
外观
Numpy
Numpy (Numerical Python) 是一个开源的 Python 科学计算库,用于快速处理任意维度的数组。
Numpy 支持常见的数组和矩阵操作。 对于同样的数值计算任务,使用 Numpy 比直接使用 Python 要简洁的多。
Numpy 使用 ndarray 对象来处理多维数组,该对象是一个快速而灵活的大数据容器。
Numpy 如何存储数据
Numpy 使用 ndarray 存储数据,类似 Python 原生的集合。
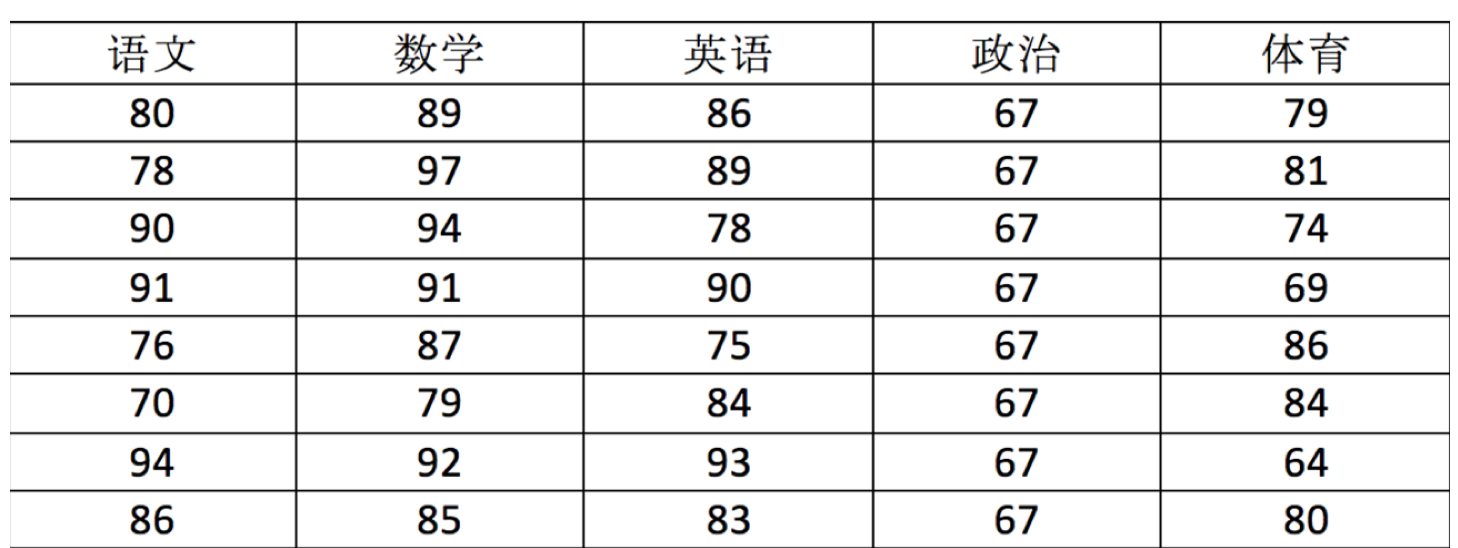
用 ndarray 进行存储:
demo.py
import numpy as np
score = np.array(
[[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]])
print(score)运行结果.txt
[[80 89 86 67 79]
[78 97 89 67 81]
[90 94 78 67 74]
[91 91 90 67 69]
[76 87 75 67 86]
[70 79 84 67 84]
[94 92 93 67 64]
[86 85 83 67 80]]ndarray 的属性
| 属性名字 | 属性解释 |
|---|---|
| ndarray.shape | 数组维度的元组 |
| ndarray.ndim | 数组维数 |
| ndarray.size | 数组中的元素数量 |
| ndarray.itemsize | 一个数组元素的长度 (字节) |
| ndarray.dtype | 数组元素的类型 |
| ndarray.nbytes | 数组总共的内存大小 |
# 接着前面的代码运行
print(f"score的形状为{score.shape}")
print(f"score的维度为{score.ndim}")
print(f"score的元素个数为{score.size}")
print(f"score的元素大小为{score.itemsize}")
print(f"score的内存大小为{score.nbytes}")
print(f"score的元素类型为{score.dtype}")ndarray 的元素类型
新版 Numpy
| 名称 | 描述 | 简写/类型字符 |
|---|---|---|
| 布尔类型 | 逻辑真/假 (True/False) | bool_/? |
| 有符号整数 | 整数,按位宽区分 | int8 (i1),int16 (i2),int32 (i4),int64 (i8) |
| 默认整数 | 平台默认大小整数 (类似 C 的 long) | int_ (l) |
| 整数 (C) | C 标准类型对应的整数 | intc |
| 索引整数 | 用于数组索引的整数 | intp |
| 无符号整数 | 非负整数,对应位宽 | uint8 (u1),uint16 (u2),uint32 (u4),uint64 (u8) |
| 默认无符号整数 | 平台无符号整数 | uint |
| 无符号整数 (C) | C 标准类型对应的无符号整数 | uintc |
| 无符号索引整数 | 用于索引的无符号整数 | uintp |
| 浮点数 | 实数,精度按位宽 | float16 (f2),float32 (f4),float64 (f8) |
| 长双精度浮点数 | 扩展精度 (平台相关) | longdouble |
| 复数数值 | 实部和虚部为浮点 | complex64 (c8),complex128 (c16) |
| 长复数 | 扩展精度复数 | clongdouble |
| 字符串类型 | 固定长度字节字符串 | bytes_ (S) |
| Unicode 字符串 | 固定长度 Unicode | str_ (U) |
| Python 对象 | 任意 Python 对象 | object_ (O) |
| 日期时间类型 | 带单位的日期时间 | datetime64 |
| 时间差类型 | 带单位的时间间隔 | timedelta64 |
| 原始/空类型 | 原始内存块/结构化用 | void (V) |
旧版 Numpy
| 名称 | 描述 | 简写 |
|---|---|---|
| np.bool | 用一个字节存储的布尔类型 (True或False) | 'b' |
| np.int8 | tinyint 一个字节大小,-128 至 127 | 'i' |
| np.int16 | smallint 整数,-32768 至 32767 | 'i2' |
| np.int32 | int 整数,-2^31 至 2^32 -1 | 'i4' |
| np.int64 | bigint 整数,-2^63 至 2^63 - 1 | 'i8' |
| np.uint8 | tinyint unsigned 无符号整数,0 至 255 | 'u' |
| np.uint16 | smallint unsigned 无符号整数,0 至 65535 | 'u2' |
| np.uint32 | 无符号整数,0 至 2^32 - 1 | 'u4' |
| np.uint64 | 无符号整数,0 至 2^64 - 1 | 'u8' |
| np.float16 | 半精度浮点数: 16 位,正负号 1 位,指数 5 位,精度 10 位 | 'f2' |
| np.float32 | float 单精度浮点数: 32 位,正负号 1 位,指数 8 位,精度 23 位 | 'f4' |
| np.float64 | double 双精度浮点数: 64 位,正负号 1 位,指数 11 位,精度 52 位 | 'f8' |
| np.complex64 | 复数,分别用两个 32 位浮点数表示实部和虚部 | 'c8' |
| np.complex128 | 复数,分别用两个 64 位浮点数表示实部和虚部 | 'c16' |
| np.object_ | python 对象 | 'O' |
| np.string_ | 字符串 | 'S' |
| np.unicode_ | unicode 类型 (字符串) | 'U' |
标粗的是常用类型。
np.string_只支持 ASCII 编码,不支持 Unicode,而np.unicode_支持 Unicode 字符。
np.string_更适合处理旧有的二进制数据,而np.unicode_更适合处理现代文本数据。
若不指定,整数默认 int64,小数默认 float64。
Numpy 模块生成数组
生成 0 和 1 的数组
np.ones(shape, dtype)、np.ones_like(a, dtype): 用于创建一个与数组 a 形状相同且所有元素都为 1 的数组的函数。np.zeros(shape, dtype)、np.zeros_like(a, dtype): 用于创建一个与数组 a 形状相同且所有元素都为 0 的数组的函数。
demo.py
ones = np.ones([4,8])
ones运行结果.txt
array([[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.]])从现有数组生成
np.array(object, dtype): 从现有的数组当中创建np.asarray(a, dtype): 相当于索引的形式,数组还是同一个
demo.py
import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6]])
a1 = np.array(a)
a2 = np.asarray(a)
print(a1)
print(a2)
print("-" * 20)
a[0][0] = 0
print(a1)
print(a2)运行结果.txt
[[1 2 3]
[4 5 6]]
[[1 2 3]
[4 5 6]]
--------------------
[[1 2 3]
[4 5 6]]
[[0 2 3]
[4 5 6]]生成固定范围的数组
np.linspace(start, stop, num, endpoint): 创建等差数列。np.arange(start,stop, step, dtype): 类似于内置range函数。np.logspace(start, stop, num): 创建等比数列。
demo.py
import numpy as np
a1 = np.linspace(1, 10, 2)
print(a1)
a2 = np.logspace(1, 4, 4, base=2)
print(a2)
a3 = np.arange(1, 10, 2)
print(a3)运行结果.txt
[ 1. 10.]
[ 2. 4. 8. 16.]
[1 3 5 7 9]生成随机数组
np.random.rand(d1, d2,..., dn): 生成一个形状为 (d1, d2,..., dn) 的数组,里面的数都是 0~1 之间的均匀分布随机数。np.random.randint(start, end, shape): 生成给定形状的数组,里面的数在 start, end 之间。np.random.randn(*shape): 生成符合标准正态分布的随机数。
demo.py
import numpy as np
# 生成一个 [0.0, 1.0) 之间的均匀分布的随机浮点数
rand_num = np.random.rand()
print("均匀分布的随机浮点数:", rand_num)
# 生成一个形状为(3, 2)的均匀分布的随机浮点数组
rand_array = np.random.rand(3, 2)
print("均匀分布的随机数组:\n", rand_array)
# 生成一个 [0, 100) 之间的均匀分布的随机整数数组
rand_num = np.random.randint(0, 100, size=(3, 2))
print("均匀分布的随机整数数组:\n", rand_num)运行结果.txt
均匀分布的随机浮点数: 0.9980889637278122
均匀分布的随机数组:
[[0.83539653 0.40084522]
[0.74816643 0.80070457]
[0.01276914 0.68486665]]
均匀分布的随机整数数组:
[[73 77]
[29 31]
[64 87]]索引和切片
ndarray 的索引和切片和 Python 原生的列表方式一样,也可以按行和列操作,语法是 [:, :],类似于 Python 原生列表的 [:][:]。
demo.py
import numpy as np
# 创建一个 3x4 的数组
arr = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]])
# 提取第 1 行和第 2 行的所有列
sub_array = arr[0:2, :]
print("第1行和第2行的所有列:\n", sub_array)
# 提取第 2 列和第 3 列的所有行
sub_array = arr[:, 1:3]
print("第2列和第3列的所有行:\n", sub_array)
# 提取第 1 行第 2 列到第 3 列的元素
sub_array = arr[0, 1:3]
print("第1行第2列到第3列的元素:", sub_array)运行结果.txt
第 1 行和第 2 行的所有列:
[[1 2 3 4]
[5 6 7 8]]
第 2 列和第 3 列的所有行:
[[ 2 3]
[ 6 7]
[10 11]]
第 1 行第 2 列到第 3 列的元素: [2 3]修改形状
ndarray.reshape(shape, order): 返回一个具有相同数据域,但 shape 不一样的视图. 行,列不进行互换。ndarray.resize(new_shape): 修改数组本身的形状 (需要保持元素个数前后相同),行,列不进行互换。ndarray.T: 转置。
它们一个是返回新数组,一个是在原数组的基本上更改。
demo.py
import numpy as np
array = np.arange(10)
array = array.reshape(2, 5)
print(array)
array.resize(5, 2)
print(array)
print(array.T)运行结果.txt
[[0 1 2 3 4]
[5 6 7 8 9]]
[[0 1]
[2 3]
[4 5]
[6 7]
[8 9]]
[[0 2 4 6 8]
[1 3 5 7 9]]类型修改
ndarray.astype(type): 返回修改了类型后的数组。type 可以传合法的字符串,如 'float32',也可以传 numpy 模块定义的类。ndarray.tobytes([order]): 构造包含数组中原始数据字节的 Python 字节。
为什么转二进制? 方便网络传输。
demo.py
import numpy as np
array = np.arange(10)
print(f"修改前的dtype: {array.dtype}")
array = array.astype(np.float32)
print(f"修改后的dtype: {array.dtype}")
print("-" * 20)
arr = np.array([[[1, 2, 3], [4, 5, 6]], [[12, 3, 34], [5, 6, 7]]])
print(f"数组: {arr}, 形状: {arr.shape}, 类型: {arr.dtype}")
bytes = arr.tobytes()
print(f"转成字节后的大小: {len(bytes)}")
arr = np.frombuffer(bytes, dtype=np.int64).reshape(2, 2, 3)
print(f"从字节转成数组: {arr}")运行结果.txt
修改前的 dtype: int64
修改后的 dtype: float32
--------------------
数组: [[[ 1 2 3]
[ 4 5 6]]
[[12 3 34]
[ 5 6 7]]], 形状: (2, 2, 3), 类型: int64
转成字节后的大小: 96
从字节转成数组: [[[ 1 2 3]
[ 4 5 6]]
[[12 3 34]
[ 5 6 7]]]转成字节前后,要保持数据类型和形状一致。
去重
np.unique(ndarray)
demo.py
import numpy as np
array = np.array([[1, 1, 2, 3], [4, 5, 5, 6]])
array = np.unique(array)
print(f"去重后的数组: {array}")运行结果.txt
去重后的数组: [1 2 3 4 5 6]运算
加减乘除
可直接使用 Python 内置的加减乘除,取余,乘方等运算符。
demo.py
import numpy as np
array1 = np.array([1, 2, 3, 4, 5, 6])
array2 = np.array([2, 3, 4, 5, 6, 7])
print(f"array1 + array2 = {array1 + array2}")
print(f"array1 * array2 = {array1 * array2}")
print(f"array1 ** 2 = {array1 ** 2}")
print(f"array1和array2的矩阵相乘 = {array1 @ array2}")运行结果.txt
array1 + array2 = [ 3 5 7 9 11 13]
array1 * array2 = [ 2 6 12 20 30 42]
array1 ** 2 = [ 1 4 9 16 25 36]
array1 和 array2 的矩阵相乘 = 112
array1 和 array2 的点积 = 112逻辑运算
可用比较运算符,如大于小于,直接比较一个数。可直接使用赋值运算符和方括号改变符合条件的值。
demo.py
import numpy as np
score = np.random.randint(40, 100, (3, 5))
print(f"随机生成的成绩: {score}")
print(f"大于等于60的成绩: {score[score >= 60]}")
print(f"每个成绩和60比较: {score >= 60}")
score[score >= 60] = 1
print(f"将大于等于60的成绩替换为1: {score}")运行结果.txt
随机生成的成绩: [[97 53 88 44 59]
[66 89 65 68 47]
[98 86 94 75 41]]
大于等于 60 的成绩: [97 88 66 89 65 68 98 86 94 75]
每个成绩和 60 比较: [[ True False True False False]
[ True True True True False]
[ True True True True False]]
将大于等于 60 的成绩替换为 1: [[ 1 53 1 44 59]
[ 1 1 1 1 47]
[ 1 1 1 1 41]]通用判断函数
np.all(): 如果所有元素都满足条件,返回 True,否则返回 False。np.any(): 当你需要检查数组中是否至少有一个元素满足条件时使用,如果有一个元素满足条件,返回 True,否则返回 False。
demo.py
import numpy as np
array = np.array([1, 2, 3, 4, 5, 6])
print(f"所有元素都大于5: {np.all(array >= 5)}")
print(f"所有元素都小于6: {np.all(array <= 6)}")
print(f"至少有一个元素大于5: {np.any(array > 5)}")运行结果.txt
所有元素都大于 5: False
所有元素都小于 6: True
至少有一个元素大于 5: True
数组的余弦值: [ 0.54030231 -0.41614684 -0.9899925 -0.65364362 0.28366219 0.96017029]三元运算符
np.where(expression, a, b): 类似 Python 中的 if...else 结构。
# 判断前四名学生, 前四门课程中, 成绩中大于 60 的置为 1, 否则为 0
temp = score[:4, :4]
np.where(temp > 60, 1, 0)复合逻辑需要结合 np.logical_and 和 np.logical_or 使用。
# 判断前四名学生, 前四门课程中, 成绩中大于 60 且小于 90 的换为 1, 否则为 0
np.where(np.logical_and(temp > 60, temp < 90), 1, 0)
# 判断前四名学生, 前四门课程中, 成绩中大于 90 或小于 60 的换为 1, 否则为 0
np.where(np.logical_or(temp > 90, temp < 60), 1, 0)数组的广播机制
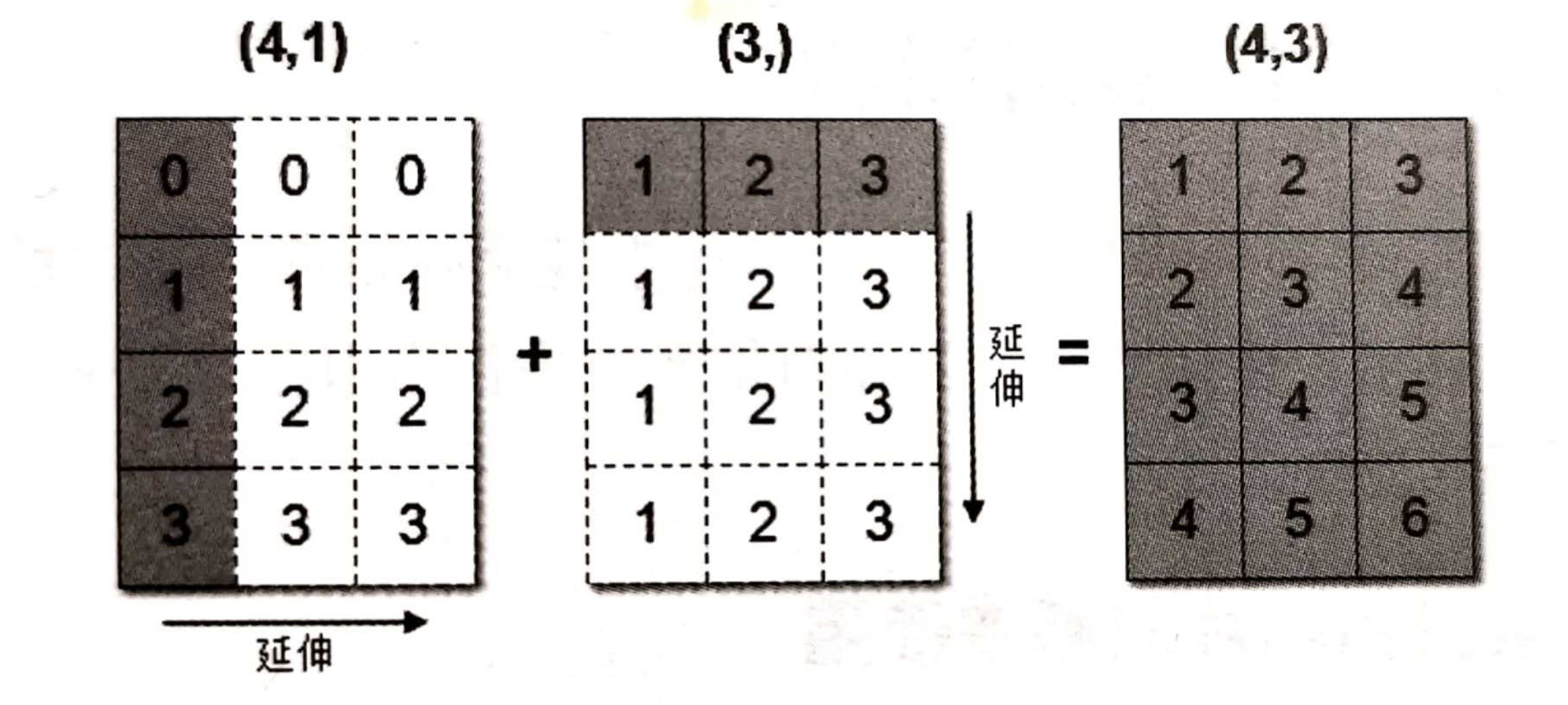
数组在进行矢量化运算时,要求数组的形状是相等的. 当形状不相等的数组执行算术运算的时候,就会出现广播机制,该机制会对数组进行扩展,使数组的 shape 属性值一样,这样,就可以进行矢量化运算了。
arr1 = np.array([[0],[1],[2],[3]]) # 4 x 1
arr1.shape
# (4, 1)
arr2 = np.array([1,2,3]) # 1 x 3
arr2.shape
# (3,)
arr1+arr2
# 结果是:
array([[1, 2, 3],
[2, 3, 4],
[3, 4, 5],
[4, 5, 6]])上述代码中,数组 arr1 是 4 行 1 列,arr2 是 1 行 3 列。这两个数组要进行相加,按照广播机制会对数组 arr1 和 arr2 都进行扩展,使得数组 arr1 和 arr2 都变成 4 行 3 列。
统计运算
min(a, axis): 返回数组中的最小值。max(a, axis): 返回数组中的最大值。median(a, axis): 返回数组的中位数。mean(a, axis, dtype): 返回数组的平均数。std(a, axis, dtype): 返回数组的标准差。var(a, axis, dtype): 返回数组的方差。argmax(a, axis): 返回元素最大值的索引。argmin(a, axis): 返回元素最小值的索引。
demo.py
import numpy as np
array = np.array([[1, 2, 3], [4, 5, 6]])
print(f"数组的最大值: {np.max(array)}")
print(f"数组的最小值: {np.min(array)}")
print(f"数组的中位数: {np.median(array)}")
print(f"数组的平均值: {np.mean(array)}")
print(f"数组的标准差: {np.std(array)}")
print(f"数组的方差: {np.var(array)}")
print(f"最小元素的下标: {np.argmin(array)}")
print(f"最大元素的下标: {np.argmax(array)}")运行结果.txt
数组的最大值: 6
数组的最小值: 1
数组的中位数: 3.5
数组的平均值: 3.5
数组的标准差: 1.707825127659933
数组的方差: 2.9166666666666665
最小元素的下标: 0
最大元素的下标: 5以上方法,ndarray 对象也有,numpy 模块也会提供。如
numpy.min(array)相当于array.min()。