧义单词,例如class_
- 在python中不要随便使用下划线开头的标识符
常量
- 一旦赋值不能改变值的标识符
- python中无法定义常量
字面常量
- 一个单独的不可变量,例如 12、"abc" 、'2341356514.03e-9'
变量
- 赋值后,可以改变值的标识符
标识符本质
每一个标识符对应一个具有数据结构的值,但是这个值不方便直接访问,程序员就可以通过其对应的标 识符来访问数据,标识符就是一个指代。一句话,标识符是给程序员编程使用的。
False 等价
| 对象/常量 | 值 |
|---|---|
| "" | 假 |
| “string” | 真 |
| 0 | 假 |
| >=1 | 真 |
| <=-1 | 真 |
| ()空元组 | 假 |
| []空列表 | 假 |
| {}空字典 | 假 |
| None | 假 |
False 等价布尔值,相当于bool(value)
- 空容器
- 空集合 set
- 空字典 dict
- 空列表 list
- 空元组 tuple
- 空字符串
- None
- 0
运算符 Operator
算数运算符
+、-、*、/、//向下取整整除、%取模、**幂
注:在Python2中/和//都是整除。
位运算符
&位与、|位或、^异或、<<左移、>>右移
~按位取反,包括符号位
比较运算符
==、!=、>、>=、<、<=
链式比较: 4 > 3 > 2
逻辑运算符
与and、或or、非not
逻辑运算符也是短路运算符
and 如果前面的表达式等价为False,后面就没有必要计算了,这个逻辑表达式最终一定等价为 False 1 and '2' and 0 0 and 'abc' and 1
or 如果前面的表达式等价为True,后面没有必要计算了,这个逻辑表达式最终一定等价为True 1 or False or None
特别注意,返回值。返回值不一定是 bool 型
把最频繁使用的,做最少计算就可以知道结果的条件放到前面,如果它能短路,将大大减少计算量
赋值运算符
a = min(3, 5)
+=、 -= 、*=、/=、%=、//= 等
x = y = z = 10
成员运算符
in、not in
身份运算符
is、is not
运算符优先级
- 单目运算符 > 双目运算符
- 算数运算符 > 位运算符 > 比较运算符 > 逻辑运算符
- -3 + 2 > 5 and 'a' > 'b'
搞不清楚就使用括号。长表达式,多用括号,易懂、易读。
表达式
由数字、符号、括号、变量等的组合。有算数表达式、逻辑表达式、赋值表达式、lambda 表达式等 等。
Python 中,赋值即定义。Python 是动态语言,只有赋值才会创建一个变量,并决定了变量的类型和 值。
如果一个变量已经定义,赋值相当于重新定义。
类和对象
创建类
在Python中,编写类时需要注意几个规则。首先,所有成员变量应当在构造方法内实现。若想要将某个变量设定为私有变量,需要在其前面加双下划线。而对于成员方法,则约定使用self作为第一个参数,代表对象本身。类的静态变量可以通过“类名.变量名”的方式设定。如果在类体内定义的方法前添加了@staticmethod装饰器,那么该方法将成为类的静态方法。实例化类的格式为“类名(参数)”。此外,若想访问对象的私有变量,可以使用“对象名._类名_变量名”的方式访问;而访问私有方法则需采用“对象名._类名__方法名()”的方式。
例:
class Demo:
def __init__(self, data=0, __data=0):
self.data = data # 所有的数据都在__init__()里面定义
self.__data = __data # 数据以两个下画线开头代表该变量为私有变量
def show_data(self): # 定义成员方法
print('data = ', self.data)
print('__data = ', self.__data)
def __pri_fun(self):
print('我是私有方法')
demo = Demo(1) # 实例化对象
print('demo的类型:', type(demo))
demo.show_data() # 调用成员方法
demo._Demo__pri_fun() # 调用私有方法运行结果:
demo的类型: <class '__main__.Demo'>
data = 1
__data = 0
我是私有方法类的继承
在大多数面向对象编程语言中,实现类的继承通常遵循以下几个步骤:
- 创建子类时,在类名后面使用括号指定要继承的父类。这告诉编程语言子类应该继承父类的属性和方法。
- 在子类的构造方法中,调用父类的构造方法以确保父类中的初始化工作得以执行。这通常通过调用父类的构造方法来实现,具体语法因编程语言而异。
- 可以在子类中重写父类的方法。这意味着你可以在子类中定义一个与父类方法同名的方法,以改变或扩展其行为。
例:
class Father:
def __init__(self):
print('父类初始化')
def show(self):
print('我是父类对象')
class Son(Father): # 子类继承父类
def __init__(self):
super(Son, self).__init__() # 调用父类方法
print('子类初始化')
def show(self): # 重写父类方法
print('我是子类对象')
father = Father()
father.show()
son = Son()
son.show()运行结果:
父类初始化
我是父类对象
父类初始化
子类初始化
我是子类对象装饰器
装饰器是在函数、成员变量或类名前面加上@xxx的标识表示这个对象具有一定属性。
- 在类的成员方法前面加上@property可以将此方法设为类的一个属性,可以直接调用对象的属性。
例:
class rect:
def __init__(self, width=0, height=0):
self.width = width
self.height = height
@property # 在函数定义的前一行加上@property则将此方法作为成员属性 调用时不需再加圆括号 同时最好要有返回值 此方法还可作为getter方法
def area(self):
return self.width * self.height
print('长为20宽为10的矩形的面积为: ', rect(20, 10).area) # 调用函数时不需要再加上圆括号运行结果:
长为20宽为10的矩形的面积为: 200- 在属性前面加上@property可以将此属性设为只读 可以保护此数据
例:
class data:
def __init__(self, data=None):
self.__data = data
@property # 可以尝试注释此代码前后的执行结果
def data(self):
return self.__data
data1 = data(0)
print('修改前的数据为: ', data1.data)
data1.data = 1
print('修改后的数据为: ', data1.data)运行结果:
修改前的数据为: 0
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In [2], line 12
10 data1 = data(0)
11 print('修改前的数据为: ', data1.data)
---> 12 data1.data = 1
13 print('修改后的数据为: ', data1.data)
AttributeError: can't set attribute 'data'序列
Python中的序列包括元组、列表、字典、集合、字符串。
元组
元组是不可变序列,因此它可以作为字典的键值。使用元组可以通过索引来访问其中的元素,索引从0开始,例如,使用 tuple[x] 可以访问第 x+1 个元素。元组的创建使用括号和逗号,例如 (item1, item2, item3)。如果元组只有一个元素,则在元素后面需要加一个逗号,例如 (item,)。元组中可以存储任意类型的数据,并且可以使用内置函数 tuple() 将一个可变序列转换为元组。
元组也可以使用切片进行范围访问。例如,使用 tuple[x:y] 可以访问第 x+1 到第 y 个元素(不包含第 y 个元素)。如果需要间隔访问元组中的元素,可以使用 tuple[x:y:s],其中 s 为步长,表示每隔 s 个元素访问一次。切片中索引的规则是,正数索引从0开始,负数索引从倒数第一个元素开始,省略 x 或 y 表示从第一个或者最后一个元素开始,省略步长 s 表示步长为1。
元组本身是不可变的,但在创建新的元组对象时可以对已有元组进行合并、取子集等操作。元组也支持遍历和推导式操作,例如使用 for 循环遍历元组中的元素,或者使用元组推导式来创建新的元组对象。
例:
tuple1 = (1, 2, 3) # 定义一个元组 还可以去掉括号 但是逗号不能省略
tuple2 = 1, 2, 3 # 也可以使用内置函数tuple将一个可变序列转换成元组
print(tuple1)
print(tuple2)
tuple3 = 1, # 定义只有一个元素的元组要写成左边的形式
tuple4 = (1,)
print(tuple3)
print(tuple4)
tuple5 = () # 想定义一个空元组可以使用左边的两种方式
tuple6 = tuple()
print(tuple5)
print(tuple6)
tuple7 = (1, 'a', (1, 'a'), None) # 元组内的元素可以是不同类型的元素
print(tuple7)
tuple8 = tuple(x for x in range(1, 10)) # 使用元组推导式时得到的对象是一个生成器,要使用tuple()函数将其转换成元组
print(tuple8)
print(tuple8[0:2])运行结果:
(1, 2, 3)
(1, 2, 3)
(1,)
(1,)
()
()
(1, 'a', (1, 'a'), None)
(1, 2, 3, 4, 5, 6, 7, 8, 9)
(1, 2)列表
列表是可变的有序序列,可以使用 for 循环对列表进行遍历。列表是一种常见的数据结构,它可以存储任意类型的数据,并且可以根据需要动态调整大小。
列表对象具有许多常用方法,其中一些包括:
append(x):向列表末尾追加元素 x。
- sort():将列表按升序排序。如果需要按降序排序,可以设置参数
- reverse=True。也可以使用内置函数 sorted(x) 来实现排序。
- count(x):统计列表中元素 x 出现的次数。
- index(x):获取元素 x 第一次出现的索引。
- insert(i, x):在指定位置 i 插入元素 x。
- remove(x):移除列表中第一个出现的元素 x,并返回该元素。
此外,列表也支持列表推导式和切片操作,类似于元组。使用列表推导式可以根据特定规则创建新的列表对象,而切片操作则允许获取列表的子集或进行特定范围的访问。
例:
list1 = [1, 2, 3] # 创建一个列表使用的是方括号
list2 = list(tuple1) # 还可以使用内置函数list将一个序列转换成列表
print(list1)
print(list2)
list3 = [] # 想要创建一个空列表只需使用一对方括号即可
print(list3)运行结果:
[1, 2, 3]
[1, 2, 3]
[]字典
字典和其他序列不同的是,字典是以键值对存储的,可以通过访问键的方式获取对应的值。字典的键不能重复,但映射是可以相同的。
- 使用
dict[key]访问字典元素,其中dict为字典对象,key为键。 - 创建一个空字典可以使用一对大括号
{}或者使用内置函数dict()。 - 若要添加元素,直接使用
dict[newKey] = newValue,其中newKey为新键。 - 使用
del dict[key]删除元素,其中key必须存在。 - 存在字典推导式,格式为
dict = {key:value for 元素 in 可迭代对象}。
字典对象的常用方法包括:
dict.items():将所有键值对转换成对应的元组(dict为字典对象)。dict.keys():将所有的键转换成元组。dict.values():将所有的值转换成元组。
例:
dic = {'1': 'a', '2': 'b', '3': 'c'}
for i, j in dic.items(): # dict.items() 将所有键值对转换成对应的元组
print(i, j, end=', ')
print()
for i in dic.keys(): # dict.keys() 将所有的键值转换成元组
print(dic.keys(), end=', ')
print()
for i in dic.values(): # dict.values() 将所有的值转换成元组
print(i, end=', ')
print('\n')
dic1 = dict()
dic2 = {} # 创建一个空字典使用一对大括号或者使用内置函数dict() 实际上所有对应的序列函数都可以生成一个对应的对象 下面不再演示。
# 使用字典推导式快速生成一个字典
keys = (1, 2, 3)
values = ('a', 'b', 'c')
dic = {i: j for i, j in zip(keys, values)}
print(dic)运行结果:
1 a, 2 b, 3 c,
dict_keys(['1', '2', '3']), dict_keys(['1', '2', '3']), dict_keys(['1', '2', '3']),
a, b, c,
{1: 'a', 2: 'b', 3: 'c'}集合
集合是无序的,用于保存不重复的元素,并且可以执行类似数学中集合的基本运算。在Python中,可以按照以下方法操作集合:
- 创建集合使用花括号。
- 使用
set.add(x)向集合中添加元素 x。 - 使用
pop()或者remove()方法删除元素。 - 使用“&”进行交集运算,使用“|”进行并集运算,使用“-”进行差集运算,使用“^”进行对称差集运算。
例:
set1 = {1, 2, 3}
print(set1)
set2 = set() # 创建空集合 不能使用括号
print(set2)
set1 = {1, 2, 3, 4, 5}
set2 = {2, 3, 6}
print('set1 & set2 = ', set1 & set2)
print('set1 | set2 = ', set1 | set2)
print('set1 - set2 = ', set1 - set2)
print('set1 ^ set2 = ', set1 ^ set2)运行结果:
{1, 2, 3}
set()
set1 & set2 = {2, 3}
set1 | set2 = {1, 2, 3, 4, 5, 6}
set1 - set2 = {1, 4, 5}
set1 ^ set2 = {1, 4, 5, 6}字符串
字符串在Python中是一种常见的数据类型,可以使用单引号或双引号表示。字符串支持多种操作,包括切片、索引访问以及使用 for 循环进行遍历。此外,字符串还可以通过 + 运算符进行拼接。在字符串中,还可以使用转义字符来表示特殊字符。另外,字符串前面可以加上 r、u 或 b 来表示不转义、以 Unicode 编码、或者表示为字节码。
格式化
- 使用 % 运算符
使用 % 格式化字符串是 Python 中常见的格式化方法,其语法格式如下:
'%[-][+][0][m][.n]格式字符' % exp其中,可选参数包括:
-:指定左对齐,正数前面无符号,负数前面有负号。+:指定右对齐,正数前面有正号,负数前面有负号。0:指定右对齐,正数前面无符号,负数前面有负号,不足位数的用0代替。m:用于指定数字位数。.n:用于指定小数位数。
其规则与 C 语言很相似。
例:
template1 = '%09d'
context1 = 1234567
print(template1 % context1)
template2 = '数值: %4.2f, 字符串: %s'
context2 = (12.34567, '小红') # 若要转换的项多于一个 就需要使用元组
print(template2 % context2)运行结果:
001234567
数值: 12.35, 字符串: 小红- 使用字符串对象的format()方法
使用字符串对象的 format() 方法是另一种常见的格式化字符串的方法,其模板的格式为 {[index]:[fill][align][sign][#][width][.precision][type]}。
其中,可选参数包括:
index:指定要设置格式的对象在参数列表的索引位置。如果索引值省略,则使用默认排序。fill:指定空白处填充的字符。align:指定对齐参数,可选值包括<左对齐、>右对齐、^居中对齐、=只对数字有效,右对齐,正数前无符号。sign:指定数字格式化格式,可选为-、+。若为空格,则表示正数加空格,负数加负号。#:在二进制、八进制、十六进制数前分别显示\0b、\0o、\0x。width:指定所占宽度。.precision:指定保留的小数位数。type:指定类型,和 C 语言非常类似。若为G或g,则自动在e和f转换。
例:
template3 = '数字格式化: {:,.2f}'
context3 = 12345.6789
print(template3.format(context3))
template4 = '数字依次转换为二进制 八进制 十六进制数: {:#b} {:#o} {:#x}'
print(template4.format(123, 456, 789))运行结果:
数字格式化: 12,345.68
数字依次转换为二进制 八进制 十六进制数: 0b1111011 0o710 0x315字符串对象常用方法
string.capitalize(): 把字符串的第一个字符大写。string.count(str, beg=0, end=len(string)): 返回 str 在 string 中出现的次数,可以指定起始位置 beg 和结束位置 end。string.decode(encoding='UTF-8', errors='strict'): 以指定的编码格式解码字符串。string.encode(encoding='UTF-8', errors='strict'): 以指定的编码格式编码字符串。string.endswith(obj, beg=0, end=len(string)): 检查字符串是否以指定对象 obj 结束,可以指定起始位置 beg 和结束位置 end。string.find(str, beg=0, end=len(string)): 检测字符串是否包含子字符串 str,可以指定查找范围。string.format(): 格式化字符串。string.index(str, beg=0, end=len(string)): 类似于 find() 方法,但是如果 str 不在 string 中会报错。string.isdecimal(): 如果字符串只包含十进制数字,则返回 True。string.isdigit(): 如果字符串只包含数字,则返回 True。string.islower(): 如果字符串中包含至少一个区分大小写的字符,并且所有这些字符都是小写,则返回 True。string.isupper(): 如果字符串中包含至少一个区分大小写的字符,并且所有这些字符都是大写,则返回 True。string.join(seq): 将 seq 中所有的元素(的字符串表示)合并为一个新的字符串,以 string 作为分隔符。string.lower(): 将字符串中所有大写字符转换为小写。string.lstrip(): 截掉字符串左边的空格。max(str): 返回字符串 str 中最大的字母。min(str): 返回字符串 str 中最小的字母。string.replace(str1, str2, num=string.count(str1)): 将字符串中的 str1 替换为 str2,可以指定替换次数 num。string.rfind(str, beg=0, end=len(string)): 类似于 find() 方法,但返回最后一次出现的位置。string.rindex(str, beg=0, end=len(string)): 类似于 index() 方法,不过返回最后一次出现的位置。string.rstrip(): 删除字符串末尾的空格。string.split(str="", num=string.count(str)): 以 str 为分隔符切片字符串,可以指定切片次数 num。string.splitlines([keepends]): 按照行分隔字符串,返回一个包含各行作为元素的列表。string.startswith(obj, beg=0, end=len(string)): 检查字符串是否以 obj 开头,可以指定起始位置 beg 和结束位置 end。string.strip([obj]): 在字符串上执行 lstrip() 和 rstrip()。string.upper(): 将字符串中的小写字母转换为大写。
例:
# 不区分大小写判断会员名字是否唯一
member = ''
con = True
while con:
name = input("请输入会员名: ").lower()
print('输入会员名:', name)
if member.find('|' + name + '|') != -1:
print('该名字已存在: ', name)
elif len(member) == 0:
member = '|' + name + '|'
print('添加成功: ', name)
elif name == 'q':
break
else:
member += name + '|'
print('添加成功: ', name)
print('现有会员列表: ', member)运行结果:
输入会员名: zhangsan
添加成功: zhangsan
现有会员列表: |zhangsan|
输入会员名: lisi
添加成功: lisi
现有会员列表: |zhangsan|lisi|
输入会员名: q函数
定义函数
在Python中,我们使用 def 关键字来定义函数,例如 def add(a, b):。在函数定义时,我们可以选择性地在函数括号后面加上箭头来指定返回值,也可以在变量名字后面加上冒号来提供提示功能。
例:
def add(a: int, b: int) -> int:
return a + b
print('1 + 2 的结果为: ', add(1, 2))运行结果:
1 + 2 的结果为: 3匿名方法
Python中的lambda表达式用于创建匿名函数。其语法为 lambda 参数: 返回值。你可以将这个匿名函数赋值给一个变量,例如 func = lambda x: x * 2。
例:
result = lambda a, b: a + b
print(result(1, 2))运行结果:
3特殊参数
- 可变参数
在参数前面加*,该参数代表可变参数,在调用时可以传入多个实参。实际上参数会保存为列表。
例:
def f(*i):
print('\n参数的值为: ')
for i in i:
print(i, end=', ')
f(1)
f(1, 2, 3)
# 若想要把列表当为参数 则只需要在列表前面加上*号即可
list1 = [1, 2, 3, 4, 5]
f(list1)运行结果:
参数的值为:
1,
参数的值为:
1, 2, 3,
参数的值为:
[1, 2, 3, 4, 5],参数前加**,则是保存到字典中。
例:
def f2(**i):
for i, j in i.items():
print(i, " = ", j, end=', ')
f2(name='小明', age=18) # 等号左边是字典的键 等号右边是字典的值
# 若想要把已经保存的字典作为参数 就在字典参数加上**
dic = {'name': '小红', 'age': 19}
f2(**dic)运行结果:
name = 小明, age = 18, name = 小红, age = 19,函数也可以指定默认值。
例:
def f3(a=1, b=2): # 为参数指定默认值 但是指定默认值的参数必须放在参数列表的末尾
print('a =', a, 'b =', b)
f3(3) # 这里的3会覆盖a的值 但是b没有重新赋值 所以b的值不会被覆盖运行结果:
a = 3 b = 2内置函数
数学相关
abs(a): 求取参数 a 的绝对值。例如,abs(-1)返回 1。max(list): 求取列表 list 中的最大值。例如,max([1,2,3])返回 3。min(list): 求取列表 list 中的最小值。例如,min([1,2,3])返回 1。sum(list): 求取列表 list 中元素的总和。例如,sum([1,2,3])返回 6。sorted(list): 对列表进行排序,返回排序后的列表。len(list): 返回列表 list 的长度。例如,len([1,2,3])返回 3。divmod(a,b): 获取 a 除以 b 的商和余数,返回一个元组。例如,divmod(5,2)返回 (2,1)。pow(a,b): 获取 a 的 b 次方。例如,pow(2,3)返回 8。round(a,b): 返回浮点数 a 的 b 位小数的近似值。例如,round(3.1415926,2)返回 3.14。range(a[,b]): 生成一个从 a 到 b 的数组,左闭右开。例如,range(1,10)返回 [1,2,3,4,5,6,7,8,9]。
例:
print('-1的绝对值:', abs(-1))
print('-1、0、1的最大值:', max(-1, 0, 1))
print('-1、0、1的最小值:', min(-1, 0, 1))
print('-1、0、2的最大值:', sum([-1, 0, 2]))
print('对[0, 2, 1]排序:', sorted([0, 2, 1]))
print('[1, 2, 3]的长度:', len([1, 2, 3]))
print('5除以2的商和余数:', divmod(5, 2)[0], divmod(5, 2)[1])
print('2的3次方:', pow(2, 3))
print('1.234567取3位小数:', round(1.234567, 3))
print('生成一个从1到9的数组:', tuple(range(1, 10)))运行结果:
-1的绝对值: 1
-1、0、1的最大值: 1
-1、0、1的最小值: -1
-1、0、2的最大值: 1
对[0, 2, 1]排序: [0, 1, 2]
[1, 2, 3]的长度: 3
5除以2的商和余数: 2 1
2的3次方: 8
1.234567取3位小数: 1.235
生成一个从1到9的数组: (1, 2, 3, 4, 5, 6, 7, 8, 9)类型转换
int(str): 将字符串转换为整数类型。例如,int('1')返回 1。float(int/str): 将整数或字符串转换为浮点数类型。例如,float('1')返回 1.0。str(int): 将整数转换为字符串类型。例如,str(1)返回 '1'。bool(int): 将整数转换为布尔类型。例如,bool(0)返回 False,bool(None)返回 False。bytes(str, code): 接收一个字符串和所要编码的格式,返回一个字节流类型。例如,bytes('abc', 'utf-8')返回 b'abc'。list(iterable): 将可迭代对象转换为列表类型。例如,list((1,2,3))返回 [1,2,3]。iter(iterable): 返回一个可迭代的对象。例如,iter([1,2,3])返回 <list_iterator object at 0x0000000003813B00>。dict(iterable): 将可迭代对象转换为字典类型。例如,dict([('a', 1), ('b', 2), ('c', 3)])返回 {'a':1, 'b':2, 'c':3}。enumerate(iterable): 返回一个枚举对象。tuple(iterable): 将可迭代对象转换为元组类型。例如,tuple([1,2,3])返回 (1,2,3)。set(iterable): 将可迭代对象转换为集合类型。例如,set([1,4,2,4,3,5])返回 {1,2,3,4,5}。hex(int): 将整数转换为16进制字符串。例如,hex(1024)返回 '0x400'。oct(int): 将整数转换为8进制字符串。例如,oct(1024)返回 '0o2000'。bin(int): 将整数转换为2进制字符串。例如,bin(1024)返回 '0b10000000000'。chr(int): 将整数转换为相应ASCI码字符。例如,chr(65)返回 'A'。ord(str): 将ASCI字符转换为相应的整数。例如,ord('A')返回 65。
例:
print('将\'1\'转换为数字:', int('1'))
print('将\'1.2\'转换为浮点值:', float('1.2'))
print('将\'1\'转化为字符型:', str(1))
print('将1转换为布尔型:', bool(1))
print('将\'abc\'转换为字节流:', bytes('abc', 'utf8'))
print('将元组1, 2, 3转换为列表:', list((1, 2, 3)))
print('将元组1, 2, 3转换为可迭代对象:', iter((1, 2, 3)))
print('将元组1, 2, 3转换为枚举对象:', enumerate((1, 2, 3)))
print('将列表[1, 2, 3]转换为元组:', tuple([1, 2, 3]))
print('将元组1, 2, 3转换为集合:', set((1, 2, 3)))
print('计算10的二进制、八进制、十六进制的数:', bin(10), oct(10), hex(10))
print('将65转换为对应的字符:', chr(65))
print('查看\'A\'的ASCII码:', ord('A'))运行结果:
将'1'转换为数字: 1
将'1.2'转换为浮点值: 1.2
将'1'转化为字符型: 1
将1转换为布尔型: True
将'abc'转换为字节流: b'abc'
将元组1, 2, 3转换为列表: [1, 2, 3]
将元组1, 2, 3转换为可迭代对象: <tuple_iterator object at 0x000001D135A3D900>
将元组1, 2, 3转换为枚举对象: <enumerate object at 0x000001D1382D5640>
将列表[1, 2, 3]转换为元组: (1, 2, 3)
将元组1, 2, 3转换为集合: {1, 2, 3}
计算10的二进制、八进制、十六进制的数: 0b1010 0o12 0xa
将65转换为对应的字符: A
查看'A'的ASCII码: 65功能相关
eval(): 执行一个表达式或字符串作为运算。例如,eval('1+1')返回 2。exec(): 执行 Python 语句。例如,exec('print("Python")')打印出 Python。filter(func, iterable): 通过判断函数 func,筛选符合条件的元素。例如,filter(lambda x: x>3, [1,2,3,4,5,6])返回<filter object at 0x0000000003813828>。map(func, *iterable): 将 func 应用于每个 iterable 对象。例如,map(lambda a,b: a+b, [1,2,3,4], [5,6,7])返回[6,8,10]。zip(*iterable): 将 iterable 分组合并,返回一个 zip 对象。例如,list(zip([1,2,3],[4,5,6]))返回[(1, 4), (2, 5), (3, 6)]。type(): 返回一个对象的类型。id(): 返回一个对象的唯一标识值。hash(object): 返回一个对象的哈希值,具有相同值的对象具有相同的哈希值。例如,hash('python')返回7070808359261009780。help(): 调用系统内置的帮助系统。isinstance(): 判断一个对象是否为该类的一个实例。issubclass(): 判断一个类是否为另一个类的子类。globals(): 返回当前全局变量的字典。next(iterator[, default]): 接收一个迭代器,返回迭代器中的下一个元素,如果设置了 default,则当迭代器中的元素遍历结束后,返回 default 内容。reversed(sequence): 生成一个反转序列的迭代器。例如,reversed('abc')返回['c','b','a']。
例:
print('1+1的结果为', eval('1+1'))
print('执行Python语句:', exec('print(\'我是由exec()函数执行的\')'))
print('过滤(1, 2, 3)中大于2的元素:', tuple(filter(lambda x: not x > 2, (1, 2, 3))))
print('将两个元组一对一映射出来:', tuple(zip((1, 2, 3), (4, 5, 6))))
print('object对象的类型:', type(object()))
print('object对象的一个标识:', id(object()))
obj = object()
print('obj是object类的示例吗:', isinstance(obj, object))
print('将元组1, 2, 3反序排列:', tuple(reversed((1, 2, 3))))运行结果:
1+1的结果为 2
我是由exec()函数执行的
执行Python语句: None
过滤(1, 2, 3)中大于2的元素: (1, 2)
将两个元组一对一映射出来: ((1, 4), (2, 5), (3, 6))
object对象的类型: <class 'object'>
object对象的一个标识: 1998066247056
obj是object类的示例吗: True
将元组1, 2, 3反序排列: (3, 2, 1)其他示例
map 函数: map 函数会根据提供的函数对指定的序列做映射。它的定义为:
map(function, iterable, ...)其中,第一个参数是函数的名称,第二个参数是表示支持迭代的容器或者迭代器。map 函数的作用是以参数序列中的每个元素分别调用 function 函数,并把每次调用返回的结果保存为对象。
示例代码:
func = lambda x: x + 2 result = map(func, [1, 2, 3, 4, 5]) print(list(result))filter 函数: filter 函数会对指定的序列执行过滤操作。它的定义为:
filter(function, iterable)其中,第一个参数是函数的名称,第二个参数表示的是序列,支持迭代的容器或者迭代器。filter 函数的作用是根据 function 函数的返回值对序列进行过滤。
示例代码:
func = lambda x: x + 2 result = filter(func, [1, 2, 3, 4, 5]) print(list(result))reduce 函数: reduce 函数会对参数序列中的元素进行累计。reduce 函数的定义如下:
reduce(function, iterable, [initializer])其中,function 是一个带有两个参数的函数,iterable 是一个可迭代对象,initializer 表示固定的初始值。在 Python 3 中,reduce 函数已经被从全局名字空间里面移除,现在被放置在 functools 模块中,使用时需要先引入。
示例代码:
from functools import reduce func = lambda x, y: x + y result = reduce(func, [1, 2, 3, 4, 5]) print(list(result))注意:function 函数不能为 None。
Object类常用函数
__new__(cls, *args, **kwargs): 创建对象时自动调用的函数,主要作用是创建对象,给该对象分配空间,方便之后的操作。该函数会返回创建出来的对象实体,一旦正常的返回实体后,会调用初始化函数。__init__(self): 初始化函数(构造函数),作用是给当前对象创建各类变量,并给变量赋初值,一般用于对象的初始设置,该函数没有返回值。__str__(self): 对象描述函数,作用是返回当前对象的字符串类型的信息描述,一般用于对象的直接输出显示。__del__(self): 删除该对象时会自动调用,一般用于工具型对象的资源回收。
例:
class Class1(object):
def __init__(self):
print('初始化函数,对象创建成功后自动调用,一般用于对象属性的赋值')
self.data = 10
def __new__(cls, *args, **kwargs):
print('创建对象时有自动调用的函数,如果当前函数没有返回对象,则不会再执行初始化函数了')
return super().__new__(cls)
def __str__(self):
print('调用对象描述方法,在需要自动转换为字符串时会自动调用此方法')
return 'self.data = %s' % self.data
def __del__(self):
print('删除该对象时会自动调用该函数,一般用于工具类释放资源')
class1 = Class1()
print(class1)
del class1运行结果:
创建对象时有自动调用的函数,如果当前函数没有返回对象,则不会再执行初始化函数了
初始化函数,对象创建成功后自动调用,一般用于对象属性的赋值
调用对象描述方法,在需要自动转换为字符串时会自动调用此方法
self.data = 10
删除该对象时会自动调用该函数,一般用于工具类释放资源__repr__(): 输出对象的名称和内存地址。__dir__(): 输出该对象的属性。__sizeof__(): 输出对象的大小。__module__: 类定义所在的模块。类的全名是__main__.className,如果类位于一个导入模块mymod中,那么className.__module__等于mymod。
例:
object1 = object()
print(object1.__repr__())
print(object1.__dir__())
print(object1.__sizeof__())
print(object1.__module__)
print(dir(object1))运行结果:
<object object at 0x000001CB01E5FC30>
['__new__', '__repr__', '__hash__', '__str__', '__getattribute__', '__setattr__', '__delattr__', '__lt__', '__le__', '__eq__', '__ne__', '__gt__', '__ge__', '__init__', '__reduce_ex__', '__reduce__', '__subclasshook__', '__init_subclass__', '__format__', '__sizeof__', '__dir__', '__class__', '__doc__']
16
['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__']文件读写
读取文件的步骤
内置函数 open() 可以打开文件,该方法返回一个 file 对象,你可以通过该对象来操作文件。下面是参数说明:
file:指定要打开的文件路径。如果文件不存在,会抛出异常。mode:指定打开文件的模式。常见模式包括r(只读)、w(只写)、w+(可读可写)、a(追加到文件末尾)。在模式后面加上b表示以二进制模式打开文件。buffering:指定缓冲模式。设置为0表示不缓存,1表示缓存,大于2的值表示定义缓冲区的大小。
例:
file1 = open('./message.txt', 'w', encoding='utf8') # 因为指定模式为可读可写 因此若文件不存在则会自动创建该文件
print(file1)
file2 = open('./message.txt', 'r', encoding='utf8')
print(file2)运行结果:
<_io.TextIOWrapper name='./message.txt' mode='w' encoding='utf8'>
<_io.TextIOWrapper name='./message.txt' mode='r' encoding='utf8'>file对象的write()方法向文件中写入内容(前提要将读取模式设为写),并返回成功写入的字符数。
例:
line = file1.write('向文件中写入内容')
print(line)
file1.flush() # 在写入内容时要清除缓冲区,或者及时关闭文件,才能保存操作运行结果:
8file对象的read()方法读取文件中的内容(前提是读取模式要设置成读取)。
例:
content = file2.read()
print(content)运行结果:
向文件中写入内容最后要关闭文件。
例:
file1.close()
file2.close()使用with关键字打开文件
可以使用 with 语句打开文件,在 with 代码块结束后文件会自动关闭。
readline()方法可以一次读取一行,也可以通过指定参数来限制读取的字符数。readlines()方法可以一次读取多行,同样可以通过指定参数来限制读取的字符数。
例:
with open('./content.txt', 'r', encoding='utf8') as file:
print(file.readline()) # readline()方法可以一次读取一行 也可指定参数指定读取的字符数
print(file.readlines()) # readlines()方法可以一次读取多行 还可以指定参数指定读取的字符数运行结果:
第一行
['第二行\n', '第三行']这里的读取结果之所以是这样是因为在使用readline()方法时文件的指针向后移动了一行,也就是说此时文件的指针在第二行。实际上每次使用读写操作时指针都会后移。
文件其他操作
- os模块的常用方法
os.name存储当前操作系统的名称。如果值为nt,则表示 Windows 操作系统。os.sep存储当前路径的路径分隔符。os.linesep存储当前系统的换行符。os.getcwd()获取当前文件工作的绝对路径。os.path.abspath(path)返回path的绝对路径。os.path.join()方法返回两个路径拼接后的结果。
例:
import os
from os import path
print('当前操作系统为: ', os.name)
print('当前系统使用的路径分隔符为: ', os.sep)
print('当前系统的换行符为: ', os.linesep.__repr__()) # __repr__()代表不转义
print('当前文件的工作目录是: ', os.getcwd()) #
print('message.txt文件所在的绝对路径为: ', path.abspath(r'message.txt'))
print('两个路径拼接后的结果为: ', path.join(r'C:\Windows', r'message.txt'))
print('相对路径下的text文件夹是否存在: ', path.exists(r'.\text'))运行结果:
当前操作系统为: nt
当前系统使用的路径分隔符为: \
当前系统的换行符为: '\r\n'
当前文件的工作目录是: A:\note\newsrc\base\file
message.txt文件所在的绝对路径为: A:\note\newsrc\base\file\message.txt
两个路径拼接后的结果为: C:\Windows\message.txt
相对路径下的text文件夹是否存在: False- os模块的高级操作——操作文件夹
os.mkdir()可以创建一个文件夹。os.makedirs()可以创建多级文件夹。rmdir()可以删除文件夹。
例:
import os
path = r'.\demo'
if not os.path.exists(path): # 若不存在该文件
os.mkdir(path)
else:
print('该文件夹已存在')
# 创建多级目录
path = r'.\demo\text'
if not os.path.exists(path): # 若此文件不存在
os.makedirs(path) # 创建此文件夹
else:
print('该文件夹已存在')
# 删除目录
path = r'.\mr\demo'
if os.path.exists(path): # 若此文件存在
os.rmdir(path) # 删除此文件
else:
print('该文件夹不存在, 删除失败')运行结果:
该文件夹已存在
该文件夹已存在
该文件夹不存在, 删除失败- 遍历目录——
walk()方法
os.walk() 函数是 Python 中用于遍历目录树的一个非常方便的工具。它返回一个生成器,可以递归地遍历指定目录及其子目录中的所有文件和文件夹。
top:必选参数,表示要遍历的根目录。topdown:可选参数,默认为 True,表示从上而下遍历。如果设置为 False,则表示从下而上遍历。onerror:可选参数,表示错误解决方式。如果指定了该参数,则遇到错误时将执行指定的错误解决方法。followlinks:可选参数,默认为 False,表示是否以链接方式输出。如果设置为 True,则会跟踪符号链接所指向的目录或文件。
os.walk() 返回一个生成器,每次迭代会生成一个元组 (root, dirs, files),其中:
root:字符串,表示当前遍历的目录路径。dirs:列表,表示当前目录下的所有文件夹名字。files:列表,表示当前目录下的所有文件名字。
通过遍历这个生成器,可以逐个访问目录树中的每个目录、子目录和文件。
例:
import os
# 遍历此目录下的所有文件和文件夹
path = os.walk('.', True)
for i in path:
print(i)
print('-'*10)
path = r'..\file'
for root, dirs, files in os.walk(path):
print('[', root, ']', '下的文件包含:')
for name in dirs:
print(name)
for name in files:
print(name)运行结果:
('.', ['demo', 'first', 'other'], [])
('.\\demo', ['text'], [])
('.\\demo\\text', [], [])
('.\\first', [], ['content.txt', 'demo.ipynb', 'message.txt'])
('.\\other', [], ['operation.ipynb'])
----------
[ ..\file ] 下的文件包含:
demo
first
other
[ ..\file\demo ] 下的文件包含:
text
[ ..\file\demo\text ] 下的文件包含:
[ ..\file\first ] 下的文件包含:
content.txt
demo.ipynb
message.txt
[ ..\file\other ] 下的文件包含:
operation.ipynb- 其他操作
remove()用于删除文件。rename()可以重命名文件,第一个参数为旧文件名,第二个参数为新文件名。os.stat()可以获取文件信息,该方法返回一个对象,访问对象的变量就可以获取信息。
例:
import os
if os.path.exists(r'.\new.txt'):
os.remove(r'.\new.txt')
else:
print('该文件不存在')
if os.path.exists(r'A:\\file'):
os.rename(r'A:\file.txt', r'A:\file')
else:
print('该文件不存在')
path = None
if os.path.exists(r'..\Error.ipynb'):
path = os.stat(r'..\Error.ipynb')
else:
print('该文件不存在')
print('Error.ipynb文件的大小是: ', path.st_size)
print('Error.ipynb最后的访问时间是: ', path.st_atime)运行结果:
该文件不存在
该文件不存在
Error.ipynb文件的大小是: 4848
Error.ipynb最后的访问时间是: 1665747794.7438216Python异常处理
异常处理是编程中至关重要的一部分,它能够帮助我们在程序执行过程中处理各种意外情况,保证程序的稳定性和可靠性。让我们来看一下异常处理的基本步骤:
- 使用
raise关键字可以在代码中抛出异常,这样可以提醒程序执行过程中发生了某些意外情况。不过,我们并不总是需要自定义异常,有时候直接使用已有的异常类型就足够了。 - 为了在执行可能出现异常的代码块时能够做好准备,我们可以使用
try关键字来包裹这段代码。这样,如果代码块中出现了异常,程序不会立即停止执行,而是会继续执行后续的代码。 - 当程序执行到
try块中的代码时发生了异常,我们可以使用except关键字来捕捉这个异常。这样,我们就有机会对异常进行处理,避免程序崩溃。如果成功捕捉到异常,则会执行except中的代码块。 - 有时候,我们也希望在没有发生异常时执行一些特定的操作。这时,可以在
except后面跟一个else,这样如果没有异常发生,则会执行else中的代码块。 - 最后,无论是否发生异常,我们都希望能够执行一些必要的清理工作。这时,可以使用
finally关键字,它表示无论是否抛出异常都会执行其后的代码块,确保程序执行完毕后能够做好善后工作。
例:
def share(children, apples): # 定义分苹果函数 第一个参数是小孩的数量 第二个参数是苹果的数量
if children > apples:
raise Exception('苹果太少, 小孩不够分! ')
elif children == apples:
print('小孩和苹果的数量一样多, 每个小朋友一个苹果')
elif children < apples:
print('苹果的数量更多, 每个小朋友一个苹果, 剩下', apples - children, '个苹果')
if __name__ == '__main__':
try:
share(10, 5) # 10个小孩分5个苹果
except Exception as e: # try except捕捉异常 后面可以加as 变量名 将捕捉到的变量包装成一个对象
print(e)
else: # 在except语句后面还可以加上else 指定没有捕捉到异常时执行的语句
print('顺利地为每一个小朋友分到了苹果')
finally: # 最后还可以加上finally语句 指定无论是否捕捉到异常都执行的语句 一般用于关闭文件等操作
print('第一次尝试分苹果完成')
share(7, 7)
share(5, 10)
share(10, 5)运行结果:
苹果太少, 小孩不够分!
第一次尝试分苹果完成
小孩和苹果的数量一样多, 每个小朋友一个苹果
苹果的数量更多, 每个小朋友一个苹果, 剩下 5 个苹果
---------------------------------------------------------------------------
Exception Traceback (most recent call last)
Cell In [1], line 19
17 share(7, 7)
18 share(5, 10)
---> 19 share(10, 5)
Cell In [1], line 3, in share(children, apples)
1 def share(children, apples): # 定义分苹果函数 第一个参数是小孩的数量 第二个参数是苹果的数量
2 if children > apples:
----> 3 raise Exception('苹果太少, 小孩不够分! ')
4 elif children == apples:
5 print('小孩和苹果的数量一样多, 每个小朋友一个苹果')
Exception: 苹果太少, 小孩不够分!正则表达式
字符串匹配
re.match()是一个用于字符串匹配的重要函数,它的使用方法如下:
- 该函数尝试从字符串的开头开始匹配正则表达式。如果匹配成功,则返回第一个符合正则表达式的
match对象,否则返回None。 - 函数接受三个参数:第一个是正则表达式,第二个是待匹配的字符串,第三个是可选的参数,用于指定匹配选项。
- 当指定
re.I选项时,表示忽略大小写;指定re.A选项时,表示\w不匹配汉字。 - 如果匹配成功,可通过
match对象的start()方法获取匹配子字符串的起始索引,end()方法获取结束索引,group()方法获取匹配的子字符串。
例:
# 字符串匹配
import re
template1 = r'\d{3}' # 匹配三个数字
string1 = '123abc456'
match1 = re.match(template1, string1, re.I)
print('符合条件的起始索引为', match1.start())
print('符合条件的最后索引为', match1.end())
print('符合条件的子字符串为', match1.group())运行结果:
符合条件的起始索引为 0
符合条件的最后索引为 3
符合条件的子字符串为 123re.match()方法同样可以返回第一个符合正则表达式的match对象。
例:
template2 = r'[a-z]{1}\d{2}' # 匹配一个字母和两个数字
string2 = '1ab23'
match2 = re.search(template2, string2, re.I) # 该方法和match()方法很相似 返回第一个符合条件的match对象 否则返回None
print('符合条件的起始索引为', match2.start())
print('符合条件的最后索引为', match2.end())
print('符合条件的子字符串为', match2.group())运行结果:
符合条件的起始索引为 2
符合条件的最后索引为 5
符合条件的子字符串为 b23findall()可以获取所有符合正则表达式的子字符串,返回值是一个match对象数组。
例:
template3 = r'abc[1-5]{1}' # 匹配abc加上一个数字
string3 = 'abc1bcd2abc3'
match3 = re.findall(template3, string3, re.I) # 该方法会返回一个列表 若没有匹配成功则返回一个空列表
print(match3)运行结果:
['abc1', 'abc3']- 使用正则表达式分割字符串 使用
re.split()方法分割字符串,参数1为正则表达式,参数2为字符串
例:
import re
pattern = r'\s*@' # 指定模式字符串
string = ' @安生 @张三 @李四 @明日科技'
list1 = re.split(pattern, string)
print('您@的好友为:')
for i in list1:
if i != '':
print(i)运行结果:
您@的好友为:
安生
张三
李四
明日科技常用模块
JSON
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于人阅读和编写。
首先需要导入json模块,使用json.dumps()来将数据转换为json格式,使用json.loads()将json数据转换为Python对象,使用json.dump()将python中的对象转化成json储存到文件中,使用json.load()将文件中的json的格式转化成python对象提取出来。
json.dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, encoding="utf-8", default=None, sort_keys=False, **kw)
参数解读:
obj:要转换的Python对象
sort_keys =True:是告诉编码器按照字典排序(a到z)输出。如果是字典类型的python对象,就把关键字按照字典排序
indent:参数根据数据格式缩进显示,读起来更加清晰
separators:是分隔符的意思,参数意思分别为不同dict项之间的分隔符和dict项内key和value之间的分隔符,把:和,后面的空格都除去了
skipkeys:默认值是False,如果dict的keys内的数据不是python的基本类型(str,unicode,int,long,float,bool,None),设置为False时,就会报TypeError的错误。此时设置成True,则会跳过这类key
ensure_ascii=True:默认输出ASCII码,如果把这个改成False,就可以输出中文。
例:
import json
dic = {'key%d' % i: 'value%d' % i for i in range(1, 6)}
json = json.dumps(dic)
print('字典格式:', dic)
print('json格式:', json)运行结果:
字典格式: {'key1': 'value1', 'key2': 'value2', 'key3': 'value3', 'key4': 'value4', 'key5': 'value5'}
json格式: {"key1": "value1", "key2": "value2", "key3": "value3", "key4": "value4", "key5": "value5"}json.dump(obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True,allow_nan=True, cls=None, indent=None, separators=None,default=None, sort_keys=False, **kw)
参数相比dumps()多了一个fp,它表示保存的文件名。
loads(s, *, cls=None, object_hook=None, parse_float=None,parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
参数解读:
s:源对象
object_pairs_hook参数是可选的,它会将结果以key-value有序列表的形式返回,形式如:[(k1, v1), (k2, v2), (k3, v3)],如果object_hook和object_pairs_hook同时指定的话优先返回object_pairs_hook
parse_float参数是可选的,它如果被指定的话,在解码json字符串的时候,符合float类型的字符串将被转为你所指定的,比如说你可以指定为decimal.Decimal
parse_int参数是可选的,它如果被指定的话,在解码json字符串的时候,符合int类型的字符串将被转为你所指定的,比如说你可以指定为float
- def load(fp, *, cls=None, object_hook=None, parse_float=None,parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
和json.load()类似,这里不再赘述。
例:
import json
x = {'name': '你猜', 'age': 19, 'city': '四川'}
#用dumps将python编码成json字符串
x = json.dumps(x, ensure_ascii=False)
print('json格式:', x)
#用loads将json编码成python
print('json解码后:', json.loads(x))运行结果:
json格式: {"name": "你猜", "age": 19, "city": "四川"}
json解码后: {'name': '你猜', 'age': 19, 'city': '四川'}随机数
random 模块是 Python 中用于生成随机数的常用模块。让我们看一下它提供的几个常用方法:
random.random(): 返回一个 0 到 1 之间的随机浮点数。random.randint(a, b): 返回一个从a到b(包含端点值)的随机整数。random.randrange(a, b, s): 返回一个从a到b之间(不包含b)的随机整数,可以指定步长s。random.choice(s): 从一个序列s中随机返回一个元素,这个序列可以是字符串、元组或列表。random.shuffle(s): 随机排列序列s中的元素,这个序列必须是列表。
例:
import random
print('产生一个从0-1的随机浮点数: ', random.random())
print('产生一个从1-10的随机整数(包括1和10): ', random.randint(1, 10))
print('产生一个从1-9的随机整数,步长为2,不包括9: ', random.randrange(1, 9, 2))
list1 = ['a', 'b', 0, 1, []]
print('从已有列表里面随机选择一个元素: ', random.choice(list1))
random.shuffle(list1)
print('将列表的顺序打乱后列表的顺序是: ', list1)运行结果:
产生一个从0-1的随机浮点数: 0.07918614268014179
产生一个从1-10的随机整数(包括1和10): 2
产生一个从1-9的随机整数,步长为2,不包括9: 3
从已有列表里面随机选择一个元素: []
将列表的顺序打乱后列表的顺序是: [1, 0, [], 'b', 'a']datetime模块
date:日期类
常用属性:year/month/day
- 获取当前时间
import datetime
today = datetime.datetime.today()
today1 = datetime.datetime.now()结果:

- 日期对象的属性
import datetime
# 这两种都可以
today = datetime.datetime.today()
# today1 = datetime.datetime.now()
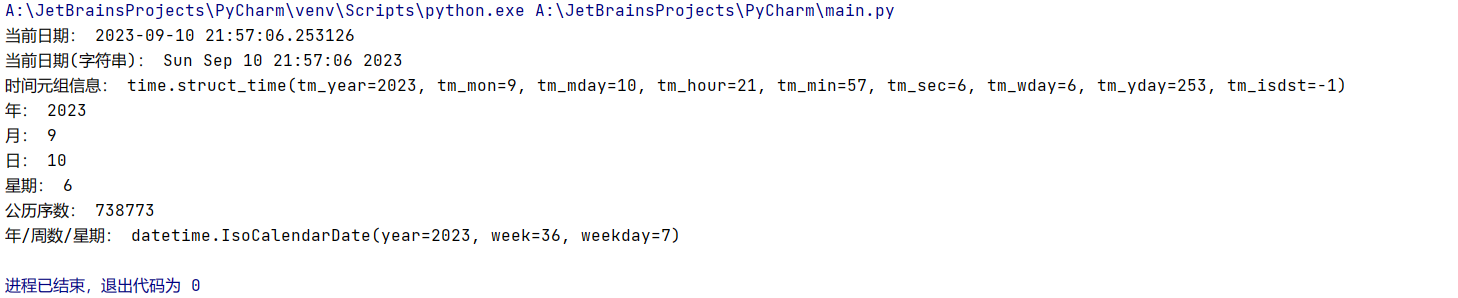
print("当前日期:", today) # 当前日期
print("当前日期(字符串):", today.ctime()) # 返回日期的字符串
print("时间元组信息:", today.timetuple()) # 当前日期的时间元组信息
print("年:", today.year) # 返回today对象的年份
print("月:", today.month) # 返回today对象的月份
print("日:", today.day) # 返回today对象的日
print("星期:", today.weekday()) # 0代表星期一,类推
print("公历序数:", today.toordinal()) # 返回公历日期的序数
print("年/周数/星期:", today.isocalendar()) # 返回一个元组:一年中的第几周,星期几结果:
- date类中时间和时间戳的转换:
(1)toordinal方法返回的公历序数转化为日期
import datetime
today = datetime.datetime.now()
# 此方法的返回类型是一个数字,它是该日期在公历中的序数。
num = today.toordinal()
print(num)
print(today.fromordinal(num))结果:

(2)time模块时间戳转化日期
import datetime
import time
nowtime = time.time()
print(nowtime)
nowdate = datetime.date.fromtimestamp(nowtime)
print(nowdate)结果:

(3)格式化时间,格式参照time模块中的strftime方法
import datetime
today = datetime.date.today()
print(today)
print(today.strftime("%Y.%m.%d"))
print(today.strftime("%Y:%m:%d"))
print(today.strftime("%Y.%m.%d %H:%M:%S"))结果:

- 修改日期使用replace方法
import datetime
# 当前日期
date1 = datetime.date.today()
print(date1)
# 指定日期
date2 = datetime.date(2022, 10, 7)
print(date2)
# 不带参数修改日期
date3 = date2.replace(2022, 10, 8)
print(date3)
# 带参数修改日期
date4 = date2.replace(month=12, day=9)
print(date4)结果:

time:时间类
常用属性:hour/minute/second/microsecond
time类生成time对象,包含hour、minute、second、microsecond属性
import datetime
# time对象
print(datetime.time)
# 格式化time
time1 = datetime.time(18, 30, 59, 59)
print(time1)
print(time1.hour)
print(time1.minute)
print(time1.second)
print(time1.microsecond) # 微秒结果:

datetime:日期时间类
datetime类包含date类和time类的全部信息
import datetime
print(datetime.datetime.today())
print(datetime.datetime.now())
print(datetime.datetime.utcnow()) # 返回当前UTC日期和时间的datetime对象
print(datetime.datetime.fromtimestamp(1670582201)) # 时间戳的datetime对象
print(datetime.datetime.fromordinal(738498))
print(datetime.datetime.strptime("2020-12-25", "%Y-%m-%d"))结果:

timedelta:时间间隔,即两个时间点之间的时间长度
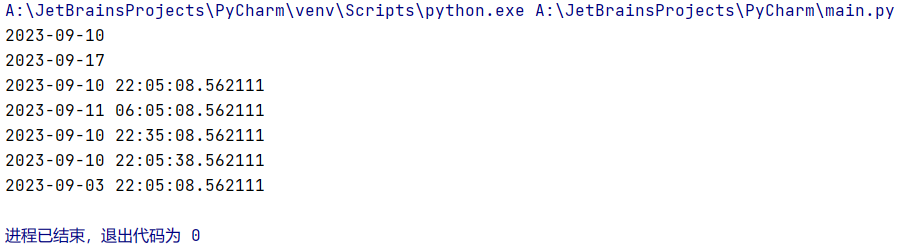
timedelta对象表示的是一个时间段,即两个日期date或者日期时间datetime之间的差;支持参数:weeks、days、hours、minutes、seconds、milliseconds、microseconds
import datetime
day = datetime.date.today()
# 当前日期
print(day)
# 增加7天后日期
print(day+datetime.timedelta(days=7))
# 时间操作
now = datetime.datetime.now()
# 当前日期时间
print(now)
# 增加8小时
print(now+datetime.timedelta(hours=8))
# 增加30分钟
print(now+datetime.timedelta(minutes=30))
# 增加30秒钟
print(now+datetime.timedelta(seconds=30))
# 减去一星期
print(now-datetime.timedelta(weeks=1))结果:
时间模块
time.time()获取当前时间戳。时间戳: 现在的时间距1970年1月1日 0时0分0秒的毫秒值。秒的取值范围为0~61,考虑到闰一秒或闰两秒的情形。夏令时数字是布尔值,如果使用-1,表示未知的,那么使用mktime()可能得到正确的值。
Python中很多方法都将如下格式的元组作为时间参数:
time_uple = (2022, 1, 1, 0, 0, 0, 0, 0, 0,)
| 索引 | 属性 | 字段 | 值 |
|---|---|---|---|
| 0 | tm_year | 年 | 如2000,2022等 |
| 1 | tm_mon | 月 | 范围1-12 |
| 2 | tm_mday | 日 | 范围1-31 |
| 3 | tm_hour | 小时 | 范围0-23 |
| 4 | tm_min | 分钟 | 范围0-59 |
| 5 | tm_sec | 秒 | 0-61 (60-61 是闰秒) |
| 6 | tm_wday | 星期 | 范围0-6 (0表示周一) |
| 7 | tm_yday | 儒略日 | 1到366 |
| 8 | tm_isdst | 夏令时 | 0、1或-1 |
| N/A | tm_zone | 时区 | 时区名称的缩写 |
| N/A | tm_gmtoff | UTC东偏 | 以秒为单位 |
time.strftime()来格式化时间,参数1为字符串,它指定了时间的格式。
| 格式 | 描述 |
|---|---|
| %a | 本地化的缩写星期中每日的名称。 |
| %A | 本地化的星期中每日的完整名称。 |
| %b | 本地化的月缩写名称。 |
| %B | 本地化的月完整名称。 |
| %c | 本地化的适当日期和时间表示。 |
| %d | 十进制数 [01,31] 表示的月中日。 |
| %H | 十进制数 [00,23] 表示的小时(24小时制)。 |
| %I | 十进制数 [01,12] 表示的小时(12小时制)。 |
| %j | 十进制数 [001,366] 表示的年中日。 |
| %m | 十进制数 [01,12] 表示的月。 |
| %M | 十进制数 [00,59] 表示的分钟。 |
| %p | 本地化的 AM 或 PM 。 |
| %S | 十进制数 [00,61] 表示的秒。 |
| %U | 十进制数 [00,53] 表示的一年中的周数(星期日作为一周的第一天)。 在第一个星期日之前的新年中的所有日子都被认为是在第 0 周。 |
| %w | 十进制数 [0(星期日),6] 表示的周中日。 |
| %W | 十进制数 [00,53] 表示的一年中的周数(星期一作为一周的第一天)。 在第一个星期一之前的新年中的所有日子被认为是在第 0 周。 |
| %x | 本地化的适当日期表示。 |
| %X | 本地化的适当时间表示。 |
| %y | 十进制数 [00,99] 表示的没有世纪的年份。 |
| %Y | 十进制数表示的带世纪的年份。 |
| %z | 十进制带符号数[-1200,+1200]表示时区。 |
| %Z | 时区名称。 |
例:
# time模块的使用
import time
nowTimeMillis = time.time()
time_tuple = (2022, 1, 1, 0, 0, 0, 0, 0, 0,)
print(nowTimeMillis) # 若想把时间格式化 可用下面的方法 第一个参数是格式化的字符串 第二个是时间元组
print('格式化的时间:', time.strftime('%Y-%m-%d %H:%M:%S', time_tuple))运行结果:
1665753500.0550375
格式化的时间: 2022-01-01 00:00:00Python连接数据库
连接SQLite
Python连接sqlite数据库不需要下载模块,Python内置了sqlite3模块。 连接SQLite的步骤
- 导入模块
import sqlite3
print(sqlite3)
---
<module 'sqlite3' from 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python310\\lib\\sqlite3\\__init__.py'>- 获取连接对象
conn = sqlite3.connect("user.db")
print(conn)
---
<sqlite3.Connection object at 0x0000025E6CF5F440>- 获取游标对象
cursor = conn.cursor()
print(cursor)
---
<sqlite3.Cursor object at 0x0000025E6C397F40>- 进行数据库操作
cursor.execute("create table if not exists user (id int not null primary key ,name varchar(20) not null)")
---
<sqlite3.Cursor at 0x25e6c397f40>- 若对数据库进行修改在关闭连接对象之前要提交事务,最后关闭游标对象和连接对象
cursor.close()
conn.close()操作SQLite的数据
- 插入数据
import sqlite3
## 向数据库中添加数据 需要使用游标对象的execute()方法
conn = sqlite3.connect('user.db')
cursor = conn.cursor()
# 接下来就是执行添加语句了 假如我们添加三行数据
# 使用游标对象的execute()方法执行查询语句 实际上这些操作都是使用游标对象的execute方法执行sql语句实现的
cursor.execute('insert into user (id ,name) values(1,"小明"),(2,"小红"),(3,"小蓝")')
cursor.execute('select * from user')
# 在执行sql查询后 使用游标对象的fetchXXX()方法执行想要查询的结果的数量
result = cursor.fetchall()
# 该方法会返回一个集合 集合内的元素是数组 存储查询到的数据
print(result)
# 最后还是要关闭游标对象和连接对象 还要提交事务
cursor.close()
conn.commit()
conn.close()
---
[(1, '小明'), (2, '小红'), (3, '小蓝')]- 修改数据
import sqlite3
### 修改数据库中的数据 还是需要使用游标对象的execute()方法
conn = sqlite3.connect('user.db')
cursor = conn.cursor()
# 接下来就是执行修改语句了 假如我们将id为2的人的名字修改为小青
# 使用游标对象的execute()方法执行查询语句 实际上这些操作都是使用游标对象的execute方法执行sql语句实现的
cursor.execute('update user set name = "小青" where id = 2')
cursor.execute('select * from user')
# 在执行sql查询后 使用游标对象的fetchXXX()方法执行想要查询的结果的数量
result = cursor.fetchall()
# 该方法会返回一个集合 集合内的元素是数组 存储查询到的数据
print(result)
# 最后还是要关闭游标对象和连接对象 还要提交事务
cursor.close()
conn.commit()
conn.close()
---
[(1, '小明'), (2, '小青'), (3, '小蓝')]- 删除数据
import sqlite3
# 删除数据库中的数据 还是需要使用游标对象的execute()方法
conn = sqlite3.connect('user.db')
cursor = conn.cursor()
# 接下来就是执行添加语句了 假如我们添加三行数据
# 使用游标对象的execute()方法执行查询语句 实际上这些操作都是使用游标对象的execute方法执行sql语句实现的
cursor.execute('delete from user where id = 1')
cursor.execute('select * from user')
# 在执行sql查询后 使用游标对象的fetchXXX()方法执行想要查询的结果的数量
result = cursor.fetchall()
# 该方法会返回一个集合 集合内的元素是数组 存储查询到的数据
print(result)
# 最后还是要关闭游标对象和连接对象 还要提交事务
cursor.close()
conn.commit()
conn.close()
---
[(2, '小青'), (3, '小蓝')]连接MySQL
首先需要安装pymysql模块,若可以导入则安装成功。 Python连接数据库的步骤:
- 导入pymysql模块
import pymysql- 获取连接对象 使用
connect()方法连接MySQL 建议使用关键字指定参数
conn = pymysql.connect(user='root', # 用户名
password="254456", # 密码
host='localhost') # 主机- 获取游标对象 使用连接对象的
cursor()方法
cursor = conn.cursor()- 通过调用cursor对象的
execute()方法操作数据库 方法的参数就是要执行的SQL语句
cursor.execute('show databases;')- 使用cursor对象的
fetchXXX()方法获取结果集 这里使用fetchall()
result = cursor.fetchall()
print(result)
---
(('db_admin',), ('information_schema',), ('mysql',), ('performance_schema',), ('sys',))- 最后关闭cursor和conn对象。
cursor.close()
conn.close()因为操作MySQL和操作SQLite的方式很接近,这里就不再演示了。
修改MySQL的数据
下方为连接数据库的操作,具体请看连接数据库的笔记。
import pymysql
conn = pymysql.connect(user='root',
password="254456",
host='localhost',)
print('conn:连接成功')
cursor = conn.cursor()
cursor.execute('create database if not exists db;')
cursor.execute('use db;')
cursor.execute('drop table if exists tb;')
cursor.execute('create table tb (id int,name varchar(10),date date);')
cursor.execute('insert into tb (id,name,date) values (1,"a",now()),(2,"b",now()),(3,"c",now());')
print('cursor:创建数据表成功')
---
conn:连接成功
cursor:创建数据表成功- 添加数据
cursor.execute('insert into tb (id,name,date) values(4,"d",now())')
cursor.execute('select * from tb')
result = cursor.fetchall()
print(result)
---
((4, 'd', datetime.date(2022, 10, 14)), (4, 'd', datetime.date(2022, 10, 14)), (4, 'd', datetime.date(2022, 10, 14)), (4, 'd', datetime.date(2022, 10, 14)))- 修改数据
cursor.execute('update tb set name = "e" where id = 2')
cursor.execute('select * from tb')
result = cursor.fetchall()
print(result)
conn.commit() # 凡是涉及到更改数据表的操作最后都要提交事务
---
((4, 'd', datetime.date(2022, 10, 14)), (4, 'd', datetime.date(2022, 10, 14)), (4, 'd', datetime.date(2022, 10, 14)), (2, 'e', datetime.date(2022, 10, 9)), (4, 'd', datetime.date(2022, 10, 14)))- 删除数据
cursor.execute('delete from tb where id = 3')
cursor.execute('select * from tb')
result = cursor.fetchall()
print(result)
conn.commit()
---
((4, 'd', datetime.date(2022, 10, 14)), (4, 'd', datetime.date(2022, 10, 14)), (4, 'd', datetime.date(2022, 10, 14)), (1, 'a', datetime.date(2022, 10, 8)), (2, 'e', datetime.date(2022, 10, 9)), (4, 'd', datetime.date(2022, 10, 14)))# 关闭
cursor.close()
conn.close()爬虫
Python提供了很多爬取网页的模块,如Python自带的urllib模块和urllib升级版的urllib3。除此外,还有requests模块和Scrapy模块也可以爬取网页。这里简要介绍一下requests模块。
requests模块基础
requests模块是由一位民间大神开发出来的一个极为强大的爬虫模块,使用此模块之前要先安装它。
使用requests模块爬取网页非常简单,只需要导入模块,然后再向服务器中发送get或post请求,然后处理响应即可。
例:
import requests
response = requests.get('https://www.baidu.com')
print(response.content.decode('utf8'))运行结果:
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');
</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>设置头部信息
如在爬取网页的时候返回的响应为403,就代表网页设置了访问机制,拒绝爬虫发送的请求立了,这种情况我们可以通过设置头部信息模拟该请求是由浏览器发出的而不是由爬虫发出的,网页就可以返回正常响应了。
例:
import requests
url = 'https://movie.douban.com'
response = requests.get(url)
print(response.content)
# 创建头部信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.70'}
response = requests.get(url, headers=headers)
print(response.content.decode('utf8'))由于运行成功,但返回的HTML代码过长,因此这里不写结果。
设置代理
代理服务在爬取被屏蔽的网站时确实是一个解决方案。通常,你可以通过使用代理服务器来隐藏你的真实 IP 地址,从而避免被服务器屏蔽。
要使用代理服务,你需要首先获取代理服务器的 IP 地址和端口号。例如,如果代理服务器的 IP 地址是 122.114.31.177,端口号是 808,那么完整的代理地址可能是 http://122.114.31.177:808 或 https://122.114.31.177:808。
在使用代理服务时,需要格外注意代理 IP 的有效性。如果代理 IP 过时或失效,可能会导致爬取失败。因此,最好在使用代理服务时添加异常处理机制,以便及时处理代理 IP 失效的情况。
例:
import requests
proxy = {
'http': 'http://http://61.154.21.249:16824',
'https': 'https://https://61.154.21.249:16824'}
response = requests.get('https://www.baidu.com/', proxies=proxy)
print(response.content.decode('utf8'))
# 查找免费代理ip的步骤这里不再详述了设置超时时间
若爬虫爬取时间过长不想再等待就可以设置超时。
例:
# 网络超时
import requests
time = 0.05 # 设置超时时间为0.05秒 具体要依据网页的大小和网速合理调整
url = 'https://www.baidu.com'
for i in range(0, 50):
try:
response = requests.get(url, timeout=time)
print('第%s次尝试: %s' % (i, response.status_code))
except Exception as e:
print('发生超时: ', str(e))
# 另外 requests模块还提供了以下三个常用异常类
from requests import ReadTimeout, HTTPError, requestsException
try:
pass
except ReadTimeout: # 超时异常
pass
except HTTPError: # HTTP 异常
pass
except requestsException: # 请求异常
pass运行结果:
发生超时: HTTPSConnectionPool(host='www.baidu.com', port=443): Read timed out. (read timeout=0.05)
第1次尝试: 200
发生超时: HTTPSConnectionPool(host='www.baidu.com', port=443): Read timed out. (read timeout=0.05)
发生超时: HTTPSConnectionPool(host='www.baidu.com', port=443): Read timed out. (read timeout=0.05)
发生超时: HTTPSConnectionPool(host='www.baidu.com', port=443): Read timed out. (read timeout=0.05)
第5次尝试: 200
发生超时: HTTPSConnectionPool(host='www.baidu.com', port=443): Read timed out. (read timeout=0.05)
发生超时: HTTPSConnectionPool(host='www.baidu.com', port=443): Read timed out. (read timeout=0.05)
第8次尝试: 200
第9次尝试: 200
发生超时: HTTPSConnectionPool(host='www.baidu.com', port=443): Read timed out. (read timeout=0.05)
第11次尝试: 200
第12次尝试: 200
第13次尝试: 200
第14次尝试: 200
发生超时: HTTPSConnectionPool(host='www.baidu.com', port=443): Read timed out. (read timeout=0.05)
发生超时: HTTPSConnectionPool(host='www.baidu.com', port=443): Read timed out. (read timeout=0.05)
发生超时: HTTPSConnectionPool(host='www.baidu.com', port=443): Read timed out. (read timeout=0.05)
第18次尝试: 200
第19次尝试: 200
发生超时: HTTPSConnectionPool(host='www.baidu.com', port=443): Read timed out. (read timeout=0.05)
第21次尝试: 200
第22次尝试: 200
发生超时: HTTPSConnectionPool(host='www.baidu.com', port=443): Read timed out. (read timeout=0.05)
发生超时: HTTPSConnectionPool(host='www.baidu.com', port=443): Read timed out. (read timeout=0.05)
发生超时: HTTPSConnectionPool(host='www.baidu.com', port=443): Read timed out. (read timeout=0.05)
发生超时: HTTPSConnectionPool(host='www.baidu.com', port=443): Read timed out. (read timeout=0.05)
第27次尝试: 200
发生超时: HTTPSConnectionPool(host='www.baidu.com', port=443): Read timed out. (read timeout=0.05)
...解析HTML代码
解析HTML代码包含获取标题、获取指定标签内容等。
要解析 HTML 代码,首先需要导入 bs4 模块,因为 BeautifulSoup 已经被内置在了其中。然后,我们需要安装解析器 lxml。接下来,我们可以从其他网页获取 HTML 代码,然后将其传递给 BeautifulSoup 对象进行解析。
例:
import requests
from bs4 import BeautifulSoup
url = 'https://www.baidu.com'
response = requests.get(url).content
result = BeautifulSoup(response, features='lxml')
print('此网站的标题是: ', result.title)
# 还可以解析本地HTML代码
# file = open('demo.html', encoding='utf8')
# result = BeautifulSoup(file, 'lxml')
# print(result.prettify()) # prettify()方法会把代码格式化
# print(result.find('meta')) # find()方法返回参数要求的html内容运行结果:
此网站的标题是: <title>百度一下,你就知道</title>多进程和多线程
多进程
创建进程有多种方法,主要包括使用 multiprocessing 包下的 Process 类、multiprocessing 包下的 multiprocessing 类以及使用进程池 Pool 类。让我们来简单介绍一下这三种方法:
- 使用
multiprocessing包下的Process类:这种方法是直接使用Process类来创建进程。你可以实例化Process类,并传入要执行的函数和函数所需的参数,然后调用start()方法启动进程。 - 使用
multiprocessing包下的multiprocessing类:这种方法是使用multiprocessing类的Process方法来创建进程。你可以调用multiprocessing.Process()方法,并传入要执行的函数和函数所需的参数,然后调用start()方法启动进程。 - 使用进程池
Pool类:这种方法是使用multiprocessing包下的Pool类来创建进程池,然后通过Pool类的apply_async()或map()方法来异步或同步地执行多个函数。进程池会管理一组工作进程,可以根据需要动态创建、重用和销毁进程。
使用Process类
Process 类是 multiprocessing 包中用于创建进程的类,它提供了一些常用的属性和方法:
is_alive(): 判断进程实例是否还在执行。join([timeout]): 等待进程实例执行结束,或等待多少秒(可选参数 timeout)。start(): 启动进程实例。run(): 若进程对象没有给定target参数,在调用start()方法时将执行该对象中的run()方法。terminate(): 不管任务是否完成,立即终止进程。name: 当前进程实例的别名,默认是Process-N,其中 N 是一个自动生成的数字。pid: 当前进程的进程 ID(PID)值。
可以通过实例化Process类,将target参数赋值为进程要运行的函数,然后调用start方法启动线程。
例:
# 使用Process类创建多线程
import os
import time
from multiprocessing import Process
def fun(args):
print('子进程开始,子进程的参数是:', args)
time.sleep(1)
print('子进程结束')
if __name__ == '__main__':
print('主进程开始执行')
print('主进程的pid:', os.getpid())
process1 = Process(target=fun, args=('我是子线程的参数',)) # Process类的构造方法可加target参数 意为线程执行的函数 还可以传递一个元组 意为传递到函数的参数
process1.start() # 开启子进程运行结果:
主线程开始执行
主线程的pid: 95552
子线程开始,子进程的参数是: 我是子线程的参数
子线程结束还可以继承Process类,然后实现run方法,最后调用start方法启动进程。
例:
# 继承至Process类
import os
import time
from multiprocessing import Process
class MyProcess(Process):
def __init__(self, name='', interval=0):
super().__init__()
self.interval = interval
if name:
self.name = name
def run(self):
print('子进程%s开始执行,它的名字为%s,它的父进程是%s' % (os.getpid(), self.name, os.getppid()))
time.sleep(self.interval)
print('子进程%s结束' % (os.getpid(),))
if __name__ == '__main__':
print('主进程开始,它的pid为%s' % os.getpid())
print('主进程的名称为%s' % os.name)
myProcess1 = MyProcess(interval=1)
myProcess2 = MyProcess('子进程2', interval=2)
myProcess1.start()
myProcess2.start()运行结果:
主进程开始,它的pid为96316
主进程的名称为nt
子进程98308开始执行,它的名字为MyProcess-1,它的父进程是96316
子进程96364开始执行,它的名字为子进程2,它的父进程是96316
子进程98308结束
子进程96364结束使用进程池Pool
若多个进程的目标函数是相同的,就可以直接使用进程池而不用实例化多个Process对象。
例:
# 使用进程池Pool创建进程
import os
import time
from multiprocessing import Pool
def task(name):
print('子进程%s开始执行任务%s' % (os.getpid(), name))
time.sleep(1)
if __name__ == '__main__':
print('父进程%s开始' % (os.getpid(),))
p = Pool(3) # 创建进程池 最多可以同时执行3个任务
for i in range(10):
p.apply_async(task,args=(i,)) # 使用非阻塞方式调用task函数
p.close() # 关闭进程池
p.join() # 主进程等待所有子进程结束再开始执行
print('所有子进程结束')
# apply() 使用阻塞方式调用函数
# terminate() 不管任务是否完成 立即终止运行结果:
父进程83920开始
子进程104952开始执行任务0
子进程106376开始执行任务1
子进程108372开始执行任务2
子进程104952开始执行任务3
子进程106376开始执行任务4
子进程108372开始执行任务5
子进程104952开始执行任务6
子进程108372开始执行任务7
子进程106376开始执行任务8
子进程104952开始执行任务9
所有子进程结束进程间通信
多线程之间的通信常常需要使用队列来进行数据的共享,Python 提供了 queue 模块来实现线程安全的队列操作。队列的特点是先进先出,即在队尾添加元素,在队头取出元素。
下面是队列的常用方法:
qsize(): 返回队列中剩余的消息数量。empty(): 若队列为空则返回True,否则返回False。full(): 若队列已满则返回True,否则返回False。put(item[, block[, timeout]]): 在队列末尾添加一个新元素。如果block参数使用默认值且没有设置等待时间timeout,若队列已满则会阻塞程序,直到队列有空间放入消息为止;若设置了timeout,则在超出等待时长后会抛出Queue.Full异常。若block参数为False且消息队列已满,则会立即抛出Queue.Full异常。put_nowait(item): 相当于put(item, False)。get([block[, timeout]]): 取出队列的第一个元素。如果block参数使用默认值且没有设置等待时间timeout,若队列为空则会阻塞程序,直到队列读取到消息为止;若设置了timeout,则在超出等待时长后会抛出Queue.Empty异常。若block参数为False且消息队列为空,则会立即抛出Queue.Empty异常。get_nowait(): 相当于get(False)。
例:
from multiprocessing import Queue
if __name__ == '__main__':
q = Queue(3) # 创建一个可以容纳三个元素的队列
print('队列是否为空:%s' % q.empty())
q.put('消息1')
q.put('消息2')
print('队列是否满了:%s' % q.full())
q.put('消息3')
print('队列是否满了:%s' % q.full())
# 下面尝试添加第四个元素
try:
q.put('消息4', True, 2) # 等待两秒
except ValueError:
print('消息已满 当前消息数量为%s' % q.qsize())
try:
q.put_nowait('消息4') # 等待两秒
except ValueError:
print('消息已满 当前消息数量为%s' % q.qsize())
if not q.empty():
print('--读取消息--')
for i in range(q.qsize()):
print(q.get())
# 此时取出全部消息 队列为空 再添加时就不会报错
if not q.empty():
q.put('消息4')
print('现在的队列长度为%s' % q.qsize())运行结果:
队列是否为空:True
队列是否满了:False
队列是否满了:True
Traceback (most recent call last):
File "A:\pythonProject\src\MultiprocessAndMultithreads\queue\useQueue.py", line 26, in <module>
q.put('消息4', True, 2) # 等待两秒
^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\Qi\AppData\Local\Programs\Python\Python311\Lib\multiprocessing\queues.py", line 90, in put
raise Full
queue.Full多线程
创建多线程可以使用 Thread 类。下面是 Thread 类的构造函数参数:
group: 值为None,为将来版本保留。target: 线程执行时运行的目标函数。如果为空,则在线程启动时会执行run方法。name: 线程的别名,默认为Thread-N,其中N是自动生成的数字。args: 传递给target函数的参数列表。kwargs: 传递给target函数的字典列表。
例:
import threading
import time
from threading import Thread
def task():
for i in range(3):
time.sleep(1)
print('当前线程的名字:%s' % threading.current_thread().name)
if __name__ == '__main__':
print('主线程开启')
threads = [Thread(target=task) for i in range(4)]
for t in threads:
t.start()
for t in threads:
t.join()
print('主线程结束')运行结果:
主线程开启
当前线程的名字:Thread-1 (task)
当前线程的名字:Thread-3 (task)
当前线程的名字:Thread-2 (task)
当前线程的名字:Thread-4 (task)
当前线程的名字:Thread-3 (task)
当前线程的名字:Thread-2 (task)
当前线程的名字:Thread-4 (task)
当前线程的名字:Thread-1 (task)
当前线程的名字:Thread-3 (task)
当前线程的名字:Thread-4 (task)
当前线程的名字:Thread-2 (task)
当前线程的名字:Thread-1 (task)
主线程结束锁
由于进程之间数据是互通的,若在一个线程中对数据的读取或更改还未完成时另外一个线程对这个数据进行更改的话会出现错误,如车站购票,购买的过程是先判断是否票数是否大于0,然后再将票数减一。若这两个线程是同时判断票数是否大于0,而此时票数只有一,那么这两个线程都会将票数减一,结果就是票数变成了负数。因此为了在一个线程尚未完成对数据的操作之前其他线程不能操作该数据,就会将该数据锁起来,这就是锁机制。
使用锁需要导入multiprocessing模块下的Mutex类,需要上锁时使用acquire()方法锁住资源,需要解锁时使用release()方法解锁资源。
例:
import random
import threading
import time
from threading import Thread, Lock
n = 15 # 代表总的资源
def task():
global n
mutex.acquire()
if n > 0:
time.sleep(random.random() * 0.1)
n -= 1
print('子线程%s获取一次资源, 剩余资源%d' % (threading.current_thread().name, n))
mutex.release()
if __name__ == '__main__':
mutex = Lock()
print('--主线程开始--')
# 共有20个线程取总计15个资源
threadList = [Thread(target=task, name='Thread-' + str(i)) for i in range(20)]
for i in threadList:
i.start()
for i in threadList:
i.join()
print('--所有子线程结束--')运行结果:
--主线程开始--
子线程Thread-0获取一次资源, 剩余资源14
子线程Thread-1获取一次资源, 剩余资源13
子线程Thread-2获取一次资源, 剩余资源12
子线程Thread-3获取一次资源, 剩余资源11
子线程Thread-4获取一次资源, 剩余资源10
子线程Thread-5获取一次资源, 剩余资源9
子线程Thread-6获取一次资源, 剩余资源8
子线程Thread-7获取一次资源, 剩余资源7
子线程Thread-8获取一次资源, 剩余资源6
子线程Thread-9获取一次资源, 剩余资源5
子线程Thread-10获取一次资源, 剩余资源4
子线程Thread-11获取一次资源, 剩余资源3
子线程Thread-12获取一次资源, 剩余资源2
子线程Thread-13获取一次资源, 剩余资源1
子线程Thread-14获取一次资源, 剩余资源0
--所有子线程结束--而将上锁和解锁的代码注释掉之后的运行结果:
--主线程开始--
子线程Thread-19获取一次资源, 剩余资源14
子线程Thread-4获取一次资源, 剩余资源13
子线程Thread-16获取一次资源, 剩余资源12
子线程Thread-14获取一次资源, 剩余资源11
子线程Thread-3获取一次资源, 剩余资源10
子线程Thread-17获取一次资源, 剩余资源9
子线程Thread-1获取一次资源, 剩余资源8
子线程Thread-12获取一次资源, 剩余资源7
子线程Thread-8获取一次资源, 剩余资源6
子线程Thread-2获取一次资源, 剩余资源5
子线程Thread-10获取一次资源, 剩余资源4
子线程Thread-7获取一次资源, 剩余资源3
子线程Thread-11获取一次资源, 剩余资源2
子线程Thread-15获取一次资源, 剩余资源1
子线程Thread-5获取一次资源, 剩余资源0
子线程Thread-6获取一次资源, 剩余资源-1
子线程Thread-0获取一次资源, 剩余资源-2
子线程Thread-18获取一次资源, 剩余资源-3
子线程Thread-13获取一次资源, 剩余资源-4
子线程Thread-9获取一次资源, 剩余资源-5
--所有子线程结束--线程间通信
线程的数据是共享的可以直接读取,如上面的代码中使用global关键字修饰的全局变量n就是在20个子线程中共享的。除此之外,也可以使用队列通信。
例:
# 使用queue模块的Queue类实现多线程通信 模拟生产者与消费者模式
from threading import Thread
from queue import Queue
import time, random
class Producer(Thread):
def __init__(self, name, queue1):
super().__init__(name=name)
self.queue = queue1
def run(self) -> None:
for i in range(5):
time.sleep(random.random())
self.queue.put(i)
print('%s将产品%d放入队列中' % (self.name, i))
class Consumer(Thread):
def __init__(self, name, queue1):
super().__init__(name=name)
self.queue = queue1
def run(self) -> None:
for i in range(5):
time.sleep(random.random())
value = self.queue.get()
print('%s将产品%d从队列中取出' % (self.name, value))
if __name__ == '__main__':
print('--主线程开始--')
queue = Queue()
p = Producer('生产者', queue)
p.start()
time.sleep(random.random())
c = Consumer('消费者', queue)
c.start()
p.join()
c.join()
print('--主线程结束--')运行结果:
--主线程开始--
生产者将产品0放入队列中
消费者将产品0从队列中取出
生产者将产品1放入队列中
消费者将产品1从队列中取出
生产者将产品2放入队列中
消费者将产品2从队列中取出
生产者将产品3放入队列中
生产者将产品4放入队列中
消费者将产品3从队列中取出
消费者将产品4从队列中取出
--主线程结束--网络编程
socket套接字简介
使用套接字(socket)进行网络通信的步骤如下:
一、实例化服务器套接字和客户端套接字对象。
二、服务器套接字首先使用 bind() 方法绑定 IP 地址和端口,然后使用 listen() 方法进行监听。
三、客户端使用 connect() 方法请求连接到服务器,而服务器使用 accept() 方法请求接受来自客户端的连接。
四、现在可以进行数据的互相发送了。假设服务器想要向客户端发送数据,那么服务器的一个进程首先使用 send() 方法向客户端发送数据。然后客户端需要有一个进程来接收来自服务器的数据,这样就完成了一个数据的传递。由于服务器和客户端都是多进程的,因此可以频繁地进行数据传输。
五、最后是断开连接。客户端使用 close() 方法关闭套接字,服务器也使用 close() 方法关闭套接字,因为它们都是 socket 对象。服务器关闭之后就不会再使用 accept() 方法接收其他连接了。
socket模块常用方法
s.bind(): 将地址(IP 地址和端口号)绑定到套接字。在 AF_INET 地址族中,地址以(ip, port)的元组形式表示。s.listen(backlog): 开启 TCP 监听。backlog参数指定操作系统在拒绝连接之前允许挂起的最大连接数,最少为 1,大多数情况下为 5。s.accept(): 被动接收 TCP 客户端连接,并以阻塞方式等待连接请求。该方法返回已经建立连接的套接字对象。s.connect(address): 主动向 TCP 服务器发起连接。address是以(ip, port)元组表示的地址。如果连接失败,会抛出socket.error错误。s.recv(bufsize[, flag]): 接收 TCP 数据。数据以字符串形式返回,需要解码。bufsize参数指定要接收的最大数据量,flag提供与数据相关的信息,通常可省略。s.send(bytes): 发送 TCP 数据。数据以字节码形式发送,如果是字符串需要进行编码。返回值是发送的字节数,可能小于发送信息的大小。s.sendall(bytes): 完整发送 TCP 数据。在返回之前尝试发送所有数据,成功返回None,错误则抛出异常。s.recvfrom(bufsize): 接收 UDP 数据。与recv()类似,但返回的是(data, addr)元组,其中data是返回的数据,addr是发送数据的套接字地址。s.sendto(bytes, address): 发送 UDP 数据。address是以(ip, port)形式表示的元组,指定远程地址。返回值是要发送的字节数。s.close(): 关闭套接字。
TCP程序
在运行 TCP 程序时,通常的顺序是这样的:
首先,服务器先运行。服务器需要绑定 IP 地址和端口,并设置连接的最大数量。
然后,客户端运行。客户端尝试连接服务器。
一旦连接建立成功,服务器和客户端之间就可以进行通信了。
最后,需要关闭服务器和客户端。
常用的是 socket 模块的 socket() 方法。这个方法有两个参数:
第一个参数是
AddressFamily,它代表进行通信的设备。如果是AF_INET,则代表两个计算机之间的通信;如果是AF_UNIX,则代表自己通信。第二个参数是
Type,它代表套接字类型。如果是SOCK_STREAM,代表 TCP 协议;如果是SOCK_DGRAM,代表 UDP 协议。
通过调用 socket() 方法获得一个套接字对象后,就可以使用这个套接字对象进行网络编程了。
浏览器连接到Python服务器
连接步骤请看代码的注释。此段代码运行之后浏览器中输入127.0.0.1:8998后就可以看到浏览器中接收到了Hello World。
# 此文件作为服务器 让浏览器输入连接访问此服务器并尝试通信 同时本文件也是网络编程的第一步
import socket # 导入socket模块
socket = socket.socket() # 使用socket模块的socket()函数创建
socket.bind(('127.0.0.1', 8998)) # 绑定IP地址和端口号
socket.listen(2) # 设置最大监听数量
conn, addr = socket.accept() # 使用套接字对象的accept()方法接收来自客户端的连接 该方法返回一个元组 第一个是连接对象 第二个是地址
conn.sendall(b'HTTP/1.1 200 OK\r\n\r\nHello World!') # 向客户端发送信息
message = conn.recv(1024).decode() # 接收来自浏览器的返回信息 若不接收则浏览器会提示服务器拒绝连接
print(message) # 打印浏览器返回的信息
conn.close() # 关闭连接对象
socket.close() # 关闭套接字
# 最后提示一下 要先运行此文件启动服务器 然后才能打开浏览器连接此服务器 地址是127.0.0.1:8998然后控制台的输出结果如下:
GET / HTTP/1.1
Host: 127.0.0.1:8998
Connection: keep-alive
sec-ch-ua: "Chromium";v="112", "Google Chrome";v="112", "Not:A-Brand";v="99"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
Upgrade-Insecure-requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9编写客户端和服务器
TCP 的优点在于传输质量高、安全可靠,因此被广泛使用。
TCP 程序的运行顺序通常如下:
- 服务器先运行。服务器需要绑定 IP 地址和端口,并设置连接的最大数量。
- 客户端运行。客户端尝试连接服务器。
- 连接成功后,服务器和客户端之间可以进行通信。
- 最后,需要关闭服务器和客户端。
常用的是 socket 模块的 socket() 方法。这个方法有两个参数:
- 第一个参数是
AddressFamily,它代表进行通信的设备。如果是AF_INET,则代表两个计算机之间的通信;如果是AF_UNIX,则代表自己通信。 - 第二个参数是
Type,它代表套接字类型。如果是SOCK_STREAM,代表 TCP 协议;如果是SOCK_DGRAM,代表 UDP 协议。
通过调用 socket() 方法获得一个套接字对象后,就可以使用这个套接字对象进行网络编程了。
具体请看代码:
# server.py
# 此文件演示如何使用TCP套接字实现网络通信 本文件为服务器 先运行
from socket import socket as soc # 导入模块使用套接字
ip = '127.0.0.1' # ip地址 实现本地计算机通信就用这个ip
port = 8080 # 端口
s = soc() # 创建套接字对象
s.bind((ip, port)) # 绑定IP地址和端口号
s.listen(1) # 设置最大连接数量
print('服务器等待连接...')
conn, addr = s.accept() # 建立连接 该方法返回一个元组 第一个元素是已经实现连接的套接字对象 第二个元素是套接字地址 可以用于发送信息
print('服务器连接成功\ns的信息:%s\nconn的信息:%s\naddr的信息:%s\n------' % (s, conn, addr))
conn.send(b'Hello!') # 使用已经连接的套接字对象的sendto()方法发送信息 第一个参数是字节码 第二个参数是要发送的地址
message = conn.recv(1024).decode() # 使用连接对象的recv()方法接收信息 参数是接收的最大字节数 由于接收过来的是字节码 因此还需要解码
print('服务器接收到来自客户端的消息: %s' % message)
conn.close()
s.close() # 关闭套接字# client.py
# 客户端 此文件后运行
from socket import socket as soc # 导入模块
ip = '127.0.0.1' # ip地址
port = 8080 # 端口号
s = soc() # 创建套接字对象
s.connect((ip, port)) # 客户端直接使用connect()方法即可 参数是一个元组 第一个元素是IP地址 第二个元素是端口号
print('连接成功 此时套接字的信息:%s' % s)
message = s.recv(1024).decode() # 接收消息 和服务器一样
print('接收到来自服务器的消息: %s' % message)
s.send(b'Hello!') # 也可以使用s.send('Hello').encode()发送
s.close() # 关闭套接字UDP
UDP 程序相比于 TCP 程序来说,设置连接方式更加简单,因为 UDP 是无连接的,不需要进行连接的建立和维护。
在使用 socket 对象时,只需要改变参数即可将连接方式设置为 UDP。具体而言,将套接字类型参数 Type 设置为 SOCK_DGRAM,即可使用 UDP 协议进行通信。
UDP 程序除了等待传入的连接外,几乎不需要做其他工作。这是因为 UDP 是无连接的,数据包之间的传输不需要建立连接,因此无需像 TCP 那样进行连接的建立和维护,也不需要像 TCP 那样处理连接的中断和重连。UDP 只需简单地发送和接收数据包,因此通常更加轻量和高效。
# server.py
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 服务器第一步 创建套接字对象 注意参数
s.bind(('127.0.0.1', 1234))
print('绑定端口完成')
data, addr = s.recvfrom(1024) # 第二步 接收数据 返回两个值:数据包和地址
print('服务器接收:%s' % data.decode())
message = 'Hello'
s.sendto(message.encode(), addr) # 第三步 发送数据
# 此时就用到了前面的地址 也就是说这个recvfrom()起到连接作用
print('服务器发送:%s' % message)
s.close()# client.py
import socket # 导入模块
ip = '127.0.0.1'
port = 1234
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 客户端第一步 创建套接字对象
message = 'Hi!'
s.sendto(message.encode(), (ip, port)) # 第二步 发送消息
print('客户端发送:%s' % message)
print('客户端接收:%s' % s.recvfrom(1024)[0].decode()) # 接收消息
s.close()版权所有
版权归属: