
外观
集成学习
集成学习是机器学习中的一种思想,它通过多个模型的组合形成一个精度更高的模型,参与组合的模型成为弱学习器(基学习器)。训练时,使用训练集依次训练出这些弱学习器,对未知的样本进行预测时,使用这些弱学习器联合进行预测。
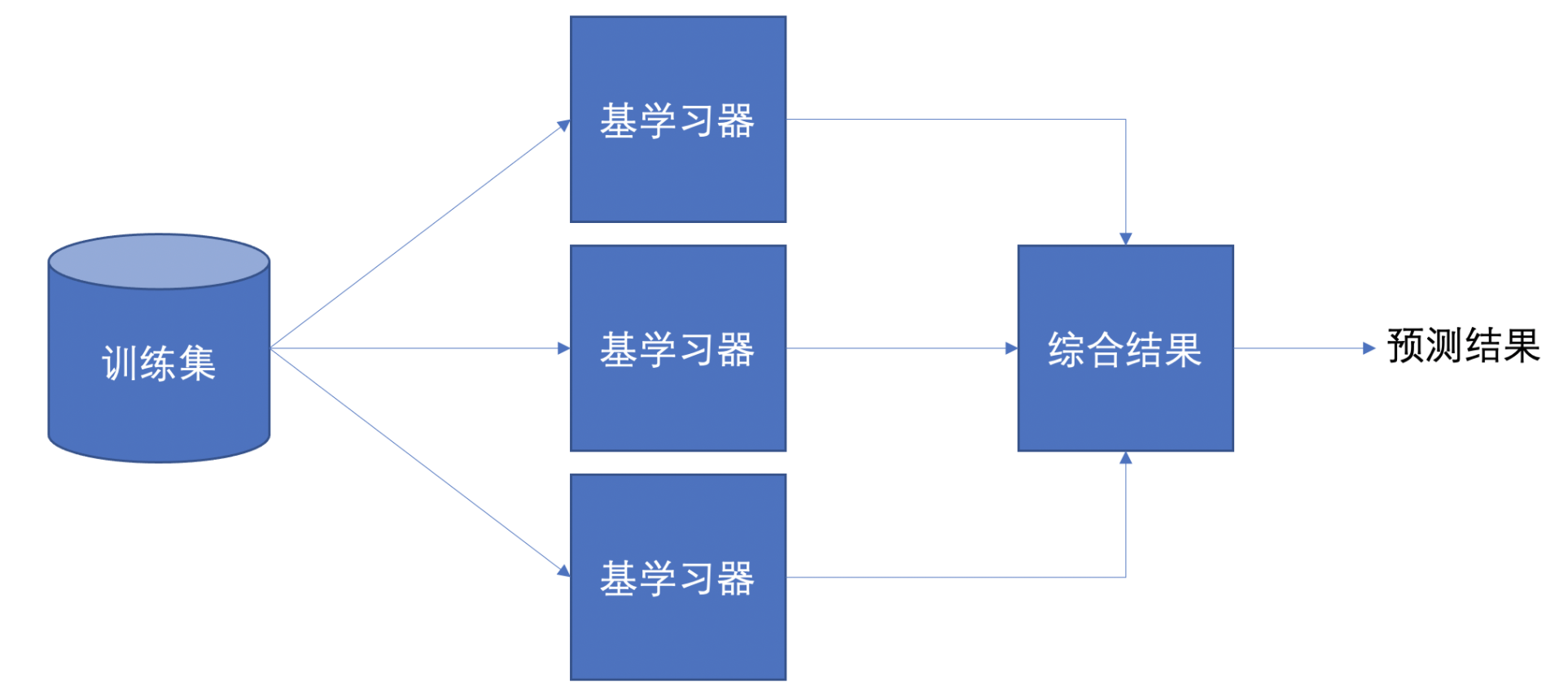
传统机器学习算法 (例如:决策树,逻辑回归等) 的目标都是寻找一个最优分类器尽可能的将训练数据分开。集成学习 (Ensemble Learning) 算法的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。
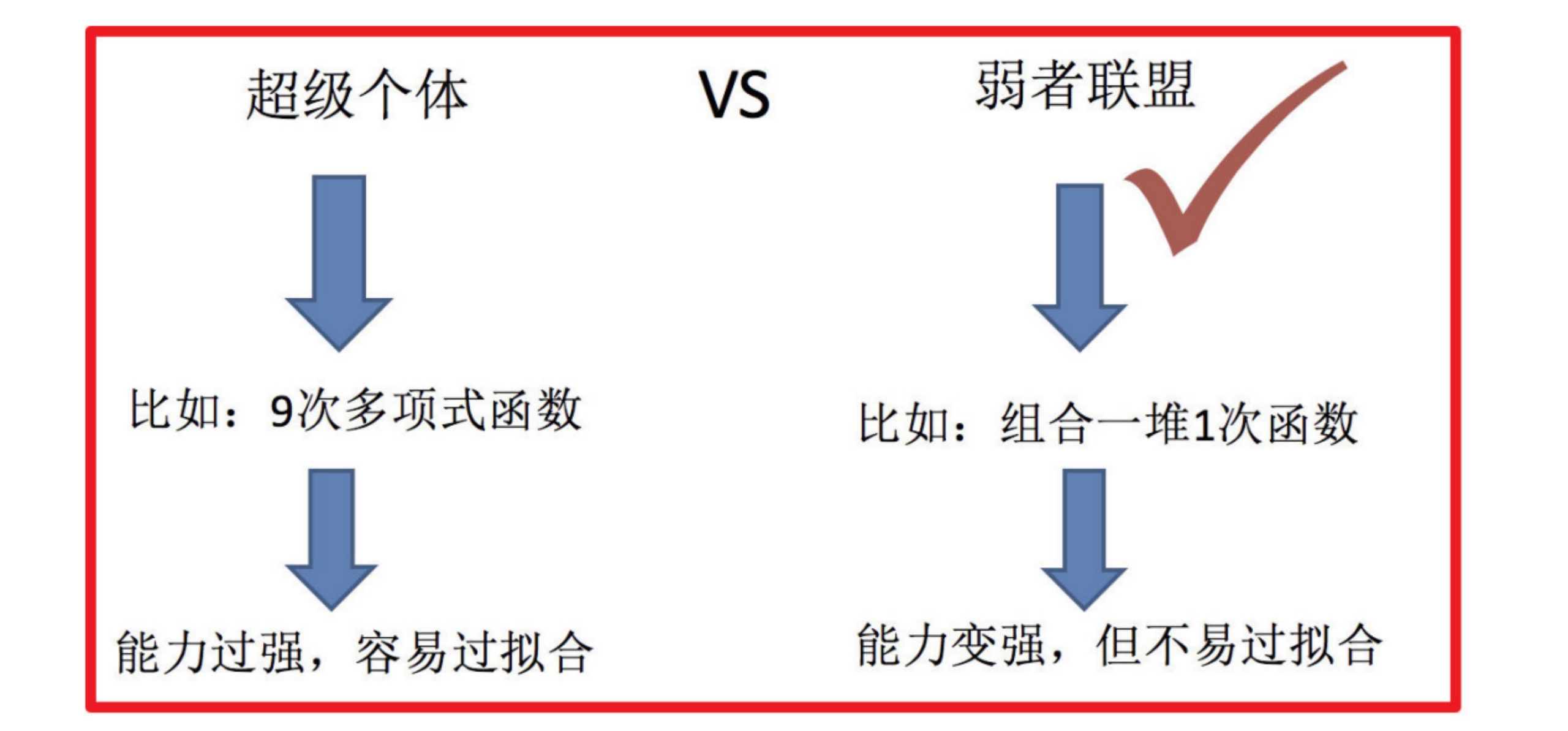
集成学习通过建立几个模型来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测。
集成学习分类
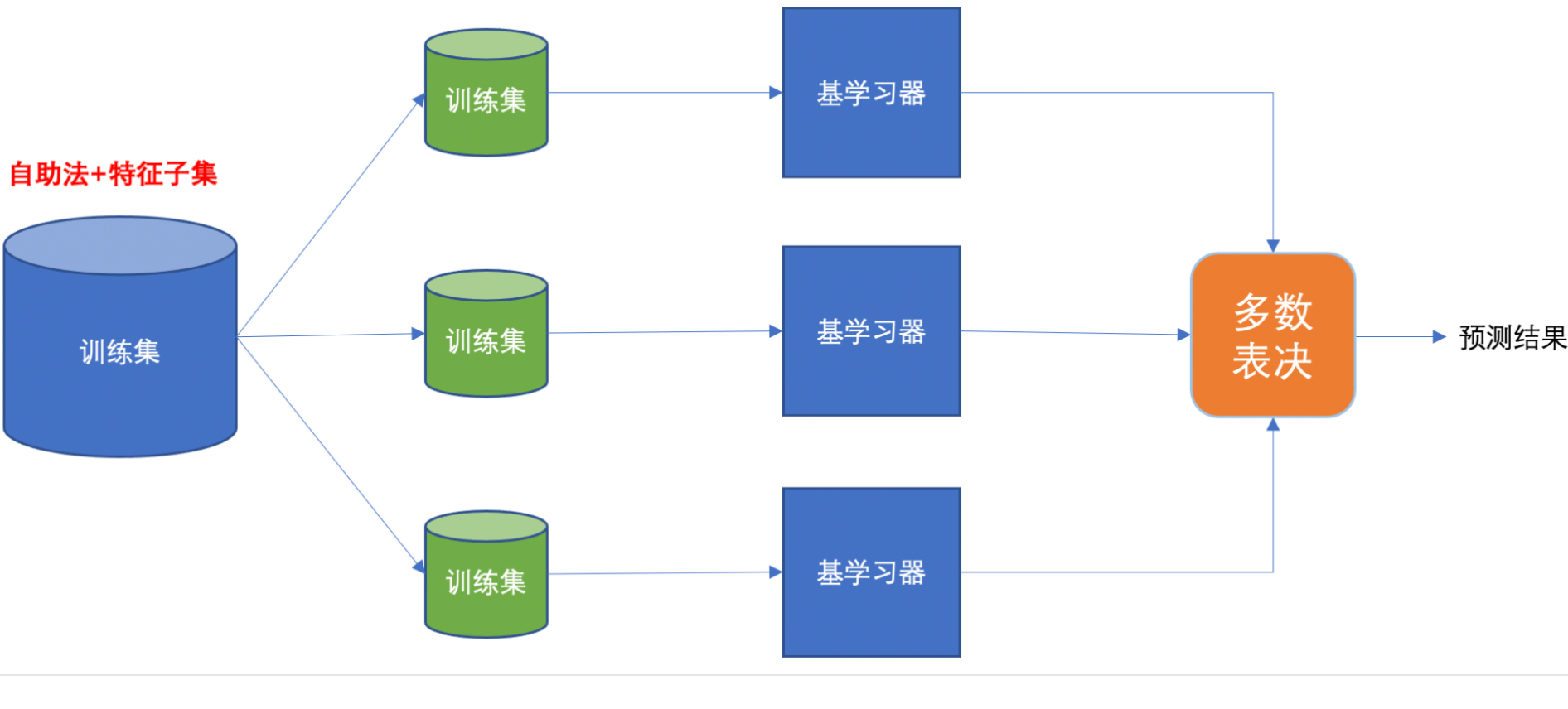
集成学习算法一般分为:bagging 和 boosting。
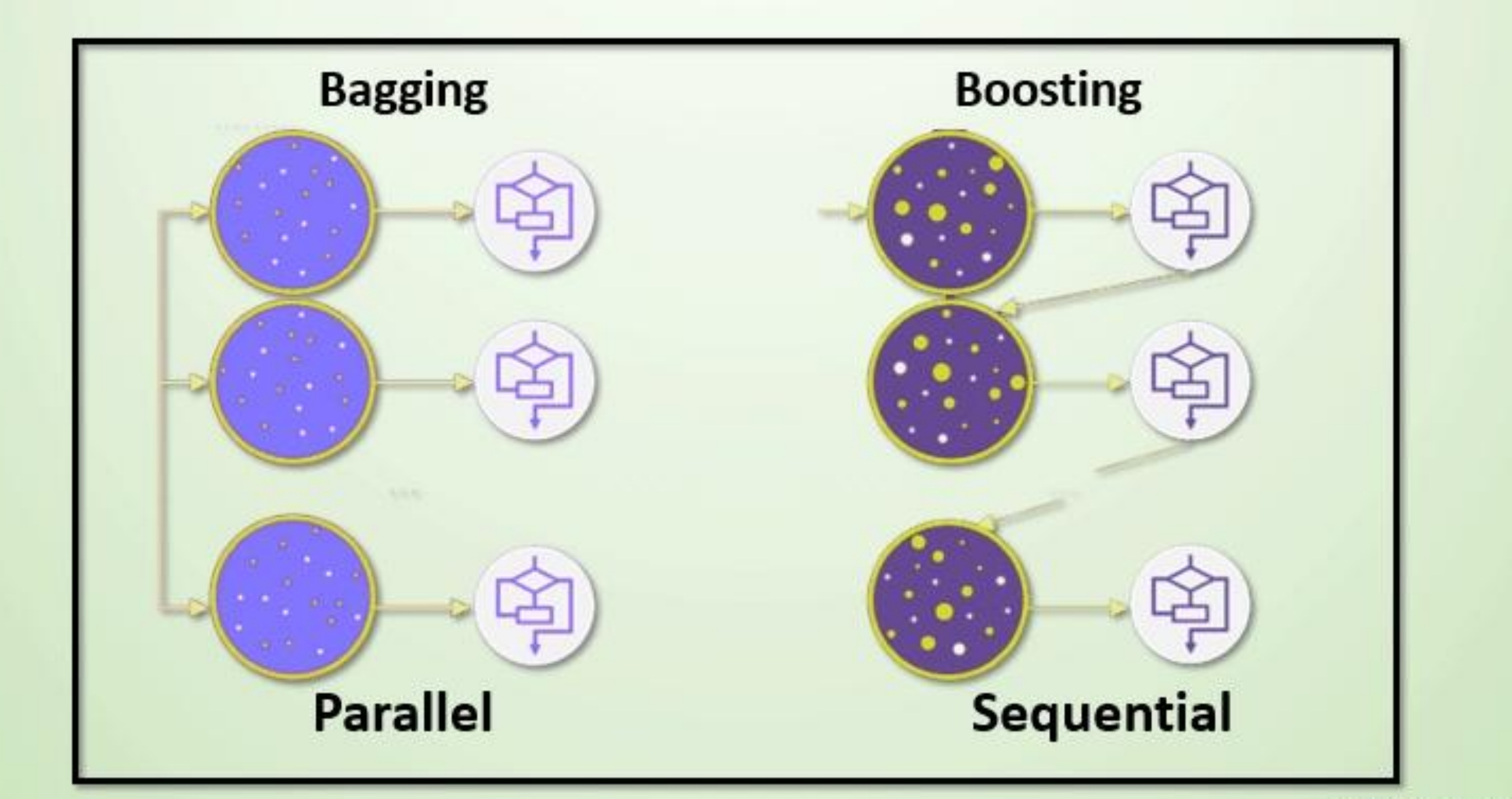
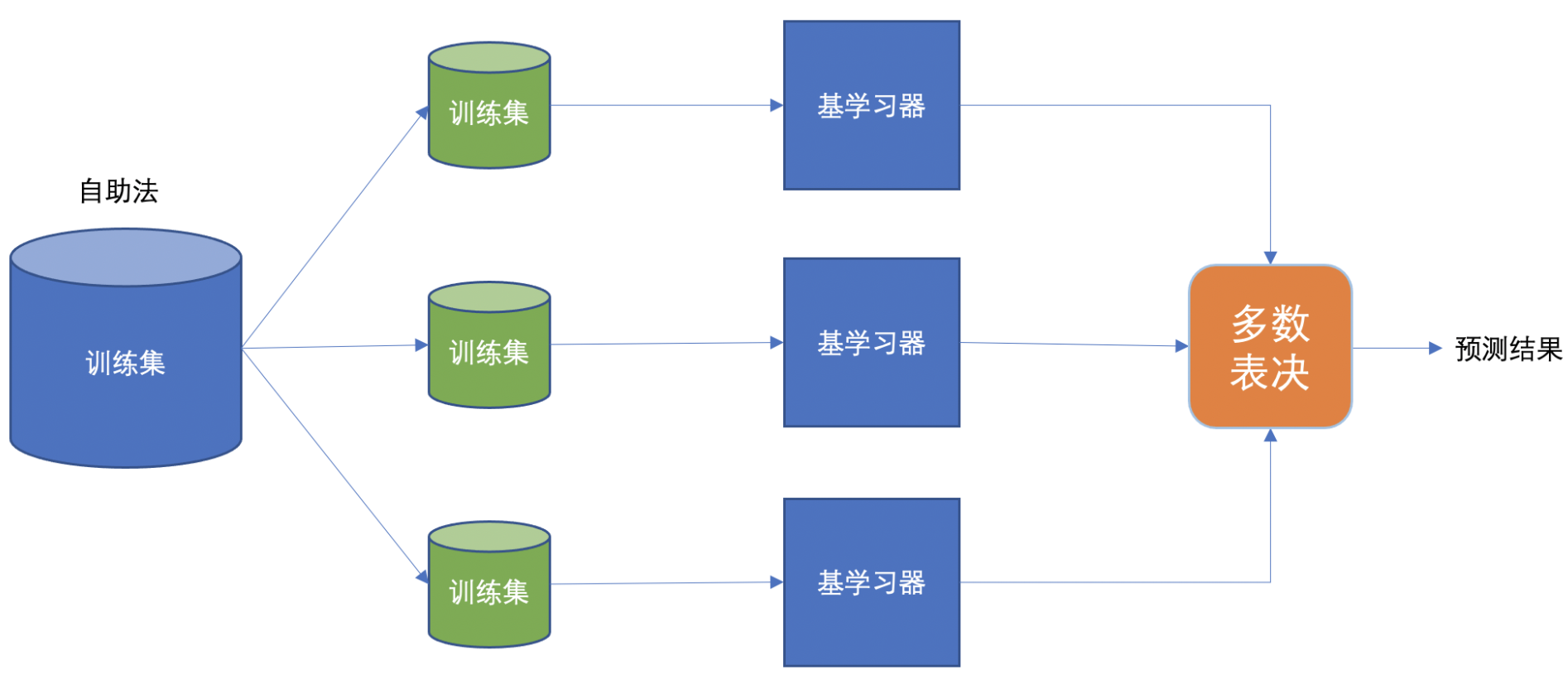
Bagging
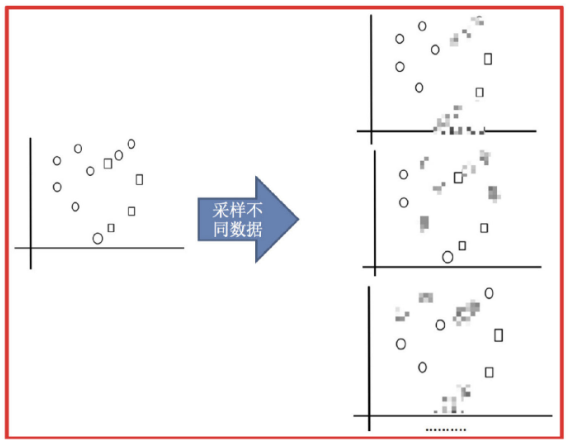
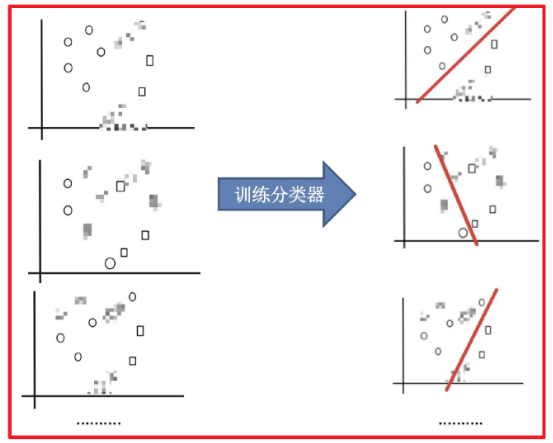
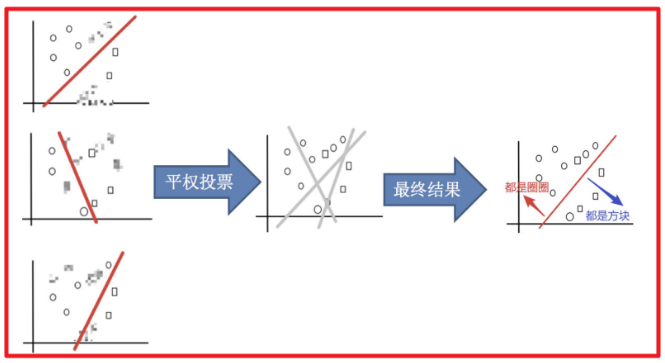
Bagging 框架通过有放回的抽样产生不同的训练集,从而训练具有差异性的弱学习器,然后通过平权投票、多数表决的方式决定预测结果。
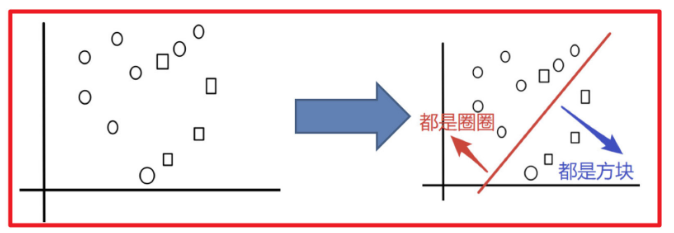
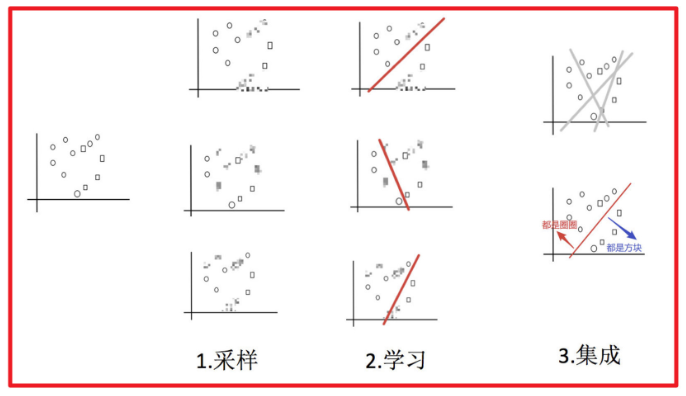
例子:
目标:把下面的圈和方块进行分类
采样不同数据集
img 训练分类器
img 平权投票,获取最终结果
img 主要实现过程小结
img
boosting
Boosting 体现了提升思想,每一个训练器重点关注前一个训练器不足的地方进行训练,通过加权投票的方式,得出预测结果。
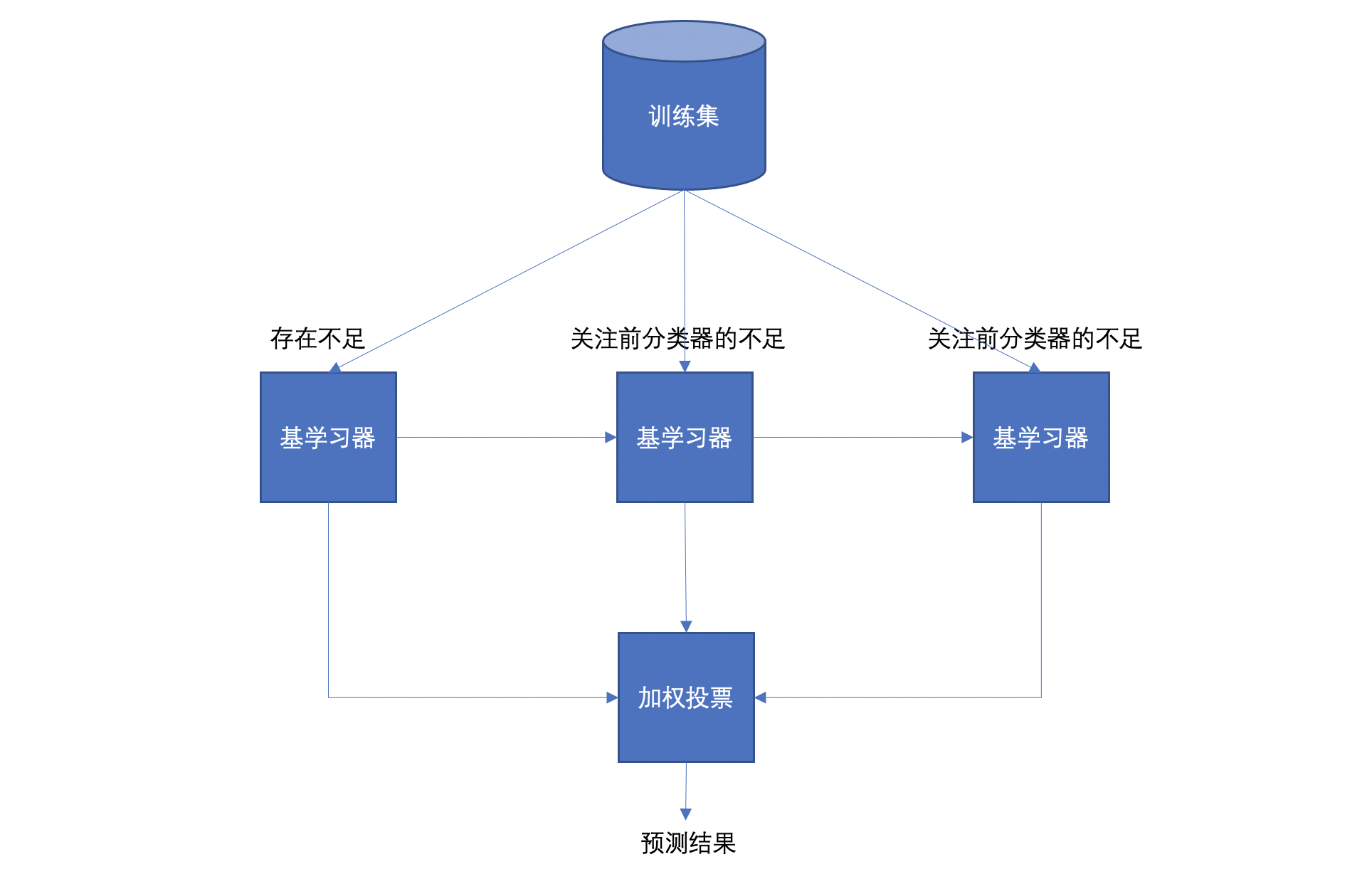
Boosting 是一组可将弱学习器升为强学习器算法。这类算法的工作机制类似:
- 先从初始训练集训练出一个基学习器
- 在根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续得到最大的关注。
- 然后基于调整后的样本分布来训练下一个基学习器;
- 如此重复进行,直至基学习器数目达到实现指定的值T为止。
- 再将这T个基学习器进行加权结合得到集成学习器。
简而言之:每新加入一个弱学习器,整体能力就会得到提升
对比
| 集成学习 | Bagging | Boosting |
|---|---|---|
| 数据 | 有放回采样 | 全部数据集,重点关注前一个弱学习器不足 |
| 投票 | 平权投票 | 加权投票 |
| 学习顺序 | 并行,每个学习器没有依赖关系 | 串行,学习有先后顺序 |
随机森林
思想
随机森林是基于 Bagging 思想实现的一种集成学习算法,它采用决策树模型作为每一个基学习器。其构造过程:
训练
- 有放回的产生训练样本
- 随机挑选 n 个特征(n 小于总特征数量)
预测:平权投票,多数表决输出预测结果
构建随机森林的步骤:
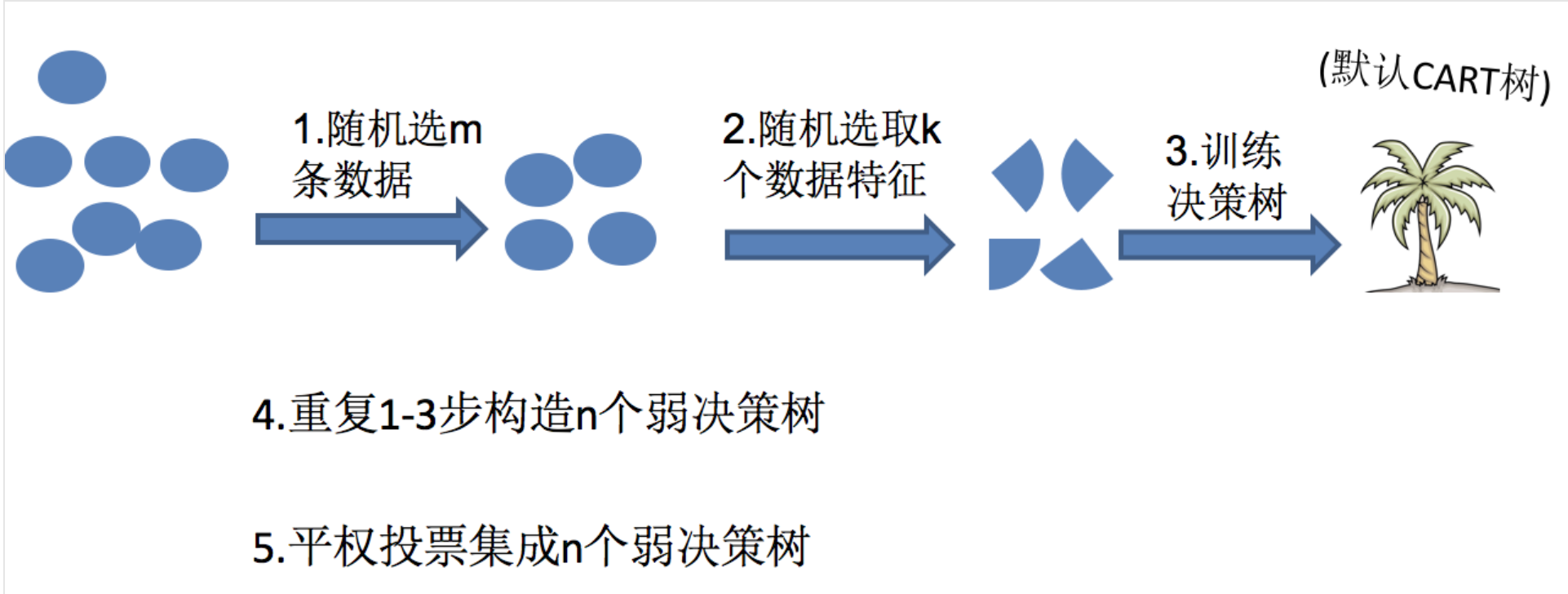
- 首先,对样本数据进行有放回的抽样,得到多个样本集。具体来讲就是每次从原来的N个训练样本中有放回地随机抽取m个样本(包括可能重复样本)。
- 然后,从候选的特征中随机抽取k个特征,作为当前节点下决策的备选特征,从这些特征中选择最好地划分训练样本的特征。用每个样本集作为训练样本构造决策树。单个决策树在产生样本集和确定特征后,使用CART算法计算,不剪枝。
- 最后,得到所需数目的决策树后,随机森林方法对这些树的输出进行投票,以得票最多的类作为随机森林的决策。
说明:
- 随机森林的方法即对训练样本进行了采样,又对特征进行了采样,充分保证了所构建的每个树之间的独立性,使得投票结果更准确。
- 随机森林的随机性体现在每棵树的训练样本是随机的,树中每个节点的分裂属性也是随机选择的。有了这2个随机因素,即使每棵决策树没有进行剪枝,随机森林也不会产生过拟合的现象。
随机森林中有两个可控制参数:
- 森林中树的数量(一般选取值较大)。
- 抽取的属性值m的大小。
随机森林 API
sklearn.ensemble.RandomForestClassifier(
n_estimators: Int = 100,
criterion: Literal["gini", "entropy", "log_loss"] = "gini",
max_depth: None | Int = None,
min_samples_split: float = 2,
min_samples_leaf: float = 1,
max_features: float | Literal["sqrt", "log2"] = "sqrt",
min_impurity_decrease: Float = 0.0,
bootstrap: bool = True,
random_state: RandomState | None | Int = None,
max_samples: float | None = None,
) -> None: ...n_estimators: 决策树数量criterion: 决策树的类型max_depth: 指定树的最大深度,None表示树会尽可能地生长max_features: 决策树构建时使用的最大特征数量:- "auto" -> max_features=sqrt(n_features)
- "sqrt" -> max_features=sqrt(n_features)(和"auto"一样)
- "log2" -> max_features=log2(n_features)
- None -> then max_features=n_features
bootstrap: 是否采用有放回抽样,如果为 False 将会使用全部训练样本,(default = True)min_samples_split: 结点分裂所需最小样本数,(default = 2)- 如果节点样本数少于min_samples_split,则不会再进行划分
- 如果样本量不大,不需要设置这个值
- 如果样本量数量级非常大,则推荐增大这个值
min_samples_leaf: 叶子节点的最小样本数,(default = 1)- 如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝
- 较小的叶子结点样本数量使模型更容易捕捉训练数据中的噪声
min_impurity_decrease: 节点划分最小不纯度- 如果某节点的不纯度(基尼系数,均方差)小于这个阈值,则该节点不再生成子节点,并变为叶子节点
通过 sklearn API 预测泰坦尼克号生存预测:
demo.py
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
titanic = pd.read_csv("./data/train.csv")
titanic.info()
X = titanic[["Pclass", "Age", "Sex"]]
y = titanic["Survived"]
X["Age"] = X["Age"].fillna(X["Age"].mean())
X = pd.get_dummies(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=22)
# 使用单一的决策树进行模型的训练及预测分析
dtc = DecisionTreeClassifier()
dtc.fit(X_train, y_train)
dtc_y_pred = dtc.predict(X_test)
dtc.score(X_test, y_test)
# 随机森林进行模型的训练和预测分析
rfc = RandomForestClassifier(max_depth=6, random_state=9)
rfc.fit(X_train, y_train)
rfc_y_pred = rfc.predict(X_test)
rfc.score(X_test, y_test)
# 性能评估
print("dtc_report:", classification_report(dtc_y_pred, y_test))
print("rfc_report:", classification_report(rfc_y_pred, y_test))运行结果.txt
<class 'pandas.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null str
4 Sex 891 non-null str
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null str
9 Fare 891 non-null float64
10 Cabin 204 non-null str
11 Embarked 889 non-null str
dtypes: float64(2), int64(5), str(5)
memory usage: 83.7 KB
dtc_report: precision recall f1-score support
0 0.86 0.79 0.82 146
1 0.66 0.77 0.71 77
accuracy 0.78 223
macro avg 0.76 0.78 0.77 223
weighted avg 0.79 0.78 0.78 223
rfc_report: precision recall f1-score support
0 0.83 0.79 0.81 140
1 0.67 0.72 0.69 83
accuracy 0.76 223
macro avg 0.75 0.75 0.75 223
weighted avg 0.77 0.76 0.76 223可以使用网格搜索寻找到适合随机森林的超参数:
from sklearn.model_selection import GridSearchCV
rf = RandomForestClassifier()
param = {"n_estimators": [80, 100, 200], "max_depth": [2, 4, 6, 8, 10, 12], "random_state": [9]}
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(X_train, y_train)
print("随机森林预测的准确率为:", gc.score(X_test, y_test))Adaboost
Adaptive Boosting(自适应提升)基于 Boosting 思想实现的一种集成学习算法核心思想是通过逐步提高那些被前一步分类错误的样本的权重来训练一个强分类器。弱分类器的性能比随机猜测强就行,即可构造出一个非常准确的强分类器。其特点是:训练时,样本具有权重,并且在训练过程中动态调整。被分错的样本的样本会加大权重,算法更加关注难分的样本。
Adaboost自适应在于:“关注”被错分的样本,“器重”性能好的弱分类器:(观察下图)
- 不同的训练集 → 调整样本权重
- “关注” → 增加错分样本权重
- “器重” → 好的分类器权重大
- 样本权重间接影响分类器权重
主要过程演示如下:
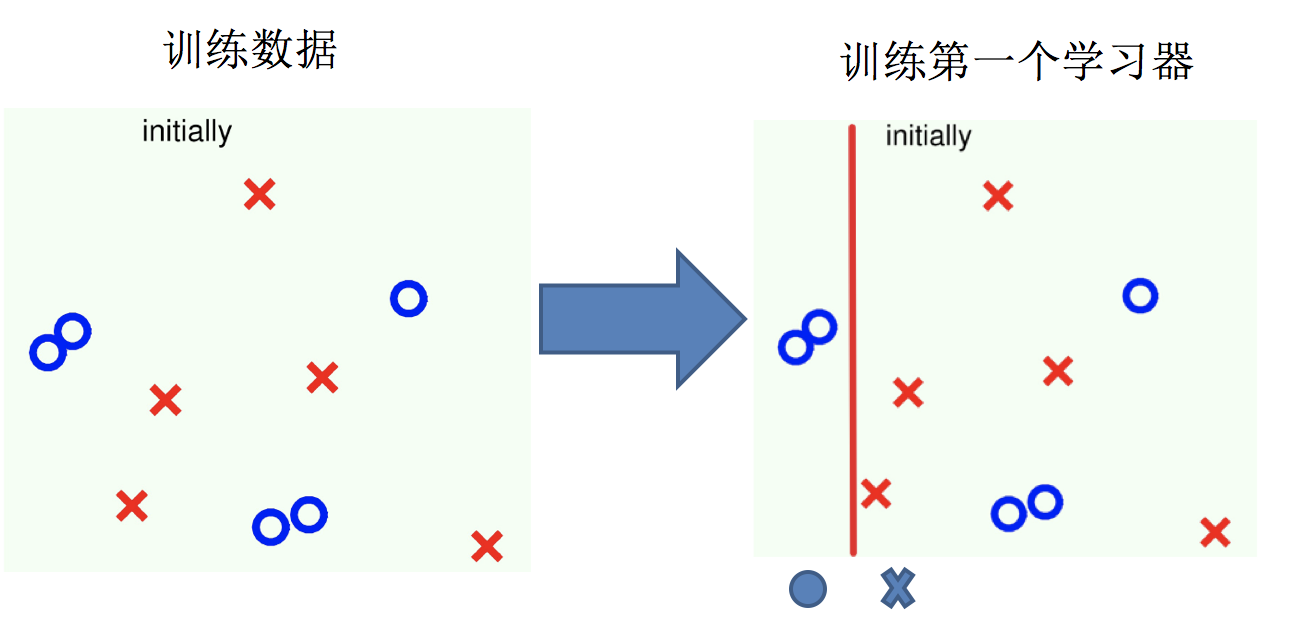
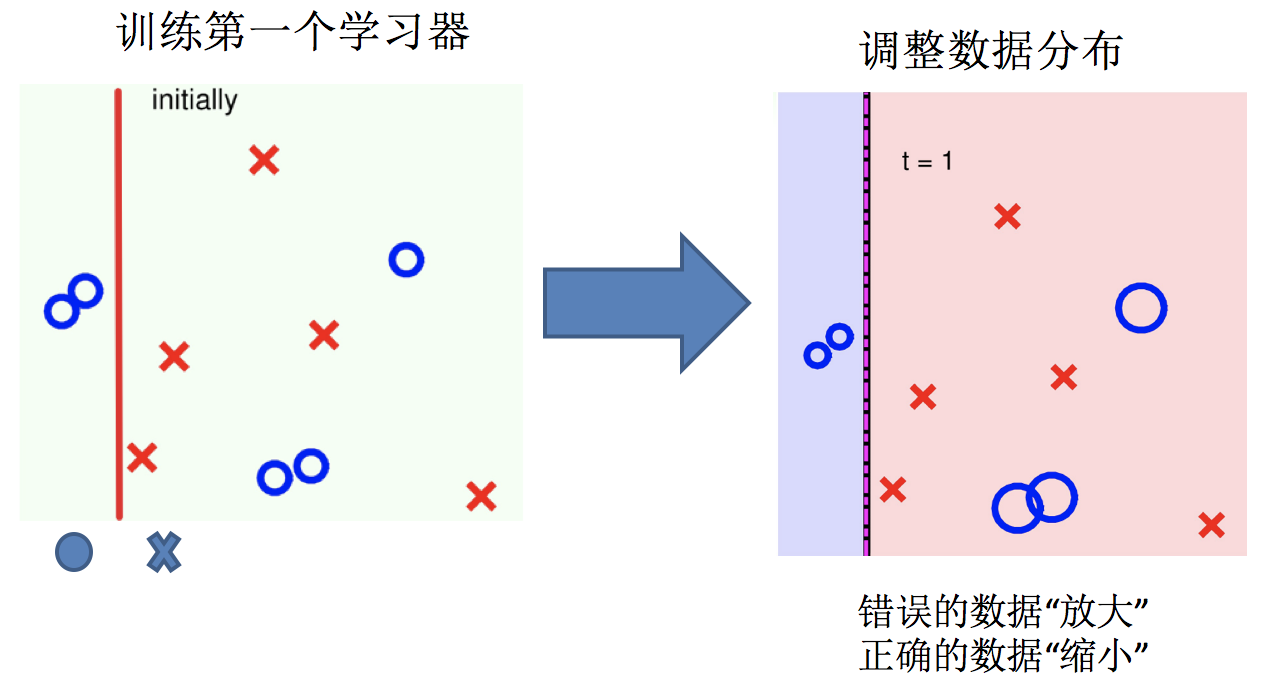
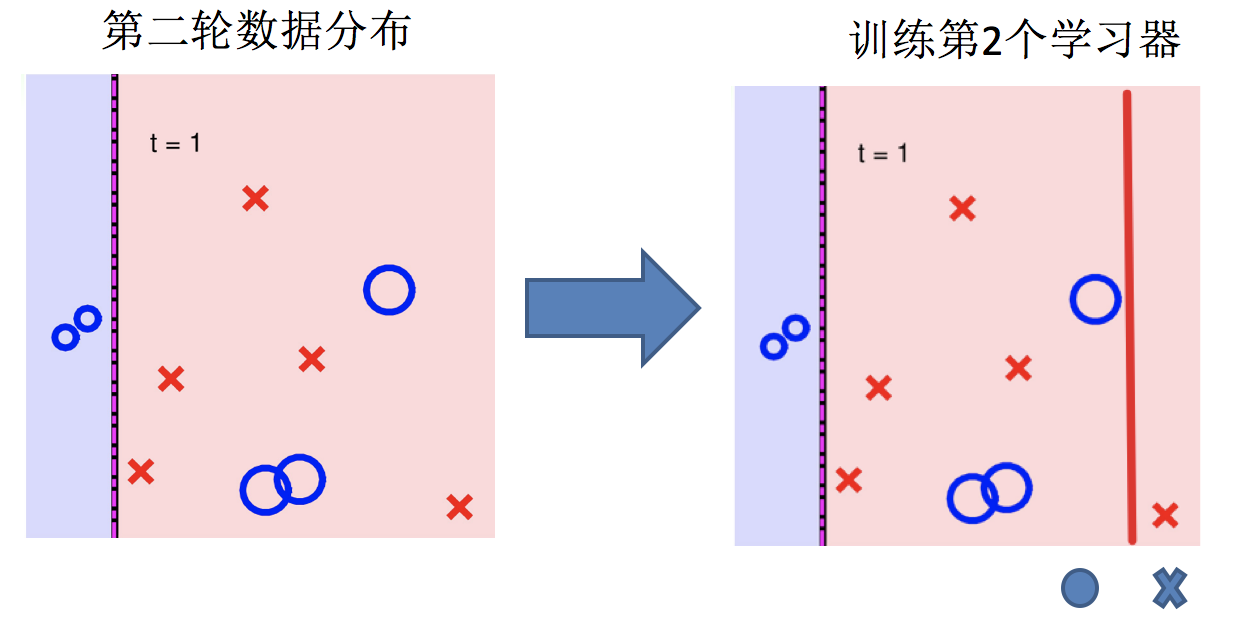
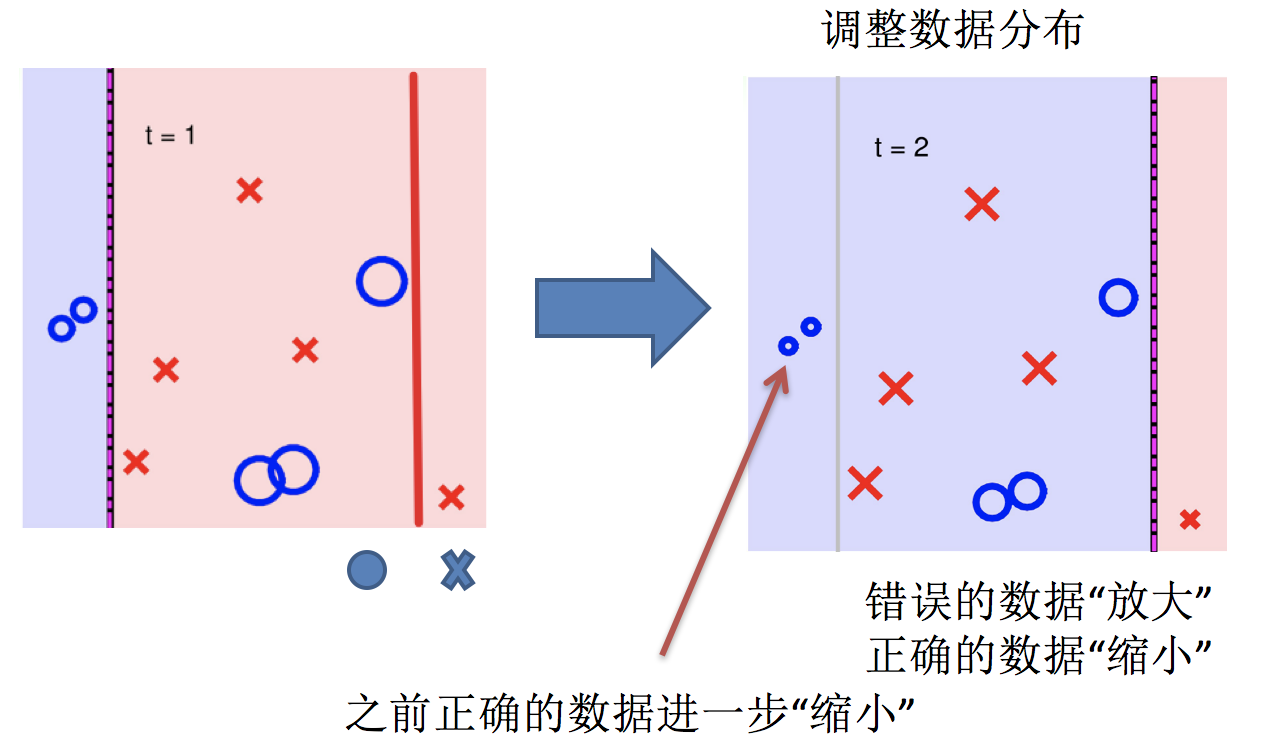
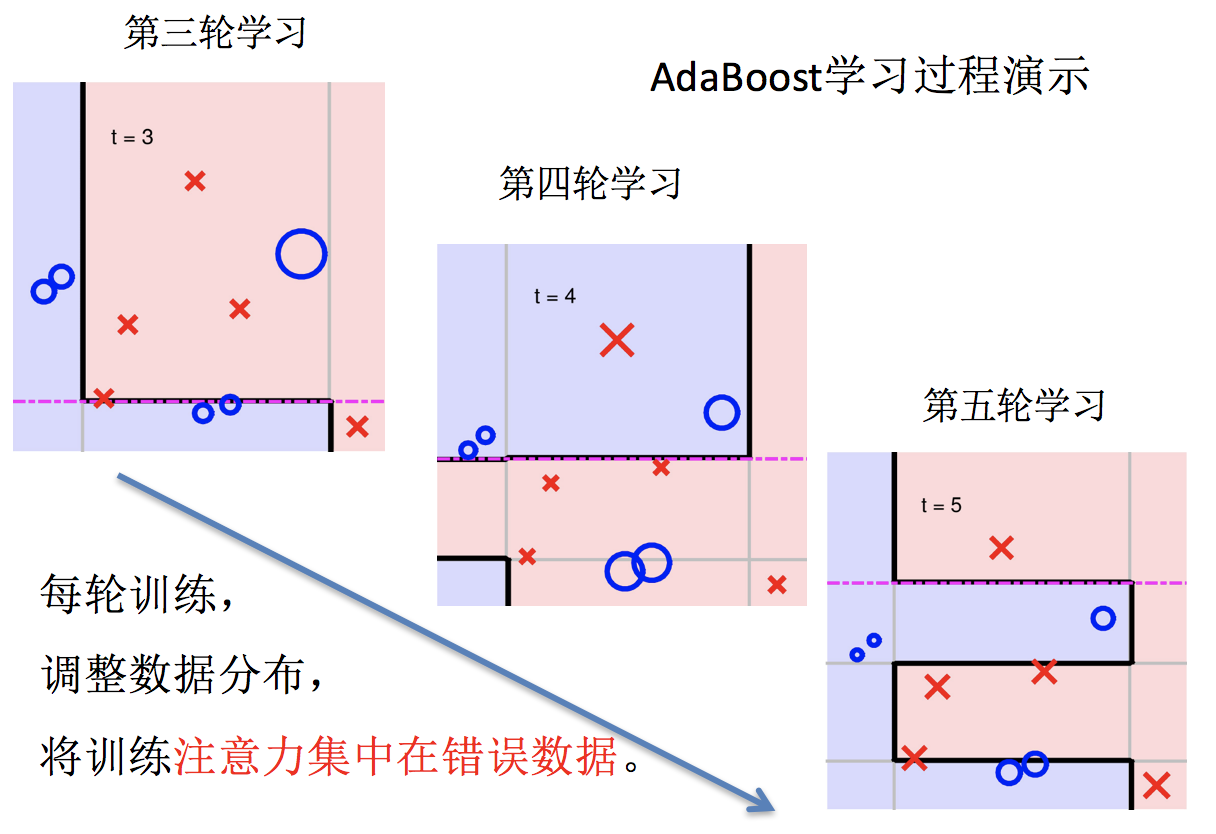
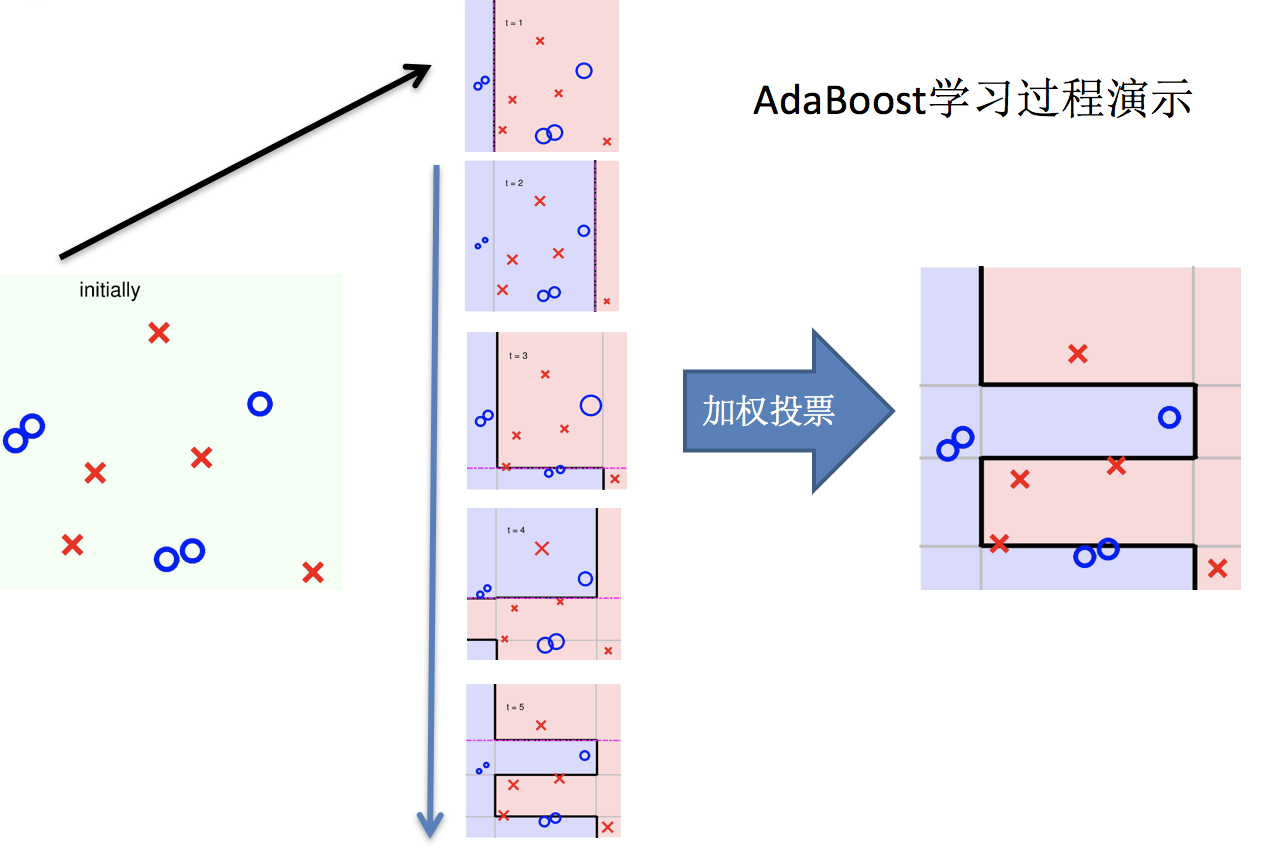
AdaBoost算法的两个核心步骤:
权值调整:AdaBoost算法提高那些被前一轮基分类器错误分类样本的权值,而降低那些被正确分类样本的权值。从而使得那些没有得到正确分类的样本,由于权值的加大而受到后一轮基分类器的更大关注。
基分类器组合:AdaBoost采用加权多数表决的方法。
- 分类误差率较小的弱分类器的权值大,在表决中起较大作用。
- 分类误差率较大的弱分类器的权值小,在表决中起较小作用。
初始化训练数据权重相等,训练第 1 个学习器
如果有 100 个样本,则每个样本的初始化权重为:1/100 根据预测结果找一个错误率最小的分裂点,计算、更新:样本权重、模型权重
根据新权重的样本集 训练第 2 个学习器
根据预测结果找一个错误率最小的分裂点计算、更新:样本权重、模型权重
迭代训练在前一个学习器的基础上,根据新的样本权重训练当前学习器
直到训练出 m 个弱学习器
AdaBoost 模型公式,表示 m 个弱学习器集成预测公式:
- 为模型的权重
- 为弱学习器数量
- 表示弱学习器
- 输出结果大于 0 则归为正类,小于 0 则归为负类。
AdaBoost 权重更新公式:
表示第 t 个弱学习器的错误率。
AdaBoost 样本权重更新公式:
- 为归一化值(所有样本权重的总和)
- 为样本权重
- 为模型权重
AdaBoost 构建过程
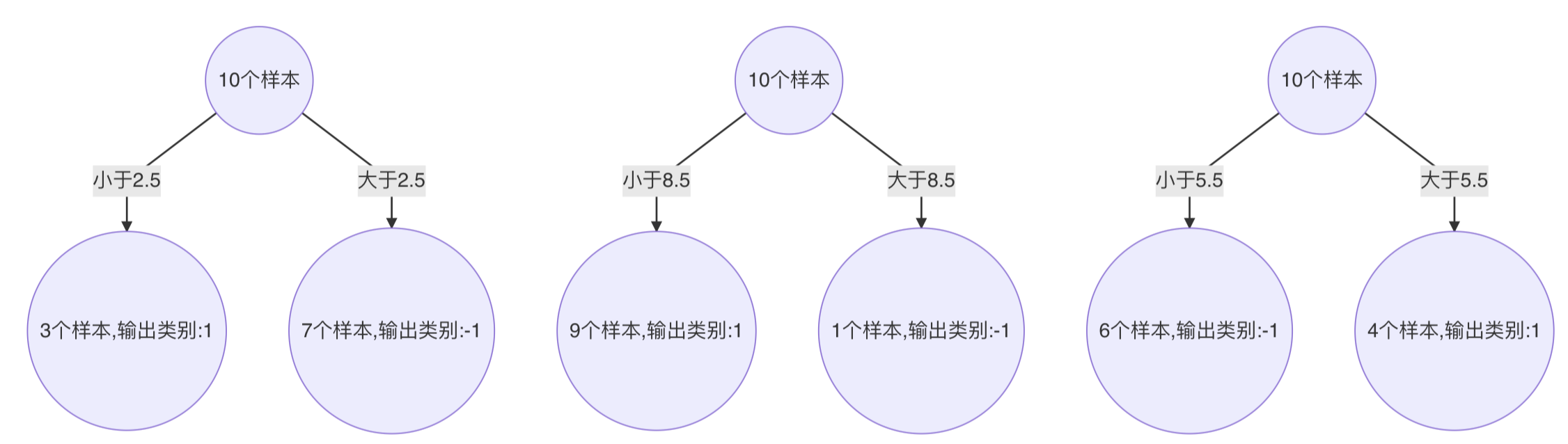
下面为训练数数据,假设弱分类器由 x 产生,其阈值 v 使该分类器在训练数据集上的分类误差率最低,试用 Adaboost 算法学习一个强分类器。

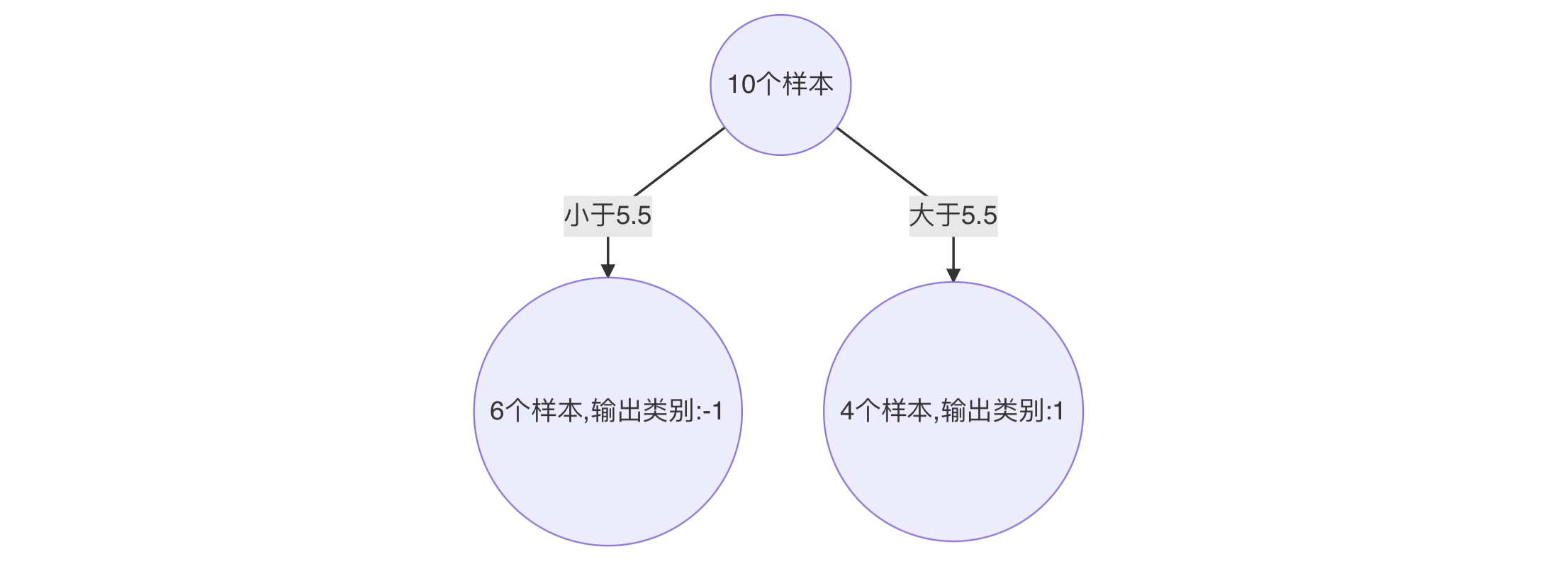
- 构建第一个弱学习器
- 初始化工作:初始化 10 个样本的权重,每个样本的权重为:0.1
- 构建第一个基学习器:
- 寻找最优分裂点
- 对特征值 x 进行排序,确定分裂点为:0.5、1.5、2.5、3.5、4.5、5.5、6.5、7.5、8.5
- 当以 0.5 为分裂点时,有 5 个样本分类错误
- 当以 1.5 为分裂点时,有 4 个样本分类错误
- 当以 2.5 为分裂点时,有 3 个样本分类错误
- 当以 3.5 为分裂点时,有 4 个样本分类错误
- 当以 4.5 为分裂点时,有 5 个样本分类错误
- 当以 5.5 为分裂点时,有 4 个样本分类错误
- 当以 6.5 为分裂点时,有 5 个样本分类错误
- 当以 7.5 为分裂点时,有 4 个样本分类错误
- 当以 8.5 为分裂点时,有 3 个样本分类错误
- 最终,选择以 2.5 作为分裂点,计算得出基学习器错误率为:3/10=0.3
- 计算模型权重:
- 更新样本权重:
- 分类正确样本为:1、2、3、4、5、6、10 共 7 个,其计算公式为:,则正确样本权重变化系数为:
- 分类错误样本为:7、8、9 共 3 个,其计算公式为:,则错误样本权重变化系数为:
- 样本 1、2、3、4、5、6、10 权重值为:
- 样本 7、8、9 的样本权重值为:
- 归一化 值为:
- 样本 1、2、3、4、5、6、10 最终权重值为:
- 样本 7、8、9 的样本权重值为:
- 此时得到:
- 寻找最优分裂点

- 构建第二个弱学习器
寻找最优分裂点:
对特征值 x 进行排序,确定分裂点为:0.5、1.5、2.5、3.5、4.5、5.5、6.5、7.5、8.5
当以 0.5 为分裂点时,有 5 个样本分类错误,错误率为:0.07143 * 5 = 0.35715
当以 1.5 为分裂点时,有 4 个样本分类错误,错误率为:0.07143 * 1 + 0.16667 * 3 = 0.57144
当以 2.5 为分裂点时,有 3 个样本分类错误,错误率为:0.16667 * 3 = 0.57144
。。。 。。。
当以 8.5 为分裂点时,有 3 个样本分类错误,错误率为:0.07143 * 3 = 0.21429
最终,选择以 8.5 作为分裂点,计算得出基学习器错误率为:0.21429
计算模型权重:
1/2 * np.log((1-0.21429)/0.21429)=0.64963分类正确的样本:1、2、3、7、8、9、10,其权重调整系数为:0.5222
分类错误的样本:4、5、6,其权重调整系数为:1.9148
分类正确样本权重值:
- 样本 0、1、2、、9 为:0.0373
- 样本 6、7、8 为:0.087
分类错误样本权重值:0.1368
归一化 Zt 值为:
0.0373 * 4 + 0.087 * 3 + 0.1368 * 3 = 0.8206最终权重:
- 样本 0、1、2、9 为 :0.0455
- 样本 6、7、8 为:0.1060
- 样本 3、4、5 为:0.1667
此时得到:
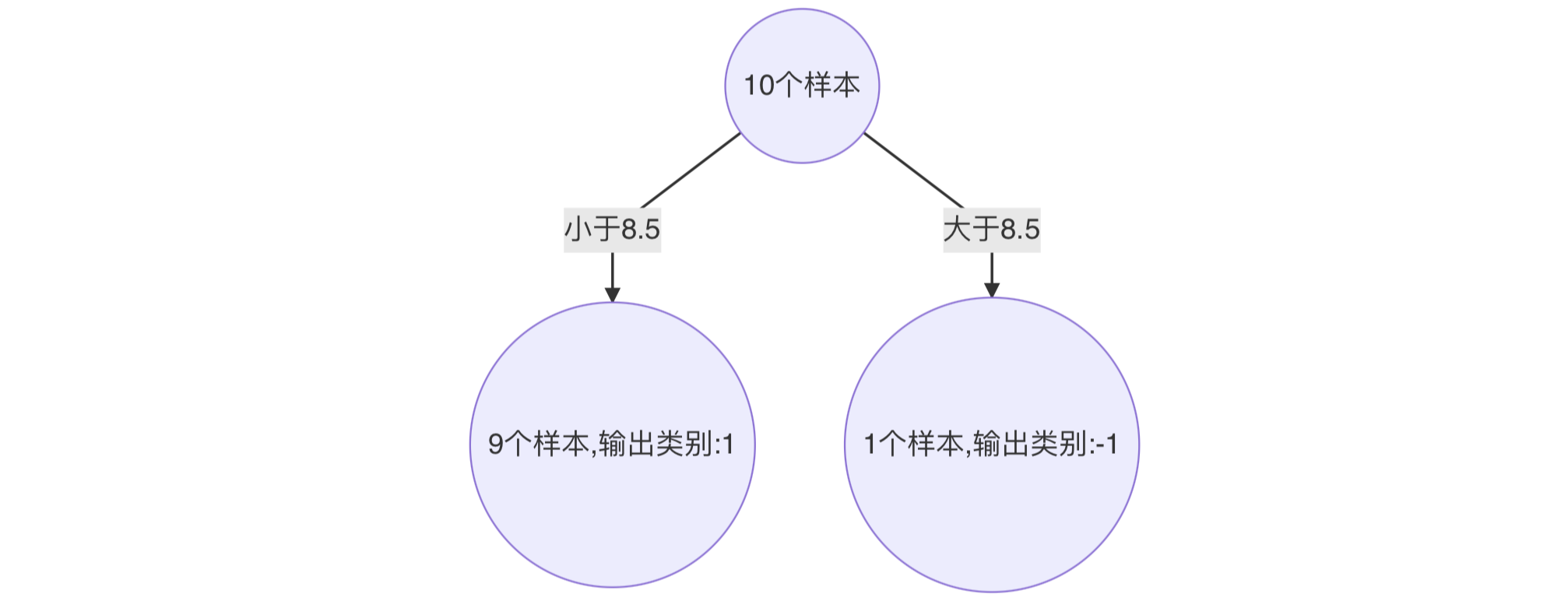

- 构建第三个弱学习器
错误率:0.1820,模型权重:0.7514
- 强学习器
AdaBoost 预测葡萄酒分类
葡萄酒分为白葡萄酒和红葡萄酒两类。
该分析涉及白葡萄酒,并基于数据集中显示的 13 个变量/特征:
固定酸度,挥发性酸度,柠檬酸,残留糖,氯化物,游离二氧化硫,总二氧化硫,密度,pH 值,硫酸盐,酒精,质量等。为了评估葡萄酒的质量,我们提出的方法就是根据酒的物理化学性质与质量的关系,找出高品质的葡萄酒具体与什么性质密切相关,这些性质又是如何影响葡萄酒的质量。
demo.py
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score
df_wine = pd.read_csv("./data/wine0501.csv")
df_wine = df_wine[df_wine["Class label"] != 1]
# 获取特征和标签
x = df_wine[["Alcohol", "Hue"]] # 酒精 和 色泽
y = df_wine["Class label"] # 标签列.
# 通过标签编码器, 把标签列转换为数值列.
le = LabelEncoder()
y = le.fit_transform(y)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=23, stratify=y)
# 模型训练, 预测, 评估.
# 单一决策树 -> 充当弱分类器
estimator1 = DecisionTreeClassifier(max_depth=3)
estimator1.fit(x_train, y_train)
y_pre1 = estimator1.predict(x_test)
print(f"单一决策树预测结果: {y_pre1}")
print(f"单一决策树预测正确率: {accuracy_score(y_test, y_pre1)}") # 0.91666666
# AdaBoost -> 集成学习, CART树, 200棵
estimator2 = AdaBoostClassifier(estimator=estimator1, n_estimators=200, learning_rate=0.1)
estimator2.fit(x_train, y_train)
y_pre2 = estimator2.predict(x_test)
print(f"AdaBoost集成学习预测结果: {y_pre2}")
print(f"AdaBoost集成学习预测正确率: {accuracy_score(y_test, y_pre2)}")运行结果.txt
单一决策树预测结果: [0 0 1 0 1 0 0 1 0 1 1 0 1 0 1 0 1 0 0 0 0 0 1 1]
单一决策树预测正确率: 0.9166666666666666
AdaBoost集成学习预测结果: [0 0 1 0 1 1 0 1 0 1 1 0 1 0 1 0 1 0 0 0 0 0 1 1]
AdaBoost集成学习预测正确率: 0.9583333333333334梯度提升树
梯度提升树(Gradient Boosting Decision Tree)也叫残差提升树,通过拟合残差的思想进行提升。
残差=真实值-预测值
如预测某人的年龄为 100 岁
- 第1次预测:对 100 岁预测,预测成 80 岁;100 – 80 = 20(残差)
- 第2次预测:上一轮残差 20 岁作为目标值,预测成 16 岁;20 – 16 = 4 (残差)
- 第3次预测:上一轮的残差 4 岁作为目标值,预测成 3.2 岁;4 – 3.2 = 0.8(残差)
- 若三次预测的结果串联起来:80 + 16 + 3.2 = 99.2
通过拟合残差可将多个弱学习器组成一个强学习器,这就是提升树的最朴素思想。
梯度提升树不再使用拟合残差,而是利用最速下降的近似方法,利用损失函数的负梯度作为提升树算法中的残差近似值。
假设:
- 我们前一轮迭代得到的强学习器是:
- 损失值为:
- 本轮迭代的目标是找到一个弱学习器:
- 让本轮的损失最小化:
- 则要拟合的负梯度为:
GBDT 拟合的负梯度就是残差。如果我们的 GBDT 进行的是分类问题,则损失函数变为 logloss,此时拟合的目标值就是该损失函数的负梯度值。
XgBoost
XGBoost(Extreme Gradient Boosting)全名叫极端梯度提升树,XGBoost是集成学习方法的王牌,在Kaggle数据挖掘比赛中,大部分获胜者用了XGBoost。XGBoost在绝大多数的回归和分类问题上表现的十分顶尖,是目前数据挖掘竞赛中最常用的模型。
XGBoost 是对GBDT的改进:
- 求解损失函数极值时使用泰勒二阶展开
- 在损失函数中加入了正则化项
- XGB 自创一个树节点分裂指标,这个分裂指标就是从损失函数推导出来的,XGB 分裂树时考虑到了树的复杂度
构建最优模型的方法是最小化训练数据的损失函数。
预测值和真实值经过某个函数计算出损失,并求解所有样本的平均损失,并且使得损失最小。这种方法训练得到的模型复杂度较高,很容易出现过拟合。因此,为了降低模型的复杂度,在损失函数中添加了正则化项,如下所示:
提高模型对未知数据的泛化能力。
XgBoost 的目标函数
XGBoost(Extreme Gradient Boosting)是对梯度提升树的改进,并且在损失函数中加入了正则化项。
目标函数的第一项表示整个强学习器的损失,第二部分表示强学习器中 K 个弱学习器的复杂度。
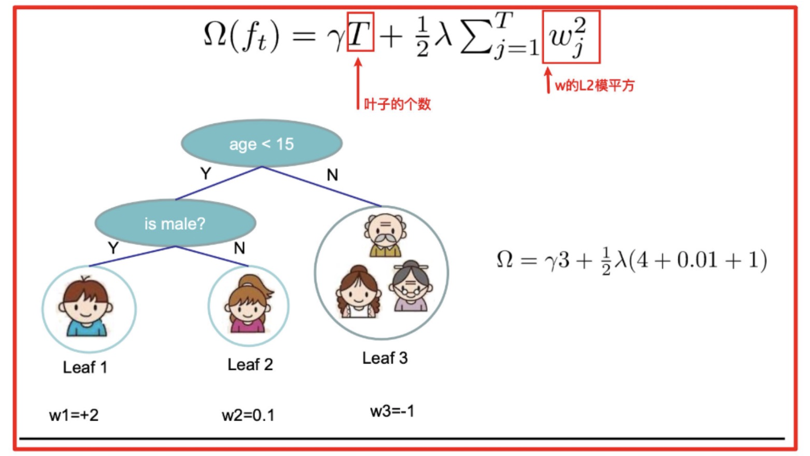
XgBoost 每一个弱学习器的复杂度主要从两个方面来考量:
- 中的 表示一棵树的叶子结点数量, 是对该项的调节系数
- 中的 表示叶子结点输出值组成的向量, 是对该项的调节系数
模型复杂度
假设我们要预测一家人对电子游戏的喜好程度,考虑到年轻和年老相比,年轻更可能喜欢电子游戏,以及男性和女性相比,男性更喜欢电子游戏,故先根据年龄大小区分小孩和大人,然后再通过性别区分开是男是女,逐一给各人在电子游戏喜好程度上打分,如下图所示:
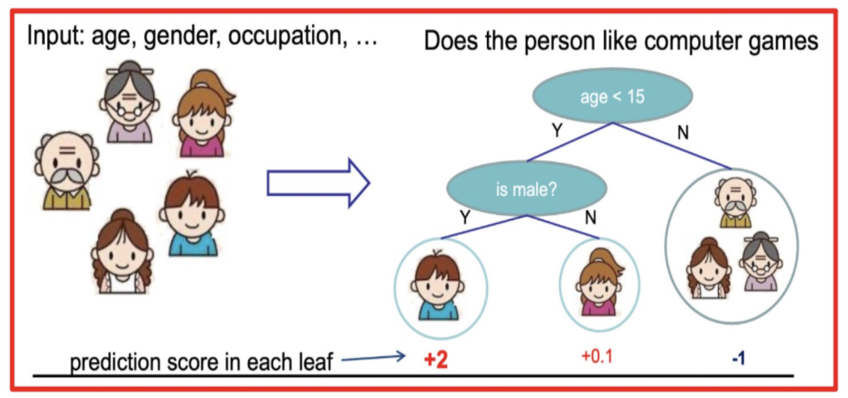
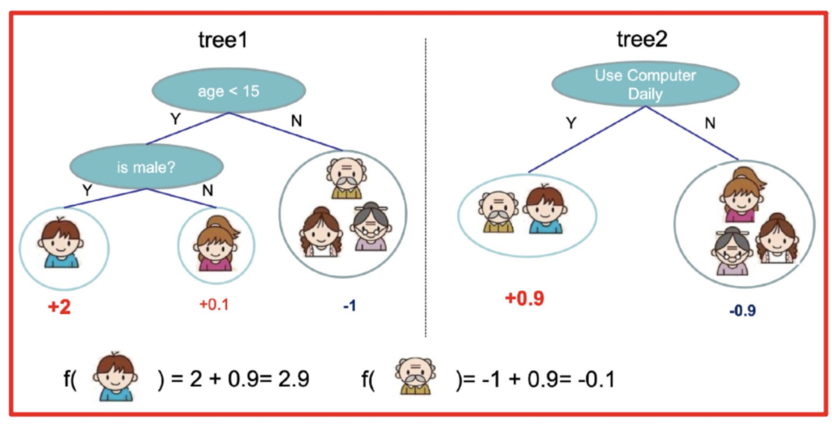
就这样,训练出了2棵树tree1和tree2,类似之前gbdt的原理,两棵树的结论累加起来便是最终的结论,所以:
- 小男孩的预测分数就是两棵树中小孩所落到的结点的分数相加:2 + 0.9 = 2.9。
- 爷爷的预测分数同理:-1 + 0.9 = -0.1。
具体如下图所示:
如下树tree1的复杂度表示为:
XgBoost API
sklearn 没有直接提供 XgBoost 算法,需要额外安装:
conda install xgboostXgBoost 可使用 sklearn 编码风格,也可使用自己的编码风格。
bst = XGBClassifier(n_estimators, max_depth, learning_rate, objective)| sklearn API参数 | 原生API参数 | 默认值 | 含义 | 说明 |
|---|---|---|---|---|
| n_estimators | num_round | 子学习器个数 | boosting框架下的子学习器数量。在原生API中,该参数在train方法中定义,也即最大迭代次数 | |
| learning_rate | eta | 0.3 | 学习率 | 用于限制子学习器的过拟合,提高模型的泛化能力,与n_estimators配合使用 |
| verbosity | verbosity | 1 | 是否输出详细信息 | 2是输出详细信息,1是偶尔输出,0是不输出 |
| subsample | subsample | 0.3 | 样本子采样数 | 用于限制子学习器的过拟合,提高模型的泛化能力,与n_estimators配合使用 |
| max_depth | max_depth | 6 | 树的最大深度 | 对基学习器函数空间的正则化,一种预修剪手段 |
| objective | objective | 损失函数 | 自定义的损失函数,通过申明合适的损失函数来处理分类、回归和排序问题。常见方法包括:线性回归 reg:linear、逻辑回归 reg:logistic、二分类 binary:logistic、多分类 multi:softmax、平方误差 reg:squarederror 等 | |
| booster | booster | gbtree | 基学习器类型 | xgboost中采用的基学习器,如梯度提升树 gbtree,梯度提升线性模型 gblinear 等 |
| gamma | gamma | 0 | 分裂阈值 | 即最小损失分裂,用来控制分裂逻辑的结构分数提升下限阈值 |
| min_child_weight | min_child_weight | 叶子节点最小权重 | 叶子节点允许的最小权重值(即节点中所有样本的二阶导数值之和),可视为对叶子节点的正则化,是一种后剪枝手段 | |
| reg_alpha | alpha | 0 | L1正则化系数 | 对集成模型进行L1正则化(以子节点的个数为约束)的系数 |
| reg_lambda | lambda | 0 | L2正则化系数 | 对集成模型进行L2正则化(以子节点权重w的平方和为约束)的系数 |
| nthread | n_jobs | 最大并发线程数 | 最大并发线程数 | |
| random_state | seed | 随机种子 | 控制模型的随机性 | |
| missing | missing | None | 缺失值标记 | 为缺失值进行标注。默认为None,即标注为np.nan |
红酒品质预测
数据集共包含 11 个特征,共计 3269 条数据. 我们通过训练模型来预测红酒的品质, 品质共有 6 个各类别,分别使用数字: 1、2、3、4、5 来表示。
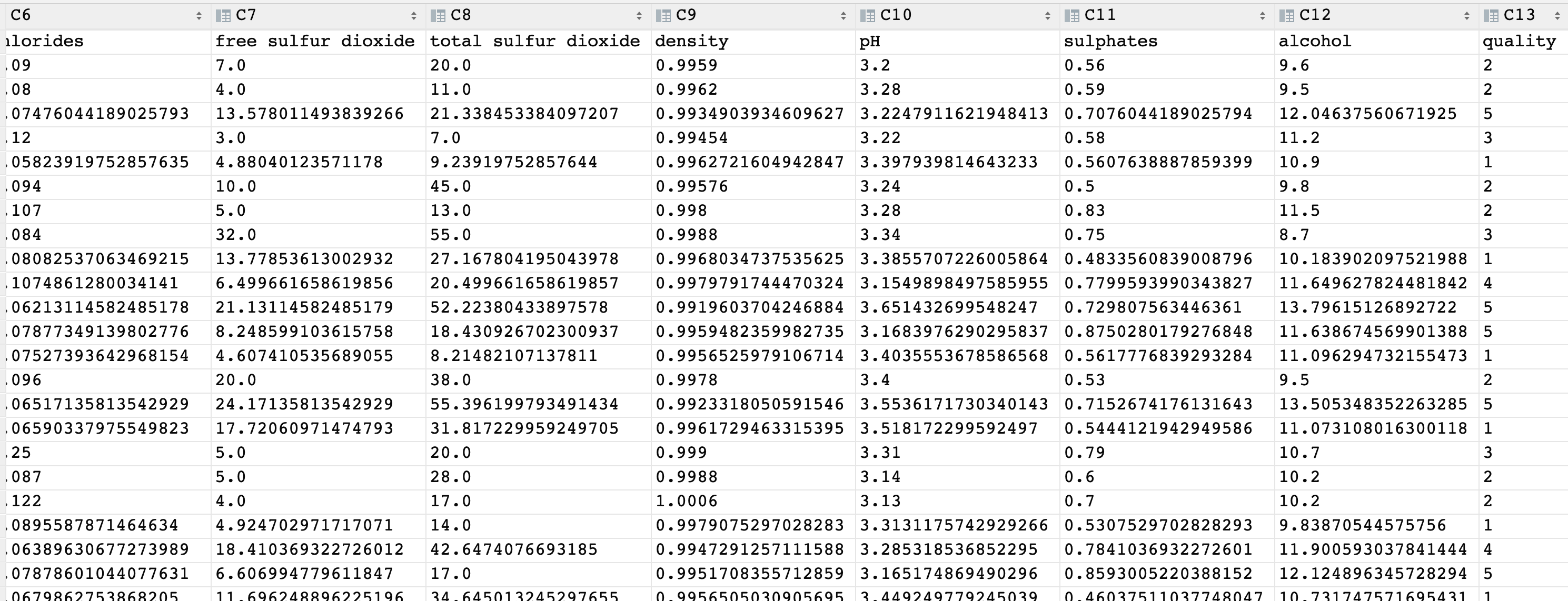
import joblib
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.utils import class_weight
def prepare_data():
# 读取数据
data = pd.read_csv("data/红酒品质分类.csv")
# 特征和标签
x = data.iloc[:, :-1]
y = data.iloc[:, -1] - 3
# 分割数据
x_train, x_valid, y_train, y_valid = train_test_split(x, y, test_size=0.2, stratify=y, random_state=22)
# 保存数据
pd.concat([x_train, y_train], axis=1).to_csv("data/红酒品质分类-train.csv", index=False)
pd.concat([x_valid, y_valid], axis=1).to_csv("data/红酒品质分类-valid.csv", index=False)
def train_model():
# 加载数据
train_data = pd.read_csv("data/红酒品质分类-train.csv")
valid_data = pd.read_csv("data/红酒品质分类-valid.csv")
x_train = train_data.iloc[:, :-1]
y_train = train_data.iloc[:, -1]
x_valid = valid_data.iloc[:, :-1]
y_valid = valid_data.iloc[:, -1]
# 建立模型
estimator = xgb.XGBClassifier(n_estimators=100, max_depth=6, learning_rate=0.1, objective="multi:softmax", eval_metric="merror", use_label_encoder=False, random_state=22)
# 训练模型
estimator.fit(x_train, y_train)
# 预测
y_pred = estimator.predict(x_valid)
# 输出评估
print(classification_report(y_valid, y_pred))
# 保存模型
joblib.dump(estimator, "model/xgboost.pkl")
def train_with_class_weight():
train_data = pd.read_csv("data/红酒品质分类-train.csv")
valid_data = pd.read_csv("data/红酒品质分类-valid.csv")
x_train = train_data.iloc[:, :-1]
y_train = train_data.iloc[:, -1]
x_valid = valid_data.iloc[:, :-1]
y_valid = valid_data.iloc[:, -1]
# 计算样本权重
sample_weights = class_weight.compute_sample_weight(class_weight="balanced", y=y_train)
estimator = xgb.XGBClassifier(n_estimators=100, max_depth=6, learning_rate=0.1, objective="multi:softmax", eval_metric="merror", use_label_encoder=False, random_state=22)
# 训练
estimator.fit(x_train, y_train, sample_weight=sample_weights)
y_pred = estimator.predict(x_valid)
print(classification_report(y_valid, y_pred))
def grid_search():
train_data = pd.read_csv("data/红酒品质分类-train.csv")
valid_data = pd.read_csv("data/红酒品质分类-valid.csv")
x_train = train_data.iloc[:, :-1]
y_train = train_data.iloc[:, -1]
x_valid = valid_data.iloc[:, :-1]
y_valid = valid_data.iloc[:, -1]
# 交叉验证
spliter = StratifiedKFold(n_splits=5, shuffle=True, random_state=22)
# 参数搜索空间
param_grid = {"max_depth": np.arange(3, 6, 1), "n_estimators": np.arange(50, 150, 50), "learning_rate": np.arange(0.1, 0.5, 0.1)}
estimator = xgb.XGBClassifier(objective="multi:softmax", eval_metric="merror", use_label_encoder=False, random_state=22)
cv = GridSearchCV(estimator, param_grid, cv=spliter, n_jobs=-1)
# 训练
cv.fit(x_train, y_train)
print("最优参数:", cv.best_params_)
# 预测
y_pred = cv.predict(x_valid)
print(classification_report(y_valid, y_pred))
if __name__ == "__main__":
# prepare_data()
# train_model()
# train_with_class_weight()
grid_search()