
外观
LLM 主要架构
LLM本身基于transformer架构. 自2017年,attention is all you need诞生起,原始的transformer模型为不同领域的模型提供了灵感和启发。基于原始的Transformer框架,衍生出了一系列模型,一些模型仅仅使用encoder或decoder,有些模型同时使用encoder+decoder。
LLM分类一般分为三种:自编码模型(encoder)、自回归模型(decoder)和序列到序列模型(encoder-decoder)。
自编码模型
代表模型:BERT,其特点为:Encoder-Only。基本原理:是在输入中随机MASK掉一部分单词,根据上下文预测这个词。AE模型通常用于内容理解任务,比如自然语言理解(NLU)中的分类任务:情感分析、提取式问答。
总体架构:如下图所示,最左边的就是BERT的架构图,一个典型的双向编码模型。
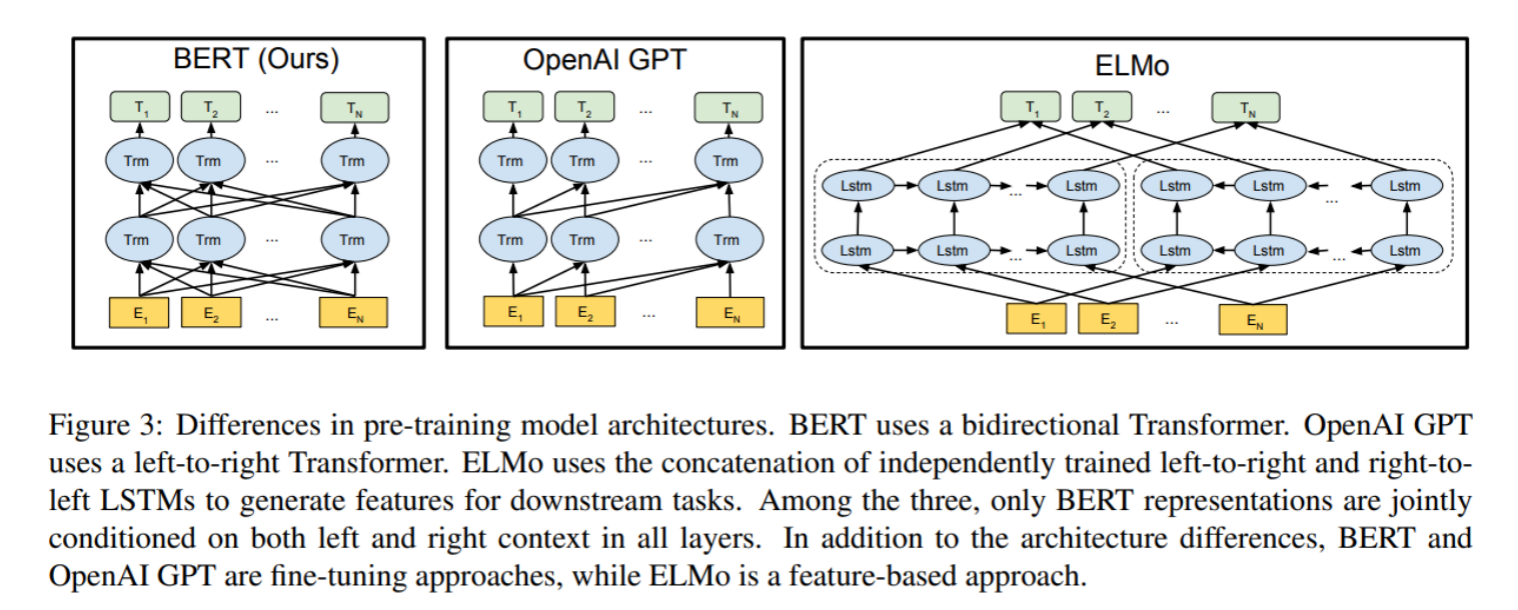
从上面的架构图中可以看到,宏观上BERT分三个主要模块:
- 最底层黄色标记的Embedding模块。
- 中间层蓝色标记的Transformer模块。
- 最上层绿色标记的预微调模块。
BERT中的Embedding模块是由三种Embedding共同组成而成,如下图:
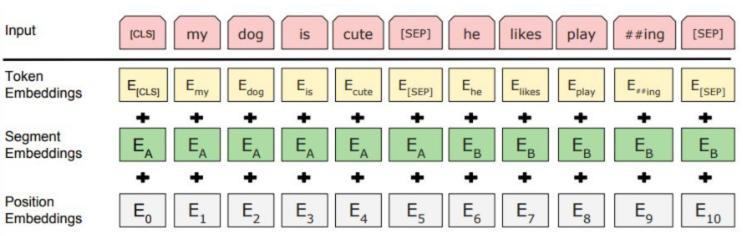
- Token Embeddings:词嵌入张量, 第一个单词是CLS标志, 可以用于之后的分类任务。
- Segment Embeddings:句子分段嵌入张量, 是为了服务后续的两个句子为输入的预训练任务。
- Position Embeddings:位置编码张量。
- 整个Embedding模块的输出张量就是这3个张量的直接加和结果。
双向 Transformer 模块。
预微调模块经过中间层Transformer的处理后, BERT的最后一层根据任务的不同需求而做不同的调整即可。
BERT 的预训练任务包括:
Masked LM(带 mask 的语言模型训练)
在原始训练文本中,随机地抽取 15% 的 token 作为参与 MASK 任务的对象。
- 80% 的概率下,用
[MASK]标记替换该 token。 - 在 10% 的概率下,用一个随机的单词替换 token。
- 在 10% 的概率下,保持该 token 不变。
Next Sentence Prediction(下一句话预测任务)
输入句子对 (A, B),模型来预测句子 B 是不是句子 A 的真实的下一句话。
- 所有参与任务训练的语句都被选中作为句子 A。
- 其中 50% 的 B 是原始文本中真实跟随的下一句话。 (标记为
IsNext,代表正样本) - 其中 50% 的 B 是原始文本中随机抽取的一句话。 (标记为
NotNext,代表负样本)
BERT的数据集是BooksCorpus (800M words) + English Wikipedia (2,500M words)。
模型的关键参数:
- transformer层数:12
- 特征维数:768
- Transformer head数:12
- 总参数量:115M
自回归模型
代表模型:GPT,特点为:Decoder-Only。 基本原理:从左往右学习的模型,只能利用上文或者下文的信息。 AR模型通常用于生成式任务,在长文本的生成能力很强,比如自然语言生成(NLG)领域的任务:摘要、翻译或抽 象问答。
GPT训练过程如下图:
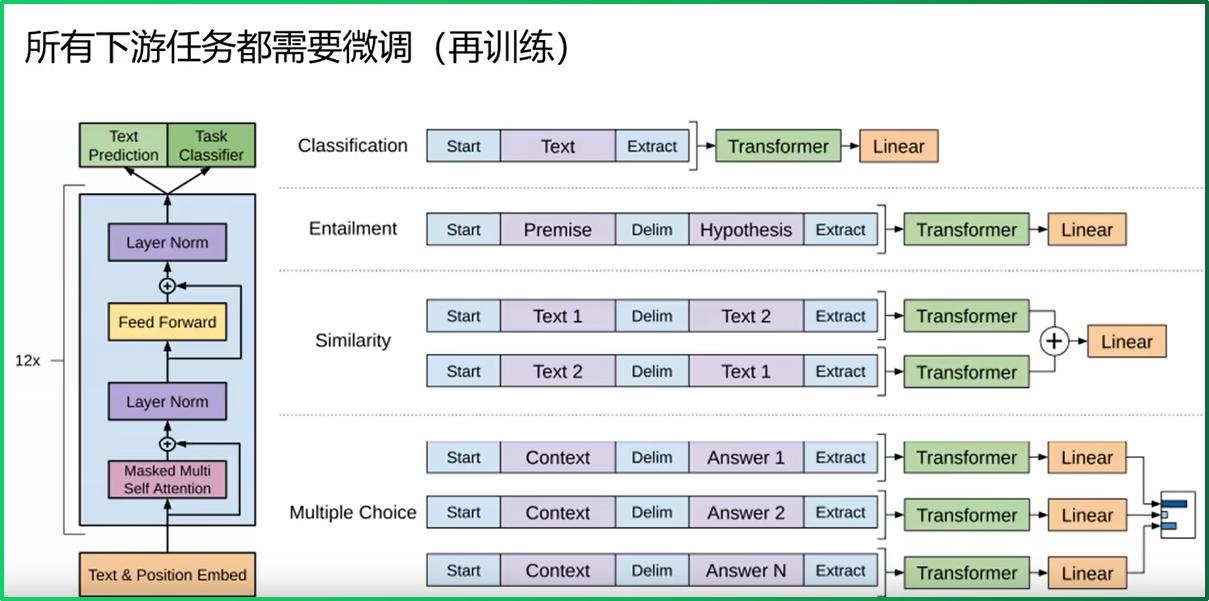
GPT使用了BooksCorpus数据集,文本大小约5GB,包含7400w+的句子。这个数据集由7000本独立的、不同风格类型的书籍组成,选择该部分数据集的原因:
- 书籍文本包含大量高质量长句,保证模型学习长距离信息依赖。
- 书籍未开源公布,所以很难在下游数据集上见到,更能验证模型的泛化能力。
参数:
- transformer层数:12
- 特征维数:768
- Transformer head数:12
- 总参数量:1.17亿
序列到序列模型
代表模型 T5。
encoder-decoder模型同时使用编码器和解码器。它将每个task视作序列到序列的转换/生成(比如,文本到文本,文本到图像或者图像到文本的多模态任务)。Encoder-decoder模型通常用于需要内容理解和生成的任务,比如机器翻译。
T5由谷歌提出,该模型的目的为构建任务统一框架:将所有NLP任务都视为文本转换任务。
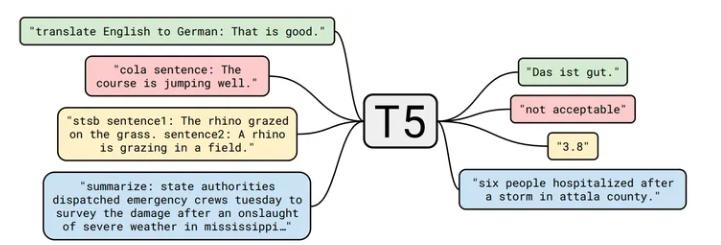
T5模型结构与原始的Transformer基本一致,除了做了以下几点改动:
- 采用了一种简化版的LayerNormalization,去除了LayerNorm的bias;将LayerNorm放在残差连接外面。
- 位置编码:T5使用了一种简化版的相对位置编码,即每个位置编码都是一个标量,被加到logits上用于计算注意力权重。各层共享位置编码,但是在同一层内,不同的注意力头的位置编码都是独立学习的。
自监督预训练:T5在预训练阶段采用了类似于BERT和GPT的大规模自监督学习策略,但与这两个模型的设计不同的是,T5使用了“文本到文本”的格式来处理任务。预训练任务包括两种类型:CausalLanguageModeling(因果语言建模)和填空任务(MaskedLanguageModeling)
多任务微调:除了使用大规模数据进行无监督预训练,T5模型还可以利用不同任务的标注数据进行有监督的多任务预训练,例如SQuAD问答和机器翻译等任务。
T5数据集:作者对公开爬取的网页数据集CommonCrawl进行了过滤,去掉一些重复的、低质量的,看着像代码的文本等,并且最后只保留英文文本,得到数据集C4:theColossalCleanCrawledCorpus。
模型参数:
- transformer层数:24
- 特征维数:768
- Transformer head数:12
- 总参数量:2.2亿