Python爬虫笔记
此笔记还未完成。
环境配置
本笔记在记录之初安装了如下环境:Python3.11、Windows本机安装MySQL、Linux CentOS安装Redis、Windows本机的Docker安装MongoDB、Selenium、Windows本机安装nodejs。
HTML页面的信息提取
XPath
XPath是一钟确认文档位于XML位置的语言,它同样适用于HTML。它提供了超过100个内置函数、用于字符串、时间、数字的匹配以及序列、节点的处理。现在流行的XPath版本为3.1。
Xpath术语
- 节点:XPath中有七种节点:元素节点、属性节点、文本节点、命名空间节点、处理指令节点、注释节点和文档节点。
- 父节点、子节点:和DOM中的概念类似。
- 同胞节点:若两个节点有相同的父节点,那么它们就互称为同胞节点。
Xpath表达式
最常见的XPath表达式就是路径表达式。路径表达式就是从一个节点到另一个节点或一组节点的书面步骤顺序。这些步骤以“/”字符分开,每一步有三个组成成分:轴描述、节点测试、节点名称。
- 简写的XPath表达式
如一个div位于文本中的位置如下:<html><body><div></div><body><html>,那么它的位置使用XPath表示就是/html/body/div。
- 完整的XPath表达式
在XPath语法的每个步骤里,用完整的轴描述,然后使用“::”,它的后面跟着节点测试的内容。
- 轴描述语法
轴描述元素用于表示HTML文档分支的遍历方向。
| 坐标 | 名称 | 缩写语法 |
|---|---|---|
| child | 子节点 | 默认,不需要 |
| attribute | 属性 | @ |
| descendant | 子孙节点 | 不提供 |
| desendant-or-self | 自身引用及子孙节点 | // |
| parent | 父节点 | .. |
| ancestor | 祖先节点 | 不提供 |
| ancestor-or-self | 自身引用及祖先节点 | |
| following | 下文节点 | |
| preceding | 前文节点 | |
| following-sibiling | 下一个同级节点 | |
| preceding-sibiling | 上一个同级节点 | |
| self | 自己 | |
| namespace | 名称空间 |
attribute坐标简写语法的一个范例就是//a/@href,在HTML文档书里,选择所有a元素的href属性。self坐标通常和术语同用,以参考当前的选定节点。如h3[.='See also']在当前节点选中了h3的元素,该元素的内容为See also。
节点测试
节点测试的对象通常包括特定节点名或者一般的表达式。
- comment():寻找HTML注释节点。
from lxml import etree
html = """
<p>这是没有注释的内容</p>
<!--这是被注释的内容-->
"""
xp = etree.HTML(html)
print(xp.xpath('//comment()'))
[<!--这是被注释的内容-->]
- text():寻找某点的文字型别,例如在
<p>Hello</p>节点中寻找Hello。
from lxml import etree
html = """
<p>这是没有注释的内容</p>
<!--这是被注释的内容-->
"""
xp = etree.HTML(html)
print(xp.xpath('//p/text()'))
['这是没有注释的内容']
- node():寻找所有节点。
from lxml import etree
html = """
<div><p id='content'>这是没有注释的内容</p>
<!--这是被注释的内容--></div>
"""
xp = etree.HTML(html)
print(xp.xpath('//div/node()'))
[<Element p at 0x2691d7d6300>, '\n', <!--这是被注释的内容-->]
节点描述
节点描述用于返回符合特定条件的节点,如//a[@href='help.php']会选择所有href属性为help.php的a节点,//a[@href='help.php'][name(..)='div'][../@class='header']会返回href属性为help.php、具有父元素div且它的class属性为header的a节点。
XPath运算符
| 运算符 | 描述 | 示例 | 返回值 |
|---|---|---|---|
| | | 两个节点集并集 | xpath('//div|//a') | 返回所有的div元素节点和a节点 |
| +/-/*/div | 加减乘除 | xpath('//div[2-1]') | 返回所有div元素的第一个结果 |
| = | 等于 | xpath('//a[href="baidu.com"]') | 返回所有href值为baidu.com的a元素 |
| != | 不等于 | ||
| </<=/>/>= | 小于/小于等于/大于/大于等于 | xpath('//input[@value>2]') | 返回所有value属性大于2的input元素 |
| or/and | 或/并且 | xpath('//input[@value=1 or @value=2]') | 返回所有value属性等于1或2的input元素 |
| mod | 取余 |
练手:
from lxml import etree
html = """<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Xpath教程</title>
</head>
<body>
<ul>
<li><a href="www.likeinlove.com/index.html">出师未捷身先死,长使英雄泪满襟。</a></li>
<li><a href="www.likeinlove.com/home.html">风急天高猿啸哀,渚清沙白鸟飞回。</a></li>
<li>仲夏苦夜短,开轩纳微凉。</li>
<!-- 以上是杜甫部分名句-->
</ul>
<p id="4">万里悲秋常作客,百年多病独登台。</p>
<p id="5">清江一曲抱村流,长夏江村事事幽。</p>
<div>
<ul>
<li>满月飞明镜,归心折大刀。</li>
<li>射人先射马,擒贼先擒王。</li>
<li>留连戏蝶时时舞,自在娇莺恰恰啼。</li>
<li>正是江南好风景,落花时节又逢君。</li>
</ul>
</div>
</body>
</html>
"""
xp = etree.HTML(html)
print('获取标题内容',xp.xpath('//title/text()'))
print('获取页面语言',xp.xpath('//html/@lang'))
print('获取页面超链接',xp.xpath('//a/@href'))
print('获取id为4的诗句',xp.xpath('//p[@id=4]/text()'))
获取标题内容 ['Xpath教程']
获取页面语言 ['en']
获取页面超链接 ['www.likeinlove.com/index.html', 'www.likeinlove.com/home.html']
获取id为4的诗句 ['万里悲秋常作客,百年多病独登台。']
XPath常用函数
| 函数 | 作用 | 示例 |
|---|---|---|
| contains(string1, string2) | 若string1包含string2,返回True | xpath('//a[contains(@href, "baidu")]') |
| starts-with(string1, string2) | 若string1以string2看开始,返回True | xpath('//a[starts-with(@href, "baidu")]') |
| substring(string, start, len) | 截取字符串string,start代表起始位置,第一个字符的下标为1,len可省略,表示截取到末尾 | xpath('//a[substring(@href,1,5)="https"]') |
| string-length(string) | 返回指定字符串的长度,若string不填写则返回当前节点的字符串的长度 | xpath('//a[string-length(@href)=18]') |
| position() | 返回当前正在被处理的节点的index位置 | xpath('//*[@value=3][posotion()=2]') |
| last() | 返回在被处理的节点哄的项目数目 | xpath('//li[last()=3]') |
| true() | 返回True | |
| false() | 返回False | |
| name(nodeset) | 指定节点集中的第一个节点的名称,若不传参数则为当前节点名称 | xpath('//*name()="div"') |
| count(nodeset) | 返回节点的数量 | xpath(//p[count(//p)=3]) |
XPath常见错误
- Unregistered Function:未注册该函数。
- Invalid Predicate:无效谓词。
- Unfinished Literal:表达式不完整。
使用Python解析HTML
Python解析HTML的库有lxml、BeautifulSoup4、pyquery等。第一个主要提供XPath语法的选择器,第二个则依赖Python标准库,提供了节点选择器,第三个提供CSS选择器。
使用这以下的代码分别安装这三个模块。
pip install lxml
pip install bs4
pip install pyquery
下面的代码将尝试用这三个库提取如下HTML代码中的这段话。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标题</title>
</head>
<body>
<p>这是网页中的一段话。</p>
</body>
</html>
- lxml
#/html/body/p
from lxml import etree
html = """<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标题</title>
</head>
<body>
<p>这是网页中的一段话。</p>
</body>
</html>"""
xp = etree.HTML(html)
items = xp.xpath('//html//body//p//text()')
print(items)
['这是网页中的一段话。']
- BeautifulSoup4
#/html/body/p
from bs4 import BeautifulSoup
html = """<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标题</title>
</head>
<body>
<p>这是网页中的一段话。</p>
</body>
</html>"""
bs = BeautifulSoup(html, 'lxml')
items = bs.select('p')
print(items)
[<p>这是网页中的一段话。</p>]
- pyquery
from pyquery import PyQuery as query
html = """<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标题</title>
</head>
<body>
<p>这是网页中的一段话。</p>
</body>
</html>"""
pq = query(html)
items = pq('p')
print(items)
<p>这是网页中的一段话。</p>
- Scrapy
使用pip install scrapy安装Scrapy框架。
在CMD中输入如下命令爬取百度网页。
scrapy shell https://baidu.com/
(venv) PS A:\Crawler> scrapy shell https://baidu.com/
2023-07-04 10:14:16 [scrapy.utils.log] INFO: Scrapy 2.9.0 started (bot: scrapybot)
2023-07-04 10:14:16 [scrapy.utils.log] INFO: Versions: lxml 4.9.2.0, libxml2 2.9.12, cssselect 1.2.0, parsel 1.8.1, w3lib 2.1.1, Twisted 22.10.0, Python 3.11.3 (tags/v3.11.3:f3909b8, Apr 4 2023, 23:49:59) [MSC v.1934 64 bit (AMD64)], pyOpenSSL 23.2.0 (OpenSSL 3.1.1 30 May 2023), cryptography 41.0.1, Platform Windows-10-10.0.22621-SP0
2023-07-04 10:14:16 [scrapy.crawler] INFO: Overridden settings:
{'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter',
'LOGSTATS_INTERVAL': 0}
2023-07-04 10:14:16 [py.warnings] WARNING: A:\Crawler\venv\Lib\site-packages\scrapy\utils\request.py:232: ScrapyDeprecationWarning: '2.6' is a deprecated value for the 'REQUEST_FINGERPRINTER_IMPLEMENTATION' setting.
It is also the default value. In other words, it is normal to get this warning if you have not defined a value for the 'REQUEST_FINGERPRINTER_IMPLEMENTATION' setting. This is so for backward compatibility reasons, but it will change in a future version of Scrapy.
See the documentation of the 'REQUEST_FINGERPRINTER_IMPLEMENTATION' setting for information on how to handle this deprecation.
return cls(crawler)
2023-07-04 10:14:16 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor
2023-07-04 10:14:16 [scrapy.extensions.telnet] INFO: Telnet Password: 94183a2e9ea1d51f
2023-07-04 10:14:16 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole']
2023-07-04 10:14:17 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2023-07-04 10:14:17 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2023-07-04 10:14:17 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2023-07-04 10:14:17 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2023-07-04 10:14:17 [scrapy.core.engine] INFO: Spider opened
2023-07-04 10:14:17 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET http://www.baidu.com/> from <GET https://baidu.com/>
2023-07-04 10:14:17 [urllib3.connectionpool] DEBUG: Starting new HTTPS connection (1): publicsuffix.org:443
2023-07-04 10:14:17 [urllib3.connectionpool] DEBUG: https://publicsuffix.org:443 "GET /list/public_suffix_list.dat HTTP/1.1" 200 79166
2023-07-04 10:14:18 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.baidu.com/> (referer: None)
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x000001D512470C90>
[s] item {}
[s] request <GET https://baidu.com/>
[s] response <200 http://www.baidu.com/>
[s] settings <scrapy.settings.Settings object at 0x000001D5123D2310>
[s] spider <DefaultSpider 'default' at 0x1d512b14c10>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
然后在输入框内输入如下内容,获取百度搜索文字的“百度一下”。
>>> response.xpath('//input[@id="su"]/@value')
[<Selector query='//input[@id="su"]/@value' data='百度一下'>]
第一条命令scrapy shell是Scrapy库提供的shell交互式命令,它可用于检测网页对爬虫的友好程度,测试目标页面的加载情况等。第二条命令则是解析网站的内容。response为Scrapy库的内置对象,请求网站后会发给回调函数进行解析。
- selenium
使用pip install selenium安装selenium库,并根据你的浏览器内核安装对应的WebDriver浏览器驱动并将它放在Python解释器的同级目录下。它是一个自动化的测试软件,可以使我们脱离双手操作浏览器。
from selenium import webdriver
from selenium.webdriver.common.by import By
with webdriver.Chrome() as driver:
driver.get('https://www.baidu.com/')
el = driver.find_element(by=By.XPATH, value='//input[@id="su"]')
text = el.get_attribute('value')
print(text)
运行这段代码后,Chrome会自动打开,然后显示一下百度的网站,之后显示出结果。
书中通过XPath获取元素节点的方法为
find_element_by_xpath(),但是在selenium4.0中此方法已被弃用,改为find_element(By.XPATH)替代。
- requests
使用pip install requests安装requests模块。
import requests
from lxml import etree
response = requests.get('https://www.baidu.com/')
response.encoding = 'utf-8'
xp = etree.HTML(response.text)
text = xp.xpath('//input[@id="su"]/@value')
print(text)
['百度一下']
- requests_HTML
使用pip install requests_html安装Requests_HTML库。
from requests_html import HTMLSession
session = HTMLSession()
response = session.get('https://www.baidu.com/')
text = response.html.xpath('//input[@id="su"]/@value')
print(text)
['百度一下']
日志模块
在程序开发中,日记记录是不可缺少的。Python处理日志的模式是logging,它是内置模块之一,提供了丰富的处理流,包括写入文件、发送到邮箱、发送到控制台等。Python中常用的异常处理信息输出如下表所示。
| 场景 | 推荐措施 |
|---|---|
| 将结果显示在控制台 | print() |
| 监控和记录程序运行状态 | 使用logging.info()函数(当由诊断目的需要详细输出的使用logging.debug()函数) |
| 发出一个警告信息 | 使用logging.warning(),在控制台显示红色 |
| 对业务之外的错误处理 | 抛出异常 |
| 只报告错误,不抛出异常 | 使用logging.error()函数 |
日志的使用
使用import logging导入日志模块。
日志模块有以下该概念:
- 记录器:Logger是日志的记录器,对外提供logging的接口,应用程序可以直接使用这个对象。
- 处理器:Handler是日志的处理器,负责将适当的日志信息分派成处理程序的目标。
- 格式化器:Formatter是日志的格式化器,负责将日志按照格式字符串输出。
- 过滤器:Filter是日志的过滤器,提供了更加精细的附加功能。
- 日志级别:用于划分错误的严重级别。
- 日志等级
日志等级分为6钟,如下表。
| 级别 | 数值 | 备注 |
|---|---|---|
| NOTSET | 0 | 当logger是根logger时,将处理所有消息,若logger是非根logger,则所有消息会委派给父级 |
| DEBUG | 10 | 细节消息,仅当诊断问题时使用 |
| INFO | 20 | 确认程序按预期执行 |
| WARNING | 30 | 表明有已经或即将发生的意外,程序仍按预期执行 |
| ERROR | 40 | 由于严重的问题,程序的某些功能已经不能正常执行 |
| CRITICAL | 50 | 有严重的错误,程序不能继续执行 |
- 格式化器
格式化器对象用于配置日志信息的输出内容,由一些字符串定义。
| 字段 | 含义 |
|---|---|
| %(levelno)s | 打印日志级别的数值 |
| %(levelname)s | 打印日志级别名称 |
| %(pathname)s | 打印当前执行程序的路径,相当于sys.argv[0] |
| %(filename) | 打印当前执行程序名 |
| %(funcName)s | 打印日志的当前函数 |
| %(lineno)d | 打印日志的当前函数 |
| %(asctime)s | 打印日志的时间 |
| %(thread)d | 打印线程ID |
| %(threadName)s | 打印线程名称 |
| %(process)d | 打印进程ID |
| %(message)s | 打印日志信息 |
| %(msecs)d | 打印记录时的毫秒部分 |
| %(created)f | 打印记录时的时间戳 |
| %(name)s | 打印记录器的名称,默认为root |
| %(processName)s | 打印进程名 |
| %(relativeCreated)d | 打印日志记录时相对于日志模块初始化的时间(毫秒) |
| %(module)s | 打印模块 |
Logger
记录器对外提供logging的接口。它具有以下属性。
propagate:判断日志是否向上传播。setLevel(level):设置记录阈值,日志等级大于阈值的会被记录。默认为WARNING级别。isEnabledFor(level):判断当前记录器是否处理级别为参数传入的level级别信息。getEffectiveLevel():获取此记录器的有效级别。getChild(suffix):用于返回由参数确定的记录器。debug(msg, *args, **kwargs):用于DEBUG在此记录器上记录级别的消息,在关键字参数中制定了三个参数:exc_info:若不为False,则将异常信息添加到日志信息中。stack_info:若为True,则将堆栈信息添加到日志信息中。extra:它不常用,可通过字典指定。
info(msg, *args, **kwargs):用于记录INFO级别的信息。- 以下函数都是记录对应级别的信息:
warning(msg, *args, **kwargs)、error(msg, *args, **kwargs)、critical(msg, *args, **kwargs)、log(msg, *args, **kwargs)、exception(msg, *args, **kwargs)。 addFilter(filter):将过滤器添加到记录器。remove(filter):从记录器中移除过滤器。filter(record):用过滤器检查记录事件对象record,若有一条不符合要求则不处理此事件。addHandler(hdlr):将处理程序添加到记录器。removeHandler(hdlr):从记录器中删除指定的处理程序。findCaller(stack_info=False):以元组形式返回记录器所在的文件名、行号、函数名称和堆栈信息。handle(record):将记录对象record传递给记录器或其祖先关联的所有处理程序。此方法用于从套接字接受的为选择记录以及本机创建记录。makeRecord(name, lvl, fn, info, lno, msg, exe_info, func=None, extra=None, sinfo=None):用于重写或创建专门的LogRecord实例。hasHandler:用于检查此记录是否配置了处理程序。
import logging
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
class MyFilter(logging.Filter):
def filter(self, record: object) -> bool:
return "测试消息" not in record.msg
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
formatter = logging.Formatter('%(asctime)s - %(filename)s[line: %(lineno)d] - %(levelname)s: %(message)s - %(name)s')
ch.setFormatter(formatter)
logger.addHandler(ch)
filter = MyFilter()
logger.addFilter(filter)
if __name__ == '__main__':
logger.info('这是日志消息')
logger.info('过滤器将过滤掉含测试消息字段的日志')
logger.removeFilter(filter)
logger.info('移除测试消息过滤器')

Handler
Handler的作用是负责将适当的日志消息分派给对应的处理程序。一般不直接实例化Handler,它只是一个基类,它内部提供了很多处理程序,直接使用它们即可。
它的属性和方法如下:
__init__(level=NOTSET):初始化实例,传入处理日志级别。createLock():初始化一个线程锁,确保对文件访问是安全的。acquire():获取使用createLock()初始化的线程锁。release():释放锁。setLevel(level):设置处理阈值。setFormatter(fmt):设置消息格式。addFilter(filter):添加过滤器。removeFilter(filter):移除过滤器。filter(record):将此处理器的过滤器应用于记录,若要处理该条记录,则返回True。依次查询过滤器,直到其中返回一个False后处理器就不会处理记录。flush():确保已清除所有日志输出记录。close():关闭当前处理程序使用的所有资源,并删除处理程序。handle(record):经处理器处理后将记录对象record发送给实际处理程序。handleError(record):当Handle遇到异常时,将记录对象传递给emit()处理。若raiseExceptions属性为False,则异常将被忽略。format(record):如果设置了格式化程序将会对记录格式化,否则使用默认的格式化程序。emit(record):处理当处理程序出现异常时的记录对象。处理器一般很少自由使用。
Python日志模板内置数十种日志处理器,下面列举出常用的。
StreamHandler:将日志记录输出发送到流,如控制台。FileHandler:将日志记录发送到磁盘文件。NullHandler:不做任何的格式输出。RotatingFileHandler:按照日志文件大小分割日志。TimedRotatingFileHandler:按照日志文件记录时间分割日志。STMPHandler:将日志文件发送到指定电子邮箱。MemoryHandler:将日志记录缓冲到内存中。HTTPHandler:将日志记录发送到Web服务器。
- 将日志写入磁盘文件。
import logging
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG) # 输出到console的log等级的开关
fh = logging.FileHandler('log.log', mode='w')
fh.setLevel(logging.DEBUG) # 输出到file的log等级的开关
fmt = logging.Formatter("%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s") # 创建一个格式化器
ch.setFormatter(fmt) # 格式化器添加到流处理器
fh.setFormatter(fmt) # 格式化器添加到文件写入处理器
logger.addHandler(ch) # 记录器添加流处理器
logger.addHandler(fh) # 记录器添加文件写入处理器
if __name__ == '__main__':
logger.info("这是一条常规日志信息1")

- 将日志文件按照时间分割
import time
import logging.handlers
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG) # 输出到console的log等级的开关
fh = logging.handlers.TimedRotatingFileHandler(filename='log.log', when="m", interval=1,
backupCount=5, encoding='utf-8') # 按照时间分割日志
fh.setLevel(logging.DEBUG) # 输出到file的log等级的开关
fmt = logging.Formatter("%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s") # 创建一个格式化器
ch.setFormatter(fmt) # 格式化器添加到流处理器
fh.setFormatter(fmt) # 格式化器添加到文件按时分割处理器
logger.addHandler(ch) # 记录器添加流处理器
logger.addHandler(fh) # 记录器添加文件按时分割处理器
if __name__ == '__main__':
while True:
logger.info(f"这是一条常规日志信息,时间戳{time.time()}")
time.sleep(1)
- 将日志按照大小分割
import time
import logging.handlers
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG) # 输出到console的log等级的开关
fh = logging.handlers.RotatingFileHandler(filename='log.log', maxBytes=1024, backupCount=5) # 按照日志文件大小分割日志
fh.setLevel(logging.DEBUG) # 输出到file的log等级的开关
fmt = logging.Formatter("%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s") # 创建一个格式化器
ch.setFormatter(fmt) # 格式化器添加到流处理器
fh.setFormatter(fmt) # 格式化器添加到文件按时分割处理器
logger.addHandler(ch) # 记录器添加流处理器
logger.addHandler(fh) # 记录器添加文件按大小割处理器
if __name__ == '__main__':
while True:
logger.info(f"这是一条常规日志信息,时间戳{time.time()}")
time.sleep(1)
- 将日志发送到邮箱
import time
import logging.handlers
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG) # 输出到console的log等级的开关
fh = logging.handlers.SMTPHandler(
mailhost=('smtp.qq.com', 587), # SMTP邮件服务器地址和端口号
fromaddr='255xxx277@qq.com', # 发件人地址
toaddrs='243xxx539@qq.com', # 收件人地址
subject='发生了一个错误', # 邮件主题
credentials=('255xxx77@qq.com', 'ouqpcxxxbab')) # SMTP邮箱账号和SMTP服务授权码,不是邮箱登陆授权码
fh.setLevel(logging.ERROR) # 输出到file的log等级的开关
fmt = logging.Formatter("%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s") # 创建一个格式化器
ch.setFormatter(fmt) # 格式化器添加到流处理器
fh.setFormatter(fmt) # 格式化器添加到邮件发送处理器
logger.addHandler(ch) # 记录器添加流处理器
logger.addHandler(fh) # 记录器添加邮件发送处理器
if __name__ == '__main__':
try:
1 + "s"
except BaseException as e:
logger.exception(e)
Formatter
格式化器的作用就是将日志按照开发者想要的格式输出。它具有如下成员属性和方法。
__init__(fmt=None, datefmt=None, style='%'):初始化方法,参数fmt代表格式化字符串,默认为%(message)s,参数datefmt是时间格式化字符串,style参数确定如何将格式字符串与数字合并,可选值有“%”、“{”、“$”。format(record):它是日志记录的属性字典,用作字符串格式化操作的数据,返回结果字符串。formatTime(record, datefmt=None):用自定义的格式化时间字符串来处理记录对象record,默认为“%Y-%m-%d%H:%M:%S,uuu”格式的时间格式化字符串。formatException(exc_info):将指定的异常信息格式化成字符串。formatStack(stack_info):将指定的堆栈信息转换为字符串。
可选择的格式化字段及输出示例如下表所示。
| 字段 | 含义 | 输出示例 |
|---|---|---|
%(levelinfo)s | 打印日志级别的数值 | 20 |
%(levelname)s | 打印日志级别名称 | INFO |
%(pathname)s | 打印当前执行程序的路径 | C:/User/PythonProject/code/log.py |
%(filename)s | 打印当前执行程序名 | log.py |
%(funcName)s | 打印日志的当前函数 | <module> |
%(lineno)d | 打印日志的当前行号 | 35 |
%(asctime)s | 打印日志的时间 | 2020-02-25 22:00:58,759 |
%(thread)d | 打印线程ID | 1772 |
%(threadName)s | 打印线程名称 | MainThread |
%(process)d | 打印进程ID | 5732 |
%(message)s | 打印日志信息 | 日志初步使用 |
%(msecs)d | 打印日志时的毫秒时分 | 759 |
%(created)f | 打印记录日志时的时间戳 | 15823412441.522445 |
%(name)s | 打印记录器的名称,默认为root | root |
(processName)s | 打印进程名 | MainProcess |
(relativeCreated)d | 打印日志记录时相对于日志模块初始化的时间 | 358 |
%(module)s | 打印模块 | log |
Filters
过滤器提供了更加精细的附加功能,用于确定要输出的日志。过滤器可以单独添加到记录器和处理器,以便更为精准地输出日志记录。同时过滤器还可以负责记录日志的上下文处理,比如技术、附加消息等。
Filters有如下的成员属性和方法。
__init__(name=''):初始化过滤器,name代表传入记录器或处理器名字,处理记录对象时会对比对象的处理器或记录器的名字与传入的name。若name为空则代表允许经过所有过滤器。filter(record):用于判断记录日志对象record是否需要记录。
过滤逻辑支持一个过滤器对象和过滤函数,执行逻辑为:检查filter对象是否有filter属性,若有假定其过滤函数为filter,并调用filter方法,否则假设它是可调用的单个函数,并以记录对象为单个参数进行调用。
下面示例如何自定义过滤器和过滤函数。
import logging
class WordFilter(logging.Filter):
def __init__(self, word, name=''):
"""
初始化一个字符检测过滤器
过滤日志消息中含有指定字符的消息
:param word: 要过滤的字符串
:param name: 记录器或处理器名字
"""
super().__init__(name)
self.name = name
self.nlen = len(name)
self.word = word
def filter(self, record: object) -> bool:
if self.nlen == 0 or self.name != record.name:
return True
if self.word in record.msg:
return False
else:
return True
logger_a = logging.getLogger('a') # 获取一个名为a的记录器
logger_b = logging.getLogger('b') # 获取一个名为b的记录器
logger_a.setLevel(logging.DEBUG) # 给a记录器设置记录日志等级
logger_b.setLevel(logging.DEBUG) # 给b记录器设置记录日志等级
ch = logging.StreamHandler() # 创建一个处理器
ch.setLevel(logging.DEBUG) # 给处理器设置日志等级
fmt = logging.Formatter("%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s-%(name)s") # 创建一个格式化器
ch.setFormatter(fmt) # 将格式化器添加到处理器
logger_a.addHandler(ch) # 给a记录器添加处理器
logger_b.addHandler(ch) # 给b记录器添加处理器
wordfilter = WordFilter("名字", "a")
logger_a.addFilter(wordfilter) # 给a记录器添加过滤器wordfilter
logger_b.addFilter(wordfilter) # 给b记录器添加过滤器wordfilter
if __name__ == '__main__':
logger_a.info("我是记录器,我的名字是a,我添加了wordfilter过滤器")
logger_b.info("我是记录器,我的名字是b,我添加了wordfilter过滤器")
logger_a.removeFilter(wordfilter)
logger_a.info("我是记录器,我的名字是a,我移除了wordfilter过滤器")

上述结果中,三条日志只处理了两条是因为自定义过滤器在过滤目标处理器a中生效,检查是否含关键词时第一条日志记录被过滤掉了。
import logging
def wordfilter(record: object) -> bool:
"""
自定义过滤器函数
:param record:
:return:
"""
if "名字" in record.msg:
return False
else:
return True
logger = logging.getLogger(__name__) # 创建一个过滤器
logger.setLevel(logging.DEBUG) # 设置处理的日志级别
ch = logging.StreamHandler() # 创建一个处理器
ch.setLevel(logging.DEBUG) # 设置处理器的日志级别
fmt = logging.Formatter(
"%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s-%(name)s") # 创建一个格式化器
ch.setFormatter(fmt) # 将格式化器添加到处理器
logger.addHandler(ch) # 将处理器添加到记录器
logger.addFilter(wordfilter) # 将自定义过滤函数添加到记录器
if __name__ == '__main__':
logger.info("我是记录器,我的名字是__main__,我添加了wordfilter过滤器函数")
logger.removeFilter(wordfilter)
logger.info("我是记录器,我的名字是__main__,我移除了wordfilter过滤器")

LogRecord对象
LogRecord对象在Logger每次记录时自动创建,并且可以通过makeLogRecord函数手动创建。它在logging四大组件之间流动,用于传递日志消息。它是连通日志记录四大组件的重要对象。
LogRecord对象的属性和方法如下。
__init__(name, level, pathname, lineno, msg, args, esc_info, func=None, sinfo=None):产生LogRecord的初始方法,相关参数解释如下。- name:产生LogRecord实例的事件记录器的名称。
- level:日志记录事件的数字级别。该属性将转换为LogRecord的levelno数字值和levelname相应的级别名称。
- pathname:日志记录时调用的源文件的完整路径。
- lineno:记录日志时代码的行号。
- msg:事件描述信息,可能是带有占位符的格式字符串。
- args:合并到msg参数中的可变数据,可以此获得事件描述。
- exc_info:具有当前异常信息的异常元组。
- func:从中调用日志记录的函数或方法的名称。
- sinfo:一个文本字符串,表示从当前线程中的堆栈底部到日志记录调用的堆栈信息。
getMessage():用于返回LogRecord对象实例化时的消息内容。
LogRecord实例化对象的全部属性见下表。
| 属性名称 | 格式 | 说明 | 示例值 |
|---|---|---|---|
| args | 不需要格式化 | 将参数的元组合并到msg,生成消息 | () |
| asctime | %(asctime)s | LogRecird创建时的格式化可读时间 | 2020-02-27 12:00:00, 054 |
| created | %(created)f | LogRecord创建的时间戳 | 2939848123.24241 |
| exc_info | 不需要格式化 | 异常信息元组或者None | None |
| filename | %(filename)s | 路径名的文件名部分 | log.py |
| funcName | %(funcName)s | 包含创建日志的函数名称 | <module> |
| levelname | %(levelname)s | 文本日志记录消息的级别 | DEBUG |
| levelno | %(levelno)s | 日志记录的级别表示数字 | 20 |
| lineno | %(lineno)d | 发出日志记录调用的源码符号 | 18 |
| message | %(message)s | 记录的消息。是调用Formatter.format函数填充args函数后得到的 | 发送日志服务器 |
| module | %(module)s | 模块(filename的名称部分) | log |
| msecs | %(msecs)d | LogRecord创建时间的毫秒部分 | 53.01134490866797 |
| msg | 不需要格式化 | 原始日志记录调用中传递的格式字符串 | 发送日志服务器 |
| name | %(name)s | 对应记录器的名称 | __main__ |
| pathname | %(pathname)s | 调用日志记录的源文件的完整路径 | A:/log/log.py |
| process | %(process)d | 进程ID | 16011 |
| processName | %(processName)s | 进程名 | MainProcess |
| relativeCreated | %(relativeCreated)d | 创建LogRecord时相对于加载日志模块的时间 | 3005.11234123231 |
| stack_info | 不需要格式化 | 当前线程中堆栈底部的堆栈帧信息,直至导致创建此纪录的日志调用的堆栈帧 | None |
| thread | %(thread)d | 线程ID | 844 |
| threadName | %(threadName)s | 线程名 | MainThread |
构造LogRecord不能直接使用上方的属性作为传入参数实例化LogRecord类,一般使用logging.makeRecord({})创建一个没有任何属性的LogRecord对象,然后使用update函数更新这个示例中__dict__的全部参数,即可实现恢复一个LogRecord实例化对象,但是要注意这个实例的字段的数据类型不能改变。
日志的配置
日志配置有以下方法:
- 使用配置方法显式创建记录器,处理程序和格式化程序;
- 使用fileConfig()函数读取日志配置文件。
- 使用dictConfig()函数读取配置信息字典。
显式配置
该方法指直接使用logging四大组件的相关设置函数来配置。在之前的例子中都是在代码中重复使用配置,如使用logger=logging.getLogger()获取记录器,这种代码放在业务代码中很不整洁,因此常用的方法是将这些配置代码放到单独的文件中,需要时导入即可。多次导入记录器不会重复实例化配置,它们的导入都是第一次配置的记录器。
通过fileConfig()配置
该函数可以从.conf文件中读取日志配置,该函数位于logging.config模块。conf文件必须包含名为[loggers]、[handlers]、[formatters]的节点,这些节点通过名称标识定义出每种类型的组件,其节点下的项以keys=value1,value2等格式组成。
新建一个log.conf文件,写入下方配置项。
import logging.config
logging.config.fileConfig('log.conf')
logger = logging.getLogger('log02')
if __name__ == '__main__':
logger.info("读取配置")
2023-07-07 23:06:12,181 - 3-13-2 fileConfig读取配置.py[line:7] - INFO: 读取配置-log02[loggers] # 声明是loggers节点
keys = root,log02
# 配置两个记录器分别是root和log02
[handlers] # 声明是handlers节点
keys = hand01
# 配置一个处理器
[formatters] # 声明是formatters节点
keys = fmt
# 配置一个格式化器fmt
[logger_root] # 对root记录器配置
level = NOTSET
handlers = hand01
[logger_log02] # 对log02记录器配置
level = DEBUG
handlers = hand01
propagate = 1
qualname = compiler.parser
[handler_hand01] # 对hand01处理器配置
class = StreamHandler
level = DEBUG
formatter = fmt
args = (sys.stdout,)
[formatter_fmt] # 对格式化器fmt进行配置
format = %(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s-%(name)s
datefmt =
class = logging.Formatter
通过dictConfig读取
dictConfig可以从字典中获取日志记录配置,该函数位于logging.config中。dictConfig同时支持在dict中导入外部对象。在配置处理器、过滤器、格式化器中使用自定义对象用特殊键“()”,兹定于i对象所需的构造参数以及键值对在配置字典中列出。当引用外部对象时使用“ext://”+自定义对象导入路径的方式,配置系统会自动分割字符串,并使用常规导入机制处理值的剩余部分。dictConfig还支持引用配置文件内部的对象。对于日志系统内部的对象通过提供ID引用或隐式转换,如DEBUG会自动换成logging.DEBUG。若为用户自定义的对象就要通过“dfg://”+相对配置文件来引用,该位置即字典获取值的路径。如“cfg://handler.email”指的是config_dict[]'handlers']['email']。
dictConfig所需的配置字典应包含下列键。
version指版本号。
formatters:格式化器,其值为dict类型,其中键为ID,值为含有format、datefmt的配置字典。
"fmt": {
"format": "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
}
- filters:过滤器,值为dict类型,键位ID,值位含有name固定字段的配置字典。
"filters": {
"wordfilter": {
"name": "WordFilter"
}
}
- handlers:处理器,值位dict类型,键为ID,值为含有clas、level、formatter、filters等字段的配置字典。
"handlers": {
"hand01": {
"class": "logging.StreamHandler",
"level": "INFO",
"filters": [
"wordfilter"
],
"formatter": "fmt"
}
}
- loggers:记录器,值为dict类型,其中键为记录器名称,值为含有propagate、level、filters、handlers等字段的配置字典。
"loggers": {
"log02": {
"propagate": 1,
"level": "DEBUG",
"handlers": ["hand01"]
},
"root": {
"level": "DEBUG",
"handlers": ["hand01"]
}
}
root:根记录器,配置和logger相同,但是配置字典不能使用propagate属性。
incremental:用来决定是否替换现有配置,默认为False。
disable_existing_logger:用于判断是否禁用现有的记录器,默认为True。
from logging import getLogger, config
data = {
"word": "去除", # 一个过滤关键字
"version": 1,
"disable_existing_loggers": True,
"formatters": {
"fmt": {
"format": "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
}
},
"filters": {
"wordfilter": {
"()": "ext://自定义类过滤器.WordFilter", "word": "名字", "name": "log02"
},
"wordfilter2": {
"()": "ext://自定义类过滤器.WordFilter", "word": "cfg://word", "name": "log02"
}
},
"handlers": {
"hand01": {
"class": "logging.StreamHandler",
"level": "DEBUG",
"formatter": "fmt",
"filters": [
"wordfilter", "wordfilter2"
],
}
},
"loggers": {
"log02": {
"propagate": 1,
"level": "DEBUG",
"handlers": ["hand01"],
},
"root": {
"level": "DEBUG",
"handlers": ["hand01"]
}
}
}
config.dictConfig(data)
logger = getLogger('log02')
if __name__ == '__main__':
logger.info("本条将不被过滤,不含过滤关键字")
logger.info("本条将过滤,含过滤关键字:名字")
logger.info("本条将过滤,含过滤关键字:去除")
2020-03-01 10:02:29,968 - log02 - INFO - 本条将不被过滤,不含过滤关键字
数据库操作
本节使用的数据库有:MySQL、Redis和MongoDB。在你观看这部分笔记时请先学习这些数据库,这里不作记录。
通过ORM操作MySQL
SQLAlchemy基础
SQLAlchemy是一个实现了ORM的框架。使用SQLAlchemy就无需自己构建ORM,无需自己编写SQL语句,也无需自己思考如何遵照规范设计,并且可以随时修改。Flask-SQLAlchemy就集成了SQLAlchemy框架,具体可以在我的博客中搜索“Flask拓展框架”查看相关文章。
使用pip install mysqlclient安装MySQL驱动,也可用pymysql替代;使用pip install SQLAlchemy安装SQLAlchemy。
SQLAlchemy驱动和Flask-SQLAlchemy比较像,都是先配置驱动,然后创建模型类,使模型类继承自Model类,然后编写成员变量,这些成员变量就是对应着数据表的字段。下面以一个学生和成绩的例子演示如何构建ORM。
from sqlalchemy import create_engine, Column, Integer, String, ForeignKey
from sqlalchemy.orm import declarative_base
from sqlalchemy.orm import sessionmaker
engine = create_engine(
'mysql://root:254456@127.0.0.1:3306/db?charset=utf8', pool_size=20, max_overflow=0, pool_recycle=3600, echo=True
)
Session = sessionmaker(bind=engine) # 创建Session会话,连接数据库
BaseModel = declarative_base() # 创建数据库基类
class Student(BaseModel):
__tablename__ = 'tb_student' # 数据表名
id = Column(Integer, primary_key=True) # 主键
name = Column(String(10), nullable=False)
_class = Column(String(10), nullable=False)
class Score(BaseModel):
__tablename__ = 'tb_score'
id = Column(Integer, primary_key=True)
subject = Column(String(10), nullable=False)
score = Column(Integer, nullable=False)
student_id = Column(Integer, ForeignKey('tb_student.id')) # 外键
def create_tables():
BaseModel.metadata.create_all(engine) # 令所有继承自基类的模型类创建数据库
if __name__ == '__main__':
create_tables()
运行这段代码后,程序就会在db数据表中创建tb_student和tb_score这两个数据表。
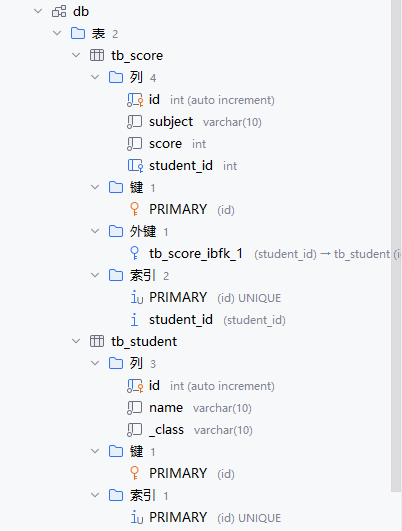
接下来使用上方的模型创建几条数据。
if __name__ == '__main__':
session = Session()
student = Student(name='小明', _class='三年一班')
score = Score(subject='数学', score=100, student_id=1)
session.add_all([student, score])
session.commit()
session.close()
执行这段代码后,数据库中会多两条数据。若插入数据时报了外键约束的错误,建议将这两个对象分开添加。
下面将详细讲解SQLAlchemy每一步都该如何配置。
引擎配置
SQLAlchemy第一步就是创建引擎。create_engine()函数通过解析URL,确定要连接的数据库、用户名、密码、端口、地址等信息,并连接数据库。单一的引擎代表进程管理多个数据库连接,以并发方式调用。引擎只会创建一次,不会再在每个对象或函数调用时重复创建。
- 给API配置引擎
sqlalchemy.create_engine(*args, **kwargs)
该方法用于创建新的引擎实例,常常第一个用于传URL,后面再跟关键字参数。
engine = create_engine(
'mysql://root:254456@127.0.0.1:3306/db?charset=utf8', pool_size=20, max_overflow=0, pool_recycle=3600, echo=True
)
这部分代码不会真正创建连接。
create_engine需要如下参数:
- url:字符串形式为
dialect[+driver]://user:password@host/dbname[?key=value...]。其中dialect是数据库名称,如mysql、oracle、postgrasql等,driver是DBAPI的名称,如pymysql、mysqlclient。 - case_sensitive:表示列名是否区分大小写。
- connect_args:将直接传递给DBAPI的字典。其作为connect方法的其他关键字参数,常常用于自定义底层连接。
- echo:是否开启日志记录器。
- echo_pool:是否记录连接信息并在默认日志记录器中输出。
- encoding:用于字符串编码和解码。
- implicit_returning:是否在发出没有现有RETURNING()子句的单行INSERT语句时使用与返回兼容的构造来获取新生成的主键值。
- label_length:可选的整数值,将动态生成的列标签的大小限制为多个字符。
- logging_name:将sqlalchemy.engine中生成日志记录的name字段改为自定义的标识符。
- max_overflow:允许在连接池中溢出的连接数。
- module:指定引擎直接使用的DBAPI模块,应为模块引用,而不是字符串。
- pool_pre_ping:是否启用连接池预ping功能。
- pool_size:在连接池中保持打开的连接数。
- pool_recycle:设置回收时间,默认为-1,不回收。
- pool_timeout:获取连接超时等待的时间。
- 常用连接配置
连接MySQL:
MYSQL_URL = 'mysql://root:123456@127.0.0.1:3306/teaching?charset=utf8'
engine = create_engine(MYSQL_URL, pool_size=20, max_overflow=20, pool_recycle=3600,pool_pre_ping=True, encoding='UTF-8')
连接到SQLite:
engine = create_engine('sqlite:////home/path/data.db') # Linux
engine = create_engine(r'sqlite:///C:\path\data.db') # Windows
创建会话
ORM和Core是SQLAlchemy核心,会话则是ORM中的核心。会话用于管理数据库及数据对象的操作。
- 会话的创建
与数据库交互前需要创建会话。Session是ORM操作数据库的句柄,但是Session并未真正地与数据库创建链接,只有发生数据库操作时才会创建连接。
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
engine = create_engine('mysql://root:254456@127.0.0.1:3306/db?charset=utf8', pool_size=20, max_overflow=20, pool_recycle=3600, echo='debug')
Session = sessionmaker(bind=engine)
上面是提前配置引擎后创建Session对象,还可以延迟绑定引擎。
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
Session = sessionmaker()
engine = create_engine('mysql://root:254456@127.0.0.1:3306/db?charset=utf8', pool_size=20, max_overflow=20, pool_recycle=3600, echo='debug')
Session.configure(bind=engine)
Session配置一次即可,然后由其他模块导入。使用前先实例化Session,最后将Session关闭。
Session接口类为sqlalchemy.orm.session.Session,下面列举常用的内部方法和配置参数。
__init__():初始化Session,其有如下参数:autocommit:默认为False。若为True,则会话不会保持持久的事务运行,将自动根据需要从引擎中获取数据库连接,并在使用后立即返回连接。若为False,则每次需要使用Session.begin()开始事务,使用commit()提交事务。
autoflush:默认为False。若为True则执行查询SQL之前都会先提交事务,以便数据库返回结果。autoflush通常与autocommit一起使用,很少单独使用flush。
bind:将会话绑定到指定的引擎。
binds:字典类型,为每种不同的table对象或Mapper对象指定不同的引擎,执行SQL时根据这种映射关系启用不同的引擎。如
Session = sessionmaker(binds={someMappedClass:create_engine('postgresql://engine1', someDaclarativeClass:'postgresql://engine2)})expire_on_commit:默认为True,每次调用commit()之后,所有实例都将过期,完成事务之后的所有对象属性的访问都将从数据库加载。
注:在最新版本的SQLAlchemy中,autocommit方法已不再支持。这里由于只在记笔记而没有运行代码,因此到了自动提交事务时才发现该参数已经废弃。由于篇幅巨大不能进行改正,因此下方凡是涉及到自动提交事务的只能改为使用begin和commit方法手动开启事务。特此说明。
add(instance, _warn=True):在会话中放置对象,它的状态将在下次刷新操作时持久化到数据库。重复调用将被忽略。add_all(instances):接收列表参数。在会话中放置列表中的所有对象。begin(substransactions=False, nested=False):在会话中标记事务的开始。Session.begin方法和autocommit一起使用。substransactions:若为True则代表开启子事务。nested:若为True,则标记一个事务保存点。
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, create_engine
from sqlalchemy.orm import sessionmaker
Base = declarative_base() # 创建一个声明性基类
engine = create_engine("mysql://root:254456@127.0.0.1:3306/db?charset=utf8", pool_size=20, max_overflow=0,
pool_recycle=3600, echo="debug") # 配置引擎
Session = sessionmaker(engine)
class User(Base):
"""
创建一个声明性数据表类
"""
__tablename__ = 'users' # 对应数据库中的表名
id = Column(Integer, primary_key=True)
name = Column(String(50))
fullname = Column(String(50))
nickname = Column(String(50))
def __repr__(self):
"""
自定义类描述
:return:
"""
return f"<User(name={self.name}, fullname={self.fullname}, nickname={self.nickname})>"
if __name__ == '__main__':
Base.metadata.create_all(engine) # 在数据库生成相应表
session = Session()
user_one = User(name="明", fullname="李明", nickname="小明")
session.add(user_one)
session.autocommit = True # 使用autocommit模式
session.begin(nested=True) # 标记事务开始,并且是事务保存点
user_two = User(name="杰克", fullname="杰克·斯帕罗", nickname="杰克船长")
user_three = User(name="彼得", fullname="彼得·帕克", nickname="蜘蛛侠")
session.add_all([user_two, user_three])
print(session.new)
session.rollback()
session.commit()
2023-07-09 21:18:25,738 INFO sqlalchemy.engine.Engine SELECT DATABASE()
2023-07-09 21:18:25,738 INFO sqlalchemy.engine.Engine [raw sql] ()
2023-07-09 21:18:25,738 DEBUG sqlalchemy.engine.Engine Col ('DATABASE()',)
2023-07-09 21:18:25,739 DEBUG sqlalchemy.engine.Engine Row ('db',)
2023-07-09 21:18:25,739 INFO sqlalchemy.engine.Engine SELECT @@sql_mode
2023-07-09 21:18:25,739 INFO sqlalchemy.engine.Engine [raw sql] ()
2023-07-09 21:18:25,739 DEBUG sqlalchemy.engine.Engine Col ('@@sql_mode',)
2023-07-09 21:18:25,739 DEBUG sqlalchemy.engine.Engine Row ('ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION',)
2023-07-09 21:18:25,739 INFO sqlalchemy.engine.Engine SELECT @@lower_case_table_names
2023-07-09 21:18:25,739 INFO sqlalchemy.engine.Engine [raw sql] ()
2023-07-09 21:18:25,739 DEBUG sqlalchemy.engine.Engine Col ('@@lower_case_table_names',)
2023-07-09 21:18:25,739 DEBUG sqlalchemy.engine.Engine Row (1,)
2023-07-09 21:18:25,740 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2023-07-09 21:18:25,740 INFO sqlalchemy.engine.Engine DESCRIBE `db`.`users`
2023-07-09 21:18:25,740 INFO sqlalchemy.engine.Engine [raw sql] ()
2023-07-09 21:18:25,742 INFO sqlalchemy.engine.Engine
CREATE TABLE users (
id INTEGER NOT NULL AUTO_INCREMENT,
name VARCHAR(50),
fullname VARCHAR(50),
nickname VARCHAR(50),
PRIMARY KEY (id)
)
2023-07-09 21:18:25,742 INFO sqlalchemy.engine.Engine [no key 0.00009s] ()
2023-07-09 21:18:25,748 INFO sqlalchemy.engine.Engine COMMIT
2023-07-09 21:18:25,749 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2023-07-09 21:18:25,750 INFO sqlalchemy.engine.Engine INSERT INTO users (name, fullname, nickname) VALUES (%s, %s, %s)
2023-07-09 21:18:25,750 INFO sqlalchemy.engine.Engine [generated in 0.00014s] ('明', '李明', '小明')
IdentitySet([<User(name=杰克, fullname=杰克·斯帕罗, nickname=杰克船长)>, <User(name=彼得, fullname=彼得·帕克, nickname=蜘蛛侠)>])
2023-07-09 21:18:25,752 INFO sqlalchemy.engine.Engine ROLLBACK
运行结果为日志输出,因为设置了echo参数为debug。
begin_nested():标记嵌套事务的开始。允许Session.begin_nested使用with块,则不必显式使用commit()方法或flush()方法提交事务。bind_mapper(mapper, bind):将映射对象绑定到指定引擎或连接,可参考Session.binds、Session.bind_table()。参数说明如下。- mapper:表示映射器对象、映射类的实例、映射类的基类。
- bind:表示引擎或数据库连接。
bind_table(table, bind):把声明性类绑定到指定引擎或连接,参数说明如下。- table:是Table对象,通常是ORM映射的目标,或者存在于映射的可选对象中。
- bind:表示引擎或数据库连接。
bulk_insert_mappings(mapper, mappings, return_defaults=False, render_nulls=False):为给定映射的声明性类和大量的Table构建参数的字典的列表指定批量插入,参数解释如下。- mapper:表示映射类或实际mapper对象,表示映射列表中的创建对象。
- mappings:表示字典列表,每个字典都包含要插入的映射行键值对。若映射引用多个表,则每个字典必须包含要填充的每个表的所有键。
- render_defaults:若为True,则将一次插入一行缺少默认值的行,如自增主键。允许连接继承和其他多表映射正确插入,且无需提前提供主键值。
- render_nulls:若为True,则值为None的列将导致INSERT语句中包含空值,而不是在INSERT中省略该列。若数据库有默认值则默认值不生效,仍为null。
from sqlalchemy import Column, Integer, String, create_engine
from sqlalchemy.orm import sessionmaker, declarative_base
Base = declarative_base() # 创建一个声明性基类
engine = create_engine("mysql://root:254456@127.0.0.1:3306/db?charset=utf8", pool_size=20, max_overflow=0,
pool_recycle=3600, echo="debug") # 配置引擎
Session = sessionmaker(engine)
class User(Base):
"""
创建一个声明性数据表类
"""
__tablename__ = 'users' # 对应数据库中的表名
id = Column(Integer, primary_key=True)
name = Column(String(50))
fullname = Column(String(50))
nickname = Column(String(50))
def __repr__(self):
"""
自定义类描述
:return:
"""
return f"<User(name={self.name}, fullname={self.fullname}, nickname={self.nickname})>"
if __name__ == '__main__':
# Base.metadata.create_all(engine) # 在数据库生成相应表
session = Session()
session.bulk_insert_mappings(User, [{"name": "杰克", "fullname": "杰克·斯帕罗", "nickname": "杰克船长"},
{"name": "彼得", "fullname": "彼得·帕克", "nickname": "蜘蛛侠"}])
# 将批量向数据库插入值
2023-07-09 21:34:49,489 INFO sqlalchemy.engine.Engine SELECT DATABASE()
2023-07-09 21:34:49,489 INFO sqlalchemy.engine.Engine [raw sql] ()
2023-07-09 21:34:49,490 DEBUG sqlalchemy.engine.Engine Col ('DATABASE()',)
2023-07-09 21:34:49,490 DEBUG sqlalchemy.engine.Engine Row ('db',)
2023-07-09 21:34:49,490 INFO sqlalchemy.engine.Engine SELECT @@sql_mode
2023-07-09 21:34:49,490 INFO sqlalchemy.engine.Engine [raw sql] ()
2023-07-09 21:34:49,490 DEBUG sqlalchemy.engine.Engine Col ('@@sql_mode',)
2023-07-09 21:34:49,490 DEBUG sqlalchemy.engine.Engine Row ('ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION',)
2023-07-09 21:34:49,490 INFO sqlalchemy.engine.Engine SELECT @@lower_case_table_names
2023-07-09 21:34:49,490 INFO sqlalchemy.engine.Engine [raw sql] ()
2023-07-09 21:34:49,491 DEBUG sqlalchemy.engine.Engine Col ('@@lower_case_table_names',)
2023-07-09 21:34:49,491 DEBUG sqlalchemy.engine.Engine Row (1,)
2023-07-09 21:34:49,491 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2023-07-09 21:34:49,491 INFO sqlalchemy.engine.Engine DESCRIBE `db`.`users`
2023-07-09 21:34:49,491 INFO sqlalchemy.engine.Engine [raw sql] ()
2023-07-09 21:34:49,493 DEBUG sqlalchemy.engine.Engine Col ('Field', 'Type', 'Null', 'Key', 'Default', 'Extra')
2023-07-09 21:34:49,493 DEBUG sqlalchemy.engine.Engine Row ('id', 'int', 'NO', 'PRI', None, 'auto_increment')
2023-07-09 21:34:49,493 INFO sqlalchemy.engine.Engine COMMIT
2023-07-09 21:34:49,494 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2023-07-09 21:34:49,495 INFO sqlalchemy.engine.Engine INSERT INTO users (name, fullname, nickname) VALUES (%s, %s, %s)
2023-07-09 21:34:49,495 INFO sqlalchemy.engine.Engine [generated in 0.00012s] [('杰克', '杰克·斯帕罗', '杰克船长'), ('彼得', '彼得·帕克', '蜘蛛侠')]

bulk_update_mappings(mapper, mappings):为给定映射的字典执行批量更新。mapping中不是主键的值将用于UPDATE的SET子句中,主键将应用于WHERE子句中。如session.bulk_update_mapping({'id':22,'fullname':'杰克·斯帕罗','nickname':'杰克船长'})。close():关闭此会话。这将清除所有项目病结束正在进行的任何事务。若此会话使用了autocommit模式,则立即开启新的事务。commit():提交事务。delete(instance):将实例标记为已删除。在这之后调用commit()方法或flush()方法会从数据库中删除此数据。deleted:包含所有已标记为已删除的对象的集合。dirty:返回数据发生了持久化改变对象集合。所有属性设置或集合修改操作都会将实例标记为dirty,并将其放置在此集合中。execute(clause, params=None, mapper=None, bind=None, **kw):执行SQL语句。参数解释如下。- clause:可执行语句。
- param:绑定参数值。
- mapper:标记适当的绑定。
- bind:绑定要操作的引擎。
# 举例
result = session.execute(User.__table__.select().where(User.__table__.c.id==5))
result = session.execute('SELECT * FROM user WHERE id = :param', {'param':5})
result = session.execute(text('SELECT * FROM user WHERE id = :param'), {'param':5})
它的第二个参数为可选参数集,可以作为单个字典传递还是作为字典列表传递。
from sqlalchemy import insert
result = session.execute(User.__table__.insert(), {'id':6,'name':'someone'})
result = session.execute(insert(User), {'id':7,'name':'someone'})
# 插入多条记录
result =session.execute(insert(User), [{'id':8,'name':'someone'},{'id':9,'name':'someone'}, {'id':10,'name':'someone'}])
expire(instance, attribute_name=None):标记Session中持久性实例的过期属性,下次再访问过期属性时将向会话对象的当前事务上下文发起查询,以便更新给定实例的所有过期属性。expite_all():标记Session对象中所有过期的持久性实例。expunge(instance):移除Session中的指定实例。expunge_all():移除Session对象的全部实例。flush(objects=None):将所有对对象的更改写入数据库,若发生错误则回滚整个事务。rollback():回滚事务。
会话使用需要遵循规范,如及时关闭资源、不要每次执行操作时都新创建一个Session,而是将Session作为一个局部参数,使其尽量具有一个生命周期。SQLAlchemy官网提供了一个比较全面的案例。
from contextlib import contextmanager
@contextmanager
def session_scope():
"""Provice a transactional scope around a series of operations."""
session = Session()
try:
yield session
session.commit
except:
session.rollback()
raise
finally:
sesson.close
def run_my_programm():
with session.scope() as session:
ThingOne().go(session)
ThingTwo().go(session)
Session也不是线程安全的。使用Session应该确保每个事务中的单个操作序列存在一个实例。应该确保Session一次只在一个线程中工作,实现适当的锁定方案。
创造声明性类
将数据表的描述和数据表抽象类映射到数据表这两个操作是同步进行的,在SQLAlchemy中由声明性系统完成。声明性类需要继承自一个特定基类,类中需要有__tablename__属性、定义表中字段等操作。
from sqlalchemy import Column, Integer, String, create_engine
from sqlalchemy.orm import declarative_base
Base = declarative_base() # 创建声明性基类
class User(Base): # 令声明类继承自声明性基类
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
name = Column(String(5))
fullname = Column(String(5))
nickname = Column(String(5))
def __repr__(self):
return f'<User(name={self.name}, fullname={self.name}, nickmame={self.nickname})'
当声明类时,声明性系统使用了一个Python元类,以便在类生命完成后执行其他活动。元类将根据定制的规范创建一个Table对象,并通过构造一个Mapper对象将其与类关联,Mapper定义了类属性与数据表列的映射关系。
Table对象时较大集合MetaData的成员,MetaData是一个注册表,可以使用metadata属性获取声明性类中的MetaData对象,其中包括向数据库发出一组有限的数据表生成命令的方法即metadata.create_all()方法。接着,用上述定义的声明性数据表对象在数据库中生成对应的数据表,后面继承声明性基类的类统称为声明性类或数据类。
engine = create_engine('mysql://root:123456@127.0.0.1:3306/db?charset=utf8', pool_size=20, max_overflow=0, pool_recycle=3600, echo='debug')
Base.metadata.create_all(engine)
定义数据列及类型
在声明性类中除了__table__变量代表表名称,使用Column定义的变量就为列。当执行MetaData.create_all()方法时就会创建这些列。上方的许多例子已经演示了如何使用Column定义列。这里说明一下Column接收的参数及意义。
- name:数据中name表示此列的名称,该参数可作为第一个位置参数,也可省略,列名将跟随字段名。
- type:列的类型,该参数可作为第二个位置参数。可选的列类型以及在Python和MySQL中对应的类型如下表。
| SQLAlchemy列类型 | Python类型 | MySQL类型 | 说明 |
|---|---|---|---|
| BIGINT | int或long | BIGINT | 极大整数值 |
| BINARY | bin() | BINARY | 固定长度二进制字符串 |
| BOOLEAN | bool | BOOLEAN | 布尔值,MySQL中使用TINYINT代替 |
| CHAR | str | CHAR | 固定长度字符串,大小0~225字节 |
| DATE | datetime.datetime | DATE | 日期和时间,格式为YYYY-MM-DD HH:MM:SS |
| DECIMAL | float | DECIMAL | 高精度的原始数值 |
| ENUM | str | ENUM | 字符串类型。ENUM是一个字符串对象,其值是从允许值的列表中选择的值 |
| FLOAT | float | FLOAT | 单精度浮点数值 |
| INT、INTEGER | int | INT或INGEGER | Integer的别名 |
| JSON | JSON | JSON | 从MySQL5.7.8开始,MySQL支持RFC7159标准中的JSON定义数据类型 |
| NUMERIC | decimal.Decimal | NUMERIC | 在MySQL中,NUMERIC时限为DECIMAL |
| PICKLETYPE | 可序列化对象 | BLOB | BLOB是一个可变对象,可以容纳可变数量的数据 |
| REAL | float | REAL | 不精确数值数据类型 |
| SMALLINTEGER | int | SMALLINT | 大整数值 |
| STRING | str | VARVHAR | 变长字符串 |
| TEXT | str | TEXT | 长文本数据 |
| TIME | datetime.time | TIME | 时间值 |
| TIMESTAMP | time.time | TIMESTAMP | 时间戳 |
| VARBINARY | bin() | VARBINARY | 可变长度二进制的字符串 |
| VARCHAR | str | VARCHAR | 变长字符串 |
除此之外,还可对数据表中的字段增加约束,也是通过参数限定。这些参数有autoincrement、default、doc(类似Python的文档属性)、key(用于标识此类对象)、index、nullable、onupdate、primary_key、unique、comment。
增删改查
这里先预定义一个类,代码如下。
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.orm import sessionmaker, declarative_base
engine = create_engine('mysql://root:254456@127.0.0.1:3306/db?charset=utf8', pool_size=20, pool_recycle=3600,
max_overflow=0, echo='debug')
Base = declarative_base()
Session = sessionmaker(engine)
class User(Base):
__tablename__ = 'user'
id = Column(Integer, autoincrement=True, primary_key=True)
username = Column(String(10), nullable=False)
password = Column(String(10), nullable=False)
def __repr__(self):
return f'<User(username={self.username}, password={self.password})'
def create_tables():
Base.metadata.create_all(engine)
if __name__ == '__main__':
create_tables()
添加数据
添加数据时常常用到Session对象的add()方法和add_all()、session.bulk_insert_mappings()、execute执行可执行子句的方法。使用add和add_all两个方法时,Table实例不会向数据库发送指令,只有需要的时候Session才使用一个flush()方法保存更改。下面就是用前面定义的User来添加一条数据。
>>> from main import *
>>> session = Session()
>>> user1 = User(username='qi', password='qi')
>>> session.add(user1)
>>> session.new
IdentitySet([<User(username=qi, password=qi)])
add()方法用于添加一个实例,若想添加多个实例则可以使用add_all()方法。
>>> user2 = User(username='qi2', password='qi2')
>>> user3 = User(username='qi3', password='qi3')
>>> # 使用add_all方法添加多个实例
>>> session.add_all([user2, user3])
>>> session.new
IdentitySet([<User(username=qi, password=qi), <User(username=qi2, password=qi2), <User(username=qi3, password=qi3)])
>>> # 使用数据字典的方式批量插入
>>> session.bulk_insert_mappings(User, [{'username': 'qi3', 'password': 'qi3'}, {'username': 'qi4', 'password': 'qi4'}])
2023-07-10 19:56:00,613 ...(日志输出结果)
>>> # 用execute批量插入
>>> session.execute(User.__table__.insert(), [{'username': 'qi5', 'password': 'qi5'}, {'username': 'qi6', 'password': 'qi6'}])
2023-07-10 20:01:56,940 ...(日志输出结果)
>>> session.commit()
更新数据
更新数据采用先更新后查询的方式:单条数据可以先查询后再提交,多条数据可以通过update提交,session.bulk_update_mappings、execute方法可以执行可执行子句方法。
>>> # 先查询后更新
>>> user = session.query(User).filter(User.username == 'qi').first()
2023-07-10 21:25:12,532 ...(日志输出结果)
>>> user.username
'qi'
>>> user.username = 'qi666'
>>> session.dirty # 查看修改的数据
IdentitySet([<User(username=qi666, password=qi)])
>>> # 以字典方式更新单条数据
>>> session.query(User).filter(User.name == 'qi2').update({User.name: 'qi777', User.password: 'qi777'})
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: type object 'User' has no attribute 'name'
>>> session.query(User).filter(User.username == 'qi2').update({User.username: 'qi777', User.password: 'qi777'})
2023-07-10 21:41:39,134 ...(日志输出结果)
>>> # 以数据字典方式批量更新
>>> session.bulk_update_mappings(User, [{'id': 4, 'username': 'qi3', 'password': 'qi888'},{'id': 5, 'username': 'qi999', 'password': 'qi999'}])
2023-07-10 21:53:23,947 ...(日志输出结果)
查询及过滤
以下结果已将日志输出省略。
- 查询的方式是使用query()方法返回一个查询对象,少数情况下直接关联Session实例化Query对象。
>>> # 常用方式
>>> session.query(User)
<sqlalchemy.orm.query.Query object at 0x0000025F5633F650>
>>> # 不常用方式
>>> from sqlalchemy.orm.query import Query
>>> Query(User, session)
<sqlalchemy.orm.query.Query object at 0x0000025F5630D0D0>
- 当多个类实体或基于列的实体做query方法的参数时,返回结果为元组,但是这个不是Python内置包的元组,是兼顾了Python元组的特性也具有对象的特性。下文称其为result元组。
>>> query = session.query(User.username, User.password)
>>> list(query)
[('qi3', 'qi3'), ('qi4', 'qi4'), ('qi5', 'qi5'), ('qi6', 'qi6'), ('qi', 'qi'), ('qi2', 'qi2'), ('qi3', 'qi3')]
- 使用label方法将列属性值映射到一个新的属性名。
>>> query = session.query(User.username.label('username'))
>>> for item in query:
... print(item.username)
...
qi3
qi4
qi5
qi6
qi
qi2
qi3
- 使用order_by方法对查询结果进行排序。
>>> query = session.query(User.id).order_by(User.id) # 以id正序排序
>>> list(query)
[(12,), (13,), (14,), (15,), (16,), (17,), (18,)]
>>> query = session.query(User.id).order_by(User.id.desc()) # 以id倒序排序
>>> list(query)
[(18,), (17,), (16,), (15,), (14,), (13,), (12,)]
>>> query = session.query(User.id).order_by('id') # 以id正序排序>>> from sqlalchemy import desc
>>> query = session.query(User.id).order_by(desc('id'))
>>> list(query)
[(18,), (17,), (16,), (15,), (14,), (13,), (12,)]
>>> list(query)
[(12,), (13,), (14,), (15,), (16,), (17,), (18,)]
>>> from sqlalchemy import desc
>>> query = session.query(User.id).order_by(desc('id')) # 以id倒序排序
>>> list(query)
[(18,), (17,), (16,), (15,), (14,), (13,), (12,)]
- 使用group_by方法对查询结果进行分组。
>>> query = session.query(User.username).group_by(User.username)
>>> query.all()
[('qi3',), ('qi4',), ('qi5',), ('qi6',), ('qi',), ('qi2',)]
- 使用get方法查询指定主键的数据。
>>> session.query(User).get(13)
<User(username=qi4, password=qi4)
>>> session.get(User, 13)
<User(username=qi4, password=qi4)
- 使用filter_by方法加关键字参数筛选结果。该方法的特点是不支持运算符,多个参数并列查询,支持多个filter_by方法叠加。
>>> query = session.query(User.id, User.username).filter_by(id=12)
>>> query.all()
[(12, 'qi3')]
>>> # 多个参数并列查询
>>> query = session.query(User.id, User.username).filter_by(id=12, username='qi13')
>>> # filte_by重复调用
>>> query = session.query(User.id, User.username).filter_by(id=12).filter_by(username='qi13')
- 使用filter方法加SQL表达式语句筛选构造结果。其特点是支持Python运算符。filter方法支持很多运算符,其中
>、>=、==(相等)、<、<=、!=等运算符可直接放在函数里作为判断条件,如查询id大于10的数据,表达式为filter(User.id>10);其他运算符功能如下表所示。
| 运算符 | 含义 | 示例 | 说明 |
|---|---|---|---|
| LIKE | 模糊查询 | filter(User.name.like('%word')) | 筛选名字以word结尾的数据 |
| NOT LIKE | 模糊查询的非 | filter(User.name.notlike('%word')) | 筛选名字不以wor的结尾的数据 |
| ILIKE | 不匹配大小写的模糊查询 | filter(User.name.ilike('%word')) | 筛选名字以word结尾的数据,不区分大小写 |
| NOT ILIKE | 不匹配大小写的模糊查询的非 | filter(User.name.notilike('%word')) | 筛选名字不以word结尾的数据,不区分大小写 |
| IN | 在给定范围内查询 | filter(User,id.in_([13,14])) | 筛选id为13和14的数据 |
| NOT IN | 在给定范围外查询 | filter(User.id.notin_([13,14])) | 筛选id不为13和14的数据 |
| IS NULL | 值为NULL | filter(User.username.is_(None)) | 筛选username值为None的数据 |
| IS NOT NULL | 值为非NULL | filter(User.username.isnot(None)) | 筛选username为非空的数据 |
| STARTSWITH | 匹配值以字符串开头 | filter(User.username.startwith('word')) | 筛选username值以word开头的数据 |
| ENDSWITH | 匹配值以字符串结尾 | filter(User.username.endswith('word')) | 筛选username值以word结尾的数据 |
| CONTAINS | 匹配值包含指定字符串 | filter(User.username.contains('word')) | 筛选username值包含word的数据 |
| BETWEEN | 匹配值在指定范围 | filter(User.id.between(10,14)) | 筛选id值在10和14之间的数据 |
| AND | 逻辑与 | filter(and_(User.id==1, User.username == 'qi')) | 筛选id为1和username为qi的数据 |
| OR | 逻辑或 | filter(or_(User.id==10, User.username=='qi')) | 筛选id为10或username为10的数据 |
>>> from sqlalchemy import or_
>>> query = session.query(User).filter(or_(User.id == 13, User.username == 'qi6'))
>>> list(query)
[<User(username=qi4, password=qi4), <User(username=qi6, password=qi6)]
- 多个filter或filter_by语法可以混用,顺序没有标准。
- 需要注意,query得到的对象是一个Query对象,而不是Python内置的元组或列表。使用Query对象的all()方法可以获取所有结果。使用first()可以获取第一个运算结果。
>>> query = session.query(User)
>>> query.all()
[<User(username=qi3, password=qi3), <User(username=qi4, password=qi4), <User(username=qi5, password=qi5), <User(username=qi6, password=qi6), <User(username=qi, password=qi), <User(username=qi2, password=qi2), <User(username=qi3, password=qi3)]
>>> query.first()
<User(username=qi3, password=qi3)
- 使用one()方法获取唯一一个结果,当结果集没有结果或有多个结果时都将引发错误,只有一个结果才会返回该结果。one_or_None()方法在只有一个结果时返回该结果,无结果时返回None,有多个结果时会引发错误。
>>> query = session.query(User) # 存在多个结果
>>> query.one()
Traceback (most recent call last):
...
sqlalchemy.exc.MultipleResultsFound: Multiple rows were found when exactly one was required
>>> query = session.query(User).where(User.id==13) # 只有一个结果
>>> query.one()
<User(username=qi4, password=qi4)
>>> query = session.query(User).where(User.id==-1) # 无结果
>>> query.one()
Traceback (most recent call last):
...
sqlalchemy.exc.NoResultFound: No row was found when one was required
- 使用offset()、limit()、slice()限定查询范围。offset用于设置索引偏移量,limit用于设置查询数量,slice用于设置查询索引及查询量。
>>> query = session.query(User)
>>> query.all()
[<User(username=qi3, password=qi3), <User(username=qi4, password=qi4), <User(username=qi5, password=qi5), <User(username=qi6, password=qi6), <User(username=qi, password=qi), <User(username=qi2, password=qi2), <User(username=qi3, password=qi3)]
>>> query = session.query(User).offset(2)
>>> query.all()
[<User(username=qi5, password=qi5), <User(username=qi6, password=qi6), <User(username=qi, password=qi), <User(username=qi2, password=qi2), <User(username=qi3, password=qi3)]
>>> query = session.query(User).slice(2, 4) # 返回索引位于2和4之间的数据,不包括4
>>> query.all()
[<User(username=qi5, password=qi5), <User(username=qi6, password=qi6)]
>>> query = session.query(User).limit(3) # 返回3条数据
>>> query.all()
[<User(username=qi3, password=qi3), <User(username=qi4, password=qi4), <User(username=qi5, password=qi5)]
- 使用count方法返回结果个数,使用func、count方法构造具体的统计字段。
>>> query = session.query(User)
>>> query.count()
7
>>> from sqlalchemy import func
>>> query = session.query(func.count(User.username), User.username).group_by(User.username) # 对指定字段计数,需要根据该字段先分组
>>> query.all()
[(2, 'qi3'), (1, 'qi4'), (1, 'qi5'), (1, 'qi6'), (1, 'qi'), (1, 'qi2')]
删除数据
delete方法用于删除数据。同时也可以使用Session.execute方法和Query.delete方法删除一个数据对象。Session.delete方法适用于删除多个元素,Session.execute和Query.delete适用于批量删除。
>>> session.query(User).all()
[<User(username=qi3, password=qi3), <User(username=qi4, password=qi4), <User(username=qi5, password=qi5), <User(username=qi6, password=qi6), <User(username=qi, password=qi), <User(username=qi2, password=qi2), <User(username=qi3, password=qi3)]
>>> obj = session.query(User).first()
>>> session.delete(obj)
>>> session.commit()
>>> session.query(User).all()
[<User(username=qi4, password=qi4), <User(username=qi5, password=qi5), <User(username=qi6, password=qi6), <User(username=qi, password=qi), <User(username=qi2, password=qi2), <User(username=qi3, password=qi3)]
>>> session.query(User).filter_by(username='qi').delete()
1
>>> session.commit()
>>> session.query(User).all()
[<User(username=qi4, password=qi4), <User(username=qi5, password=qi5), <User(username=qi6, password=qi6), <User(username=qi2, password=qi2), <User(username=qi3, password=qi3)]
书中还有第三种方式,为
session.execute(User.__table__.delete(User.__table__.c.name=='qi3')),但是我运行失败了,而这个为命令行运行,没有代码补全,我也就不想再继续研究了。
ORM事务操作
当初始化Session时,session处于无事务状态。当Session接收到需要执行SQL请求,如commit方法、flush方法,请求会传递给引擎,引擎通过query方法、execute方法执行SQL。收到这些请求后,Session配置的引擎会与会话维护的、正在进行的事务相关联。书中有更多关于ORM事务的介绍,这里不介绍了。
Session提供了一个rollback方法用于回滚事务,若当前事务有嵌套事务则回滚嵌套事务。会话中已提交的更改都将被取消,不会提交到数据库中,使用begin(subtransaction=True)方法开启的子事务也会全部关闭。如果使用了begin(nested=True)事务保存点,那么rollback方法会回滚到最近的保存点。
下面将介绍几种SQLAlchemy事务的使用场景和方式。
使用保存点
通过begin_nested方法可以设置任意数量的保存点,但是每个保存点必须有对应的rollback方法或commit方法来发布事务。一般常用begin_nested方法与begin方法,它们都可用于上下文管理器中。
# 使用方式一
session = Session()
session.add(u1)
session.add(u2)
session.begin_nested() # 设置一个保存点
session.add(u3)
session.rollback() # 将撤销u1对象,保留u1、u2
session.commit() # 提交u1、u2操作
# 使用方式二
for user in users:
try:
with session.begin_nested(): # 隐式提交事务
session.merge(user) # 将给定实例的状态复制到Session
except:
print(f'跳过{user}')
session.commit()
自动提交模式
该模式比较老,使用Session.begin方法启动一个事务,或者再需要数据库操作时自动开启事务,比如调用session.execute()。使用时需先设置autocommit=True,然后调用session.begin方法开启新事务,最后使用session.commit()方法提交事务或使用session.rollback()方法回滚事务,一个完整的事务就结束了。
Session = sessionmaker(bind=engine, autocommit=True)
session = Session()
# 使用try-except
session.begin() # 标记事务开始
try:
user1 = session.query(User).get(1)
user2 = session.query(User).get(2)
user1.username = '棋'
user2.username = '棋2'
session.commit()
except:
session.rollback()
raise
# 使用with子句
with session.begin():
user1 = session.query(User).get(1)
user2 = session.query(User).get(2)
user1.username = '棋'
user2.username = '棋2'
自动提交子事务
子事务由Session.begin产生,这是一个非事务性的定界结构,该结构允许嵌套调用begin和commit方法,让独立于启动事务的外部代码在事务中执行,也可以在已经划分事务的块内进行。
subtransactions一般只和autocommit使用,达到事务块嵌套的效果,使得任意数量的函数都可以调用Connection.begin和Transaction.commit()。
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, create_engine, update
from sqlalchemy.orm import sessionmaker
Base = declarative_base() # 创建一个声明性基类
engine = create_engine("mysql://root:123456@127.0.0.1:3306/teaching?charset=utf8", pool_size=20, max_overflow=0,
pool_recycle=3600, echo="debug") # 配置引擎
Session = sessionmaker(engine)
class User(Base):
"""
创建一个声明性数据表类
"""
__tablename__ = 'users' # 对应数据库中的表名
id = Column(Integer, primary_key=True)
name = Column(String(50))
fullname = Column(String(50))
nickname = Column(String(50))
def __repr__(self):
"""
自定义类描述
:return:
"""
return f"<User(name={self.name}, fullname={self.fullname}, nickname={self.nickname})>"
def a(session):
session.begin(subtransactions=True)
try:
b(session)
session.commit()
print("子事务a执行完成")
except:
session.rollback()
raise
def b(session):
session.begin(subtransactions=True)
try:
session.add(User(**{"name": "杰克", "fullname": "杰克·斯帕罗", "nickname": "杰克船长"}))
session.commit()
print("子事务b执行完成")
except:
session.rollback()
raise
if __name__ == '__main__':
# Base.metadata.create_all(engine) # 在数据库生成相应表
session = Session(autocommit=True)
a(session)
session.close()