外观
决策树
决策树算法是一种监督学习算法,英文是 "Decision tree"。
决策树思想的来源非常朴素,试想每个人的大脑都有类似于 if-else 这样的逻辑判断,这其中的 if 表示的是条件,if 之后的 else 就是一种选择或决策。程序设计中的条件分支结构就是 if-else 结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法。
决策树是一种树形结构,树中每个内部节点表示一个特征上的判断,每个分支代表一个判断结果的输出,每个叶子节点代表一种分类结果。
决策树的建立过程:
- 特征选择:选取有较强分类能力的特征。
- 决策树生成:根据选择的特征生成决策树。
- 决策树也易过拟合,采用剪枝的方法缓解过拟合。
ID3 决策树
ID3 树是基于信息增益构建的决策树。
信息熵
- 熵在信息论中代表随机变量不确定度的度量。
- 熵越大,数据的不确定性度越高。
- 熵越小,数据的不确定性越低。
公式
例子1:假如有三个类别,分别占比为:,信息熵计算结果为:
例子2:假如有三个类别,分别占比为:,信息熵计算结果为:
熵越大,表示整个系统不确定性越大,越随机,反之确定性越强。
例子3:假如有三个类别,分别占比为:,信息熵计算结果为:
信息增益
特征 对训练数据集 的信息增益 ,定义为集合 的熵 与特征 给定条件下 的熵 之差。即:
根据信息增益选择特征方法是:对训练数据集 ,计算其每个特征的信息增益,并比较它们的大小,并选择信息增益最大的特征进行划分。表示由于特征 而使得对数据 的分类不确定性减少的程度。
称为条件熵,公式:
例:已知六个样本:
| 特征a | 目标值 |
|---|---|
整体类别是 3 个 、3 个 。
先算整体熵:
代入公式:
所以整体熵值为 。
然后按特征 a 分裂。特征 a 有两个值 和 , 对应样本为 ,,所以熵 。
因为 样本只有 ,所以熵 。
占 , 占 ,所以条件熵 。
信息增益 。
决策树就是选信息增益最大的特征做分裂。原来特征 完全混乱,但是按照特征 a 分裂后, 分支变成了 (有点混乱), 分支变成了 (完全纯),整体混乱程度从 1 下降到 0.54,所以特征 a 带来了 0.46 的信息增益。信息增益衡量的是某个特征能够让数据变得“更纯”多少,如果增益好,这个特征就很好。这就是信息增益的用处。
上述过程就可以理解为:
- 计算整体混乱程度(1)
- 按特征 a 分裂
- 计算分裂后的混乱程度(0.54)
- 看下降多少(0.46)
ID3 决策树构建论坛流失率模型
需求:考察性别、活跃度特征哪一个对流失率的影响更大。
| uin | gender | act_info | is_lost |
|---|---|---|---|
| 1 | 男 | 高 | 0 |
| 2 | 女 | 中 | 0 |
| 3 | 男 | 低 | 1 |
| 4 | 女 | 高 | 0 |
| 5 | 男 | 高 | 0 |
| 6 | 男 | 中 | 0 |
| 7 | 男 | 中 | 1 |
| 8 | 女 | 中 | 0 |
| 9 | 女 | 低 | 1 |
| 10 | 女 | 中 | 0 |
| 11 | 女 | 高 | 0 |
| 12 | 男 | 低 | 1 |
| 13 | 女 | 低 | 1 |
| 14 | 男 | 高 | 0 |
| 15 | 男 | 高 | 0 |
总共 15 条样本,其中 5 条正样本,10 条负样本。
按整体统计:
| 类别 | positive | negative | 汇总 |
|---|---|---|---|
| 整体 | 5 | 10 | 15 |
按性别统计:
| 性别 | positive | negative | 汇总 |
|---|---|---|---|
| 男性 | 3 | 5 | 8 |
| 女性 | 2 | 5 | 7 |
按活跃度统计:
| 活跃度 | positive | negative | 汇总 |
|---|---|---|---|
| 高 | 0 | 6 | 6 |
| 中 | 1 | 4 | 5 |
| 低 | 4 | 0 | 4 |
- 计算熵:
- 计算性别条件熵(a="性别")
- 计算性别信息增益(a="性别")
- 计算活跃度条件熵(a="活跃度")
- 计算活跃度信息增益(a="活跃度")
由此得出,活跃度的信息增益比性别的信息增益大,对用户流失的影响比性别大。
C4.5 决策树
ID3 具有如下缺点:
易过拟合:
- ID3倾向于生成深而复杂的树,尤其当训练数据噪声较多时。
- 对少数异常样本敏感,会导致对训练数据记忆过度,从而在新数据上表现不佳。
仅能处理离散特征:
- ID3在原始形式下只能处理离散型特征(categorical feature)。
- 对连续特征(如身高、价格)必须先离散化,否则算法无法计算信息增益。
- 离散化方式不当会导致信息损失或偏差。
偏向多值特征:
- 信息增益衡量标准会偏向取值较多的特征。
- 例如,一个ID号或唯一标识字段虽然信息增益高,但对分类没有实际意义。
- 这会导致树在某些特征上产生不合理的分裂。
无剪枝机制:
- ID3本身没有提供剪枝(pruning)策略。
- 树生成后如果过深,会包含许多冗余分支,增加复杂度和过拟合风险。
- 需要结合后续算法(如C4.5、CART)引入剪枝。
对缺失值处理能力弱:
- 原始ID3对数据缺失值不敏感,需要手动处理或进行填充。
- 在实际数据集(尤其大规模数据)中,这会成为一个限制。
计算开销:
- 对大规模特征集,计算每个特征的信息增益可能开销较大。
- 尤其连续特征需要尝试不同切分点,计算成本增加。
| 特征b | 特征a | 目标值 |
|---|---|---|
| 1 | α | A |
| 2 | α | A |
| 3 | β | B |
| 4 | α | A |
| 5 | β | B |
| 6 | α | B |
由此,C4.5 树引出了信息增益率概念。
- Gain_Ratio 表示信息增益率
- IV 表示分裂信息、内在信息,也叫特征熵。IV 公式中, 表示数据集 中第 个特征值的样本数;D 表示数据集 的样本总数;所以分数 表示第 个特征值的样本数占比/概率。
- 特征的信息增益除以内在信息:
- 如果某个特征的特征值种类较多,则其内在信息值就越大。即:特征值种类越多,除以的系数就越大。
- 如果某个特征的特征值种类较小,则其内在信息值就越小。即:特征值种类越小,除以的系数就越小。
信息增益比本质:是在信息增益的基础之上乘上一个惩罚参数。特征个数较多时,惩罚参数较小;特征个数较少时,惩罚参数较大。惩罚参数:数据集 以特征 作为随机变量的熵的倒数。
例:
| 特征b | 特征a | 目标值 |
|---|---|---|
| 1 | A | |
| 2 | A | |
| 3 | B | |
| 4 | A | |
| 5 | B | |
| 6 | B |
样本总数
一、总体信息熵
类别分布:
二、按特征 计算
- 条件熵
当 : 共 个样本
当 : 共 个样本
加权条件熵:
- 信息增益
- 分裂信息
- 信息增益率
三、按特征 计算
特征 有 个不同取值,每个仅出现 次。
每个子集纯,熵为 。
- 条件熵
- 信息增益
- 分裂信息
- 信息增益率
最终结果:
特征 : 信息增益 分裂信息 信息增益率
特征 : 信息增益 分裂信息 信息增益率
虽然 的信息增益更大,但由于分裂信息非常高(分支过多),信息增益率选择特征 a。
CART 决策树
CART,Classfication And Regression Tree,是一种决策树模型,它即可以用于分类,也可以用于回归。
基尼指数
- 信息增益(ID3)、信息增益率值越大(C4.5),则说明优先选择该特征。
- 基尼指数值越小(cart),则说明优先选择该特征。
CART 决策树示例
| 序号 | 是否有房 | 婚姻状况 | 年收入(K) | 是否拖欠贷款 |
|---|---|---|---|---|
| 1 | yes | single | 125 | no |
| 2 | no | married | 100 | no |
| 3 | no | single | 70 | no |
| 4 | yes | married | 120 | no |
| 5 | no | divorced | 95 | yes |
| 6 | no | married | 60 | no |
| 7 | yes | divorced | 220 | no |
| 8 | no | single | 85 | yes |
| 9 | no | married | 75 | no |
| 10 | no | single | 90 | yes |
首先计算是否有房。根据是否有房将目标值划分为两部分:
- 计算有房子的基尼值:有房子有 1、4、7 共计三个样本,对应:3个no、0个yes
- 计算无房子的基尼值:无房子有 2、3、5、6、8、9、10 共七个样本,对应:4个no、3个yes
- 计算基尼指数:第一部分样本数量占了总样本的 3/10、第二部分样本数量占了总样本的 7/10:
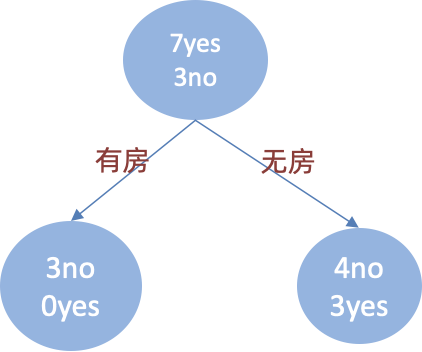
然后计算结婚情况。
- 计算 {married} 和 {single, divorced} 情况下的基尼指数:
结婚的基尼值,有 2、4、6、9 共 4 个样本,并且对应目标值全部为 no:
不结婚的基尼值,有 1、3、5、7、8、10 共 6 个样本,并且对应 3 个 no,3 个 yes:
以 married 作为分裂点的基尼指数:
- 计算 {single} | {married,divorced} 情况下的基尼指数
- 计算 {divorced} | {single,married} 情况下基尼指数
- 最终:该特征的基尼值为 0.3,并且预选分裂点为:{married} 和 {single, divorced}
最后计算年收入。年收入为数值型,所以采取另一种方式计算。
先将数值型属性升序排列,以相邻中间值作为待确定分裂点:
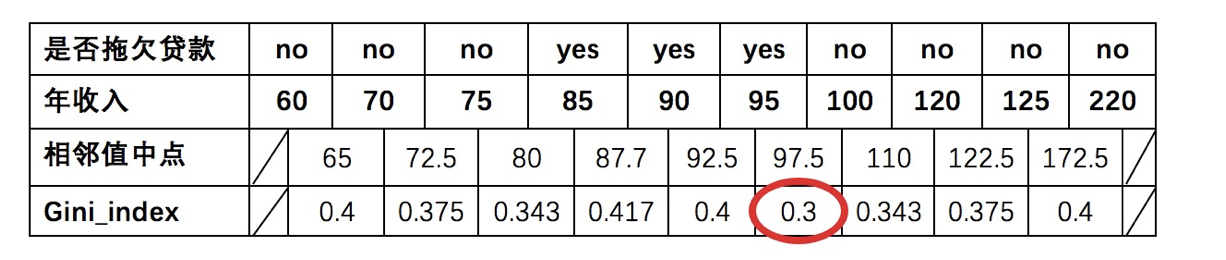
以年收入 65 将样本分为两部分,计算基尼指数:
以此类推计算所有分割点的基尼指数,我们发现最小的基尼指数为 0.3。
此时,我们发现:
- 以是否有房作为分裂点的基尼指数为:0.343
- 以婚姻状况为分裂特征、以 married 作为分裂点的基尼指数为:0.3
- 以年收入作为分裂特征、以 97.5 作为分裂点的的基尼指数为:0.3
最小基尼指数有两个分裂点,我们随机选择一个即可,假设婚姻状况,则可确定决策树如下:
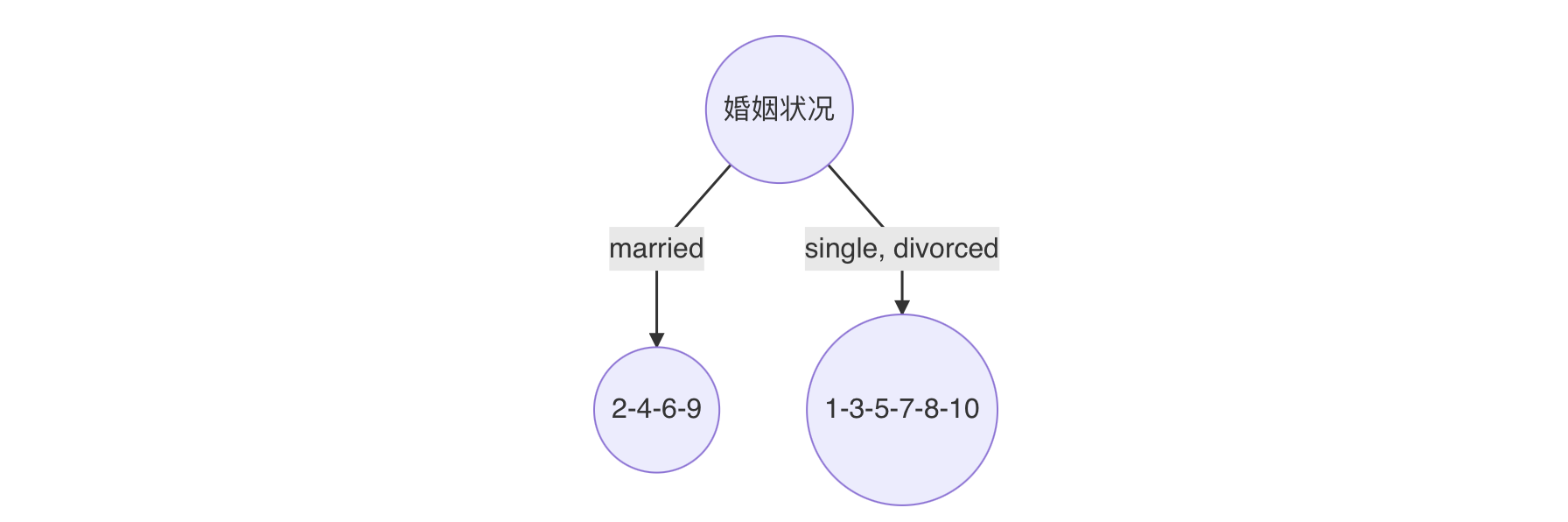
重复上面步骤,直到每个叶子结点纯度达到最高。
CART 决策树做回归
- CART 分类树预测输出的是一个离散值,CART 回归树预测输出的是一个连续值。
- CART 分类树使用基尼指数作为划分、构建树的依据,CART 回归树使用平方损失。
- 分类树使用叶子节点里出现更多次数的类别作为预测类别,回归树则采用叶子节点里均值作为预测输出。
平方损失公式:
假设:数据集只有 1 个特征 x,目标值值为 y,如下表所示:
| x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| y | 5.56 | 5.7 | 5.91 | 6.4 | 6.8 | 7.05 | 8.9 | 8.7 | 9 | 9.05 |
由于只有 1 个特征,所以只需要选择该特征的最优划分点,并不需要计算其他特征。
先将特征 x 的值排序,并取相邻元素均值作为待划分点:
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 | 9.5 |
|---|
计算每一个划分点的平方损失,例如:1.5 的平方损失计算过程为:
R1 为 小于 1.5 的样本个数,样本数量为:1,其输出值为:5.56
R2 为 大于 1.5 的样本个数,样本数量为:9 ,其输出值为:
该划分点的平方损失:
以此方式计算 2.5、3.5... 等划分点的平方损失,结果如下所示:
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 | 6.5 | 7.5 | 8.5 | 9.5 |
|---|---|---|---|---|---|---|---|---|---|
| m(s) | 15.72 | 12.07 | 8.36 | 5.78 | 3.91 | 1.93 | 8.01 | 11.73 | 15.74 |
当划分点 s=6.5 时,m(s) 最小。因此,第一个划分变量:特征为 X,切分点为 6.5,即:j=x, s=6.5。
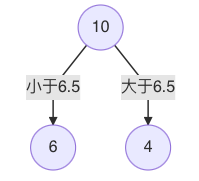
对左子树的 6 个结点计算每个划分点的平方式损失,找出最优划分点:
| x | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| y | 5.56 | 5.7 | 5.91 | 6.4 | 6.8 | 7.05 |
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 |
|---|---|---|---|---|---|
| c1 | 5.56 | 5.63 | 5.72 | 5.89 | 6.07 |
| c2 | 6.37 | 6.54 | 6.75 | 6.93 | 7.05 |
| s | 1.5 | 2.5 | 3.5 | 4.5 | 5.5 |
|---|---|---|---|---|---|
| m(s) | 1.3087 | 0.754 | 0.2771 | 0.4368 | 1.0644 |
s=3.5时,m(s) 最小,所以左子树继续以 3.5 进行分裂:
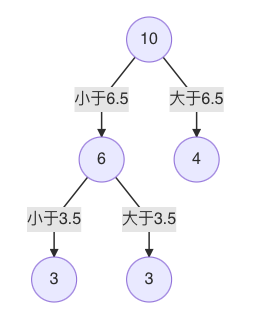
以此类推。
CART 回归树构建过程如下:
- 选择第一个特征,将该特征的值进行排序,取相邻点计算均值作为待划分点
- 根据所有划分点,将数据集分成两部分:R1、R2
- R1 和 R2 两部分的平方损失相加作为该切分点平方损失
- 取最小的平方损失的划分点,作为当前特征的划分点
- 以此计算其他特征的最优划分点、以及该划分点对应的损失值
- 在所有的特征的划分点中,选择出最小平方损失的划分点,作为当前树的分裂点
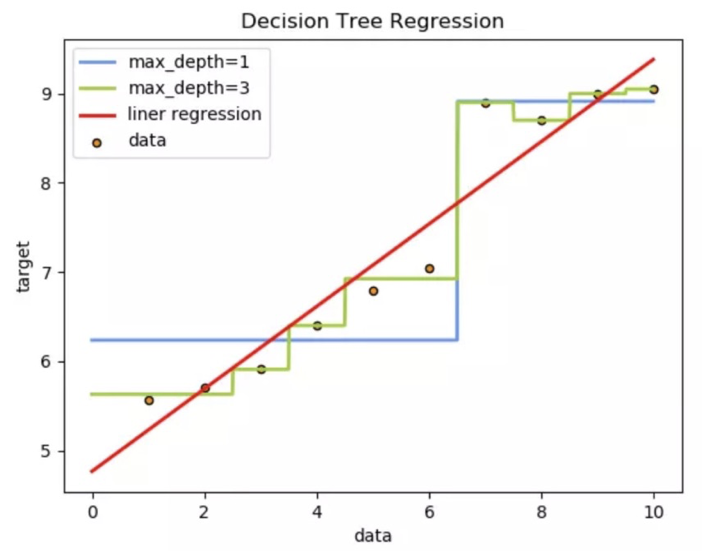
分别训练线性回归、回归决策树模型,并预测对比。
训练模型,并使用1000个[0.0, 10]之间的数据,让模型预测,画出预测值图线。
从预测效果来看:
1、线性回归是一条直线
2、决策树是曲线
3、树的拟合能力是很强的,易过拟合
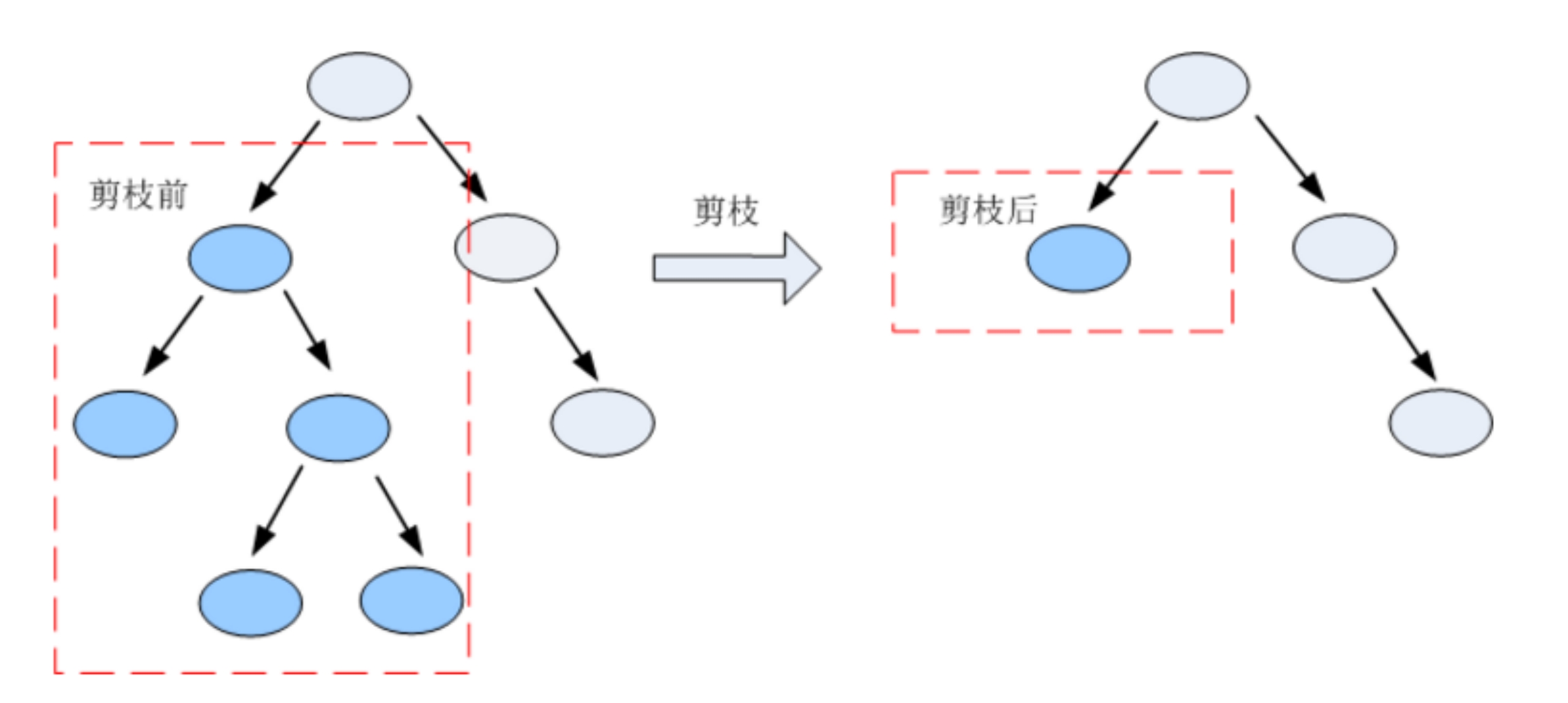
决策树剪枝
剪枝 (pruning)是决策树学习算法对付过拟合的主要手段。
在决策树学习中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树分支过多,这时就可能因训练样本学得"太好"了,以致于把训练集自身的一些特点当作所有数据都具有的一般性质而导致过拟合。因此,可通过主动去掉一些分支来降低过拟合的风险。
剪枝是指将一颗子树的子节点全部删掉,利用叶子节点替换子树(实质上是后剪枝技术),也可以(假定当前对以root为根的子树进行剪枝)只保留根节点本身而删除所有的叶子,以下图为例:
决策树剪枝的基本策略有"预剪枝" (pre-pruning)和"后剪枝"(post-pruning) 。
- 预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点;
- 后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
预剪枝
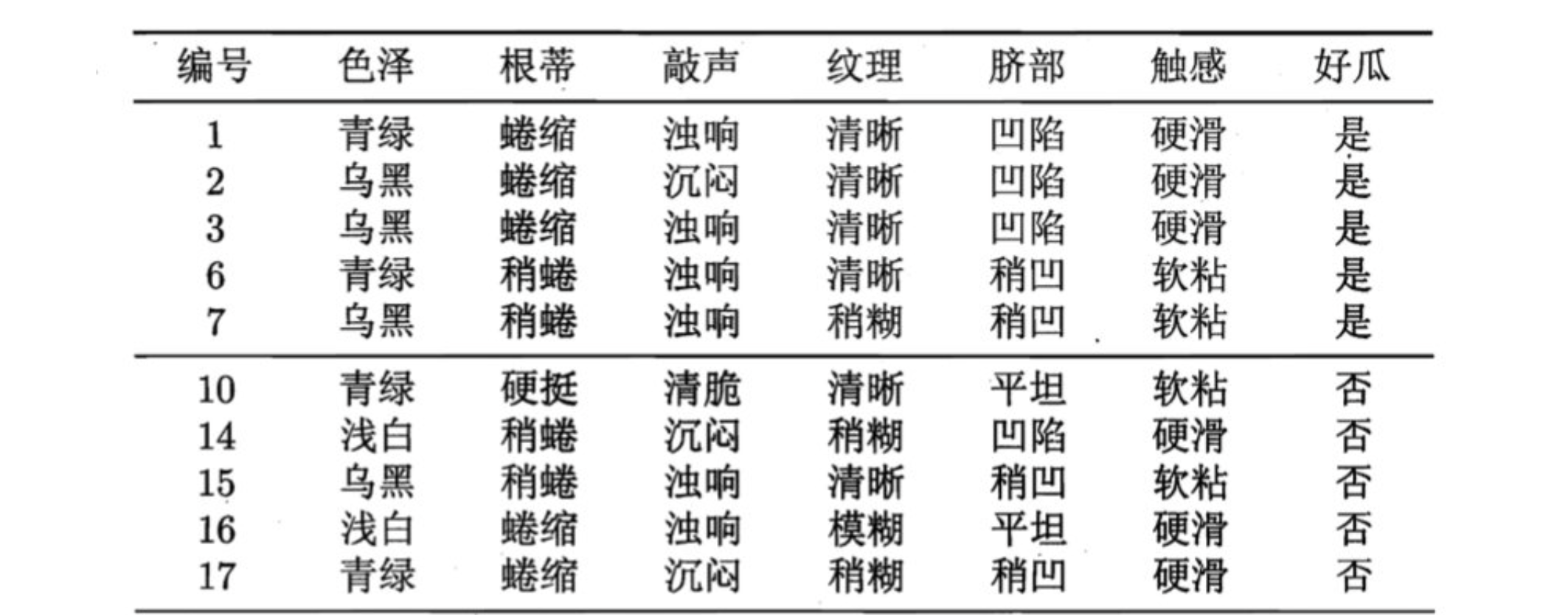
在构建树时,为了能够实现剪枝,可预留一部分数据用作 "验证集" 以进行性能评估。我们的训练集如下:
验证集:
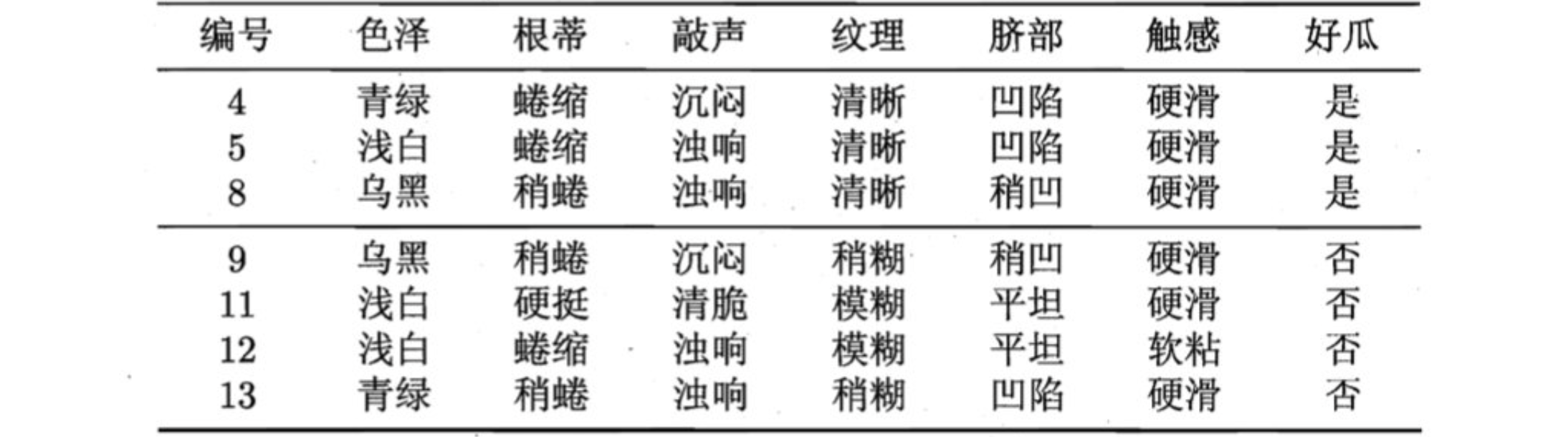
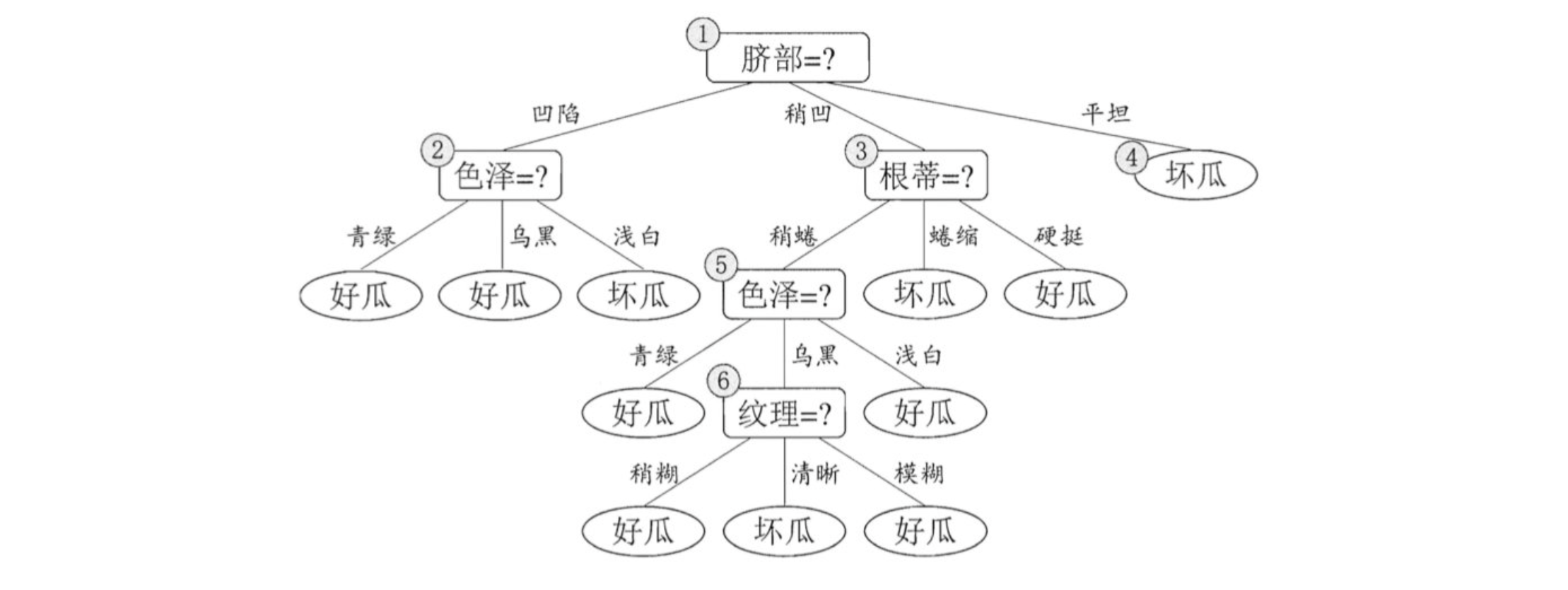
- 假设:当前树只有一个结点,即编号为1的结点. 此时,所有的样本预测类别为:其类别标记为训练样例数最多的类别,假设我们将这个叶结点标记为 "好瓜"。此时,在验证集上所有的样本都会被预测为 "好瓜",此时的准确率为:3/7。
- 如果进行此次分裂,则树的深度为 2,有三个分支. 在用属性"脐部"划分之后,上图中的结点2、3、4分别包含编号为 {1,2,3,14}、 {6,7,15,17}、 {10,16} 的训练样例,因此这 3 个结点分别被标记为叶结点"好瓜"、 "好瓜"、 "坏瓜"。此时,在验证集上 4、5、8、11、12 样本预测正确,准确率为:5/7。很显然,通过此次分裂准确率有所提升,值得分裂。
- 接下来,对结点2进行划分,基于信息增益准则将挑选出划分属性"色泽"。然而,在使用"色泽"划分后,编号为 {5} 的验证集样本分类结果会由正确转为错误,使得验证集精度下降为 57.1%。于是,预剪枝策略将禁止结点2被划分。
- 对结点3,最优划分属性为"根蒂",划分后验证集精度仍为 5/7. 这个 划分不能提升验证集精度,于是,预剪枝策略禁止结点3被划分。
- 对结点4,其所含训练样例己属于同一类,不再进行划分。
于是,基于预剪枝策略从上表数据所生成的决策树如上图所示,其验证集精度为 71.4%. 这是一棵仅有一层划分的决策树。
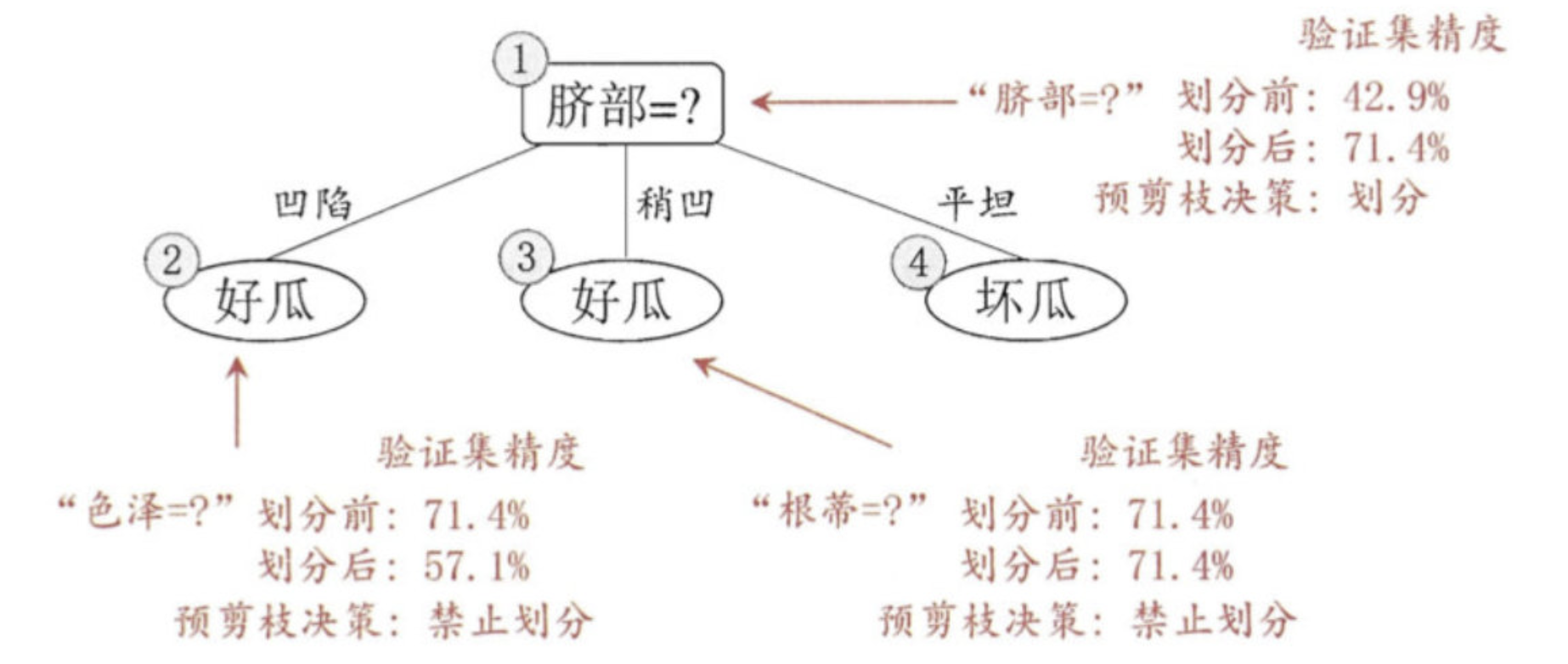
后剪枝
后剪枝先从训练集生成一棵完整决策树,继续使用上面的案例,从前面计算,我们知前面构造的决策树的验证集精度为42.9%。
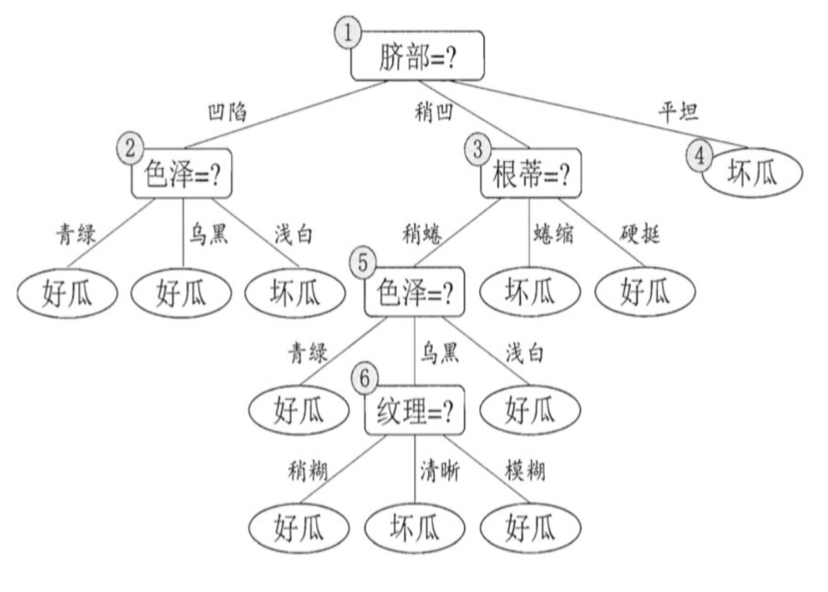
- 首先考察结点6,若将其领衔的分支剪除则相当于把6替换为叶结点。替换后的叶结点包含编号为 {7,15} 的训练样本,于是该叶结点的类别标记为"好瓜",此时决策树的验证集精度提高至 57.1%。
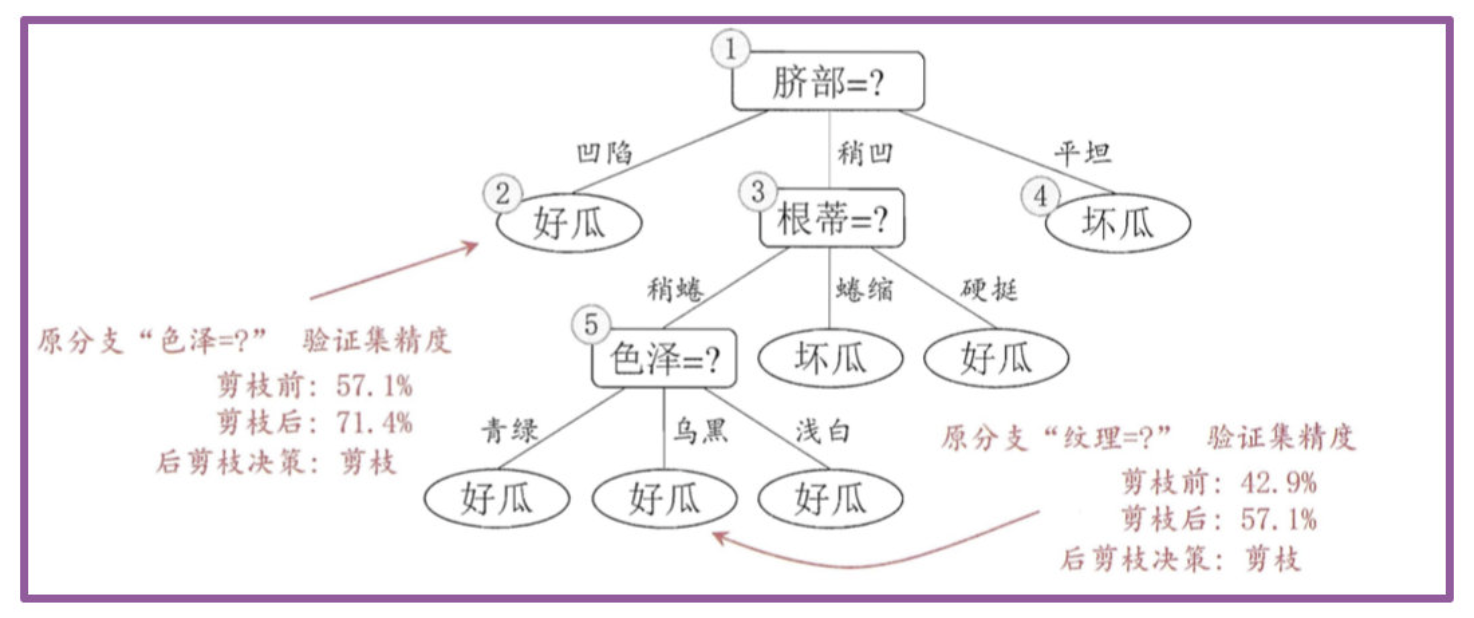
- 然后考察结点5,若将其领衔的子树替换为叶结点,则替换后的叶结点包含编号为 {6,7,15}的训练样例,叶结点类别标记为"好瓜';此时决策树验证集精度仍为 57.1%. 于是,可以不进行剪枝.
- 对结点2,若将其领衔的子树替换为叶结点,则替换后的叶结点包含编号 为 {1,2,3,14} 的训练样例,叶结点标记为"好瓜"此时决策树的验证集精度提高至 71.4%. 于是,后剪枝策略决定剪枝.
- 对结点3和1,若将其领衔的子树替换为叶结点,则所得决策树的验证集 精度分别为 71.4% 与 42.9%,均未得到提高,于是它们被保留。
- 最终,基于后剪枝策略生成的决策树如上图所示,其验证集精度为 71.4%。
两种剪枝方法的对比
预剪枝优点:
- 预剪枝使决策树的很多分支没有展开,不单降低了过拟合风险,还显著减少了决策树的训练、测试时间开销
预剪枝缺点:
- 有些分支的当前划分虽不能提升泛化性能,甚至会导致泛化性能降低,但在其基础上进行的后续划分却有可能导致性能的显著提高
- 预剪枝决策树也带来了欠拟合的风险
后剪枝优点:
- 比预剪枝保留了更多的分支。一般情况下,后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝
后剪枝缺点:
- 但后剪枝过程是在生成完全决策树之后进行的,并且要自底向上地对树中所有非叶子节点进行逐一考察,因此在训练时间开销比未剪枝的决策树和预剪枝的决策树都要大得多。
决策树 API
sklearn.tree.DecisionTreeClassifier(
criterion="gini",
splitter="best",
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
min_weight_fraction_leaf=0.0,
max_features=None,
random_state=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
class_weight=None,
ccp_alpha=0.0,
monotonic_cst=None,
)criterion: 特征选择标准,可选gini或entropy,前者代表基尼系数(CART决策树),后者代表信息增益。min_samples_split: 内部节点再划分所需最小样本数。min_samples_leaf: 叶子结点最少样本数。max_depth: 叶子结点最少样本数。
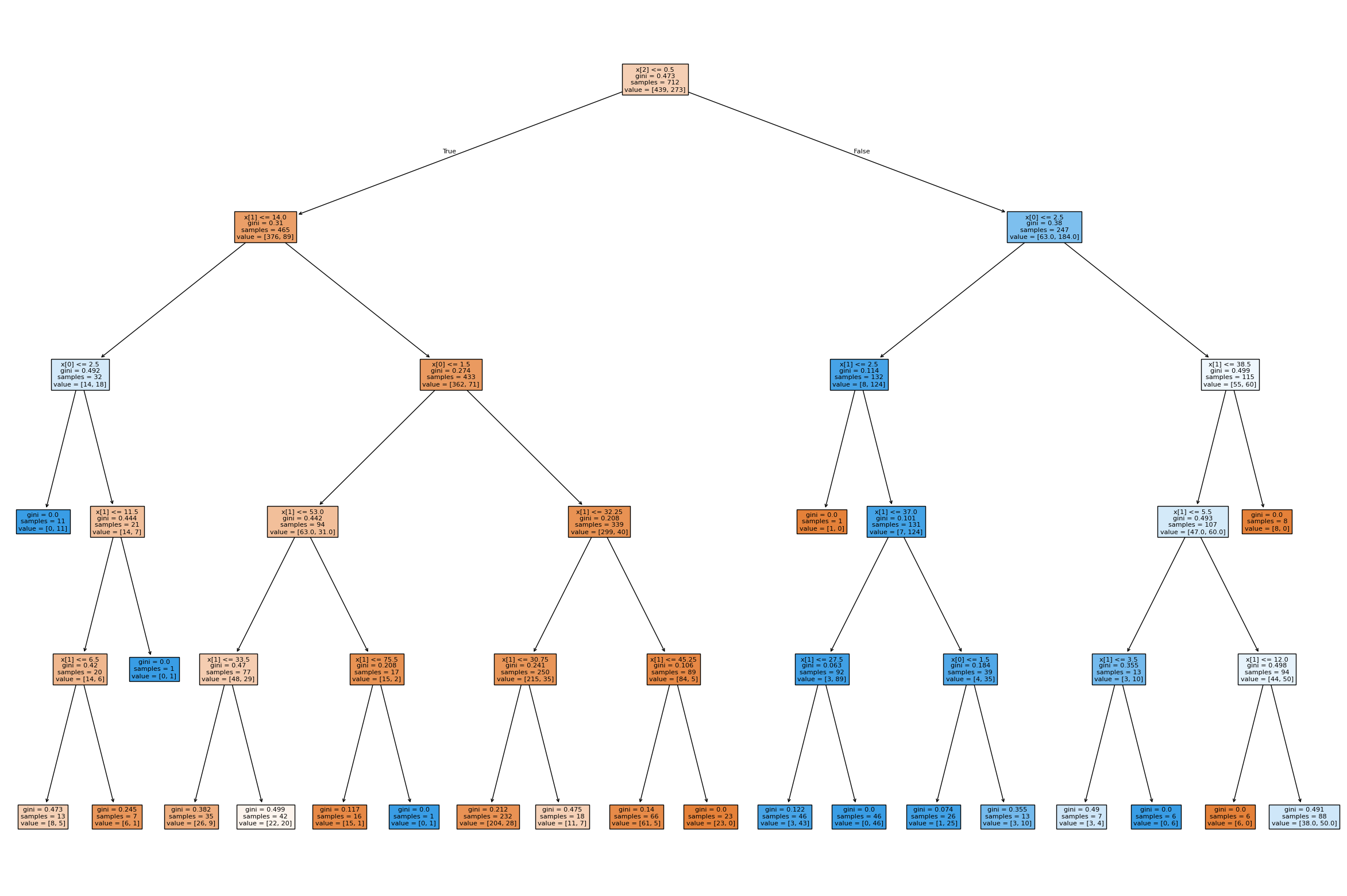
这里以泰坦尼克号乘客生存预测为例。
数据集的特征有票的类别、是否存活、乘坐班次、年龄、登陆、来源地、目的地、房间、船和性别。
乘坐班次是乘客班(1、2、3),是社会经济阶层的代表。
age 字段存在缺失值。
demo.py
import pandas as pd
data = pd.read_csv("./data/train.csv")
data.info()运行结果.txt
<class 'pandas.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null str
4 Sex 891 non-null str
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null str
9 Fare 891 non-null float64
10 Cabin 204 non-null str
11 Embarked 889 non-null str
dtypes: float64(2), int64(5), str(5)
memory usage: 83.7 KB我们提取特征和标签,处理缺失值。
demo.py
import pandas as pd
data = pd.read_csv("./data/train.csv")
x = data[["Pclass", "Sex", "Age"]]
y = data["Survived"]
# 填充缺失值
x["Age"] = x["Age"].fillna(x["Age"].mean())
x.info()运行结果.txt
<class 'pandas.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Pclass 891 non-null int64
1 Sex 891 non-null str
2 Age 891 non-null float64
dtypes: float64(1), int64(1), str(1)
memory usage: 21.0 KB训练,评估。
demo.py
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
# 1. 加载数据.
data = pd.read_csv("./data/train.csv")
# data.info()
x = data[["Pclass", "Sex", "Age"]]
y = data["Survived"]
# 填充缺失值
# x["Age"].fillna({x["Age"]: x["Age"].mean()}, inplace=True)
x["Age"] = x["Age"].fillna(x["Age"].mean())
# 给 Sex 做 one-hot 编码
x = pd.get_dummies(x, columns=["Sex"])
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
# 训练
clf = DecisionTreeClassifier(max_depth=5)
clf.fit(x_train, y_train)
# 预测
y_pred = clf.predict(x_test)
# 评估
print(f"分类评估报告: \n {classification_report(y_test, y_pred)}")
# 可视化
plt.figure(figsize=(30, 20))
plot_tree(clf, filled=True, max_depth=5)
plt.savefig("./data/my_titanic.png")
plt.show()运行结果.txt
分类评估报告:
precision recall f1-score support
0 0.82 0.86 0.84 110
1 0.76 0.70 0.73 69
accuracy 0.80 179
macro avg 0.79 0.78 0.78 179
weighted avg 0.80 0.80 0.80 179