MySQL表数据查找
基本查询语句
SELECT语句是最常用的查询语句,它的使用方式有点复杂,但是功能非常强大。语法如下。
select selection_list
from 数据表名
where primary_columns
group by grouping_columns
order by sorting_columns
having secondary_constraint
limit count;
其中的子句将在后面介绍。
使用SELECT语句查询一个数据表
使用具体的字段名查询该字段,或者用*号查询全字段。如:
select * from tb1;
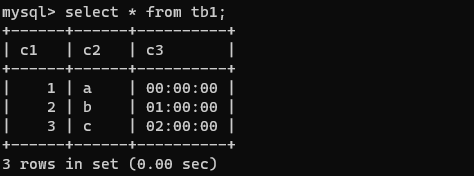
查询表中部分数据
select c1,c3 from tb1;
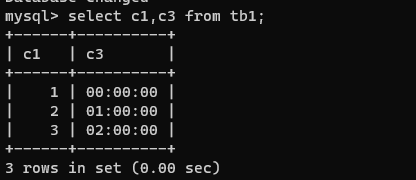
查询多个表中的数据
select c1,c2,c3,c4,c5 from tb1,tb2;
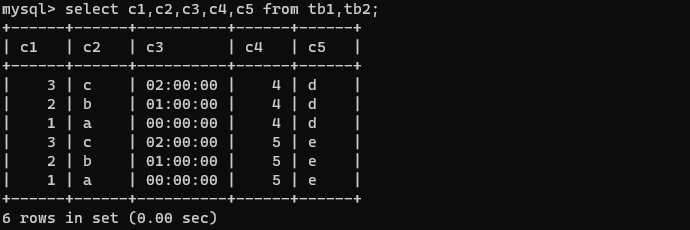
单表查询
查询所有字段
语法:
SELECT * FROM 表名;
如:
select * from tb1;
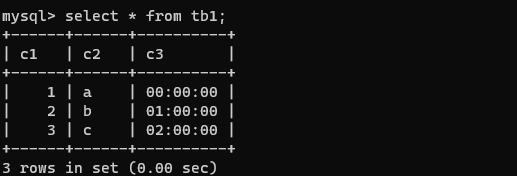
查询指定字段
语法:
SELECT 字段名 FROM 表名;
如:
select c1,c3 from tb1;
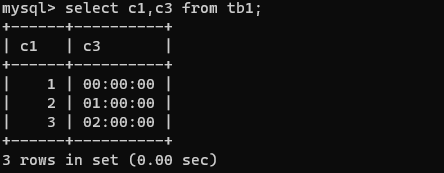
查询指定数据
可以通过使用WHERE子句来设定查询条件。如:
select * from tb1 where c1>1;
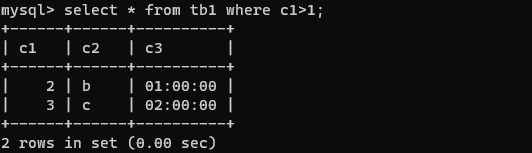
带关键字IN的查询
关键字IN可以判断某个字段的值是否在某一集合中,语法:
SELECT * FROM 表名 WHERE 条件 [NOT] IN (元素1,元素2,...);
如:
select * from tb1 where c1 in (0,1,2);
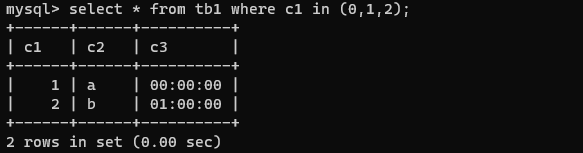
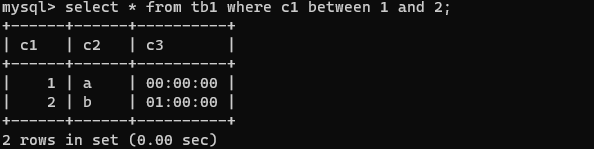
带关键字BETWEEN AND的范围查询
关键字BETWEEN AND可以判断某个字段的值是否在指定的范围之内,语法:
SELECT * FROM 表名 WHERE 条件 [NOT] BETWEEN 取值1 AND 取值2;
如:
select * from tb1 where c1 between 1 and 3;
带LIKE的字符匹配查询
LIKE是比较常用的比较运算符,可以实现模糊查询,它有“%”、“_”两种通配符。
“%”表示匹配一个或者多个字段,可以代表任意长度的字符串,长度可以为0。
“_”表示只匹配一个字符。
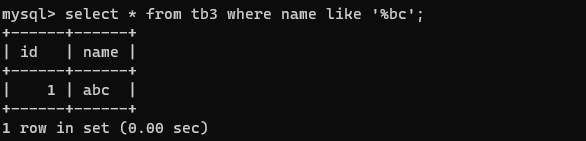
如下面的语句代表查找字段以bc为结尾的数据行:
select * from tb3 where name like '%bc';
用IS NULL查找空值
IS NULL关键字可以判断字段的值是否为空值,语法如下:
IS [NOT] NULL
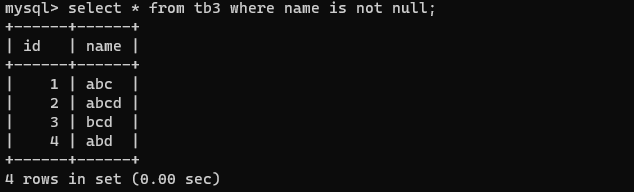
如查找表中不是NULL的字段:
select * from tb3 where name is not null;
带关键字AND的多条件查询
语法:
SELECT * FROM 数据表名 WHERE 条件1 AND 条件2 [...AND 条件表达式n];
如:
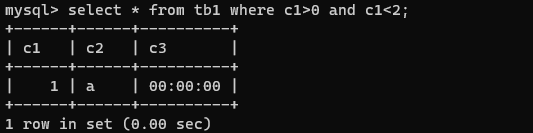
select * from tb1 where id>0 and id<2;
带OR的多条件查询
语法:
SELECT * FROM 数据表名 WHERE 条件1 OR 条件2[...OR 条件表达式n];
如:
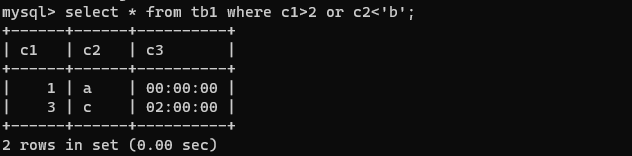
select * from tb1 where c1>2 or c2<'b';
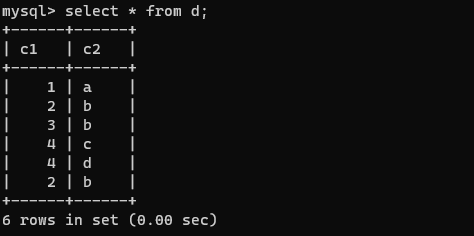
用DISTINCT关键字去除结果中的重复行
语法:
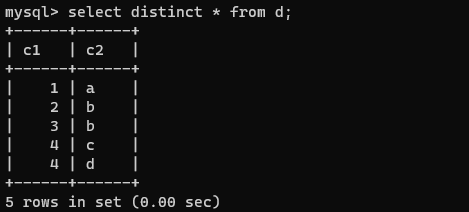
SELECT * DISTINCT 字段名 FROM 表名;
如:
去重前:
使用DISTINCT去重后:
使用ORDER BY关键字对查询结果排序
语法:
ORDER BY [ASC|DESC]
其中,ASC表示按照升序排序,DESC表示按照降序排序。
如:
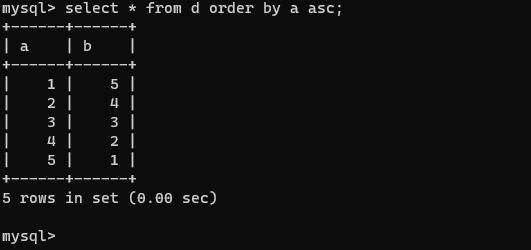
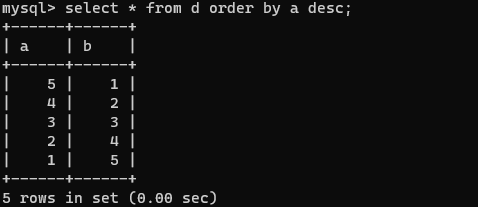
select * from d order by a asc;
select * from d order by a desc;
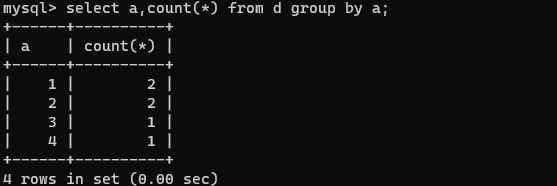
用GROUP BY关键字分组查询
- 单独使用GROUP BY关键字分组
如:
select a,count(*) from d group by a;
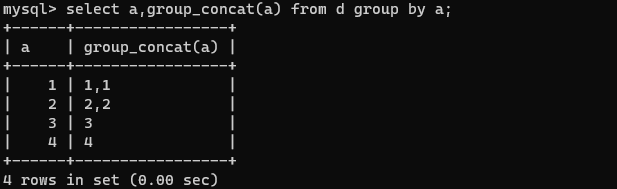
- GROUP BY关键字和GROUP_CONCAT()函数一起使用
通常情况下,GROUP BY关键字和聚合函数一起使用。
如:
select a,group_concat(a) from d group by a;
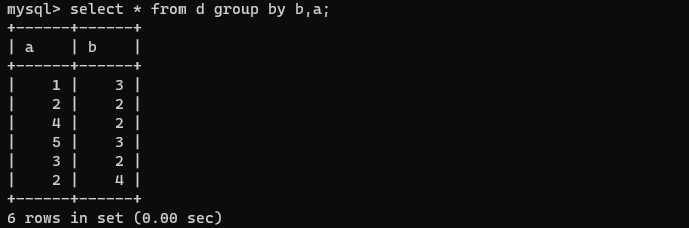
- 按多个字段分组
若第一个字段有相同值时再按照第二个字段分组。
select * from d group by b,a;
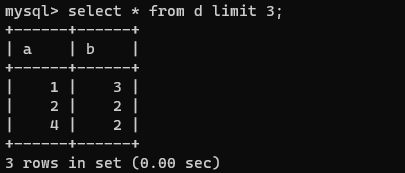
用LIMIT限制输出结果的数量
如:
select * from d limit 3;
聚合函数查询
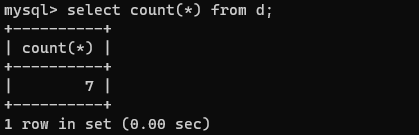
COUNT()函数
COUNT()的参数若为非“*”的参数,返回所选集合中非NULL值的行的数目。对于参数“*”,返回集合中所有行的数目,包含NULL值的行。没有WHERE子句的count(*)是经过内部优化的,能够快速返回表中所有数据的总数。
如:
select count(*) from d;
SUM()函数
SUM()函数可以求出表中某个数值类型字段取值的总和。
如:
select *,sum(a) from d;

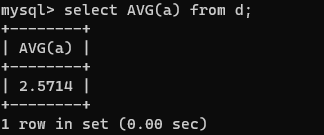
AVG函数
AVG()函数可以返回某个字段的平均值。
如:
select AVG(a) from d;
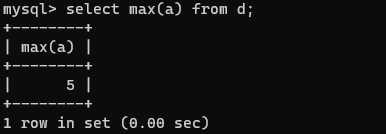
MAX()函数
MAX()函数可以返回某个字段的最大值。
如:
select max(a) from d;
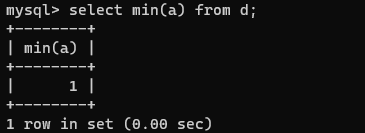
MIN()函数
MIN()函数可以返回某个字段的最小值。
select min(a) from d;
连接查询
连接是把不同的表的记录连接到一起,MySQL从一开始就很好地支持连接操作。
内连接查询
内连接是普遍的连接类型,而且是最匀称的,它们要求构成连接的每个表的共有列匹配,不匹配的行将被删除。
select book_list.bookid,book_list.bookname,book_list.author,book_borrow.borrowtime,book_borrow.borrower from book_list,book_borrow where id=bookid;
上面代码中,设置了若book_list中的书的“bookid”和book_borrow中借书的“id”相等才连接。

外连接查询
外连接就是使用OUT JOIN关键字连接两个表。选取一个主表,然后在选取一个副表,将主表和副表连接起来。语法如下:
SELECT 字段名称 FROM 表名1 LEFT|RIGHT JOIN 表名2 ON 表名1.字段名1=表名2.属性名2;
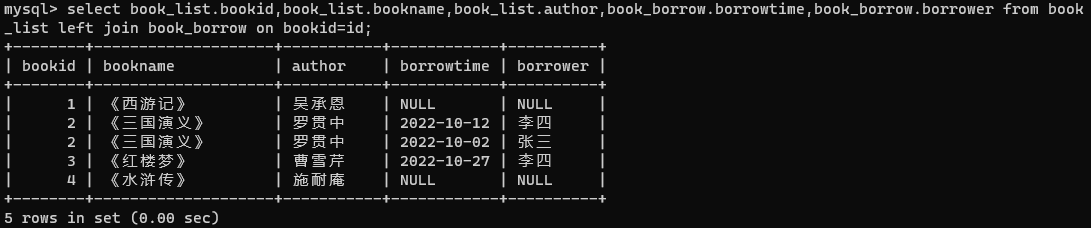
- 使用左外连接:
左外连接是将左表中所有数据分别都与右表中每条数据相连接组合,返回的结果除了左连接的数据以外,还包括左表中不符合条件的数据,并在右表中不符合条件的位置添加NULL。
select book_list.bookid,book_list.bookname,book_list.author,book_borrow.borrowtime,book_borrow.borrower from book_borrow left join book_list on bookid=id;

针对这里的图书信息表和借阅表,内连接和左外连接得到的结果一样。这是因为左表(借阅表)中的数据在右表 你 (图书信息表)中一定有之相对应的数据。如果将图书信息表作为左表,借阅表作为右表,就会得到如下图的数据。
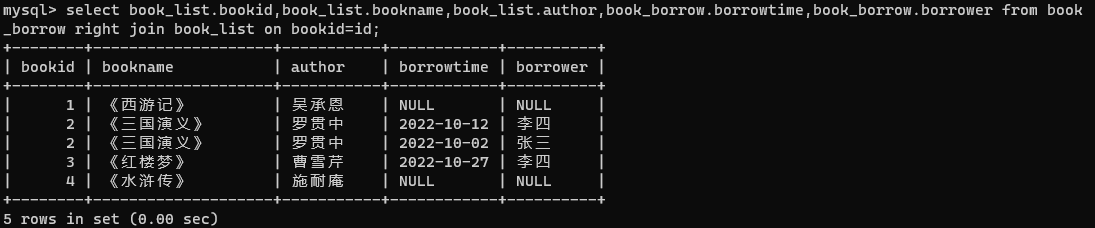
- 使用右外连接
右外连接是指将右表中的所有数据分别与左表中的每条数据进行连接组合,返回的结果除内连接的数据以外,还包括右表中不符合条件的数据,并在左表的相应列中添加NULL。
select book_list.bookid,book_list.bookname,book_list.author,book_borrow.borrowtime,
book_borrow.borrower from book_borrow right join book_list on bookid=id;
- 外连接的列顺序还是根据select后面的字段顺序保持一致,也就是说左外连接和右外连接不会改变字段的顺序。
- 若为左连接,那么左表是LEFT JOIN左边的表,也是主表,若为右连接,那么右表是RIGHT JOIN右边的表,也是主表。
复合条件连接查询
在连接查询时,也可以添加其他的查询条件,使查找结果更加准确。
select book_list.bookid,book_list.bookname,book_list.author,book_borrow.borrowtime,book_borrow.borrower from book_list,book_borrow where id=bookid and isback=0;

子查询
子查询就是一个SELECT语句查询另一个SELECT语句的附属。MySQL中支持嵌套多个查询,在里面查询的结果可以作为外面查询的条件。
带关键字IN的子查询
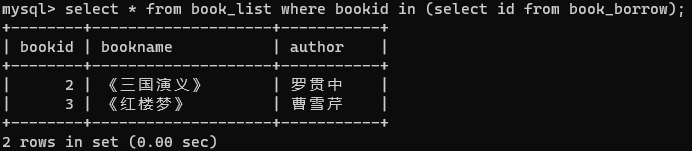
只有在子查询返回至少一个结果时才可以使用带IN关键字的子查询。IN关键字用于检测结果集中是否存在某个特定的值,若检测成功则执行外部查询。
在下面的例子中,我们每次可以执行查询book_borrow表中id字段的所有值,然后再执行查询book_list表中bookid字段含有id字段的可能取值来查询被借阅的书的信息,但是book_borrow中字段的值随时会发生改变,因此我们可以一次使用子查询简化操作。
select * from book_list where bookid in (select id from book_borrow);
带比较运算符的子查询
如下方代码代表查询张三借阅的书的信息:
select * from book_list where book_list.bookid=(select id from book_borrow where borrower='张三');

带EXISTS关键字的子查询
此情况子查询不返回查询的记录而是返回一个真假值。当内层查询语句查询到满足条件的记录就返回真值(true),否则返回假值(false);当值为真值时外层查询语句开始查询,所以查询的条件一般在内查询实现。
如下面的语句查询李四是否借阅了且没有归还的书,若有就输出:
select * from book_list where exists (select * from book_borrow where borrower='李四' and isback='0' and book_list.bookid=book_borrow.id);

NOT EXISTS关键字与EXISTS关键字相反,当返回值:为true时外查询不查询。
带ANY关键字的子查询
通常与比较运算符一起使用,它代表若内查询中的条件有一个满足就执行外查询,语法如下:
列名 比较运算符 ANY(内查询语句)
如果比较运算符是“<”,则表示小于子查询结果集中的某一个值,如果是“>”,则表示至少大于子查询结果集中的任何一个值。
如下面查找比一年三班最低分高的全部学生信息:
select * from tb_student where score>any(select score from tb_student where class='1.3');
带ALL关键字的子查询
表示满足所有条件。语法如下
列名 比较运算符 ALL(子查询)
如下面查找是否有比一年三班最高分高的全部学生信息:
select * from tb_student where score>all(select score from tb_student where class='1.3');
合并查询结果
使用UNION关键字
使用该关键字可以将多个结果合并在一起并且去除重复数据。
如下面实现同事查找两本书架上的书,先查询各自的书。
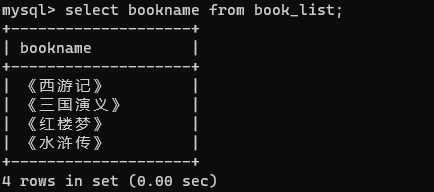
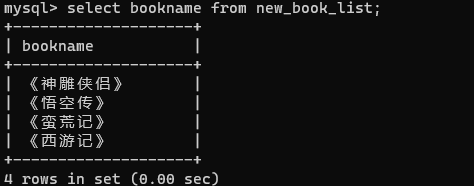
现在查询两本书架上所有的书,代码如下:
select bookname from book_list union select * from new_book_list;
结果就是【西游记、三国演义、红楼梦、水浒传、神雕侠侣、悟空传、蛮荒记】这几本书。
使用UNION ALL关键字
该关键字和UNION唯一的区别就是该关键字不会去除相同的记录。
select bookname from book_list union all select * from new_book_list;
这步结果就是西游记会显示两次,因为两个表都有
为表和字段取别名
若表或者字段的名称特别长,可以给表或者字段取别名,采用这种方式可以使代码更加简洁易读,能使查询更加方便。
为表取别名
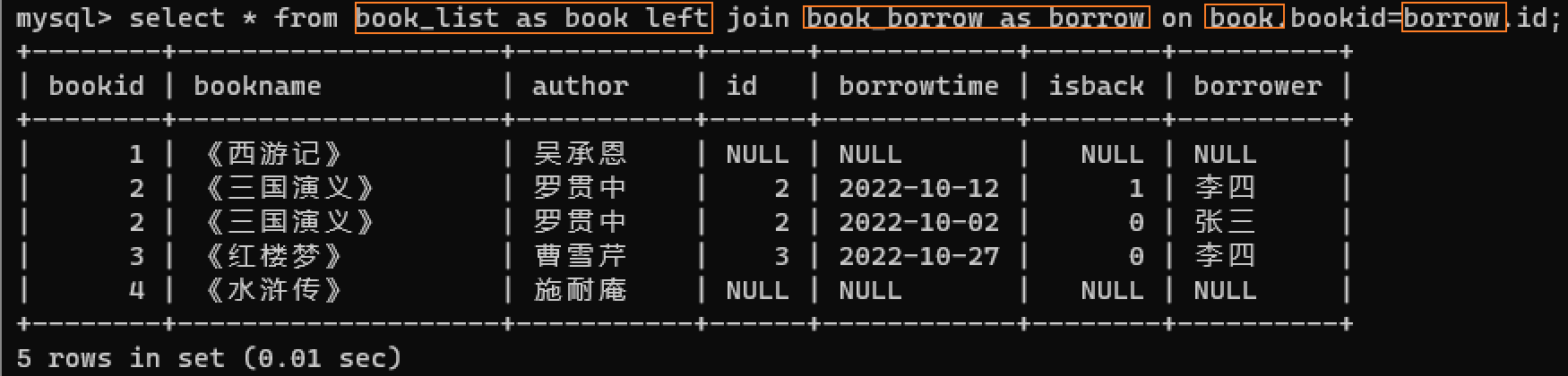
下面的代码就将book_list表取别名为book,将book_borrow表取别名为borrow。
select * from book_list as book left join book_borrow as borrow on book.bookid=borrow.id;
为字段取别名
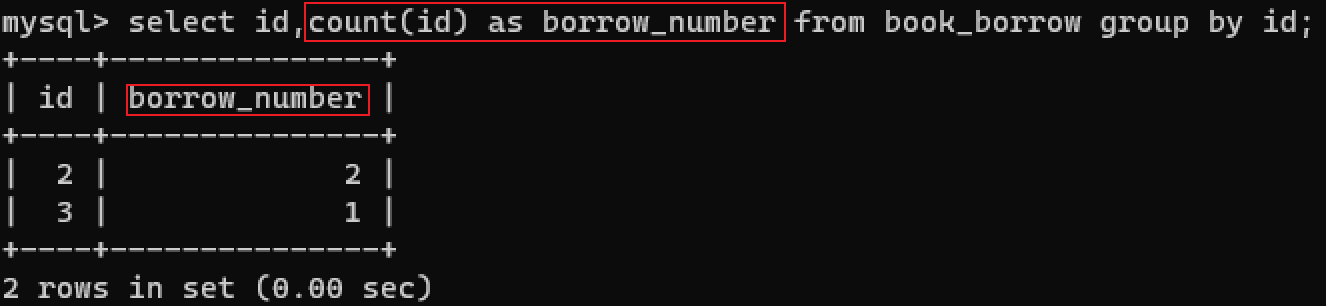
为字段取别名就是在输出时让该列的名称用别名替代。
select id,count(id) as borrow_number from book_borrow;
使用正则表达式查询
使用正则表达式比使用通配符更加强大,使用关键字REGEXP关键字匹配查询正则表达式,语法如下:
字段名 REGEXP '匹配方式'
正则表达式请在其他地方学习,这里不过多阐述。
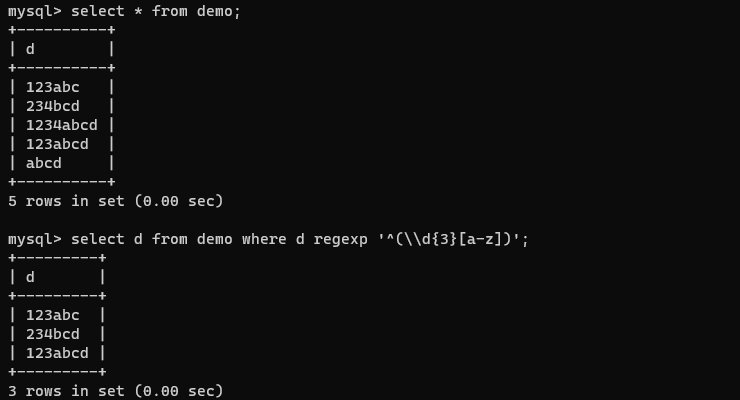
如下面的正则表达式表达式表示匹配以三个数字加一个小写字母开头的字符串。
select d from demo where d regexp '^(\\d{3}[a-z])';