主题
机器学习
人工智能相关概念
人工智能
人工智能 (AI) 是一组使计算机能够模拟人类智能,从而学习、推理、解决问题、感知环境并执行高级任务(如语言理解、图像识别)的技术。作为计算机科学的一个分支,它通过处理海量数据、应用机器学习和深度学习算法来不断优化,被广泛应用于自动驾驶、医疗诊断和智能助手等各行各业。
核心概览:
- 定义:是指制造智能机器的科学与工程,致力于让计算机模拟人类的学习、判断和行动。
- 三大核心要素:算力、算法、数据。
- 关键分类:
- 弱人工智能 (ANI):专注特定任务的AI(如Apple Siri、AlphaGo、图像识别),是目前普遍应用的类型。
- 通用人工智能 (AGI):具备与人类相当的广泛智慧,能执行任何智能任务。
- 超级人工智能 (ASI):理论上在所有领域远超人类智能的AI。
- 主要子领域:
- 机器学习 (ML):让计算机通过经验和数据自主学习。
- 深度学习 (DL):一种多层神经网络机器学习技术,是当前人工智能突破的主力。
- 自然语言处理 (NLP):实现人机自然语言交流。
- 计算机视觉:赋予机器看和识别物体的能力。
- 当前应用:生成式AI(如ChatGPT生成文本、图像)、自动驾驶汽车、数据分析挖掘、医疗诊断、金融风控等。
人工智能正迅速改变世界,是一项以数据驱动决策并最大化成功机会的变革性技术。
机器学习
机器学习是人工智能的一个分支,向系统输入大量数据后,系统会使用神经网络和深度学习进行自主学习和改进,无需对其明确编程。机器学习可让计算机系统通过累积更多“经验”来不断调整并增强自身功能,因此,通过提供更大、更多样化的数据集进行处理,可以提高这些系统的性能。
深度学习
深度学习(Deep Learning)是机器学习的一个子集,基于多层人工神经网络模拟人脑处理数据,擅长从海量数据中自动学习复杂的非线性特征。它无需人工干预即可进行特征提取(如卷积神经网络 CNN、循环神经网络 RNN),广泛应用于计算机视觉、语音识别和自然语言处理等领域。其核心在于通过隐藏层逐层抽象数据信息。
深度学习的核心原理与特点
- 多层神经网络架构: 深度学习的“深度”是指网络中拥有多个隐藏层,能够层层处理、提取不同级别的特征(从低级边缘到高级物体)。
- 自动化特征工程: 区别于传统机器学习,深度学习能自动从原始数据中学习有效的表征,避免了手动设计特征的繁琐和限制。
- 依赖大数据和大算力: 其性能随数据量增加而提升,处理复杂任务需要强大的计算资源。
常见深度学习模型类型
- 卷积神经网络(CNN): 擅长处理图像和视频数据,通过卷积和池化过滤图片信息。
- 循环神经网络(RNN/LSTM): 专门处理时序数据或序列数据,具备记忆前一层信息的能力。
- 生成对抗网络(GAN): 通过生成器与判别器的博弈提升输出准确率,常用于图像生成。
主要应用领域
- **计算机视觉:**人脸识别、物体检测、自动驾驶。
- **语音与自然语言处理:**语音转文字、机器翻译、智能对话助手。
- **预测与分析:**数据集中的复杂模式分析与见解生成。
深度学习不仅能模拟生物神经网络的运作,更是目前解决强人工智能技术中最具潜力的途径之一。
人工智能中包括机器学习,机器学习中又包括深度学习。

机器学习相关概念
| 名称 | 英文 | 所属层级 | 严格定义 | 在数据中的位置 | 主要作用 | 示例 |
|---|---|---|---|---|---|---|
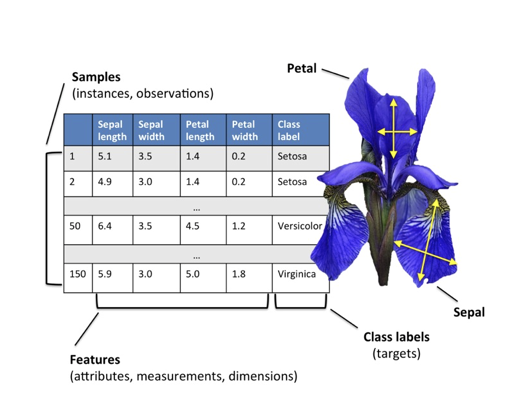
| 样本 | Sample | 行级 | 数据集中的一条独立观测记录 | 一行 | 表示一个研究对象 | 一条用户记录 / 一封邮件 / 一套房 |
| 特征 | Feature | 列级(输入) | 描述样本属性的输入变量 | 多列 | 作为模型输入 | 年龄、面积、点击次数 |
| 标签 | Label / Target | 列级(输出) | 样本对应的真实结果值 | 通常1列 | 作为监督学习的目标 | 是否违约、房价、类别 |
| 训练集 | Training Set | 数据子集 | 用于训练模型参数的数据集合 | 样本子集 | 让模型学习规律 | 用来“拟合”模型 |
| 测试集 | Test Set | 数据子集 | 用于评估模型效果的数据集合 | 样本子集 | 检验泛化能力 | 用来“打分”模型 |
| 学习类型 | 是否需要标签 | 核心目标 | 典型任务 | 输出形式 | 训练方式 |
|---|---|---|---|---|---|
| 有监督学习 | 必须有 | 学习输入→输出映射 | 分类、回归 | 预测值 | 用已知答案训练 |
| 无监督学习 | 不需要 | 发现数据结构 | 聚类、降维 | 结构/分组 | 自动找模式 |
| 半监督学习 | 少量有标签 | 利用未标注数据 | 分类 | 预测值 | 混合训练 |
| 强化学习 | 没有固定标签 | 学习最优策略 | 决策控制 | 动作策略 | 奖励驱动 |
机器学习的建模流程
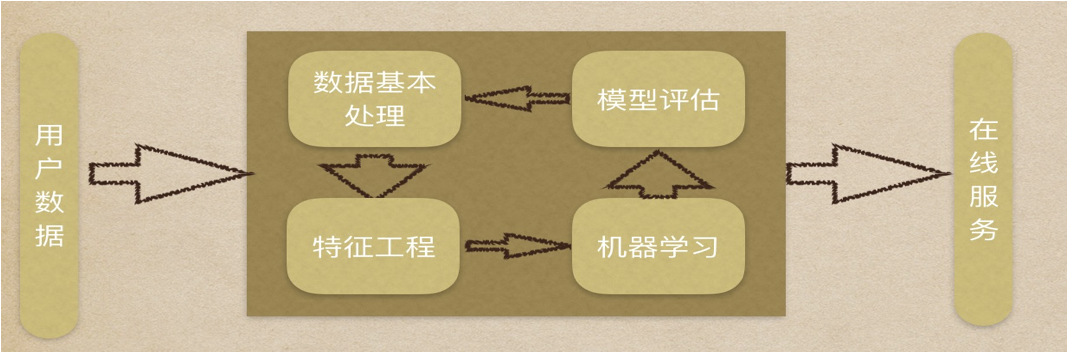
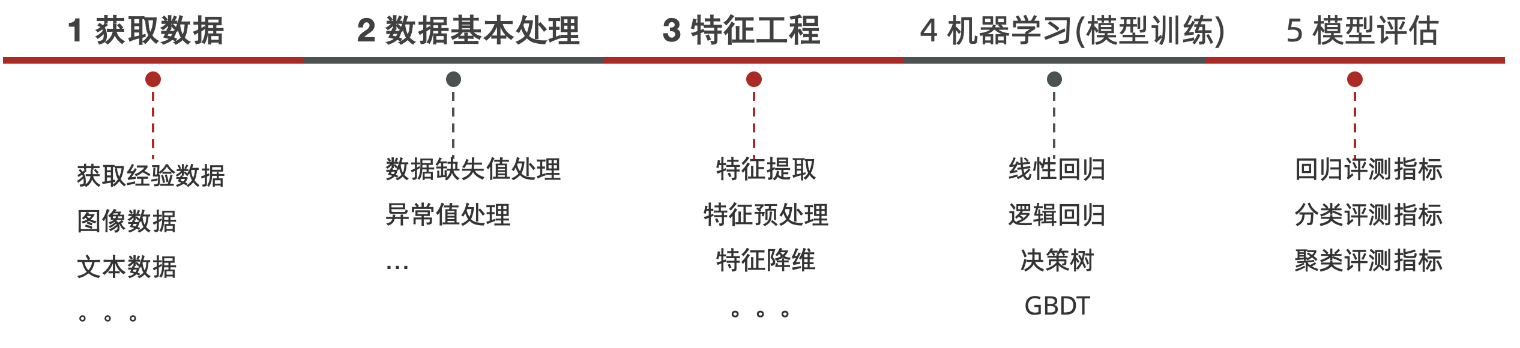
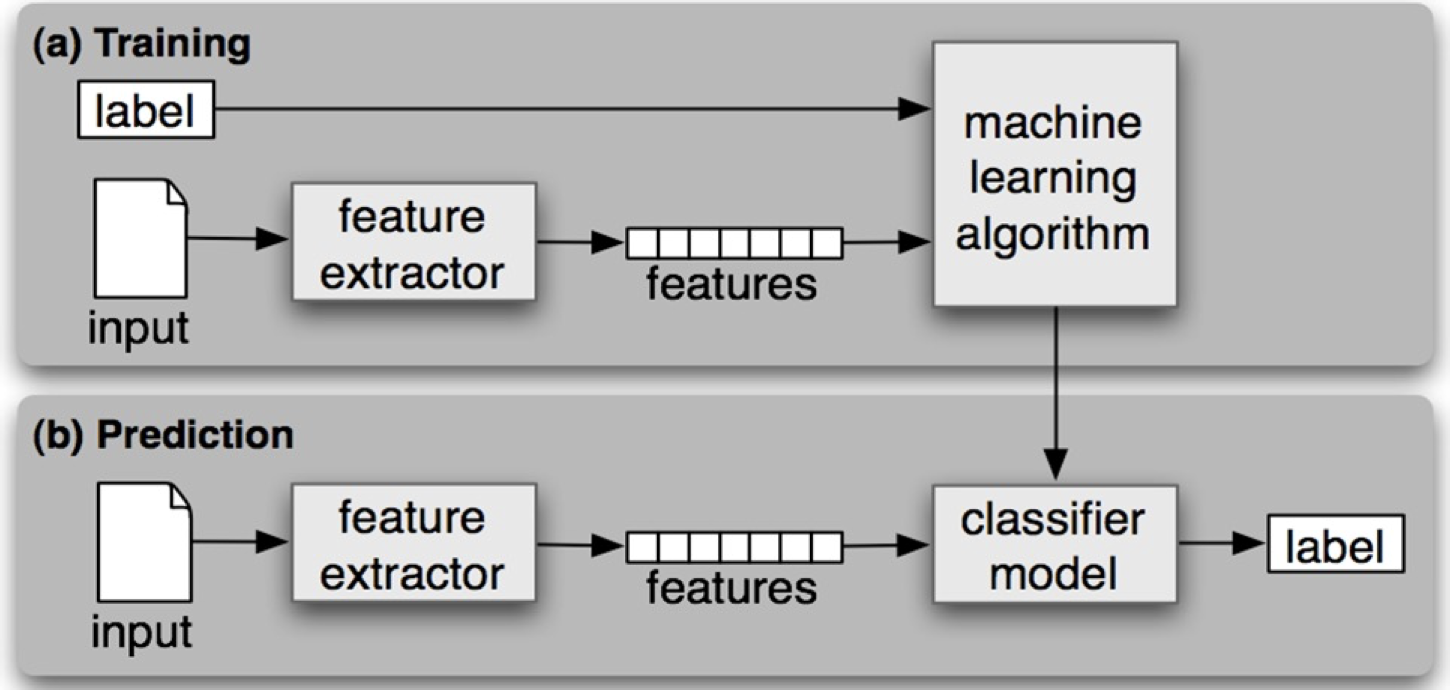
特征工程
特征:数据集中,一列一列的数据为特征;模型训练中,对预测结果有用的叫特征。
特征工程:利用专业背景知识和技巧处理数据,让机器学习算法效果最好。
特征工程是机器学习周期中最困难、最耗时的任务,需要专业知识。
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
特征提取
从原始任务中提取和任务相关的特征,构成特征向量。

特征预处理
特征会影响模型。因量纲问题,有些特征对模型影响大,有些影响小。如通过一个人的身高和体重预测这个人的健康状况,如果身高的单位是cm和m,对模型的影响就不一样。
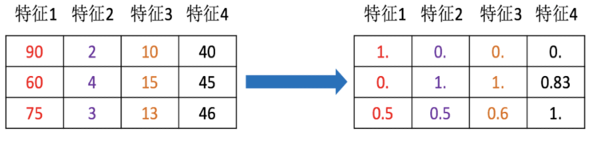
将不同的单位的特征数据转换成同一个范围内,使训练数据中不同特征对模型产生较为一致的影响。
特征降维
将原始数据的维度降低,叫做特征降维。
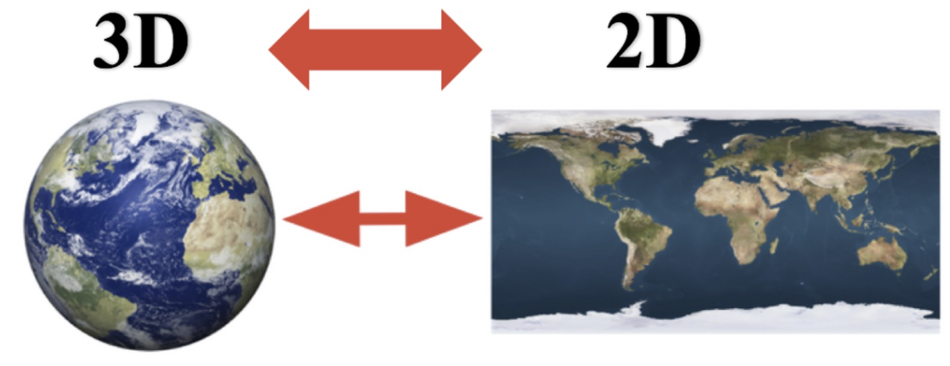
降维会丢失部分信息,降维就需要保证数据的主要信息要保留下来。原始数据会发生变化,不需要了解数据本身是什么含义,它保留了最主要的信息。
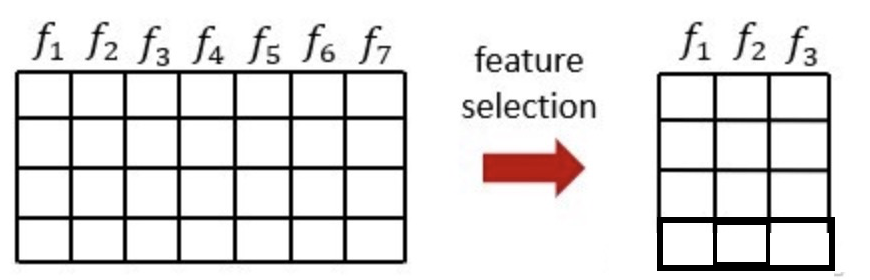
从特征中选择出一些重要特征(选择就需要根据一些指标来选择),特征选择不会改变原来的数据。
模型拟合
在机器学习或统计建模中,通过已有数据去“训练”一个数学模型,使模型参数被确定下来,从而让模型输出尽可能接近真实结果的过程。
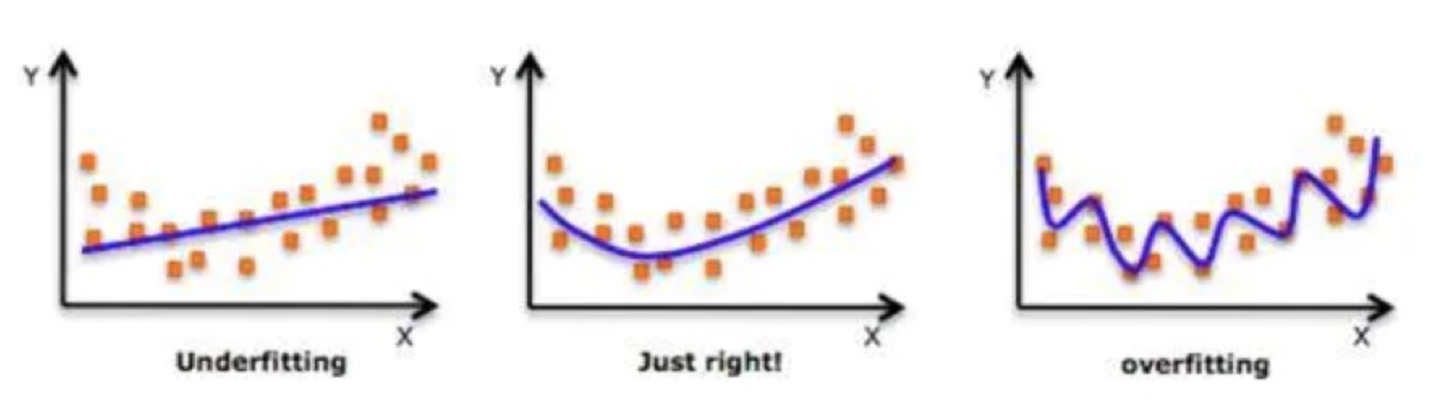
如果模型对训练集理解好,测试集理解也好,能泛化到新数据,就称为拟合良好。
如果模型对训练集和测试集理解都不好,就称为欠拟合,比如用一条直线去拟合明显弯曲的数据。
如果模型对测试集理解良好,但是测试集理解不好,就称为过拟合,好像把每个训练点都“死记硬背”。
| 维度 | 拟合良好(Good Fit) | 过拟合(Overfitting) | 欠拟合(Underfitting) |
|---|---|---|---|
| 基本定义 | 模型正确捕捉主要规律 | 模型把噪声也当成规律 | 模型没有学到有效规律 |
| 训练集误差 | 低 | 很低 | 高 |
| 测试集误差 | 低 | 高 | 高 |
| 泛化能力 | 强 | 弱 | 弱 |
| 模型复杂度 | 合适 | 过高 | 过低 |
| 对数据模式 | 抓住趋势 | 记住细节 | 忽略结构 |
| 曲线形态类比 | 平滑贴合趋势 | 过度弯曲抖动 | 过于简单僵直 |
| 是否学习噪声 | 不会 | 会 | 基本没学到 |
| 常见原因 | 特征与模型匹配 | 参数太多、模型太复杂、数据少 | 模型太简单、特征不足 |
| 训练时表现 | 稳定收敛 | 训练效果极好 | 训练效果也不好 |
| 新数据表现 | 稳定 | 明显变差 | 依旧很差 |
| 典型例子 | 合理阶数的回归曲线 | 高阶多项式强行穿点 | 用直线拟合非线性关系 |
| 改进方向 | 保持或微调 | 降复杂度、加正则、加数据 | 增复杂度、加特征、延长训练 |
scikit-learn
基于 Python 的 scikit-learn 库是机器学习的库之一,特点:
- 简单高效的数据挖掘和数据分析工具;
- 可供大家使用,可在各种环境中重复使用;
- 建立在 NumPy,SciPy 和 matplotlib 上;
- 开源,可商业使用-获取 BSD 许可证。
安装:pip install scikit-learn