
外观
卷积神经网络
图像基本知识
图像是由像素点组成的,每个像素点的取值范围为:[0, 255]。像素值越接近于 0,颜色越暗,接近于黑色;像素值越接近于 255,颜色越亮,接近于白色。
在深度学习中,我们使用的图像大多是彩色图,彩色图由 RGB 3 个通道组成,如下图所示:
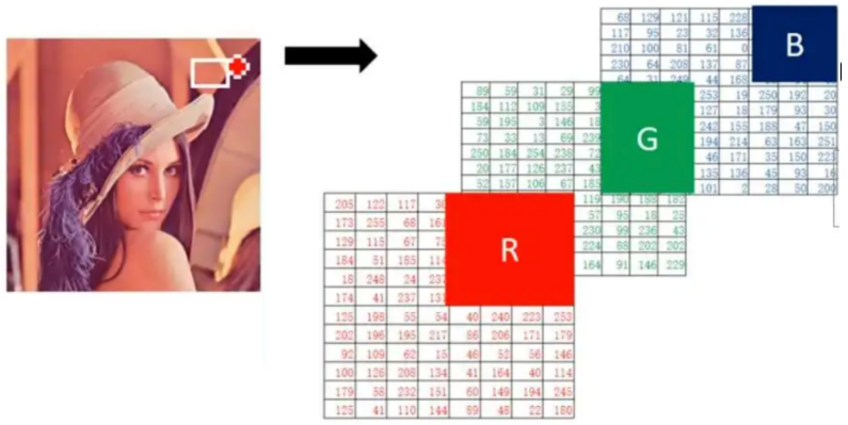
计算机中的图像分为:
- 二值图像,1 通道(1 个二维矩阵),像素值:0 或 1
- 灰度图像,1 通道,像素值:0-255
- 索引图像,1 通道,索引值 -> RGB 二维矩阵行下标,彩色图像,像素值:0-255
- RGB真彩色图像(最常用),3 通道(3 个二维矩阵),R G B三个二维矩阵,像素值:0-255
可以使用 Matplotlib 处理图像:
import numpy as np
import matplotlib.pyplot as plt
# 全0数组是黑色的图像
img = np.zeros([200, 200, 3])
# 展示图像
plt.imshow(img)
plt.show()
# 全255数组是白色的图像
img = np.full([200, 200, 3], 255)
# 展示图像
plt.imshow(img)
plt.show()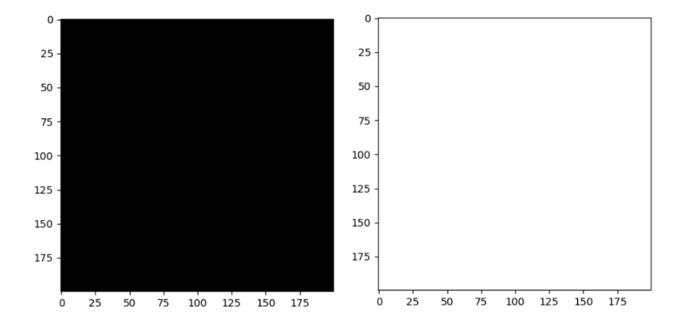
img = plt.imread("data/img.jpg")
# 图像形状 高,宽,通道
print("图像的形状(H, W, C):\n", img.shape)
# 展示图像
plt.imshow(img)
plt.axis("off")
plt.show()卷积神经网络定义
卷积神经网络(Convolutional Neural Network)是含有卷积层的神经网络。卷积层的作用就是用来自动学习、提取图像的特征。
CNN 网络主要由三部分构成:卷积层、池化层和全连接层构成:
- 卷积层负责提取图像中的局部特征;
- 池化层用来大幅降低参数量级(降维);
- 全连接层用来输出想要的结果。

图中的卷积神经网络要识别图中是一辆车还是什么物体。
最左边是数据输入层,它需要做的有去均值(各维度都减对应维度的均值,使各个维度的数据都中心化为 0,避免数据过多偏差,影响训练效果)、归一化、PCA 等等。CNN只对训练集做“去均值”这一步。
中间的层是:
- 卷积层(CONV):线性乘积求和,提取图像局部特征
- 激励层(RELU):RELU激活函数,输入数据转换为输出数据
- 池化层(POOL):取区域平均值或最大值,大幅降低参数量级(降维)
最右边是全连接层,它输出 CNN的预测结果。
卷积层
卷积层(Convolutional Layer)通过卷积操作提取输入数据中的特征(例如图像中的边缘、纹理、形状等)。
卷积层利用卷积核(滤波器)对输入进行处理,从而生成特征图(feature map),并且每个卷积层能够提取不同层次的特征,从低级特征(如边缘)到高级特征(如物体的形状)。
卷积层的主要作用如下:
- 特征提取:卷积层的主要作用是从输入图像中提取低级特征(如边缘、角点、纹理等)。通过多个卷积层的堆叠,网络能够逐渐从低级特征到高级特征(如物体的形状、区域等)进行学习。
- 权重共享:在卷积层中,同一个卷积核在整个输入图像上共享权重,这使得卷积层的参数数量大大减少,减少了计算量并提高了训练效率。
- 局部连接:卷积层中的每个神经元仅与输入图像的一个小局部区域相连,这称为局部感受野,这种局部连接方式更符合图像的空间结构,有助于捕捉图像中的局部特征。
- 空间不变性:由于卷积操作是局部的并且采用权重共享,卷积层在处理图像时具有平移不变性。也就是说,不论物体出现在图像的哪个位置,卷积层都能有效地检测到这些物体的特征。
卷积计算
卷积计算等同于线性层加权求和计算,通过带有权重的卷积核和图像的特征值进行点乘运算, 得到新特征图上的一个特征值。
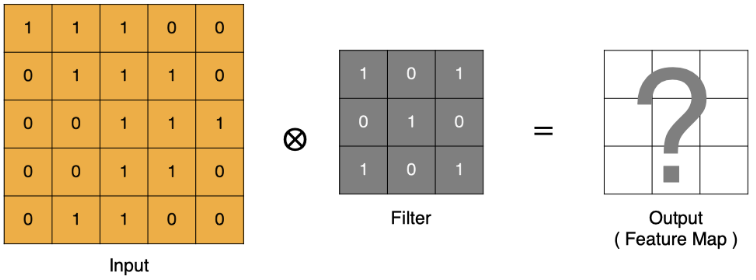
input 表示输入的图像;filter 表示卷积核,也叫做滤波矩阵;input 经过 filter 得到输出为最右侧的图像,该图叫做特征图。
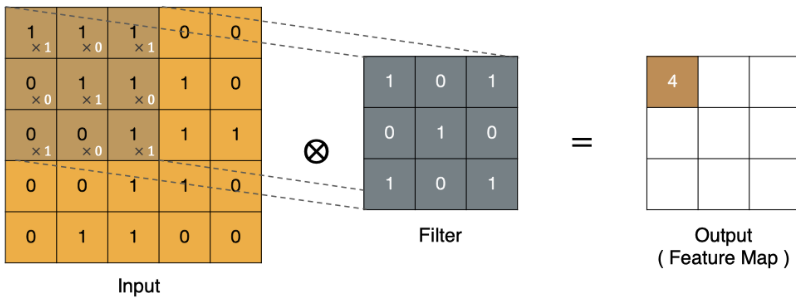
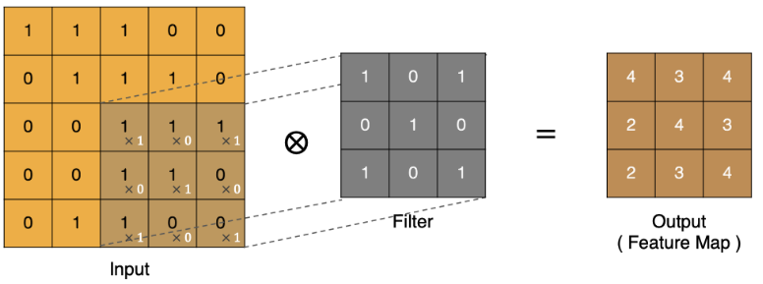
卷积核:也被称为滤波矩阵,它内部的值都是随机的,它从输入的左上角开始做点乘,结果作为特征图的 [0,0] 的值,然后通过步长向上或右移动,重复计算,将值填入它相邻的格中。
Padding 填充
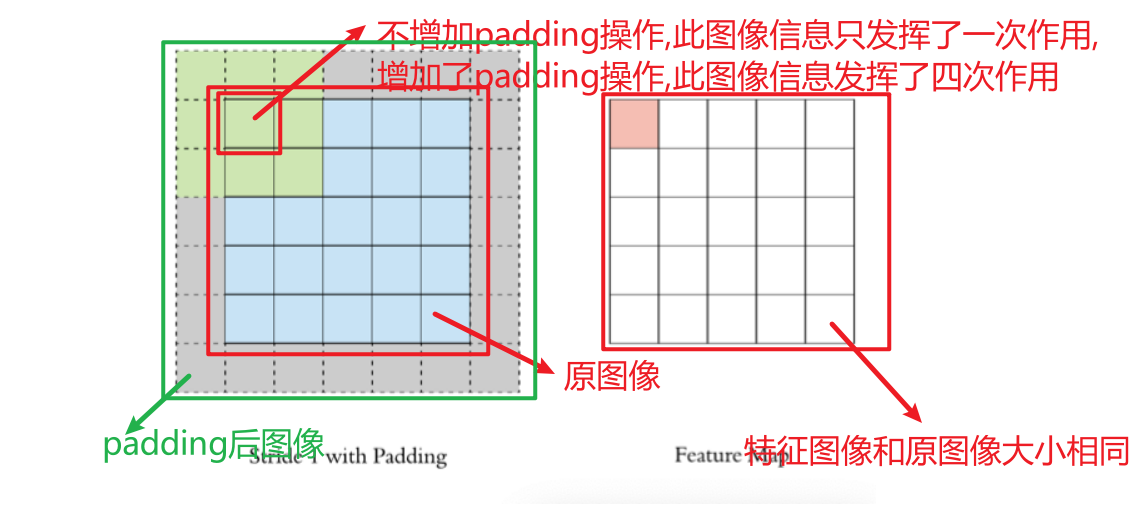
通过上面的卷积计算过程,最终的特征图比原始图像小很多,如果想要保持经过卷积后的图像大小不变, 可以在原图周围添加 padding 来实现。
padding(填充)操作用于处理卷积时图像边缘的像素。
其目的是在输入图像的边界周围添加额外的像素(通常是零),从而解决卷积操作时边缘信息丢失的问题。
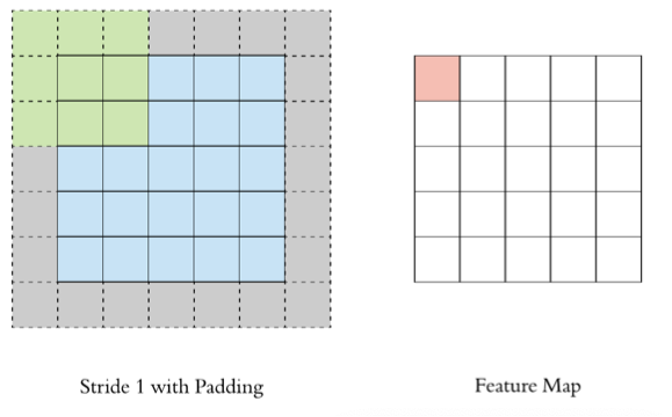
Padding的主要作用:
- 保持空间维度:如果不使用 padding,每次卷积操作后,特征图的尺寸都会缩小。多次卷积后,特征图会变得非常小,可能会丢失重要的边缘信息。Padding可以帮助维持输出特征图的尺寸与输入相同或接近相同。
- 保留边缘信息:图像边缘的像素在卷积过程中参与的计算次数较少,这意味着边缘信息在特征提取过程中容易丢失。Padding通过在边缘添加额外的像素,增加了边缘像素的参与度,从而更好地保留了边缘信息。
- 提高性能:Padding有助于避免由于特征图尺寸快速缩小而导致的信息丢失,从而提高模型的性能,尤其是在处理较小的图像或需要进行多层卷积时。
Padding的类型:
- Valid Padding (No Padding): 不进行任何填充。卷积核只在输入图像的有效区域内滑动。输出尺寸会缩小。
- Same Padding: 添加足够的填充,使得输出特征图的尺寸与输入相同。
- Full Padding: 尽可能多地添加填充,使得卷积核的每个元素都至少在输入图像上滑动一次。输出尺寸会增大。
Stride 步长
Stride(步长)指的是卷积核在图像上滑动时的步伐大小,即每次卷积时卷积核在图像中向右(或向下)移动的像素数。步长直接影响卷积操作后输出特征图的尺寸,以及计算量和模型的特征提取能力。
Stride的作用:
- 降低计算复杂度:更大的步长意味着卷积核移动的次数更少,从而减少了计算量,并加快了训练和推理速度。
- 有利于池化层降维:步长越大,生成的特征图尺寸越小。这类似于池化的降维效果。
- 增大感受野:虽然更大的步长会减小特征图的尺寸,但它同时也会增大每个神经元在输入数据上的感受野。这意味着每个神经元能够捕捉到更大范围的输入信息。
Stride的选择:取决于具体的应用场景和网络架构
- Stride = 1: 这是最常见的设置,尤其是在网络的早期层。它允许保留更多的空间细节。
- Stride > 1: 通常用于减小特征图的尺寸和增大感受野,例如在网络的后期层或需要进行快速降维时。 常见的设置包括 stride=2 或 stride=4。
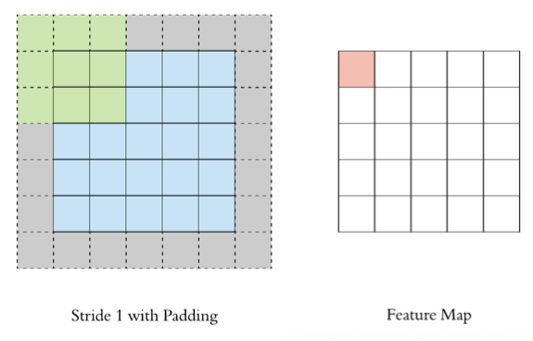
按照步长为1来移动卷积核,计算特征图如下所示:

如果把 Stride 增大为2,也是可以提取特征图的,如下图所示:

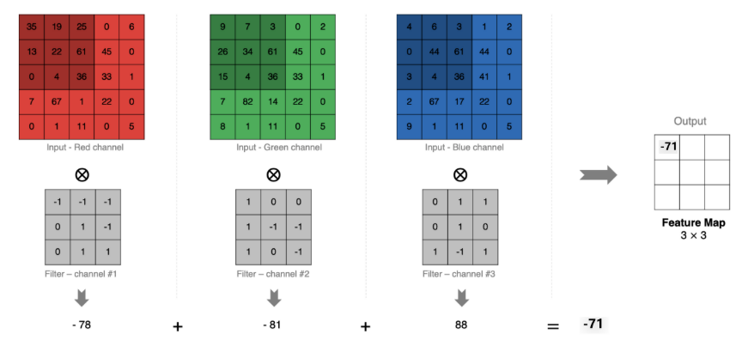
多通道卷积计算
RGB 彩色图像是由 3 个通道组成的,相当于 3 个二维矩阵,每个矩阵分别代表 R/G/B。
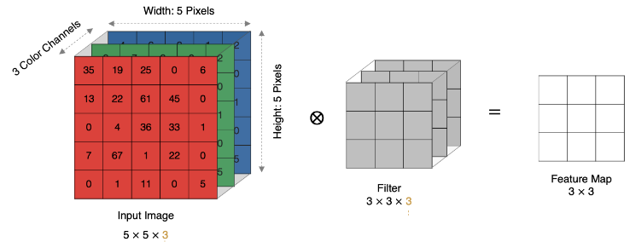
卷积核通道数要和原图像通道数一致。
这时的卷积计算是对应通道二维矩阵进行卷积计算,将每个通道卷积计算的结果加到一起,得到新特征图的一个特征值。
多卷积核卷积计算
每个卷积核都相当于一个神经元,有多少个卷积核就是有多少个神经元,就会提取到多少个二维的特征图。
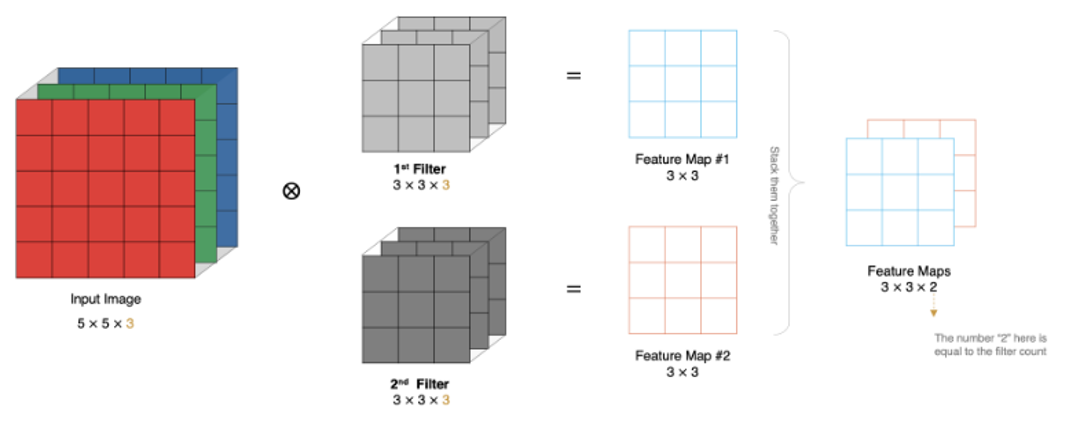
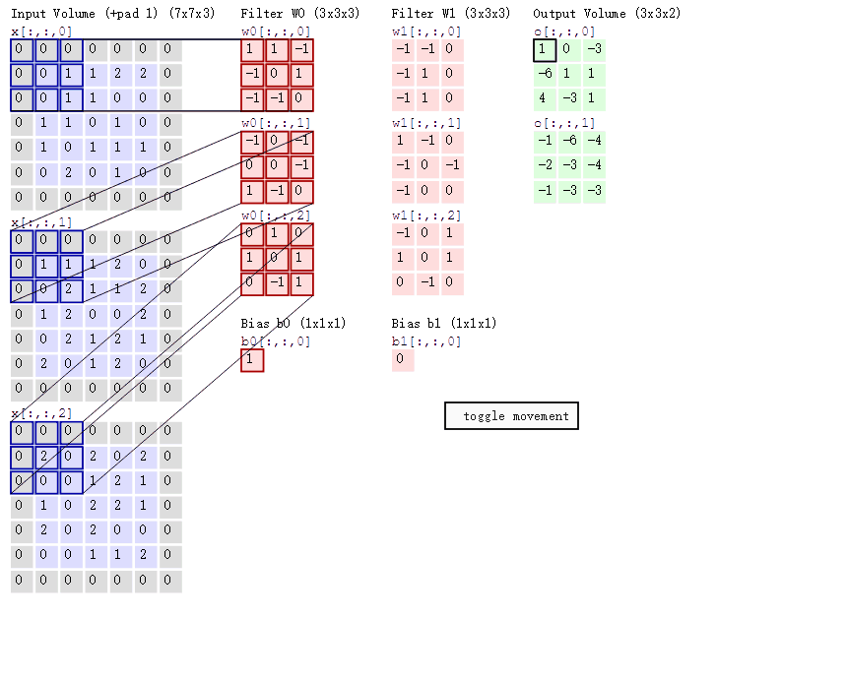
特征图大小
输出特征图的大小与以下参数息息相关:
- size:卷积核/过滤器大小,一般会选择为奇数,比如有 1*1 、3*3、5*5
- Padding:零填充的方式
- Stride:步长
计算方法:
- 输入图像大小: W x W
- 卷积核大小: F x F
- Stride: S
- Padding: P
- 输出图像大小: N x N
以上图为例:
图像大小:5 x 5,卷积核大小:3 x 3,Stride:1,Padding:1,(5 - 3 + 2) / 1 + 1 = 5, 即得到的特征图大小为:5 x 5。
PyTorch 卷积层 API
conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
"""
参数说明:
in_channels: 输入通道数,
out_channels: 输出通道,也可以理解为卷积核kernel的数量
kernel_size:卷积核的高和宽设置,一般为3,5,7...
stride:卷积核移动的步长
padding:在四周加入padding的数量,默认补0
"""import torch
import torch.nn as nn
import matplotlib.pyplot as plt
# 加载RGB真彩图
img = plt.imread('./data/a.jpg')
# 打印读取到的图像信息
print(f'img: {img}, shape: {img.shape}') # HWC (640, 640, 3)
# 3. 把图像的形状从 HWC -> CHW, 思路: img -> 张量 -> 转换维度
img2 = torch.tensor(img, dtype=torch.float)
img2 = img2.permute(2, 0, 1)
print(f'img2: {img2}, shape: {img2.shape}') # [3, 640, 640]
# 因为这里只有1张图, 所以我们给它增加1个维度, 从 CHW -> (1, C, H, W), 1张3通道的 640*640像素的图
img3 = img2.unsqueeze(dim=0)
print(f'img3: {img3}, shape: {img3.shape}') # [1, 3, 640, 640]
# 创建卷积层对象, 提取 特征图.
# 参1: 输入图像的通道数, 参2: 输出图像的通道数(几个特征图), 参3: 卷积核的大小, 参4: 步长, 参5: 填充
conv = nn.Conv2d(3, 4, 3, 2, 0)
# 具体的卷积计算
conv_img = conv(img3)
# 打印卷积后的结果: 1张4通道的319*319像素的图
print(f'conv_img: {conv_img}, shape: {conv_img.shape}') # (1, 4, 319, 319)
# 查看提取到的4个特征图
img4 = conv_img[0]
print(f'img4: {img4}, shape: {img4.shape}') # (4, 319, 319) -> CHW
# 把上述的图从 CHW -> HWC
img5 = img4.permute(1, 2, 0)
# print(f'img5: {img5}, shape: {img5.shape}') # (319, 319, 4) -> HWC
# 可视化第1个通道的特征图.
feature1 = img5[:, :, 3].detach().numpy() # 第0通道(即: 第1通道的) (319, 319)像素图
plt.imshow(feature1)
plt.show()池化层
池化层(Pooling)能够降低维度,从而减少计算量、减少内存消耗,并提高模型的鲁棒性。
池化层通常位于卷积层之后,它通过对卷积层输出的特征图进行下采样,保留最重要的特征信息,同时丢弃一些不重要的细节。
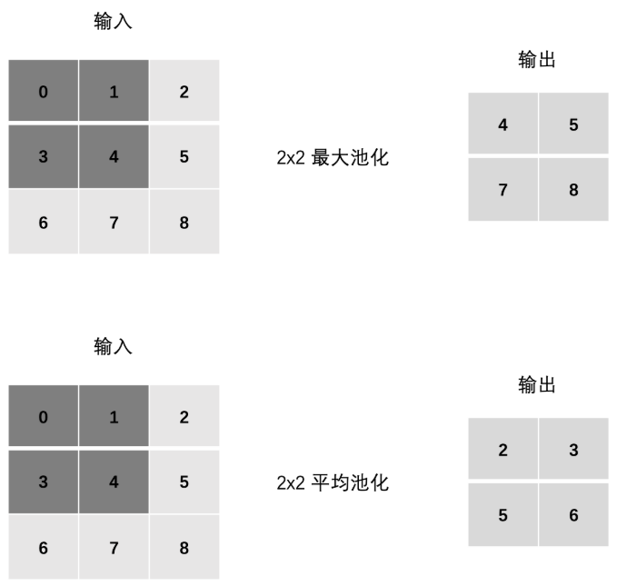
池化层没有神经元,因为它不像卷积层那样有卷积核。
池化分为最大池化和平均池化。如上图,最大池化是每次计算时选取某一区域的最大值作为该区域的输出;而平均池化则是计算平均值。
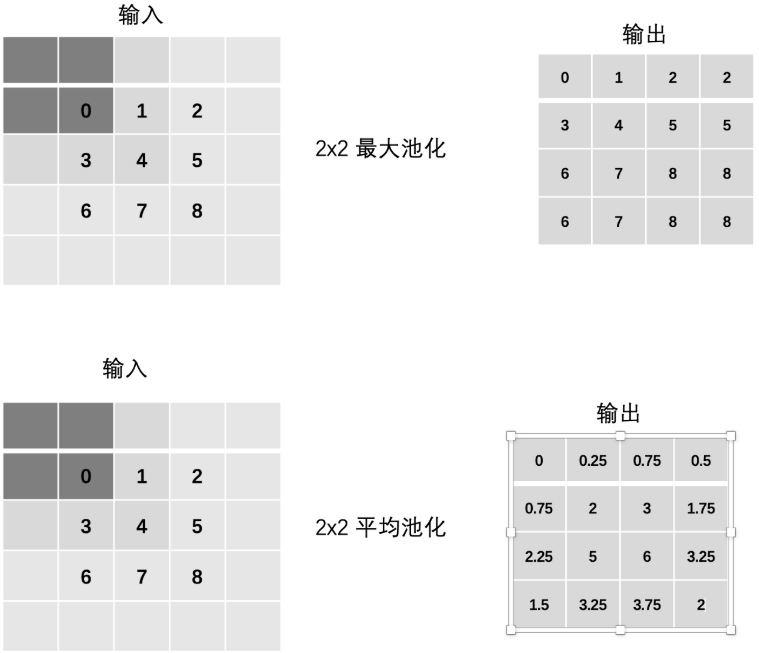
Padding 填充
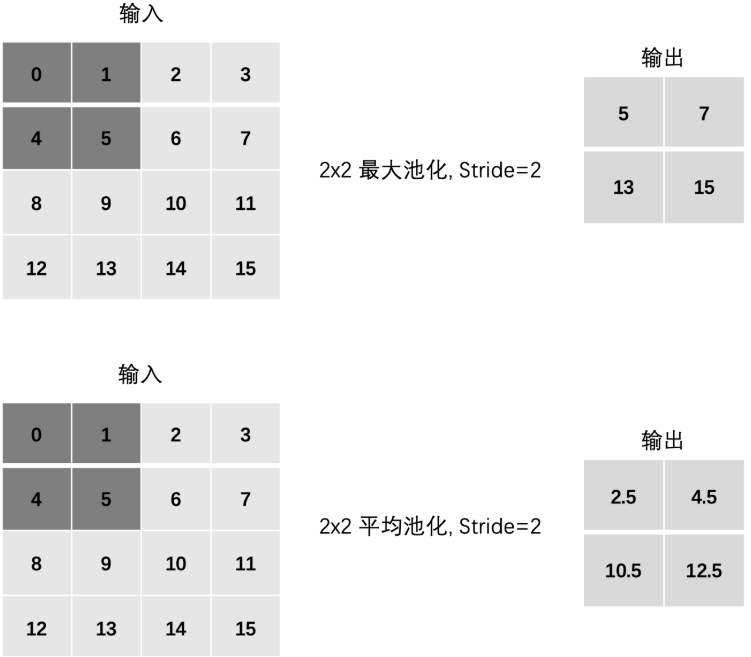
Stride 步长
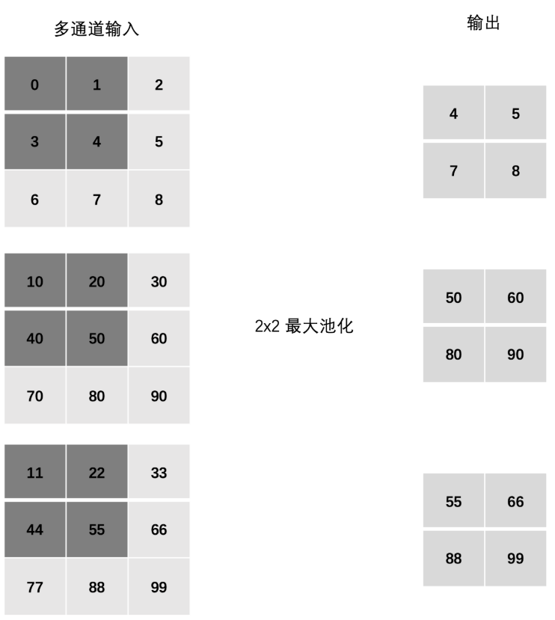
多通道池化层计算
在处理多通道输入数据时,池化层对每个输入通道分别池化,而不是像卷积层那样将各个通道的输入相加。这意味着池化层的输出和输入的通道数是相等的。
PyTorch 池化层 API
# 最大池化
nn.MaxPool2d(kernel_size=2, stride=2, padding=1)
# 平均池化
nn.AvgPool2d(kernel_size=2, stride=1, padding=0)单通道池化:
import torch
import torch.nn as nn
# 创建1个1通道3*3的二维矩阵.
inputs = torch.tensor(
[ # 1 通道C
[ # 3 高度H
[0, 1, 2], # 3 宽度W
[3, 4, 5],
[6, 7, 8],
]
]
)
print(f'inputs: {inputs}, shape: {inputs.shape}') # (1, 3, 3)
# 创建最大池化层
pool1 = nn.MaxPool2d(2, 1, 0)
outpus = pool1(inputs)
print(f"outpus: {outpus}, shape: {outpus.shape}") # (1, 2, 2)
# 创建平均池化层
pool2 = nn.AvgPool2d(2, 1, 0)
outpus = pool2(inputs)
print(f"outpus: {outpus}, shape: {outpus.shape}") # (1, 2, 2)多通道池化:
# 创建1个3通道3*3的二维矩阵.
inputs = torch.tensor(
[ # 3 通道C
[ # 通道1, HW 3,3
[0, 1, 2],
[3, 4, 5],
[6, 7, 8],
],
[ # 通道2, HW 3,3
[10, 20, 30],
[40, 50, 60],
[70, 80, 90],
],
[ # 通道3, HW 3,3
[11, 22, 33],
[44, 55, 66],
[77, 88, 99],
],
]
)
print(f'inputs: {inputs}, shape: {inputs.shape}') # (3, 3, 3)
# 创建最大池化层.
pool1 = nn.MaxPool2d(2, 1, 0)
outpus = pool1(inputs)
print(f"outpus: {outpus}, shape: {outpus.shape}") # (3, 2, 2)
# 创建平均池化层.
pool2 = nn.AvgPool2d(2, 1, 0)
outpus = pool2(inputs)
print(f"outpus: {outpus}, shape: {outpus.shape}") # (3, 2, 2)