
外观
Django简介
Django
最新的Django已经支持异步。Django是当今最受欢迎的Python Web框架,拥有最大的社区和文档,许多知名的网站都是使用Django编写的。
安装Django框架
在venv环境中使用pip install django即可安装Django。
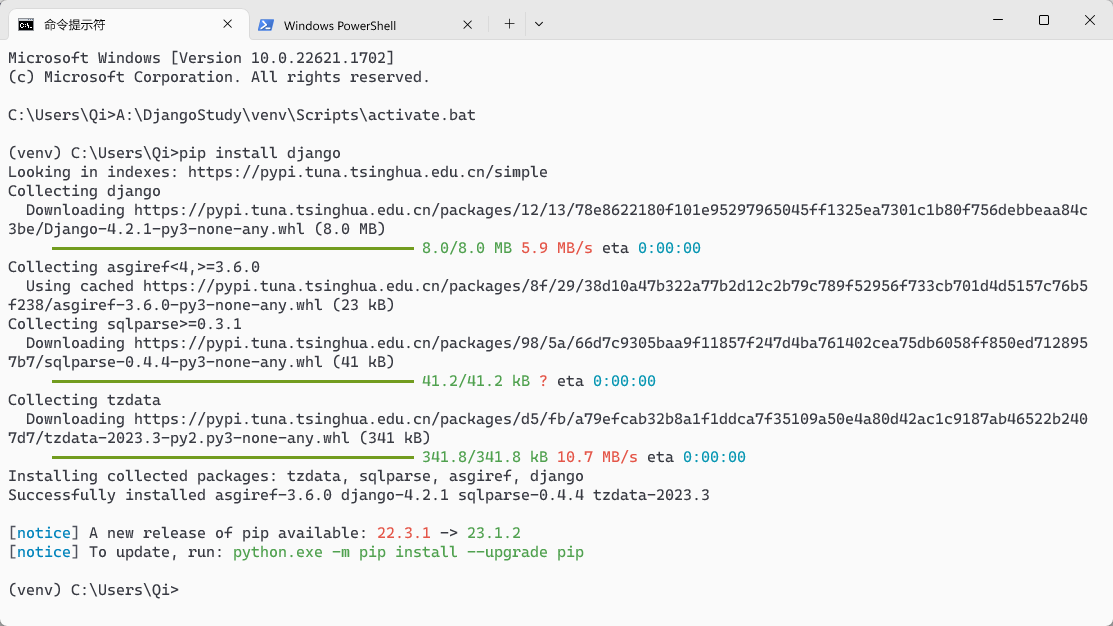
创建项目
在venv环境中使用django-admin创建项目,命令如下:
django-admin startproject blog运行此命令后不会有任何提示,Django会在用户文件夹下创建blog项目,我们将它移至项目文件夹中。
它的目录结构如下图。
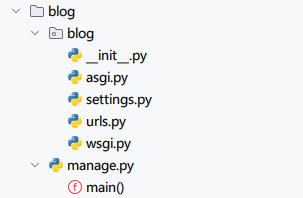
在生成的目录结构中,各个目录的作用如下表。
| 文件 | 说明 |
|---|---|
| manage.py | Django程序的入口,一个可以用各种方式管理Django项目的命令行工具 |
| blog/__init__.py | 一个空文件,告诉Python这个目录是一个Python包 |
| blog/asgi.py | 项目运行在ASGI兼容Web服务器的入口 |
| setting.py | Django的总配置文件,可以配置App、数据库、中间件、模板等诸多文件 |
| urls.py | Django默认的路由配置文件,可以在其中include其他路径的url.py |
| wsgi.py | Django实现的WSGI接口文件,用来处理Web请求 |
创建完项目以后,进入blog目录,使用如下命令运行项目。
python manage.py runserver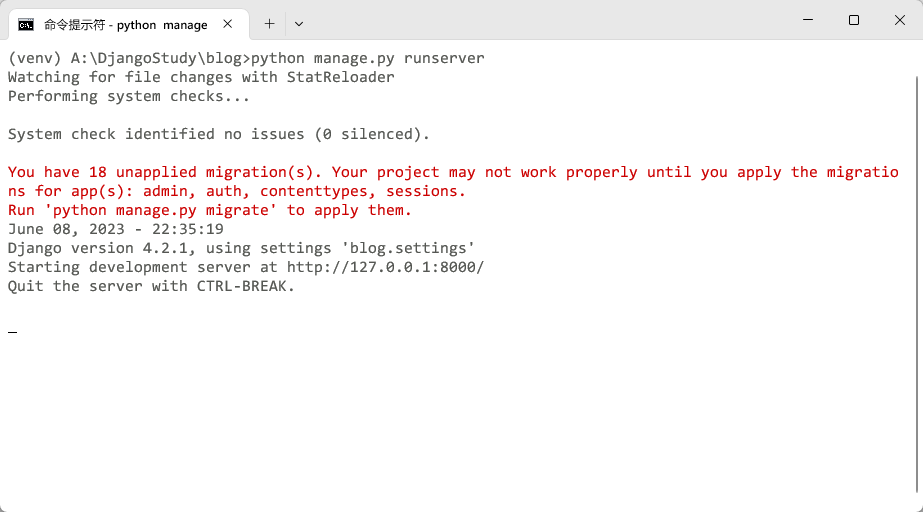
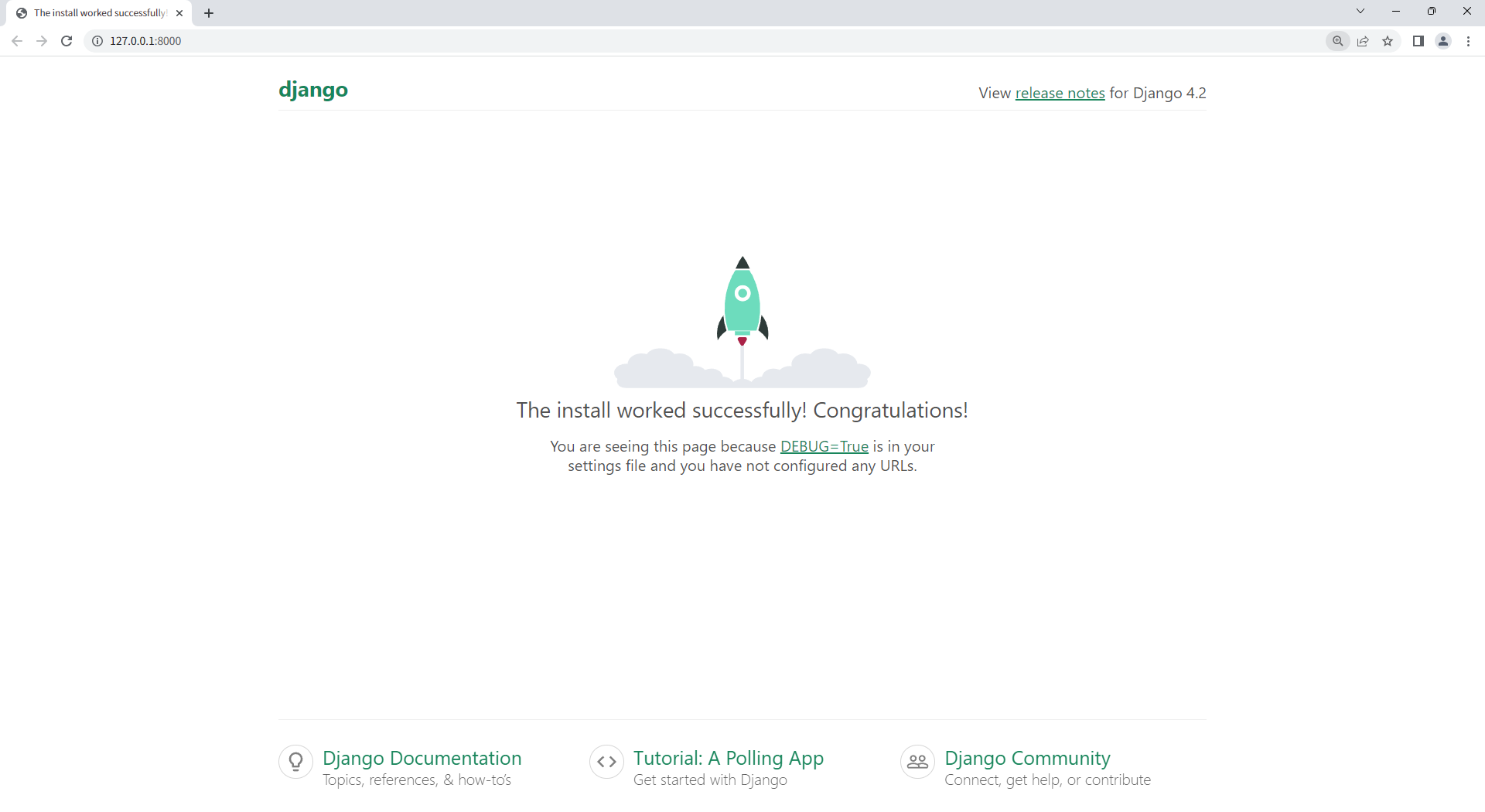
可以看到,服务器已经监听8000端口了。浏览器输入127.0.0.1:8000即可看到如下界面。
创建应用
在Django项目中,一般使用应用来完成不同的任务。一个应用在一个包中,并且遵循着相同的约定。Django自带的工具可以生成应用的基础目录结构。
创建一个应用非常简单,在服务关闭的情况下使用如下命令创建应用。
python manage.py startapp article运行此命令后没有提示,但是目录已经被创建。下面是目录的结构。
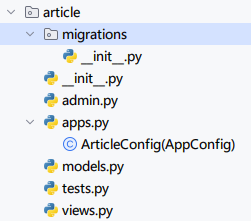
目录的说明如下表。
| 文件 | 说明 |
|---|---|
| __init__.py | 一个空文件,告诉Python这是一个软件包 |
| migrations | 执行数据库迁移命令生成的脚本 |
| admin.py | 配置Django管理后台的文件 |
| apps.py | 单独配置用户添加的每个app文件 |
| models.py | 创建数据库数据模型对象的文件 |
| tests.py | 用来编写测试脚本的文件 |
| views.py | 用来编写视图控制器的文件 |
创建完article应用后,它不会立即生效,还需要在项目配置文件blog/setting.py中激活应用。代码如下:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'article.apps.ArticleConfig', # 新增代码,激活articles应用
]通常,INSTALLED_APPS默认包含以下Django自带应用。
django.contrib.admin:管理员站点。
django.contrib.auth:认证授权系统。
django.contrib.contenttypes:内容类型框架。
django.contrib.sessions:会话框架。
django.contrib.messages:消息框架。
django.contrib.staticfiles:管理静态文件的框架。
这些应用可以为默认应用提供方便。
数据模型
使用Django编写数据库驱动的web网站时,第一步就是定义数据模型。Django支持ORM,所以可以使用关系模型操作关系型数据库。
在应用中添加数据模型
在article/models.py中,创建User类和Articles模型类,代码如下。
from django.db import models
class User(models.Model):
"""
User模型类,数据模型应继承自models.Model或其子类
"""
id = models.IntegerField(primary_key=True) # 主键
user = models.CharField(max_length=30) # 用户名,字符串类型
email = models.CharField(max_length=30) # 邮箱,字符串类型
class Article(models.Model):
"""
Article模型类,数据模型应继承自models.Model或其子类
"""
id = models.IntegerField(primary_key=True) # 主键
title = models.CharField(max_length=120) # 标题,字符串类型
content = models.TextField() # 文章,文本类型
publish_time = models.DateTimeField() # 出版时间,日期时间类型
user = models.ForeignKey(User, on_delete=models.CASCADE) # 设置外键上述代码中,每个模型的属性都指明了models下的一个数据模型,代表了数据库中的每一个字段。Django的db.models给出了如下的常见字段类型。
| 字段类型 | 说明 |
|---|---|
| AutoField | 一个id自增的字段,创建表的过程中,Django会自动添加一个自增的主键字段 |
| BinaryField | 一个保持二进制源数据的字段 |
| BooleanField | 一个布尔值字段,需要指明默认值。管理后台中默认呈现为CheckBox形式 |
| NullBooleanField | 可以为None值的布尔值字段 |
| CharField | 字符串字段,必须指明max_length参数值。管理后台默认呈现为TextInput形式 |
| TextField | 文本域字段,对于大量文本应该使用TextField。管理后台默认呈现为TextArea形式 |
| DateField | 日期字段,代表Python的datetime.date实例。管理后台默认呈现为TextInput形式 |
| DateTimeField | 时间字段,代表Python中的datetime.datetime实例。管理后台默认呈现TextInput形式 |
| EmailField | 邮件字段,是CharField的实现,用于检查该字段是否符合邮件的格式 |
| FileField | 上传文件字段,管理后台默认呈现ClearableFileInput形式 |
| ImageField | 图片上传字段,是FileField的实现。管理后台默认呈现ClearableFileInput形式 |
| IntegerField | 整数字段,在管理后台默认呈现NumberInput或TextInput形式 |
| FloatField | 浮点数值字段,在管理后腰默认呈现NumbrtInput或TextInput形式 |
| SlugField | 只保存字母、数字、下画线和连接符,用于生成url的短标签 |
| UUIDField | 保存一般统一标识符的字段,代表Python中的UUID实例,建议提供默认值(default) |
| ForeignKey | 外键关系字段,需要提供外键的模型参数和on_delete参数(指定当该模型实例删除时,是否删除关联模型)。若要外键的模型出现在当前模型的后面,需要在第一个参数中使用单引号 |
| ManyToManyField | 多对多关系字段,与ForeignKey字段类似 |
| OneToOneFIeld | 一对一关系字段,常用于扩展其他模型 |
执行数据库迁移
创建完数据模型后,接下来就是执行数据库迁移。Django支持多种数据库,默认情况使用的是MySQL数据库。可以在项目配置blog/settings.py文件中查看,内容如下:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': BASE_DIR / 'db.sqlite3',
}
}若想将数据库改为MySQL数据库,则需要修改配置文件,代码如下:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql', # 将驱动设为MySQL
'NAME': 'django_study', # 数据库名称
'USER': 'root', # 用户名
'PASSWORD': 'root' # 密码
}
}需要先创建django_study数据库,因为Django不会为我们自动创建数据库。
然后进入到项目的venv环境中使用pip install pymysql安装pymysql。

然后在blog\blog\__init__.py中添加如下代码:
import pymysql
# 为实现版本兼容,此处设置mysqlclient的版本
pymysql.version_info = (1, 4, 13, 'final', 0)
pymysql.install_as_MySQLdb()然后再执行如下命令,创建数据表。
python manage.py makemigrations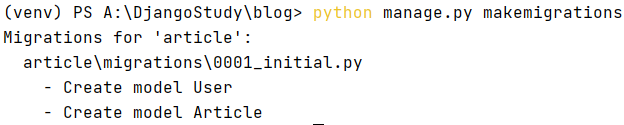
它会在article/migrations目录下生成一个0001_initial.py文件,它就是数据库迁移文件。
接着再执行如下命令,实现数据库迁移。
python manage.py migrate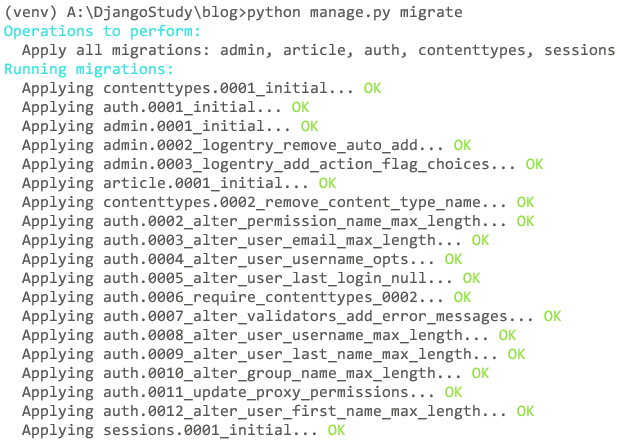
这个命令执行完之后就可以看到创建的数据表了。除了article_article和article_user外,还有Django创建的其他数据表。
Django的数据库迁移非常强大,若想要改变数据表的模型,只需要修改models.py中的模型类中的字段,然后重新执行上面的两个脚本即可。
python manage.py makemigrations
python manage.py migrate数据库迁移分为两步是为了能够在代码控制系统上提交迁移数据并使其能在多个应用中被使用。这不仅仅会让开发更加简单,也给别的开发者和生产环境的使用带来方便。
了解Django数据API
我们进入交互式Python命令行,尝试一下Django提供的API。通过下面的命令打开交互式命令行。
python manage.py shell
导入数据模型命令如下。
from article.models import User, Article- 添加数据
添加数据有两种方法。
方法一:
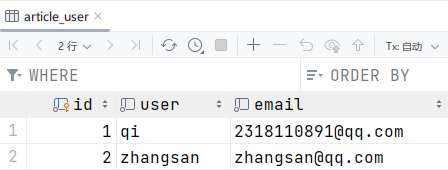
user1 = User.objects.create(id=1, username='qi', email='2318110891@qq.com')方法二:
user2 = User(id=2, username='zhangsan', email='zhangsan@qq.com')
user2.save()先输入第一条命令后,查看数据库,数据会被添加,但是第二个命令输入第一句后数据不会被添加,必须要使用save()方法才能保存数据。
观察数据库,可以看到数据被保存了。
- 查询数据
查询User表中的所有数据:
User.objects.all()它的返回值是一个QuerySet对象。
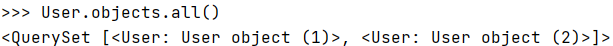
可以通过遍历QuerySet对象获取每一个用户的详细信息。
users = User.objects.all()
for user in users:
print(f'id:{user.id}, user:{user.user}, email:{user.email}')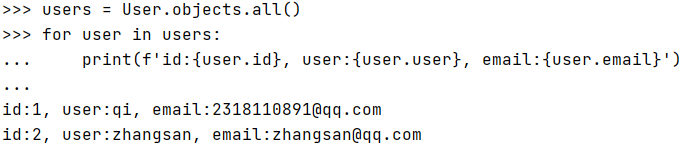
查询User表单数据,可以使用如下命令。
User.objects.first() # 获取第一条记录
User.objects.get(id=1) # 括号内要加入指定的条件,因为get()方法只返回一个确定值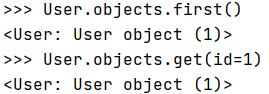
此外,还可以根据指定的条件查询数据,例如:
User.objects.filter(user_exact='qi') # 指定user字段值必须为某值
User.objects.filter(user_iexact='qi') # 忽略大小写
User.objects.filter(id_gt=1) # 查找id值大于1的
User.objects.filter(id_lt=100) # 查找id值小于100的
# 过滤掉所有user字段值包含“n”的记录,然后按照id进行升序排序
User.objects.filter(user_contains='n').order_by('id')
# 过滤出所有user字段值包含“n”的记录,不区分大小写
User.objects.filter(user_icontains='n')- 修改数据
修改之前需要查询数据或数据集,然后对响应的字段进行赋值,代码如下。
user = User.objects.get(id=1)
user.user = 'qi1'
user.save()运行此代码后,从下图可以看到数据被改变了。
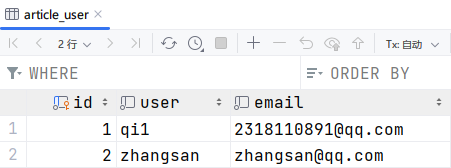
- 删除数据
删除数据与修改数据类似,也需要先找到对应的数据,然后调用delete方法。
User.objects.get(id=1).delete()管理后台
Django提供了一个特别强大的后台,只需要几行命令即可生成一个后台管理系统。
在终端执行以下命令,就可以创建一个管理员账号。
python manage.py createsuperuser
创建完成后启动服务器,在浏览器中输入127.0.0.1:8000/admin,即可访问后台。
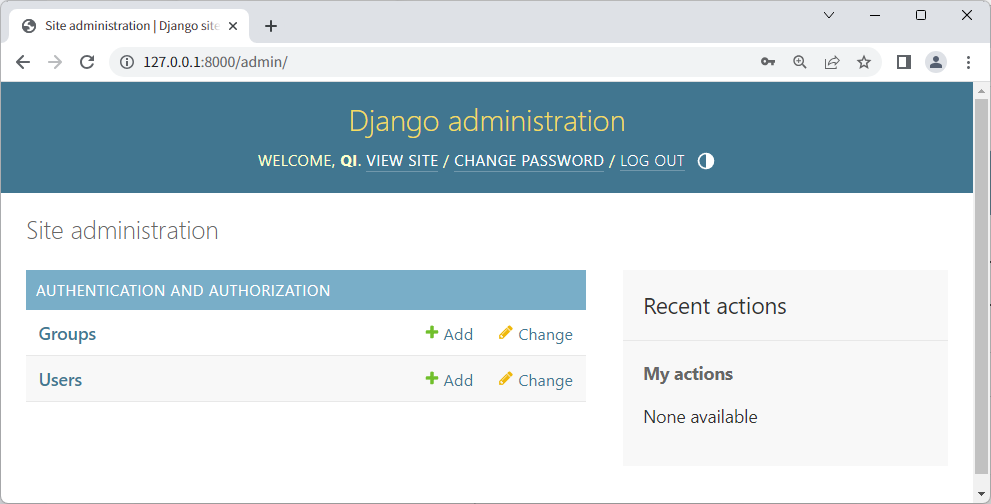
使用之前的用户名和密码登录,即可看到后台了。
定义好数据模型,就可以配置管理后台了。修改article/admin.py配置文件,在admin.py中创建UserAdmin和ArticleAdmin后台控制模型类,并全部继承自admin.ModelAdmin模型类。设置属性,最后将数据模型绑定到管理后台。代码如下。
from article.models import User, Article
from django.contrib import admin
# Register your models here.
class UserAdmin(admin.ModelAdmin):
# 配置展示列表,在User板块下的列表显示
list_display = ('user', 'email')
# 配置过滤查询字段,在User板块下右侧过滤框
list_filter = ('user', 'email')
# 配置可以搜索的字段,在User板块下右侧搜索框
search_fields = ('user', 'email')
class ArticleAdmin(admin.ModelAdmin):
# 配置展示列表,在User板块下的列表显示
list_display = ('title', 'content', 'publish_time')
# 配置过滤查询字段,在User板块下右侧过滤框
list_filter = ('title',) # list_filter应该是列表或元组
# 配置可以搜索的字段,在User板块下右侧搜索框
search_fields = ('title',) # search_fields应该是列表或元组
# 绑定User模型到UserAdmin管理后台
admin.site.register(User, UserAdmin)
# 绑定Article模型到UserAdmin管理后台
admin.site.register(Article, ArticleAdmin)博主在代码运行后报RuntimeError: populate() isn't reentrant的错误,是因为Django导入包的逻辑和PyCharm的导入包的逻辑不一样。上述代码在PyCharm中报错,但是运行时无问题。
当导入模型是这个时则报错:
from models import User, Article。当导入模型是这个时则不报错:
from .models import User, Article、from article.models import User, Article。
配置完成后运行服务器,访问127.0.0.1/admin,可以看到后台多了一个ARTICLE管理,下面有Users和Articles两个模型。
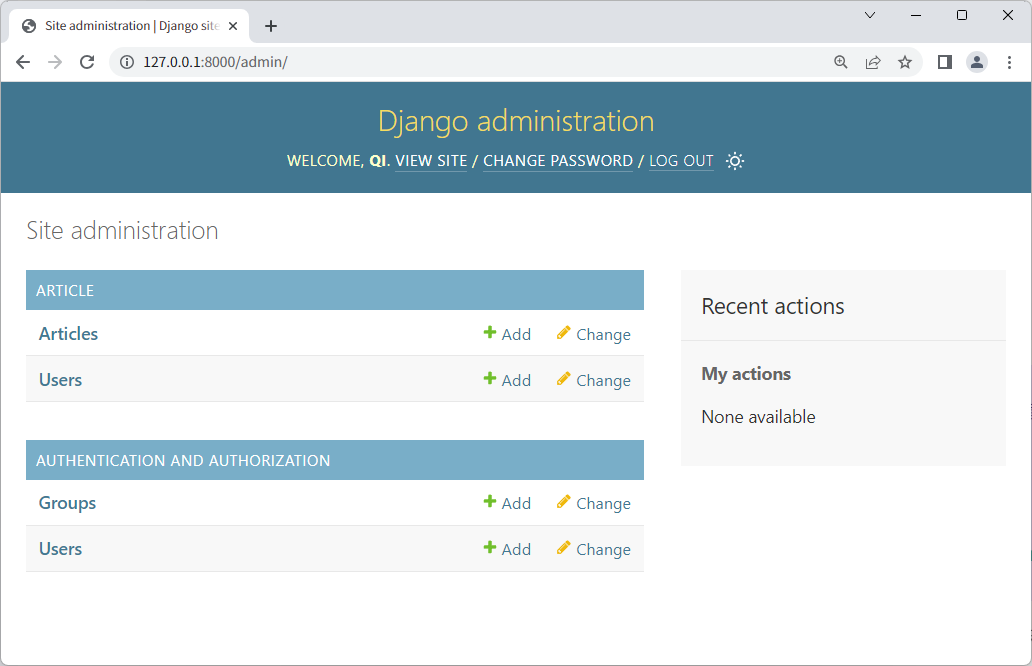
选中一个模型,可以实现对模型的增删改查操作,如单击Articles模型的Add按钮,即可执行新增文章的操作。
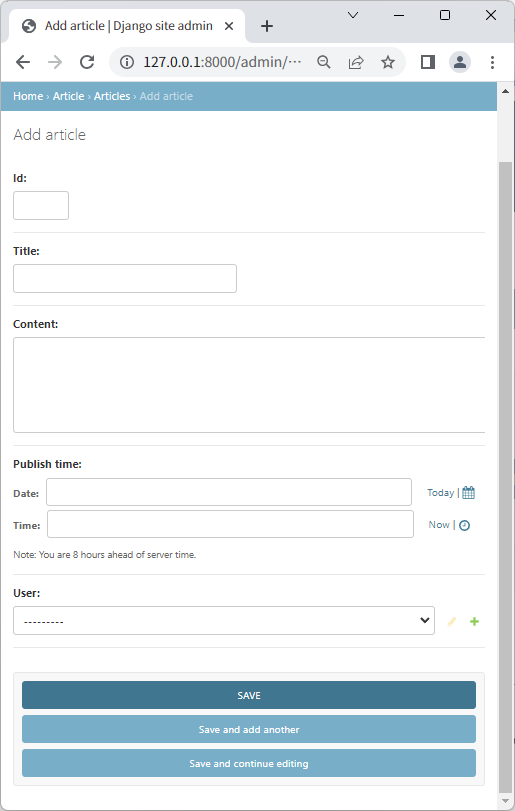
在文章编辑页面中,会显示User选项,以为User和Article是一对多的关系,User选项的出现就是为了选择文章是谁写的。在创建数据模型时使用models.ForeignKey(User, on_delete.models.CASCADE)就指定了这种关系。
路由
Django处理路由的流程如下:
- 查找全局urlpatterns变量,即blog/url.py文件中定义的urlpatterns变量。
- 按照先后顺序,对URL逐一匹配urlpatterns中的每个元素。
- 找到第一个匹配时停止查找,根据匹配元素执行对应的处理函数。
- 若没有匹配或出现异常,Django会进行错误处理。
Django支持的路由形式
Django支持的路由形式有3种。
- 精确字符串形式。即一个精确URL匹配一个操作函数。这是最简单的方式,适合对静态URL的响应。URL字符串不以“/”开头,但要以“/”结尾。如:
path('admin/', admin.site.urls),
path('articles', views.article_list)- 路径转换器形式。在匹配URL格式时,通过URL进行参数获取和传递,语法格式如下:
<类型: 变量名>, articles/<int:year>/例如:
path('articles/<int:year>', views.year_archive),
path('articles/<int:year>/<int:month>', views.month_archive),
path('articles/<int:year>/<int:month>/<slug:slug>', views.article_details)下表中展示了一些常用的格式转换类型。
| 格式类型 | 说明 |
|---|---|
| str | 匹配除分隔符以外的非空字符,默认类型<year>等价为<int:year> |
| int | 匹配0和正整数 |
| slug | 匹配字母、数字、横杠、下画线组成的字符串,是str的子集 |
| uuid | 匹配格式化的UUID |
| path | 匹配任何非空字符串,包含路径分隔符 |
下面演示如何创建路由。
首先在blog/urls.py中创建路由,代码如下:
from django.contrib import admin
from django.urls import path
from . import views
urlpatterns = [
path('admin/', admin.site.urls),
path('articles/', views.article_list),
path('archives/<int:year>/', views.year_archive),
path('archives/<int:year>/<int:month>/', views.month_archive),
path('archives/<int:year>/<int:month>/<slug:slug>/', views.article_details)
]这个代码中引用了同目录下的views.py文件,接下来创建这个文件,代码如下:
from django.http import HttpResponse
def article_list(request):
return HttpResponse('article_list函数')
def year_archive(request, year):
return HttpResponse(f'year_archive函数,year={year}')
def month_archive(request, year, month):
return HttpResponse(f'month_archive函数,year={year},month={month}')
def article_details(request, year, month, slug):
return HttpResponse(f'article_details函数,year={year},month={month},slug={slug}')启动服务,在浏览器中输入127.0.0.1:8000/articles/,结果如下:
article_list函数在浏览器中输入127.0.0.1:8000/archives/2023/,结果如下:
year_archive函数,year=2023在浏览器中输入127.0.0.1:8000/archives/2023/01/,结果如下:
month_archive函数,year=2023,month=1在浏览器中输入127.0.0.1:8000/archives/2023/01/01/,结果如下:
article_details函数,year=2023,month=1,slug=01- 正则表达式形式。若路径和转换器语法不能很好地识别URL模式,则可以通过更加强大的正则表达式匹配对应的URL。使用正则表达式匹配URL时需要使用re_path()而不是path()。
匹配正则表达式组的语法如下:
(?P<name>pattern)其中,name为组名,pattern为正则表达式。
下面用正则表达式重写前面的路由。
from django.urls import path, re_path
from . import views
urlpatterns = [
path('articles/list/', views.article_list),
re_path(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive),
re_path(r'^articles/(?P<year>[0-9]{4}/<month>[0-9]{1,2})/$', views.month_archive),
re_path(r'^articles/(?P<year>[0-9]{4}/<month>[0-9]{1,2}/<slug>[\w+-_])/$', views.article_details)
]使用include包含路由
在开发过程中,随着项目复杂度增加,定义的路由也会越来越多。若全部路由都定义在blog/urls.py中,代码会特别凌乱。此时,可以将前缀内容相同的路由设置为一组,然后使用include()函数包含分组的路由。
例如,将blog/urls.py文件中包含“articles/”前缀的路由作为一组,修改blog/urls.py文件,代码如下:
from django.urls import path, include
urlpatterns = [
path('admin', admin.site.urls),
path('articles', include('article.urls'))
]在上方使用了include包含article下的urls文件,接下来就是在article目录下创建一个urls.py,代码如下:
from django.urls import path
from . import views
urlpatterns = [
path('', views.article_list),
path('<int:year>/', views.year_archives),
path('<int:year>/<int:month>/', views.month_archives),
path('<int:year>/<int:month>/<slug:slug>/', views.article_details)
]最后在article目录下创建一个views.py,代码如下:
from django.http import HttpResponse
def article_list(request):
return HttpResponse('article_list函数')
def year_archives(request, year):
return HttpResponse('year_archives函数')
def month_archives(request, year, month):
return HttpResponse('month_archives函数')
def article_details(request, year):
return HttpResponse('article_details函数')视图
视图函数简称视图,它是一个简单的Python函数,接受request并返回HttpResponse对象。根据视图或函数的类型,Django视图可以分为FBV视图和CBV视图。
FBV视图——基于函数的视图
- 定义路由。在article/urls.py文件中定义路由,代码如下:
from django import path
from . import views
urlpatterns = [
path('', views.article_list),
path('<int:year>/', views.year_archives),
path('<int:year>/<int:month>/', views.month_archives),
path('<int:year>/<int:month>/<slug:slug>/', views.article_details),
path('current', view.get_current_datetime)
]- 创建视图函数。在article/views.py文件中创建一个名为get_current_datetime()视图函数,代码如下:
from django import HttpResponse
from datetime import datetime
def get_current_datetime(request):
today =datetime.today()
formatted_today = today.strftime('%Y-%m-%d')
html = f'<html><body>今天是{formatted_today}</body></html>'
return HttpResponse(html)上方的代码中定义了一个函数,返回了HttpResponse对象。每个视图函数都需要有一个HttpRequest对象作为参数,用来接收客户端传递过来的参数,并且必须返回一个HttpResponse对象,作为响应返回给客户端。
- CBV视图——基于类的视图
首先定义一个类,它继承自View视图类,然后在里面定义get()和post()方法,在接收到对应的请求时自动调用对应的方法。如:
from django.view import View
from django.http import HttpResponse
class ArticleView(View):
def get(self, request, *args, **kwargs):
return HttpResponse('GET请求')
def post(self, request, *args, **kwargs):
return HttpResponse('POST请求')Django模板
Django使用render()函数渲染模板。之前的代码都是使用HttpResponse创建响应,修改这部分文件,代码如下:
from django.shortcuts import render
from article.models import Article, User
def article_list(request):
articles = Article.object.all()
return render(request, 'article.html', {'articles': articles})上述代码中,从Articles表中获取全部数据,然后使用render()函数渲染模板,设置模板文件为article.html,并向模板内存入参数。
随后在后台中添加内容。由于Article表还未添加数据,所以我们先登录后台,添加Article模型数据,如下图。
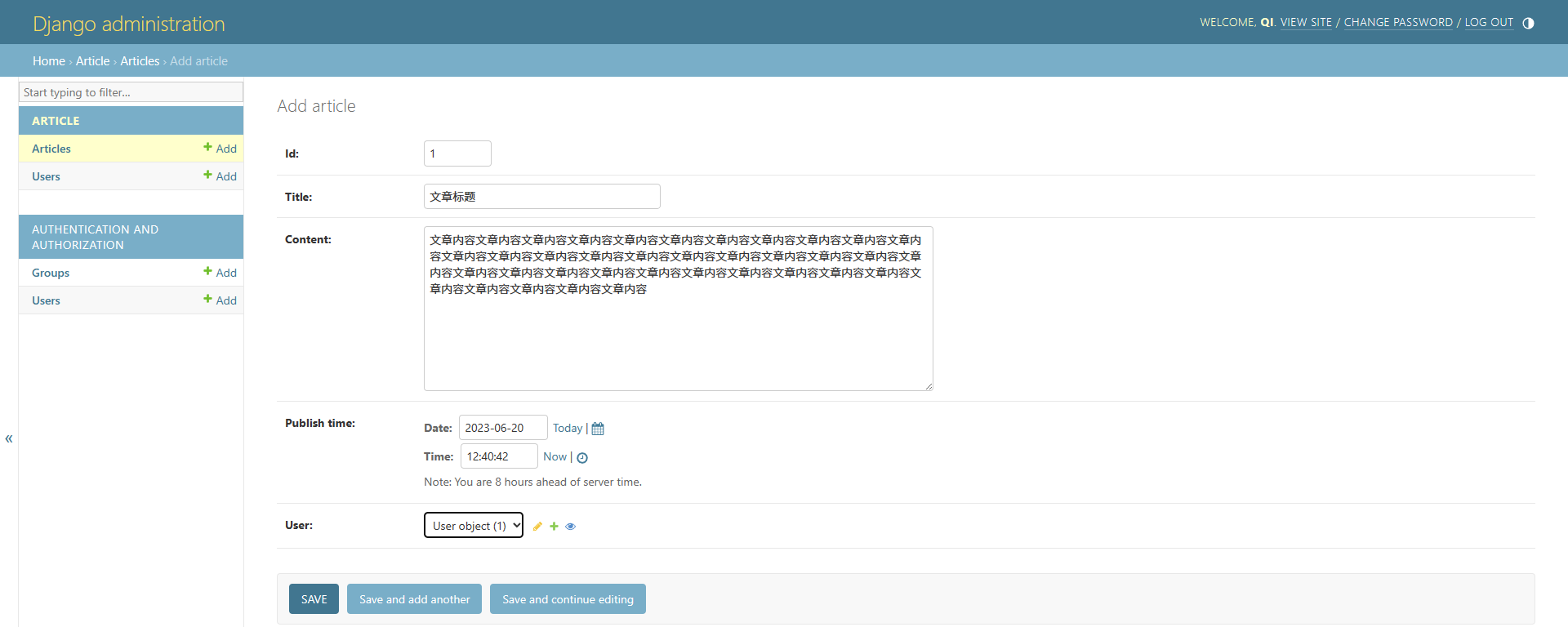
随后创建模板文件。Django默认的模板文件夹为article/templates。在对应位置创建文件夹,并在里面创建article_list.html和base.html文件。base.html为基模板,在这里面可以引入相同的信息和导航栏等公共元素。base.html的代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{% block title %}{% endblock %}</title>
{% load static %}
<link rel="stylesheet" type="text/css" href="{% static 'css/bootstrap.css' %}">
<script src="{% static 'js/jquery.js' %}"></script>
<script src="{% static 'js/bootstrap.js' %}"></script>
</head>
<body class="container">
<nav class="navbar navbar-expand-sm bg-primary navbar-dark">
<!--省略导航栏代码-->
</nav>
{% block content %}{% endblock %}
</body>
</html>在base.html中使用了{% block xxx %}作为占位符,使用{% load static %}导入静态文件路径,即article/static路径。接下来,在article_list.html中编写以下代码:
{% extends "base.html" %}
{% block title %}文章列表{% endblock %}
{% block content %}
<div style="margin-top:20px">
<h3>文章列表</h3>
<table class="table table-bordered ">
<thead>
<tr>
<th>文章ID</th>
<th>作者</th>
<th>标题</th>
<th>发布时间</th>
</tr>
</thead>
<tbody>
{% for article in articles %}
<tr>
<td>{{ article.id }}</td>
<td>{{ article.user.username }}</td>
<td>{{ article.title }}</td>
<td>{{ article.publish_date | date:'Y-m-d' }}
</tr>
{% endfor %}
</tbody>
</table>
</div>
{% endblock %}Django模板引擎使用“{% %}”来描述Python语句,以区别于html标签。使用“{{ }}”来描述变量。上面的代码及说明如下表索所示。
| 标签 | 说明 |
|---|---|
{% extends 'base.html'%} | 扩展一个基模板 |
{%block title%} | 指定父模板中的一段代码块,此处为title,在父模板中定义title,可以在子模块中重写该代码。block标签必须是封闭的,要由{% end block %}结尾 |
{{ article.title }} | 获取变量的值 |
{% for element in lst%}<br />{% endfor %} | 和Python中的for循环比较类似 |
此外,“|”为过滤器。Django的过滤器非常实用,可对返回的变量做进一步处理。常用的过滤器如下:
| 过滤器 | 说明 |
|---|---|
{{value|default:"nothing"}} | 用来指定默认值 |
{{value|length}} | 用来计算返回的列表或者字符串长度 |
{{value|lower}} | 用来将返回的数据变为小写字母 |
{{value|date}} | 用来将日期格式转换为字符串格式 |
{{value|safe}} | 不使用转义 |
{{value|filesizeformat}} | 用于使文件大小变得易读,如15KB |
{{value|truncatewords:30}} | 对返回的字符加以截取,多用于显示文章摘要,此处为30个字符 |
表单
Django提供了一个表单类功能,可以将Python字段转换为HTML的表单。首先在blog/article下创建一个form.py文件,代码如下:
from django import forms
class LoginForm(forms.Form):
username = forms.CharField(
label='姓名',
required=True,
min_length=3,
max_length=10,
widget=forms.TextInput(attrs={'class': 'form-control'}),
error_messages={
'required': '用户名必须填写',
'min-length': '长度不能少于3个字符',
'max-length': '长度不能多于10个字符'
}
)
email = forms.EmailField(
label='邮箱',
required=True,
max_length=50,
widget=forms.TextInput(attrs={'class': 'form-control'}),
error_messages={
'required': '邮箱必须填写',
'max-length': '长度不能多于50个字符'
}
)上述代码创建了一个LoginForm类,它继承自表单类Form类;它里面有两个字段:用户名username和邮箱email,分别对应数据库中的用户名和邮箱字段。由于这两个字段都为字符串型数据,因此都用forms.CharField类实例化。此外,forms类中还有其他的字段类型属性,如IntegerField、FloatField、DateFIeld等。在forms.FIeld实例化时,可以设置验证规则,如required用于设置该字段是否必须被填写,min_length用于设定最小长度等。此外,还可以widget参数来设定表单中字段的样式。
LoginForm类将呈现如下的代码:
<div class='form-group'>
<label>姓名:</label>
<input type='text' name='username' class='form-control' maxlength='10' minlength='3' required id='id_username'>
</div>
<div class='form-group'>
<label>邮箱:</label>
<input type='text' name='email' class='form-control' maxlength='50' required id='id_email'>
</div>接下来创建路由。在article/urls.py中配置路由:
urlpatterns = [
path('login', views.LoginFormView.as_view())
]接下来创建FCV,并在类中设置get()和post()方法:
class LoginFormView(View):
def get(self, request, *args, **kwargs):
return render(request, 'login.html', {'form': LoginForm()})
def post(self, request, *args, **kwargs):
# 将请求数据传入到form实例中
form = LoginForm(request.POST)
# 判断是否为有效表单
if form.is_valid():
username = form.cleaned_data['username']
email = form.cleaned_data['email']
return HttpResponse(f'username={username},email={email}')
else:
return render(request, 'login.html', {'form': form})上述代码中,定义了get()方法和post()方法,用于处理GET请求和POST请求。在提交表单时,会调用post()方法。
最后就是创建login.html模板文件。
{% extends 'base.html' %}
{% block titie %}登录页面
{% endblock %}
{% block content %}
<style>
.errorlist {
color: red;
}
</style>
<div class="container">
<form action="" method="post">
{% csrf_token %}
<div class='form-group'>
<label>{{ form.username.label }}</label>
{{ form.username }}
{{ form.username.errors }}
</div>
<div class='form-group'>
<label>{{ form.email.label }}</label>
{{ form.email }}
{{ form.email.errors }}
</div>
<button type="submit">提交</button>
</form>
</div>
{% endblock %}在模板文件中,使用form.field_name来获取对应的字段信息,并通过form.field_name.errors来获取字段验证失败时的提示信息。此外,使用模板标签{% csrf_token %}来验证表单的真伪性。
Session会话
由于HTTP是无状态的,因此网页一般都会把信息存放到Cookie中。Django提供了一个Session框架,并且提供了多种存储这种数据的方法。
- 保存到数据库。
- 保存在缓存中。
- 保存到文件。
- 保存到Cookie。
Django支持匿名会话,会话允许在每个站点访问者的基础上访问任何数据。它将数据存储到服务器中,并抽象发送和接收Cookie。
启用会话
Django通过一个内置中间件来实现会话功能。编辑setting.py中的MIDDLEWARE设置,设置方式如下:
MIDDLEWARE = [
'django.contrib.sessions.middleware.SessionMiddleware'
]默认情况下,使用django-admin startapp创建项目时会自动实现此配置。
配置会话引擎
默认情况下,Django会将会话数据保存在数据库里。可选的其他保存位置如下:
- 基于数据库的会话
确保在INSTALLED_APPS设置中django.contrib.sessions存在,然后运行manage.py migrate命令,在数据库中创建sessions表。
- 基于缓存的会话
为了提高性能,通常会将Session保存在缓存中,但是首先要配置缓存。
若定义了多个缓存,Django会使用默认的缓存。若使用其他缓存需要将SESSION_CACHE_ALIAS参数设置为对应的缓存名字。
配置好缓存后,可以选择以下两种保存缓存的方法。
- 将SESSION_ENGINE设置为django.contrib.sessions.backends.cache,简单的对会话进行保存。但是这种缓存在满了之后将清除部分数据,且服务器重启后数据会丢失。
- 为了数据安全,通常将SESSION_ENGINE设置为django.contrib.sessions.cached_db,这样每次缓存时会同时存在数据库里,当缓存不可用时会在数据库中读取。
两种方法都很迅速,但第一种缓存更快。
- 基于文件的会话
将SESSION_ENGINE设为django.contrib.sessions.backends.file,同时必须正确配置SESSION_CACHE_PATH,确保文件存储目录及Web服务器有读取该目录的权限。
- 基于Cookie的会话
将SESSION_ENGINE设为django.contrib.sessions.backends.signed_cookies,Django将使用加密签名密钥和安全密钥设置保存会话的Cookie。
除此之外可以将SESSION_COOKIE_HTTPONLY设为True,以阻止JavaScript对会话数据的访问,提高安全性。
会话对象的常用方法
会话中间件启用后,传递给视图request参数的HTTPRequest对象将包含一个session属性,这个属性的值是一个类似字典的对象。request.session对象的常用方法如下。
| 方法 | 说明 |
|---|---|
request.session['key'] = 123 | 设置或者更新key的值 |
request.session.setdefault('key', 123) | 设置key的默认值 |
request.session['key'] | 获取Session中指定key的值 |
request.session.get('key', None) | 获取Session中指定的值,如果不存在则赋值默认值 |
request.session.pop('key') | 删除Session中弹出指定key |
del request.session['key'] | 删除Session中指定key的值 |
request.session.delete('session_key') | 删除当前用户的所有Session数据 |
request.session.clear() | 删除当前用户的Session数据 |
request.session.flush() | 删除当前Session数据并删除Cookie |
request.session.session_key | 获取用户Session的随机字符串 |
request.session.clear_expired() | 将所有Session失效日期小于当前日期的数据删除 |
request.session.exists('session_key') | 检查用户Session的随机字符串在数据库中是否存在 |
request.session.keys() | 获取Session所有的键 |
request.session.values() | 获取Session所有的值 |
request.session.items() | 获取Session中所有键值对 |
request.session.iterkeys() | 获取Session所有键的可迭代对象 |
request.session.itervalues() | 获取Session中所有值的可迭代对象 |
request.session.iteritems() | 获取Session中所有键值对的可迭代对象 |
request.session.set_expiry(value) | 设置Session的过期时间。value参数说明如下列表。 |
- 整数:表示Session在指定秒数后过期。
- 0:表示Session在用户关闭浏览器后过期。
- datatime或timedelta:表示Session会在设置时间后失效。
- None:表示Session依赖于全局Session失效策略。
使用会话实现登录功能
Session可以记录用户的行为和数据,所以Session可以用于处理用户登录事件上。若用户在输入正确的用户名和密码后,就可以向Session中写入用户的个人信息,在其他需要用户登录后才能获取的页面中就可以使用Session获取用户数据。
要实现这种方式,首先进入Shell中。
python manage.py shell在Shell模式中,首先先创建一个用户。
>>> from django.contrib.auth.models import User
>>> User.objects.create_user(username='qi1', password='qi1')
<User: qi1>上述命令中,创建了一个用户名为qi1,密码也为qi1的用户。接下来,使用Django的authenticate()判断用户名和密码是否正确。
>>> from django.contrib.auth import authenticate
>>> user = authenticate(username='qi1', password='qi1')
user
>>> user = authenticate(username='qi1', password='123456')
user上述代码中,若传递了错误的用户名和密码,authenticate()方法将返回None;当传递正确的用户名和密码时,会返回正确的User对象。
然后修改登录表单,将邮箱字段改为密码字段。修改blog/article/forms.py,关键代码如下:
from django import forms
from django.forms import CharField
class LoginForm(forms.Form):
username = forms.CharField(
label='姓名',
required=True,
min_length=3,
max_length=10,
widget=forms.TextInput(attrs={'class': 'form-control'}),
error_messages={
'required': '用户名必须填写',
'min-length': '长度不能少于3个字符',
'max-length': '长度不能多于10个字符'
}
)
password = CharField(
label='密码',
required=True,
min_length=3,
max_length=50,
widget=forms.TextInput(attrs={'class': 'form-control'}),
error_messages={
'required': '密码必须填写',
'min-length': '长度不能少于3个字符',
'max-length': '长度不能多于50个字符'
}
)然后修改登录函数,添加对用户名密码的验证。修改blog/article/views.py文件中的LoginView类,关键代码如下:
from article.models import Article
from django.contrib import messages
from django.contrib.auth import authenticate, login
from django.http import HttpResponse, HttpResponseRedirect
class LoginFormView(View):
def get(self, request, *args, **kwargs):
return render(request, 'login.html', {'form': LoginForm()})
def post(self, request, *args, **kwargs):
# 将请求数据传入到form实例中
form = LoginForm(request.POST)
# 判断是否为有效表单
if form.is_valid():
username = form.cleaned_data['username']
password = form.cleaned_data['password']
user = authenticate(username=username, password=password)
if user is not None:
login(request, user)
return HttpResponseRedirect('/articles/')
else:
messages.add_message(request, messages.WARNING, '用户名或密码不正确')
else:
return render(request, 'login.html', {'form': form})上述代码中,当用户点击登录按钮后会调用POST请求对应的post()方法,在这其中首先实例化表单类,然后检验表单中的值是否符合要求。若不符合要求则重新要求重新输入表单。接着验证用户名和密码是否正确。若正确则调用login()函数向Session中写入登录信息。
接着修改模板文件,打开blog/article/template/login.html,修改关键代码如下:
{% extends 'base.html' %}
{% block titie %}登录页面
{% endblock %}
{% block content %}
<style>
.errorlist {
color: red;
}
</style>
<div class="container">
{% if messages %}
{% for message in messages %}
<div class="errorlist {% message.tags %}" >{% message %}</div>
{% endfor %}
{% endif %}
<form action="" method="post">
{% csrf_token %}
<div class='form-group'>
<label>{{ form.username.label }}</label>
{{ form.username }}
{{ form.username.errors }}
</div>
<div class='form-group'>
<label>{{ form.password.label }}</label>
{{ form.password }}
{{ form.password.errors }}
</div>
<button type="submit">提交</button>
</form>
</div>
{% endblock %}退出登录
用户登录成功后,会将用户信息写入Session。若此时想要退出登录,只需要清除Session即可。Django自带了一个logout()函数,使用它处理对应的路由即可实现退出登录功能。
首先先创建一个logout路由。在blog/article/urls.py文件中,添加以下代码:
urlpatterns = [
path('logout/', view.logout)
]随后在blog/article/view.py文件中,添加如下的代码:
from django.contrib.auth import authenticate, login, logout as django_logout
def logout(request):
django.logout(request)
return HttpResponseRedirect('/login/')在上述代码中,创建了一个自定义处理退出登录功能的函数logout(),为了避免它和Django的logout()函数重名,将Django的logout()函数修改为django_logout()。
登录验证
我们有时希望有些页面在登录的情况下不能访问,为此Django提供了一个装饰器login_required。
如下面的代码就可以实现不允许用户在未登录的情况下阅读文章。
from django.contrib.auth.decorators import login_required
@login_required
def article_list(request):
article = Article.objects,all()
return render(request, 'article_list.html', {'articles': articles})同时需要在自定义路由配置文件urls.py文件中设置页面跳转的路径。
LOGIN_URL = '/articles/login/'ModelForm
前面的例子中我们既创建了数据库模型类又创建了表单类,-这种方法实际上可以被简化。使用Django提供的ModelForm创建完数据模型后它会自动创建表单类。ModelForm是Django中基于Model定制表单的方法,可以提高Model的复用性。使用时Django会根据django.db.models.FIeld自动转换为django.forms.Field见如下例子。
使用ModelForm
ModelForm通过Meta把db.Field自动转换为forms.Field,其中涉及到如下转换:
- validators不变。
- 添加widget属性,即前端的渲染方式。
- 修改Model包含的字段,通过fields来控制显示指定字段或者通过excludes排除指定字段。
- 修改错误信息。
下面使用ModelForm类替换Form表单类。修改如下:
from django import forms
from django.db import models
from django.forms import ModelForm, TextInput, DateInput
class User(models.Model):
"""
User模型类,数据模型应继承自models.Model或其子类
"""
id = models.IntegerField(primary_key=True) # 主键
user = models.CharField(max_length=30) # 用户名,字符串类型
email = models.CharField(max_length=30) # 邮箱,字符串类型
def __repr__(self):
return User.user
class Article(models.Model):
"""
Article模型类,数据模型应继承自models.Model或其子类
"""
id = models.IntegerField(primary_key=True) # 主键
title = models.CharField(max_length=120) # 标题,字符串类型
content = models.TextField() # 文章,文本类型
publish_time = models.DateTimeField() # 出版时间,日期时间类型
user = models.ForeignKey(User, on_delete=models.CASCADE) # 设置外键
def __repr__(self):
return Article.title
class UserModelForm(ModelForm):
class Meta:
model = User
fields = '__all__'
class ArticleModelForm(ModelForm):
content = forms.CharField(
label='内容',
widget=forms.Textarea(attrs={'class': 'form-control'}),
error_messages={
'required': '长度不能为空',
'mix_length': '长度不能少于10个字符'
}
)
class Meta:
model = Article
fields = ['title', 'content', 'publish_time']
widgets = {
'title': TextInput(attrs={'class': 'form-control'}),
'publish_time': DateInput(attrs={'class': 'form-control'})
}
error_messages = {
'title': {
'required': '标题不能为空',
'max-length': '长度不能超过三十个字符'
},
'publish_time': {
'required': '日期时间不能为空',
'invalid': '请输入正确的日期时间格式'
}
}在models.py文件中,新增的这两个类都继承自ModelForm类。Meta类中属性说明如下:
- model:关联的ORM模型。
- fields:表单中使用的字段列表。
- widgets:同Form类的widgets。
- error_messages:验证错误的信息。
字段类型
生成的Form类中将具有和指定模型对应的表单字段,顺序为fields属性列表中指定的顺序。每个模型字段都有一个默认的表单字段。如模型中的CharField字段可表现成表单中的CharField,模型中的ManyToManyField可表现成MultipleChoiceField字段。完整的映射关系如下表。
| 模型字段 | 表单字段 |
|---|---|
| AutoField | 在Form类中无法使用 |
| BlgAutoField | 在Form类中无法使用 |
| BigIntegerField | IntegerField,最小-9223372036854775808,最大9223372036854775807 |
| BooleanField | BooleanField |
| CharField | CharField |
| CommaSeparatedIntegerField | CharField |
| DateField | DateField |
| DateTimeField | DateTimeField |
| DecimalField | DecimalField |
| EmailField | EmailField |
| FileFIeld | FileFIeld |
| FilePathField | FilePathField |
| FloatField | FloatField |
| ForeignKey | ModelChoiceField |
| ImageField | ImageField |
| IntegerField | IntegerField |
| IPAddressField | IPAddressField |
| GenericIPAddressField | GenericIPAddressField |
| ManyToManyField | ModelMutipleChoiceField |
| NullBooleanField | NullBooleanField |
| PositiveIntegerField | IntegerField |
| PositiceSmallIntegerField | InregerField |
| SlugField | SlugField |
| SmallIntegerField | IntegerField |
| TexrField | CharField,带有widget=forms.Texrarea参数 |
| TimeField | TimeField |
| URLField | URLField |
可以看出,Django在设计model字段和表单字段时存在大量的相似之处。
- ForeignKey被映射为表单的django.forms.ModelChoiceField,它的选项是一个模型的QuerySet,也就是可以选择的对象列表,但是只能选择一个。
- ManyToManyField被映射为表单的django.forms.ModelMultipleChoiceField,它的选项是一个模型的QuerySet,也就是可以选择的对象列表,且可以选择多个。
同时,在表单属性设置上,还有如下的映射关系。
- 若模型字段设置blank=True,那么表单字段的required字段将被设为False。
- 表单字段的label属性根据字段的verbose_name属性设置,并将第一个字母大写。
- 若模型的某个字段设置了editable=False属性,那么表单类将不会出现该字段。表单字段额help_text设置为模型字段的help_text。
- 如果模型字段设置了choices参数,那么表单字段的widget属性将设为Select框,其选项来自于模型字段的choices。选单中通常有一个空选项,并且作为默认选择。若该字段为必选字段,则会强制用户选择第一个选项;若模型字段具有default参数,则不会添加空选项到选单中。
ModelForm的验证
验证ModelForm分为两步:验证表单和调用模型实例。
与普通的表单验证,模型表单的验证也需要调用is_valid()方法或访问errors属性。模型的验证(Model.full_clean())紧跟在表单的clean()方法调用之后。通常情况下,我们使用Django内置的验证其。若需要,也可以重写表单的clean()方法来提供额外的验证,方法和普通的表单一样。
下面创建一个视图函数,然后验证ModelForm类。创建视图函数,代码如下:
@login_required
def add_article(request):
if request.method = 'GET':
form = ArticleModelForm()
else:
form = ArticleModelForm(request.POST)
if form.is_valid():
return HttpResponse('验证成功')
return render(request, 'add_article.html', {'form': form})创建add_article.html模板。
{% extends 'base.html' %}
{% block title %}添加文章{% endblock %}
{% block content %}
<style>
.errorlist{
float: left;
}
.errorlist li{
color: red;
}
</style>
<div>
<h3>
添加文章
</h3>
<form class='mt-4' action='' method='post'>
{% csrf_token %}
{{ form }}
<div style='padding-top: 20px'>
<button type='submit' class='btn btn-primary'>
登录
</button>
</div>
</form>
</div>
{% end block %}save()方法
每个ModelForm都有一个save()方法,此方法根据绑定到表单的数据创建并保存数据库对象。ModelForm子类可以接受现有的模型实例作为关键字参数实例。若提供了此参数,则save()方法会更新此实例。若未提供,则save()方法将创建指定模型的新实例。在shell中示例代码如下:
>>> from myapp.model import Article
>>> from myapp.forms import ArticleForm
>>> f = ArticleForm(request.POST)
>>> new_article = f.save()
>>> a = Article.objects.get(pk=1)
>>> f = ArticleForm(request.POST, instance=a)
>>> f.save()调用save()方法时,通过添加commit=False可以避免立即存储数据,可通过后续的修改或补充,得到完整的Model实例后再存储到数据库。
若初始化时传入了instance,那么调用save()时会用ModelForm中定义过的字段值覆盖传入实例的相应字段,并写入数据库。save()方法同样会存储MantToManyField,若调用save()方法时使用了commit=False,那么ManyToManyField的储存需要等该条目存入数据库之后手动调用save_m2m()方法。示例代码如下。
# 新建一个表单实例,传递POST数据
>>> f = AuthorForm(request.POST)
# 创建一个新的实例,但是不保存
>>> new_author = f.save(commit=False)
# 修改实例属性
>>> new_author.some_field = 'some_value'
# 保存实例
>>> new_author.save()
# 保存多对多类型数据
>>> f.save_m2m()仅当使用save(commit=False)时才使用save_m2m()。当在表单上使用save()时,所有数据(包含多对多数据)都会被保存。如:
>>> a = Author()
>>> f = AuthorForm(request.POST, instance=a)
>>> new_author = f.save()ModelForm的字段选择
在选择字段时使用ModelForm的fields属性,在复制列表内将想要的字段都添加进去,或者使用__all__添加所有字段或使用exclude排除字段。如:
from django.forms import ModelForm
# __all__表示将所有字段都添加到表单中
class AuthorForm(ModelForm):
class Meta:
model = Author
fields = '__all__'
# exclude表示将模型类除排除外的字段都添加进来
class AuthorForm(ModelForm):
class Meta:
model = Author
excludes = ['title']处理数据关系
一对一
一对一关系类型的定义如下:
class OneToOneField(to, on_delete, parent_link=False, **options)[source]一对一关系非常类似于关系数据库的unique字段,但是反向对象关联只有一个。这种关系多数用于一个对象从另一个对象扩展而来。如Django自带auth模块的User用户表,若想在自己的项目里创建用户模型,又想方便地使用Django的认证功能,就要可以在用户模型内使用一对一关系,添加一个与auth模块User模型的关联字段。
下面通过餐厅和地址的例子介绍一对一模型。
from django.db import models
class Place(models.Model):
name = models.CharField(max_length=50)
address = models.CharField(max_length=80)
def __str__(self):
return f'{self.name} the place'
class Restaurant(models.Model):
place = models.OneToOneField(Place, on_delete=models.CASCADE, primary_key=True)
serves_hot_dogs = models.BooleanField(default=False)
serves_pizzas = models.BooleanField(default=False)
def __str__(self):
return f'{self.place.name} thr restaurant'上述代码中,在餐厅模型中定义了models.OneToOneField()方法,第一个参数表示关联的模型,第二个参数on_delete表示删除关系,models.CASCADE表示级联删除;第三个参数表示设置主键。
下面使用Shell命令指定一对一操作。
首先创建一组Place模型数据。
>>> p1 = Place(name='肯德基', address='人民广场88号')
>>> p1.save()
>>> p2 = Place(name='麦当劳', address='人民广场99号')
>>> p2.save()创建一组Restaurant模型数据,传递parent作为这个对象的主键。
>>>r = Restaurant(place=p1, serves_hot_dogs=True, serves_pizzas=False)
>>>r.save()一个Restaurant对象可以获取它的地点。
>>>r.place
<Place: 肯德基 the place>一个Place对象可以获取它的餐厅,示例代码如下:
>>> p1.restaurant
<Restaurant: 肯德基 the restaurant>现在p2还没有和Restaurant关联,所以使用try...except语句检测异常,示例代码如下:
>>> from django.core.exceptions import ObjectDoesNotExist
>>> try:
>>> p2.restaurant
>>> except ObjectDoesNotExist:
>>> print("there is no restaurant here.")
There is no restaurant here.也可以使用hasattr属性来避免捕获异常,示例代码如下:
>>> hasattr(p2,'restaurant')
False使用分配符号设置地点。由于地点是餐厅的主键,因此保存将创建一个新餐厅,示例代码如下:
>>> r.place = p2
>>> r.save(
>>> p2.restaurant>
<Restaurant: 麦当劳the restaurant>
>>> r.place
<Place: 麦当劳 the place>反向设置Place,示例代码如下:
>>> p1.restaurant = r
>>> p1.restaurant
<Restaurant: 肯德基 the restaurant>注意,必须先保存一个对象,然后才能将其分配给一对一关系。例如,创建一个未保存位置的餐厅会引发ValueError,示例代码如下:
>>> p3 = Place(name='Demon Dogs', address='944 W.Fullerton")
>>> Restaurant.objects.create(place=p3, serves_hot_dogs=True, serves_pizza=False)
Traceback (most recent calllast):
...
ValueError: save() prohibited to prevent data loss due to unsaved related object 'place'.Restaurant.objects.all()返回餐厅,而不是地点。示例代码如下:
>>> Restaurant.objects.all()
<QuerySet [<Restaurant: 肯德基 the restaurant>, <Restaurant: 麦当劳 the restaurant>]Place.objects.all()返回所有Places,无论它们是否有Restaurants。示例代码如下:
>>> Place.obiects.all('name')
<QuerySet [<Place: 肯德基 the place>, <Place: 麦当劳 the place>]>也可以使用跨关系的查询来查询模型,示例代码如下:
>>> Restaurant.objects.get(place=p1)
<Restaurant: Demon Dogs the restaurants>
>>> Restaurant.objects.get(place pk=1)
<Restaurant: Demon Dogs the restaurant>
>>>Restaurant.objects.filter(place__name__startswith="Demon")
<QuerySet [<Restaurant: Demon Dogs the restaurant>]>
>>> Restaurant.objects.exclude(place__address__contains="Ashland")
<QuerySet [<Restaurant: Demon Dogs the restaurant>]>反向也同样适用,示例代码如下:
>>> Place.objects.get(pk=1)
<Place: Demon Dogs the place>
>>> Place.objects.get(restaurant_place=p1)
<Place: Demon Dogs the place>
>>> Place.objects.get(restaurant=r)
<Place: Demon Dogs the place>
>>>Place.objects.get(restaurant__place__name__startswith="Demon")
<Place: Demon Dogs the place>多对一
多对一和一对多是相同的模型,只是表述不同。以班主任和学生为例,班主任和学生的关系是一够的关系,而学生和班主任的关系就是多对一的关系。
多对一的关系,通常被称为外键。外键字段类的定义如下:
class ForeignKey(to, on_delete, **options)[source]外键需要两个位置参数:一个是关联的模型,另一个是on_delete选项。外键要定义在“多”的一方下面以新闻报道的文章和记者为例,一篇文章(Article)有一个记者(Reporte),而一个记者可以发布多篇文章,所以文章和作者之间的关系就是多对一的关系。模型的定义如下:
from django.db import models
class Reporter(models.Model):
first_name = models.CharField(max_length=30)
last_name = models.CharField(max_length=30)
email = models.EmailField()
def __str__(self):
return "%s %s"%(self.first_name, self.last_name)
class Article(models.Model)
headline = models.CharField(max_length=100)
pub_date = models.DateField()
reporter = models.ForeignKey(Reporter, on_delete=models.CASCADE)
def str_(self):
return self.headline
class Meta:
ordering =['headline']上述代码中,在“多”的一侧(Article)定义ForeignKey(),关联Reporter下面使用Shell命令执行多对一操作。创建一组Reporter对象,示例代码如下:
>>> r = Reporter(first_name='John', last_name='Smith', email='john@example.com')
>>> r.save()
>>> r2 = Reporter(first_name='Paul', last_name='Jones', email='paul@example.com')
>>> r2.save()创建一组文章对象,示例代码如下:
>>> from datetime import date
>>> a = Article(id=None, headline="This is a test", pub_date=date(2005,7,27), reporter=n)
>>> a.save()
>>> a.reporter.id
1
>>> a.reporter
<Reporter: John Smith>请注意,必须先保存一个对象,然后才能将其分配给外键关系。例如,使用未保存的Reporter创建文章会引发ValueError,示例代码如下:
>>> r3 = Reporter(first_name='John', last_name='Smith', email='john@example.com')
>>> Article.objects.create(headline="This is a test", pub_date=date(2005,7.27), reporter=r3)
Traceback (most recent call last):
ValueError: save() prohibited to prevent data loss due to unsaved related object 'reporter'.文章对象可以访问其相关的Reporter对象,示例代码如下:
>>> r= a.reporter通过Reporter对象创建文章,示例代码如下:
>>> new_article = r.article_set.create(headline="John's second story", pub_date=date(2005,7,29))
>>> new_article
<Article: John's second story>
>>> new_article.reporter
<Reporter: John Smith>
>>> new article.reporter.id
1创建新文章,示例代码如下:
>>> new_article2 = Article.objects.create(headline="Paul's story"pub_date=date(2006,1,17), reporter=r)
>>> new_article2.reporter
<Reporter: John Smith>
>>> new article2.reporter.id
1
>>> r.article_set.all()
<QuerySet [<Article: John's second story>, <Article: Paul's story>, <Article: This is a test>]>将同一篇文章添加到其他文章集中,并检查其是否移动,示例代码如下:
>>> r2.article_set.add(new_article2)
>>> new_article2.reporter.id
2
>>> new_article2.reporter
<Reporter: Paul Jones>添加错误类型的对象会引发TypeError,示例代码如下:
>>> r.article_set.add(r2)
Traceback (most recent call last):
...
TypeError: 'Article' instance expected, got <Reporter: Paul Jones>
>>> r.article_set.all()
<QuerySet [<Article: Join's second story>, Article: This is a test>]>
>>> r2.article_set.all()
<QuerySet [<Article: Paul's story>]>
>>> r.article_set.count()
2
>>> r2.article_set.count()
1请注意,在最后一个示例中,文章已从John转到Paul。相关管理人员也支持字段查找,API会相据需要自动遵循关系。通常使用双下画线分隔关系,例如要查找headline字段,可以使用headline作为过滤条件,示例代码如下:
>>> r.article_set.filter(headline__startswith='This')
<QuervSet [<Article: This is a test>]>
# 查找所有名字为"John"的记者的所有文章
>>> Article.obiects.filter(reporter__first__name='John')
<QuerySet [<Article: John's second storvy>, <Article: This is a test>]>也可以使用完全匹配,示例代码如下:
>>> Article.objects.filter(reporter__first name='John')
<QuerySet [<Article: John's second story>, <Article: This is a test>]>也可以查询多个条件,这将转换为WHERE子句中的AND条件,示例代码如下:
>>> Article.objects.filter(reporter__first__name='John', reporter__last__name='Smith')
<QuerySet [<Article: John's second story>, <Article: This is a test>]>对于相关查找,可以提供主键值或显式传递相关对象,示例代码如下:
>>> Article.objects.filter(reporter_pk=1)
<QuerySet [<Article: John's second story>,<Article: This is a test>]>
>>> Article.objects.filter(reporter=1)
<QuerySet [<Article: John's second story>, <Article: This is a test>]>
>>> Article.objects.filter(reporter=r)
<QuerySet [<Article: John's second story>, <Article: This is a test>]>
>>>Article.objects.filter(reporter__in=[1 ,2]).distinct()
<QuerySet [<Article: John's second story>, <Article: Paul's story>, <Article: This is a test>]>
>>> Article.objects.filter(reporter__in=[r, r2]).distinct()
<QuerySet [<Article: John's second story>, <Article: Paul's story>, <Article: This is a test>]>还可以使用查询集代替实例的列表,示例代码如下:
>>> Article.objects.filter(reporter__in=Reporter.obiects.filter(first__name='John')).distinct()
<QuerySet [<Article: John's second story>, <Article: This is a test>]>也支持反向查询,示例代码如下:
>>> Reporter.obiects.filter(article_pk=1)
<QuerySet [<Reporter: John Smith>]>
>>> Reporter.objects.filter(article=1)
<QuerySet [<Reporter: John Smith>]>
>>> Reporter.objects.filter(article=a)
<QuerySet [<Reporter: John Smith>]
>>> Reporter.objects.filter(article__headline__startswith='This")
<QuerySet [<Reporter: John Smith>, <Reporter: John Smith>,<Reporter: John Smith>]>
>>> Reporter.objects.filter(article__headline__startswith='This').distinct()
<QuerySet [<Reporter: John Smith>]>反向计数可以与distinct()结合使用,示例如下:
>>> Reporter.objects.filter(article_headline_startswith='This').count(3)
>>> Reporter.objects.filter(article_headline_startswith='This').distinct().count(1)查询可以转向自身,示例如下:
>>> Reporter.objects.filter(article__reporter__first__name__startswith='John")
<QuerySet [<Reporter: John Smith>, <Reporter: John Smith>, <Reporter: John Smith>, <Reporter: John Smith>]>
>>> Reporter.objects.filter(article__reporter__first__name_startswith='John').distinct()
<QuerySet [<Reporter: John Smith>]>
>>> Reporter.obiects.filter(article__reporter=r).distinct()
<QuerySet [<Reporter: John Smith>]>如果删除记者,则他的文章将被删除(假设ForeignKey是在django.db.models.ForeignKey.on_delete没置为CASCADE的情况下定义的,这是默认设置),示例代码如下:
>>> Article.objects.all()
<QuerySet [<Article: John's second story>, <Article: Paul's story>, <Article: This is a test>]>
>>>Reporter.objects.order_by('first_name')
<QuerySet [<Reporter: John Smith>, <Reporter: Paul Jones>]>
>>> r2.delete()
>>> Article.objects.all()
<QuerySet [<Article: John's second story>, <Article: This is a test>]>
>>> Reporter.objects.order_by('first_name')
<QuerySet [<Reporter: John Smith>]>也可以在查询中使用JOIN删除,示例代码如下:
>>> Reporter.objects.filter(article_headline_startswith='This').delete()
>>> Reporter.objects.all()
<QuerySet []>
>>> Article.objects.all()
<QuerySet []>多对多
多对多关系在数据库中也是非常常见的关系类型。比如一本书可以有好几个作者,一个作者也可写多本书。多对多的字段可以定义在任何一方,一般定义在符合人们思维习惯的一方,且不要同义。
定义多对多关系,需要使用ManyToManyField,语法格式如下:
class ManyToManyField(to, **options)[source]多关系需要一个位置参数——关联的对象模型,它的用法和外键多对一基本类似。下面通过文章和出版模型为例,说明如何使用多对多模型。
一篇文章(Article)可以在多个出版对象(Publication)中发布,一个出版对象可以具有多个文章对象。它们之间是多对多的关系,模型的定义如下:
from diango.db import models
class Publication(models.Model):
title = models CharField(max_length=30)
class Meta:
ordering =['title']
def __str__(self):
return self.title
class Article(models.Model):
headline = models.CharField(max_length=100)
publications = models.ManyToManyField(Publication)
class Meta:
ordering = ['headline']
def __str__(self):
return self.headline上述代码中,在Article模型中使用了ManyToManyField定义多对多关系。下面使用Shell命令执行多对多操作。创建一组Publication对象,示例代码如下:
>>> p1=Publication(title='The Python Joumal')
>>> p1.save()
>>> p2=Publication(title='Science News')
>>> p2.save()
>>> p3=Publication(title='Science Weekly')
>>> p3.save()创建Article对象,示例代码如下:
>>> a1 = Article(headline='Django lets you build Web apps easily')在将其保存之前,无法将其与Publication对象相关联,示例代码如下:
>>> a1.publications.add(p1)
Traceback (most recent call last):
...
ValueEror: "<Article: Django lets you build Web apps easily>" needs to have a value for field "id" before this many-to-many relationship can be used.保存对象,示例代码如下:
>>> a1.save()管理Arcticle对象和Publication对象,示例代码如下:
>>> a1.publications.add(p1)创建另一个Article对象,并将其设置为出现在Publications中,示例代码如下:
>>> a2 = Article(headline='NASA uses Python')
>>> a2.save()
>>> a2.publications.add(p1, p2)
>>> a2.publications.add(p3)再次添加是可以的,它不会重复该关系,示例代码如下:
>>> a2.publications.add(p3)添加错误类型的对象会引发TypeError,示例代码如下:
>>> a2.publications.add(a1)
Traceback (most recent call last):
TypeError: 'Publication' instance expected使用create()创建出版物并将其添加到文章,示例代码如下:
>>> new publication = a2.publications.create(title='Highlights for Children')Article对象可以访问其相关的Publication对象,示例代码如下:
>>> a1.publications.all()
<QuerySet [<Publication: The Python Journal>]>
>>> a2.publications.all()
<QuerySet [<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>, <Publication: The Python Journal>]>Publication对象可以访问其相关的Article对象,示例代码如下:
>>> p2.article_set.all()
QuerySet [<Article: NASA uses Python>]>
>>> p1.article_set.all()
<QuerySet [<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]>
>>>Publication.objects.get(id=4).article_set.all()
<QuerySet [<Article: NASA uses Python>]>可以使用跨关系的查询来查询多对多关系,示例代码如下;
>>> Article.objects.filter(publications_id=1)
<QuerySet [<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]>
>>> Article.objects.filter(publications_pk=1)
<QuerySet [<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]>
>>> Article.objects.filter(publications=1)
KQuerySet [<Article: Diango lets you build Web apps easily>, <Article: NASA uses Python>]>
>>> Article.objects.filter(publications=p1)
<QuerySet [<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]>
>>> Article.objects.filter(publications_title_startswith="Science")
<QuerySet [<Article: NASA uses Python>, <Article: NASA uses Python>]>
>>> Article.objects.filter(publications_title_startswith="Science").distinct()
<QuerySet [<Article: NASA uses Python>]>count()函数也支持distinct()函数,示例代码如下:
>>> Article.objects.filter(publications_title_startswith="Science").count()
>>> Article.objects.filter(publications titlestartswith="Science").distinct().count()
>>> Article.objects.filter(publications_in=[1,2]).distinct()
<QuerySet [<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]>
>>> Article.objects.filter(publications_in=[p1,p2]).distinct()
<QuerySet [<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]>如果删除Publication对象,则其Article将无法访问它,示例代码如下:
>>> p1.delete()
>>> Publication.objects.all()
<QuerySet [<Publication: Highlights for Children>,<Publication: Science News>,<Publication: SciencWeekly>]>
>>> a1 = Article.obiects.aet(pk=1)
>>> a1.publications.all()
<QuerySet []>如果删除Article,则其Publication也将无法访问,示例代码如下:
>>> a2.delete()
>>> Article.objects.all()
<QuerySet [<Article: Django lets you build Web apps easily>]>
>>> p2.article_set.all()
<QuerySet []>ModelAdmin
如果知识在admin中简单地展示和管理模型,那么在admin.py中使用admin.site.register注册即可,示例如下:
from django.contrib import admin
from myproject.myapp.models import Author
admin.site.register(Author)但是,很多时候为了满足业务需求,需要对admin进行深度定制。这时就可以使用Django为我们提供的ModelAdmin类了。ModelAdmin有很多内置属性,可以很方便地定制我们想要的功能。如:
from django.contrib import admin
class AuthorAdmin(admin.ModelAdmin):
date_hierarchy = 'pub_date'ModelAdmin.fields
fields属性定义添加数据时显示哪些字段。若fields字段没有定义,那么Django会按照模型的顺序逐个显示所有的非AutoField字段和editable=True的字段。
如,在blog/article/admin.py中,为ArticleAdmin模型定义fields属性。
class AuthorAdmin(admin.ModelAdmin):
# 显示字段
fields = ('id', 'title', 'content', 'publish_time')新增数据的页面中字段会每行显示一个、按顺序展示。
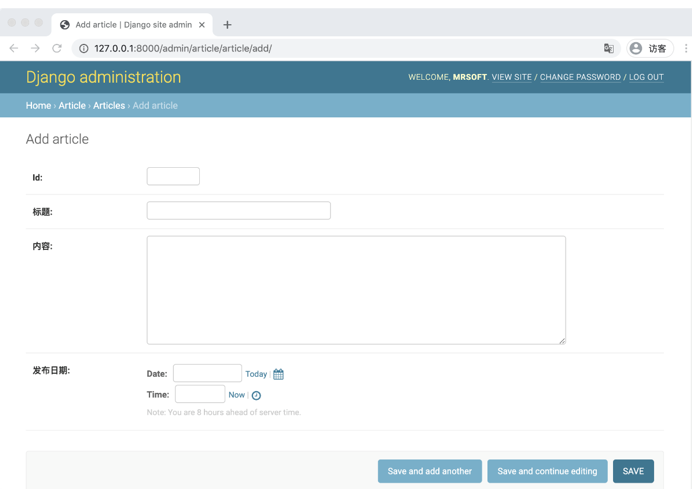
此外,可以通过组合元组的方式,让某些字段位于一行显示。
class AuthorAdmin(admin.ModelAdmin):
# 显示字段
fields = (('id', 'title'), 'content', 'publish_time')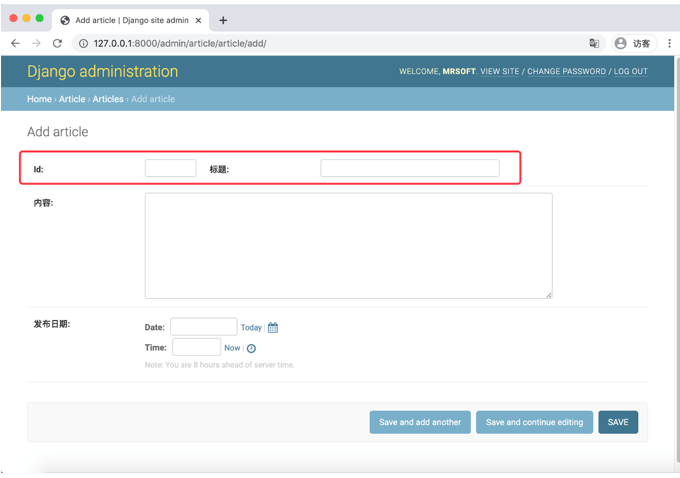
ModelAdmin.fieldset
fieldsets可根据字段对页面进行分组显示和布局。它是一个二元元组的列表,每个二元元组代表一个<fieldset>,是整个form的一部分。二元元组的格式为“(name, field_options”,name是标题,field_options是显示在fieldset内的字段列表。
field_options字典内,可以使用如下关键字:
- fields:一个必填的元组,包含要在fieldset中显示的字段。fields可以包含readonly_fields的值,作为组合字段。也可以通过组合元组的方式,使多个字段在一行内显示。
{
('fields':('id','title'), 'content')
}- classes:一个包含额外CSS类的元素。collapse可以将fieldset折叠起来,wide可以让它具备更宽的水平空间。
{
'classes': ('wide', 'extrapretty')
}- description:一个可选的额外说明文本,放在fieldset的顶部。这里的description没有转义,需要使用django.utils.html.escape()手动转义。
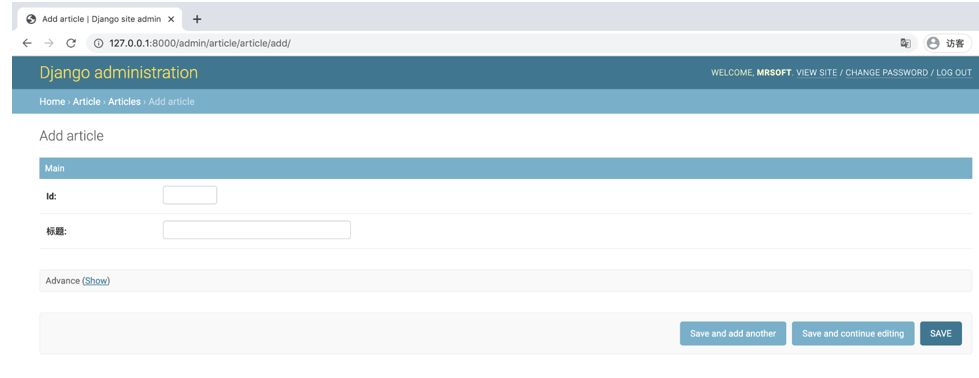
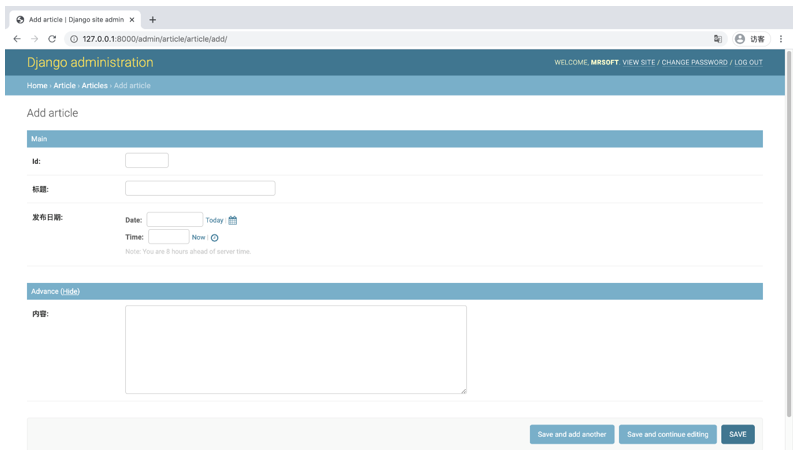
class ArticleAdmin(admin.ModelAdmin):
field = (
('Main', {
'fields': ('id', 'title', 'publish_time')
}),
('Advance', {
'classes': ('collapse',),
'fields': ('content',),
})
)fieldsets字段分为Main和Advance两个布局。在Advance内部,设置classes为collapse,会折叠Advance内部的字段,点击show会展开Advance内部的内容。
ModelAdmin.list_display
list_display可指定显示在列表页面上的字段。如:
list_display = ['first_name', 'last_name']若不设置这个属性,admin站点将只显示一页,内容为每个对象__str__()返回的内容。
在list_display中,可以设置4种值:模型字段、函数、ModelAdmin的属性和模型的属性。
- 设置模型字段
class ArticleAdmin(admin.ModelAdmin):
list.display = ['title', 'content', 'publish_time']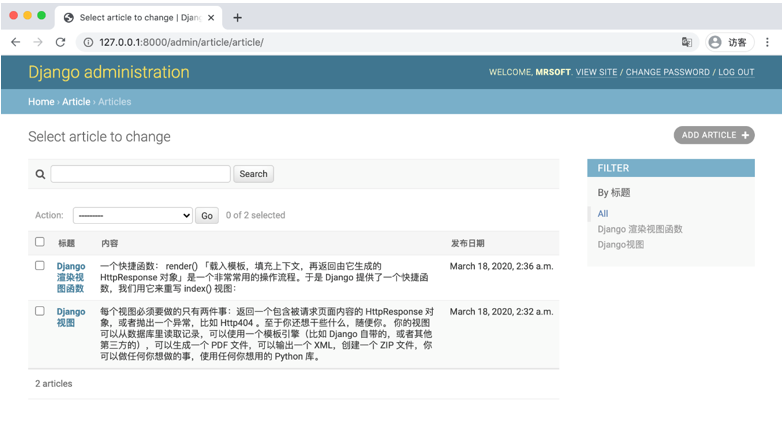
- 设置函数
def upper_case_name(obj):
return ("%s %s" % (obj.id, obj.title)).upper()
class ArticleAdmin(admin.ModelAdmin):
list_display = (upper_case_name,)
upper_case_name.short_description = 'Name'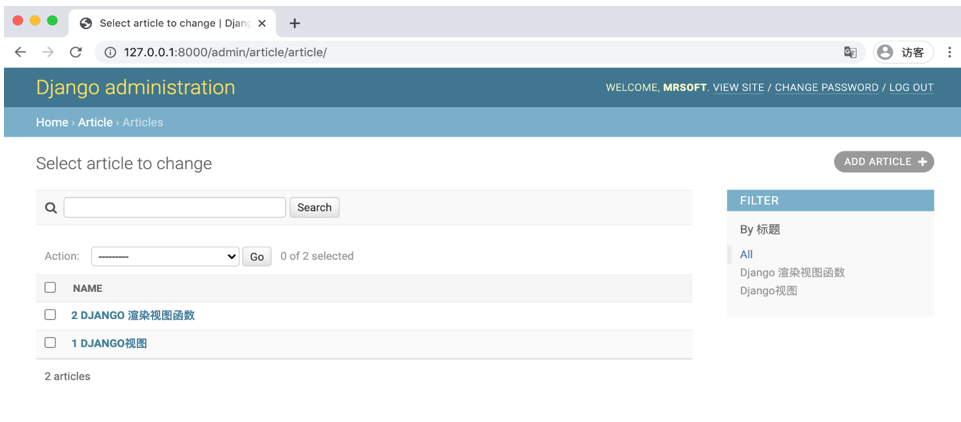
- 设置ModelAdmin的属性
类似函数调用,通过反射获取函数名,相当于换了种写法。
class ArticleAdmin(model.ModelAdmin):
list_display = ('upper_case_name',)
def upp_case_name(self, obj):
return ("%s %s" % (obj.id, obj.title)).upper()
upper_case_name.short_description = 'Name'- 设置模型的属性
类似第二种,但是此处的self是模型实例,引用的是模型属性。在blog/article/models.py中新增属性,代码如下:
class Article(models.Model):
id = models.IntegerField(primary_key=True)
title = models.CharField(max_length=20, verbose_name='标题')
content = models.TextField(verbose_name='内容')
publish_time = models.DateTimeField(verbose_name='发布日期')
user = models.ForeignKey(User, on_delete=models.CASCADE)
def __repr__(self):
return Article.title
def short_content(self):
return self.content[50:]
short_content.short_description = 'content'在blog/article/admin.py文件中将ArticleAdmin类的list_display属性设置short_content,代码如下:
class ArticleAdmin(admin.ModelAdmin):
list_display = ('id', 'title', 'short_content')运行结果如下:
注:
- 对于ForeignKey字段,显示的将是其__str__()方法的值。
- 不支持ManyToMany字段,需要自定义方法。
- 对于BooleanField或NullBooleanField字段,会用on/off图标代替True/False。
- 如果给list_display提供的值是一个模型的、ModelAdmin的或者可调用的方法,默认情况下会自动对返回结果进行HTML转义。
ModelAdmin.list_display_links
ModelAdmin.list_display_links指定用于链接修改页面的字段。通常情况下,list_display列表的第一个元素被作为指向目标修改页面的超链接点。使用它可以修改这个默认配置。
若设置为None,则取消链接,无法跳转到链接修改页面。若设定为一个字段的元组或列表(和list_dislay的格式一样),其中的每个元素都指向修改页面的链接。可以指定和list_display一样多的元素个数,Django不关心它的多少。要注意若要使用list_display_links,必须先指定list_display。
class ArticleAdmin(admin.ModelAdmin):
list_display = ('id', 'title', 'content', 'publish_time')
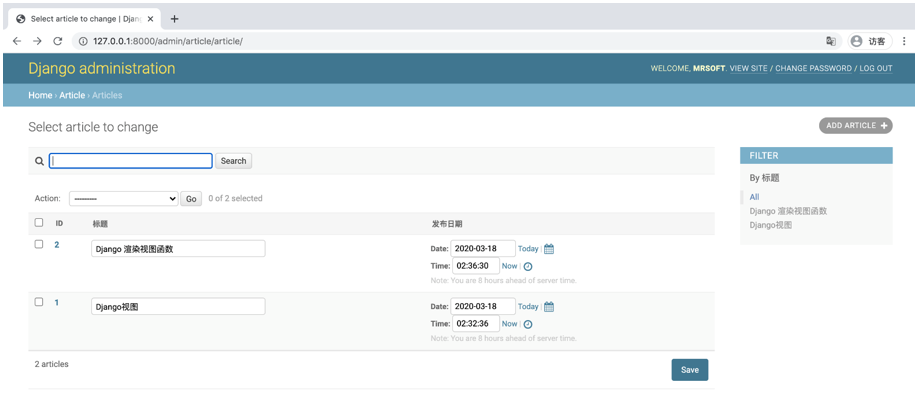
list_display_links = ('id', 'title')ModelAdmin.list_editable
该属性指定在修改列表页面中哪些字段可以被编辑。指定的字段将显示为编辑框,可修改后直接批量保存。
需要注意,不能将list_display中没有的字段设为list_editable,也不能将list_display_links中的元素设为list_editable。
class ArticleAdmin(admin.ModelAdmin):
list_display = ('id', 'title', 'content', 'publish_time')
list_display_links = ('id',)
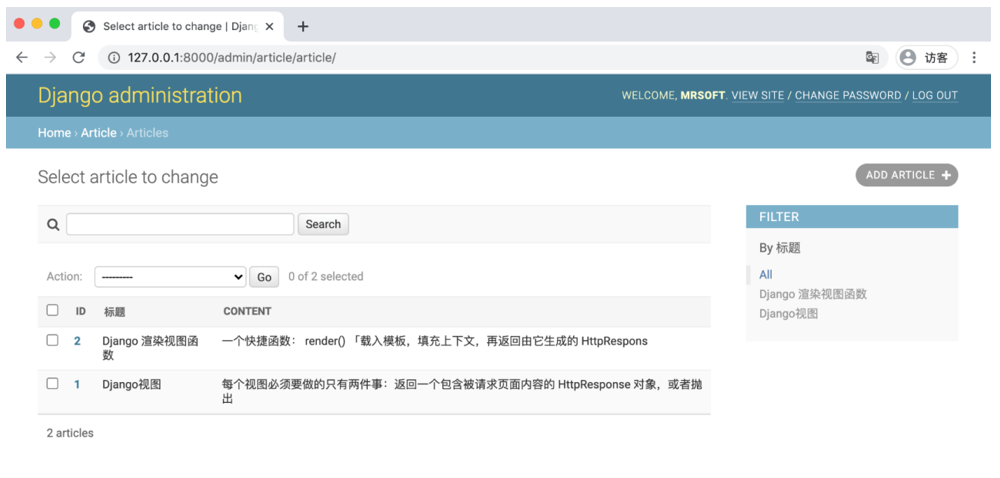
list_editable = ('title','publish_date')运行结果如下图。
ModelAdmin.list_filter
list_filter属性用于激活修改列表的右侧边栏,并对列表元素进行过滤。list_filter必须是一个元组或列表,其元素类型可以是字段名或django.contrib.admin.SimpleListFilter。
- 设置字段名
字段必须是BooleanFIeld、CharField、DateField、DateTimeField、IntegerField、ForeignKey或者ManyToManyFIeld中的一种。
class ArticleAdmin(admin.ModelAdmin):
list_filter = ('title',)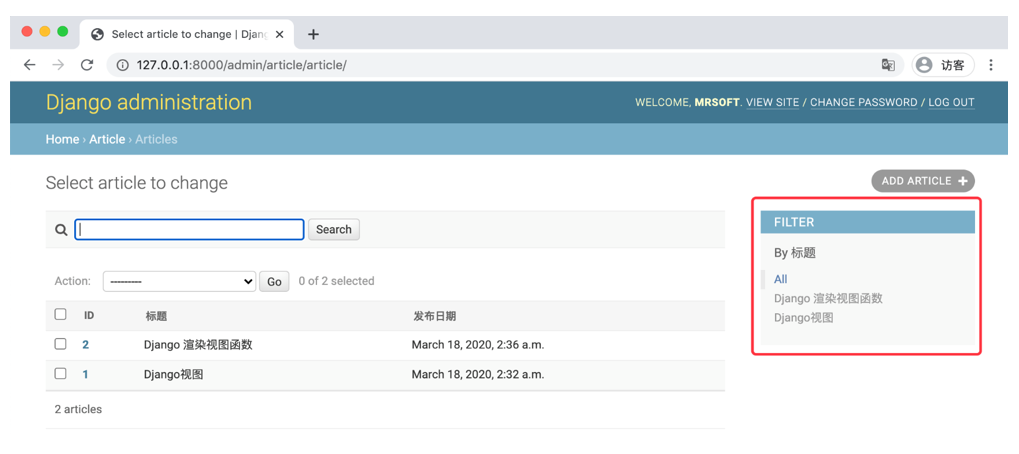
也可以使用双下画线进行跨表关联,如根据User模型的username条件过滤。
class ArticleAdmin(admin.ModelAdmin):
list_filter = ('title','user__username')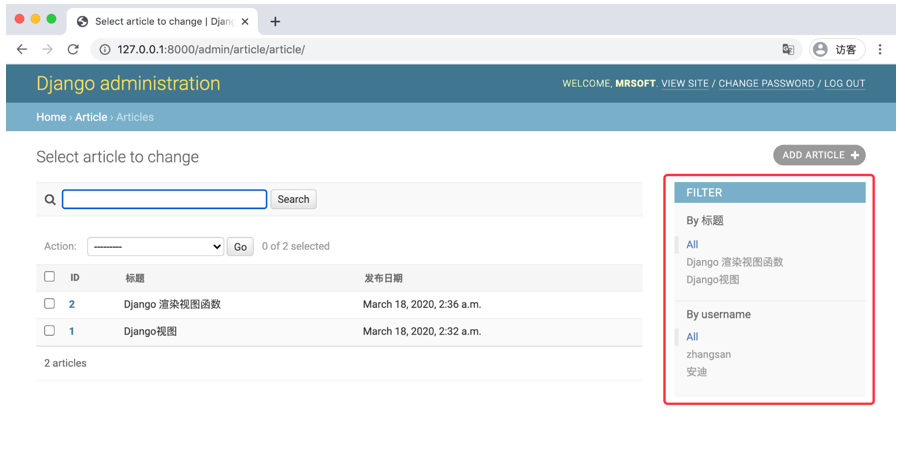
- 继承django.contrib.admin.SimpleListFilter类
继承此类后,需要提供title和parameter_name的值,并重写lookups()和queryset()方法:
class PublishYearFilter(admin.SimpleListFilter):
title = _('发布年份')
parameter_name = 'year'
def lookups(self, request, model_admin):
return (('2020', _('2020年')), ('2019', _('2019')))
def queryset(self, request, queryset):
if self.value() == '2019':
return queryset.filter(publish_time__gte=date(2019, 1, 1),
publish_time__lte=date(2019, 12, 31))
if self.value() == '2020':
return queryset.filter(publish_time__gte=date(2020, 1, 1),
publish_time__lte=date(2020, 12, 31))
class ArticleAdmin(admin.NodelAdmin):
list_filter = ('title', 'user__username', PublishYearFilter)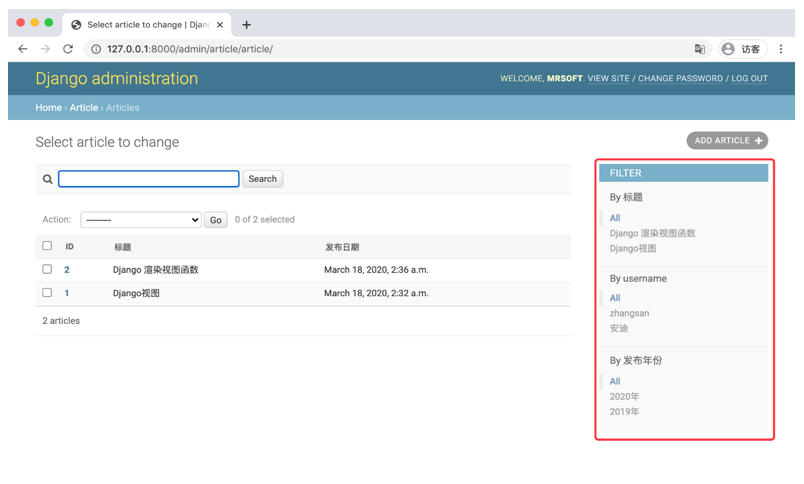
版权所有
版权归属: