
外观
KNN 算法
KNN 算法,K Nearest Neighbor,简称 KNN。思想是使用 K 个临近的样本,这些样本与待测样本最相似。若这些样本中大多数属于某一个类别,那么待测样本也属于这个类别。
KNN 算法举例
| 序号 | 电影名称 | 搞笑镜头 | 拥抱镜头 | 打斗镜头 | 电影类型 |
|---|---|---|---|---|---|
| 1 | 功夫熊猫 | 39 | 0 | 31 | 喜剧片 |
| 2 | 叶问3 | 3 | 2 | 65 | 动作片 |
| 3 | 伦敦陷落 | 2 | 3 | 55 | 动作片 |
| 4 | 代理情人 | 9 | 38 | 2 | 爱情片 |
| 5 | 新步步惊心 | 8 | 34 | 17 | 爱情片 |
| 6 | 谍影重重 | 5 | 2 | 57 | 动作片 |
| 7 | 功夫熊猫 | 39 | 0 | 31 | 喜剧片 |
| 8 | 美人鱼 | 21 | 17 | 5 | 喜剧片 |
| 9 | 宝贝当家 | 45 | 2 | 9 | 喜剧片 |
| 10 | 唐人街探案 | 23 | 3 | 17 | ? |
我们计算唐人街探案到每个样本间的欧式距离:
| 序号 | 电影名称 | 搞笑镜头 | 拥抱镜头 | 打斗镜头 | 电影类型 | 距离 | K=5时 |
|---|---|---|---|---|---|---|---|
| 1 | 功夫熊猫 | 39 | 0 | 31 | 喜剧片 | 21.47 | ✅️ |
| 2 | 叶问3 | 3 | 2 | 65 | 动作片 | 52.01 | |
| 3 | 伦敦陷落 | 2 | 3 | 55 | 动作片 | 43.42 | |
| 4 | 代理情人 | 9 | 38 | 2 | 爱情片 | 40.57 | |
| 5 | 新步步惊心 | 8 | 34 | 17 | 爱情片 | 34.44 | ✅️ |
| 6 | 谍影重重 | 5 | 2 | 57 | 动作片 | 43.87 | |
| 7 | 功夫熊猫 | 39 | 0 | 31 | 喜剧片 | 21.47 | ✅️ |
| 8 | 美人鱼 | 21 | 17 | 5 | 喜剧片 | 18.55 | ✅️ |
| 9 | 宝贝当家 | 45 | 2 | 9 | 喜剧片 | 23.43 | ✅️ |
| 10 | 唐人街探案 | 23 | 3 | 17 | ? | —— | ? |
欧式距离,就是两点间距离公式:
若两点在一维空间内:
若两点在二维空间内:
若两点在 n 维空间内:
其中:
- 为特征维度
- 为欧式距离
计算出待测数据和每个样本的所有距离,可以得到 5 个带有绿色对号标记的最相似样本。在这五个样本里面,有一个是爱情片,其他都是喜剧片,因此可以得出,唐人街探案为喜剧片。
K 值的选择
在上述示例中,K 值选择 5,即选择 5 个最临近的样本。
如果 K 值过小,相当于用较小领域的训练实例预测,容易受到异常点的影响,让整体模型变得复杂,容易发生过。
如果 K 值过大,相当于用较大领域的训练实例预测,会受到样本均衡的问题,且 K 值的增大就意味着整体的模型变得简单,容易发生欠拟合。
若 ,即 K 值等于样本训练的个数,则无论输入实例是什么,只会按训练集中最多的类别进行预测,会受到样本均衡的影响。
可通过交叉验证、网格搜索等方法调优此参数。
KNN 在分类和回归中的应用
特征空间:把样本用“特征向量”表示后,所有样本点所处的数学空间。它是由特征维度构成的坐标空间,每个样本在这个空间中都是一个点。
若一个样本在特征空间中的 k 个最相似的样本大多数属于某一个类别,则该样本也属于这个类别。样本间的相似性用欧氏距离计算,处理流程:
分类应用
- 计算未知样本到每一个训练样本的距离;
- 将训练样本根据距离大小升序排列;
- 取出距离最近的 k 个样本;
- 进行投票,统计 k 个样本中哪个类别的样本个数最多;
- 将未知的样本归属到出现次数最多的类别。
回归应用
- 计算未知样本到每一个训练样本的距离;
- 将训练样本根据距离大小升序排列;
- 取出距离最近的 K 个训练样本;
- 把这个 K 个样本的目标值计算其平均值;
- 作为将未知的样本预测的值。
使用 scikit-learn 和 KNN 计算
分类
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5)n_neighbors:查询默认使用的邻居数,即 KNN 算法中的 "K"。
# 用电影的例子
from pandas import DataFrame
from sklearn.neighbors import KNeighborsClassifier
x_train = DataFrame([[39, 0, 31], [3, 2, 65], [2, 3, 55], [9, 38, 2], [8, 34, 17], [5, 2, 57], [39, 0, 31], [21, 17, 5], [45, 2, 9]])
y_train = (["喜剧片", "动作片", "动作片", "爱情片", "爱情片", "动作片", "喜剧片", "喜剧片", "喜剧片"])
x_test = DataFrame([[23, 3, 17]])
model = KNeighborsClassifier()
model.fit(x_train, y_train)
y_predict = model.predict(x_test)
print(y_predict) # ["喜剧片"]代码步骤:先导入包,然后准备数据,接着实例化模型,然后训练模型,最后预测结果。
因为一个样本可能具有多个特征,所以 x_train 和 x_test 都要用双层列表。
[39, 0, 31]是一个样本,39、3、2 等是一个特征,“喜剧片”、“动作片”等是标签,x_test 为测试集,这里测试集只有一个,所以用[[23, 3, 17]]。>>> X = [[0], [1], [2], [3]] >>> y = [0, 0, 1, 1] >>> from sklearn.neighbors import KNeighborsClassifier >>> neigh = KNeighborsClassifier(n_neighbors=3) >>> neigh.fit(X, y) KNeighborsClassifier(...) >>> print(neigh.predict([[1.1]])) [0] >>> print(neigh.predict_proba([[0.9]])) [[0.666 0.333]]
回归
sklearn.neighbors.KNeighborsRegressor(n_neighbors=5)Classfier 表示分类,Regressor 表示回归。
# 电影票房预测
from pandas import DataFrame
from sklearn.neighbors import KNeighborsRegressor
# 特征:著名演员个数、片长、煽情片段个数
x_train = DataFrame([[5, 130, 6], [2, 95, 1], [3, 110, 2], [6, 145, 8], [4, 120, 4], [1, 90, 0], [7, 150, 9], [3, 105, 3]])
y_train = [980, 320, 450, 1200, 760, 210, 1500, 520]
x_test = DataFrame([[4, 125, 5]])
model = KNeighborsRegressor(n_neighbors=3)
model.fit(x_train, y_train)
y_predict = model.predict(x_test)
print("预测票房(百万):", y_predict) # [730.]距离度量方法
欧式距离
欧氏距离是最常用的一种距离度量方式,用于衡量两个点在欧几里得空间中的直线距离。直观理解:就是几何中“两点之间线段的长度”。
在 维空间中,点 和 之间的欧式距离为:
曼哈顿距离
也成为“城市街区距离”,源于曼哈顿城市街区横平竖直的特点。
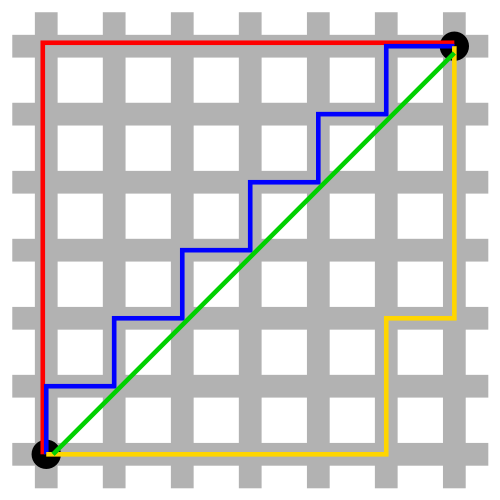
曼哈顿与欧几里得距离:红、蓝与黄线分别表示所有曼哈顿距离都拥有一样长度(12),而绿线表示欧几里得距离有 的长度。
在 维空间中,点 和 之间的曼哈顿距离为:
切比雪夫距离
国际象棋中,国王可以执行、横行、斜行,所以国王走一步可以移动到相邻 8 个方格中的任意一个。国王从格子 走到格子 走过的最少步数就是切比雪夫距离。
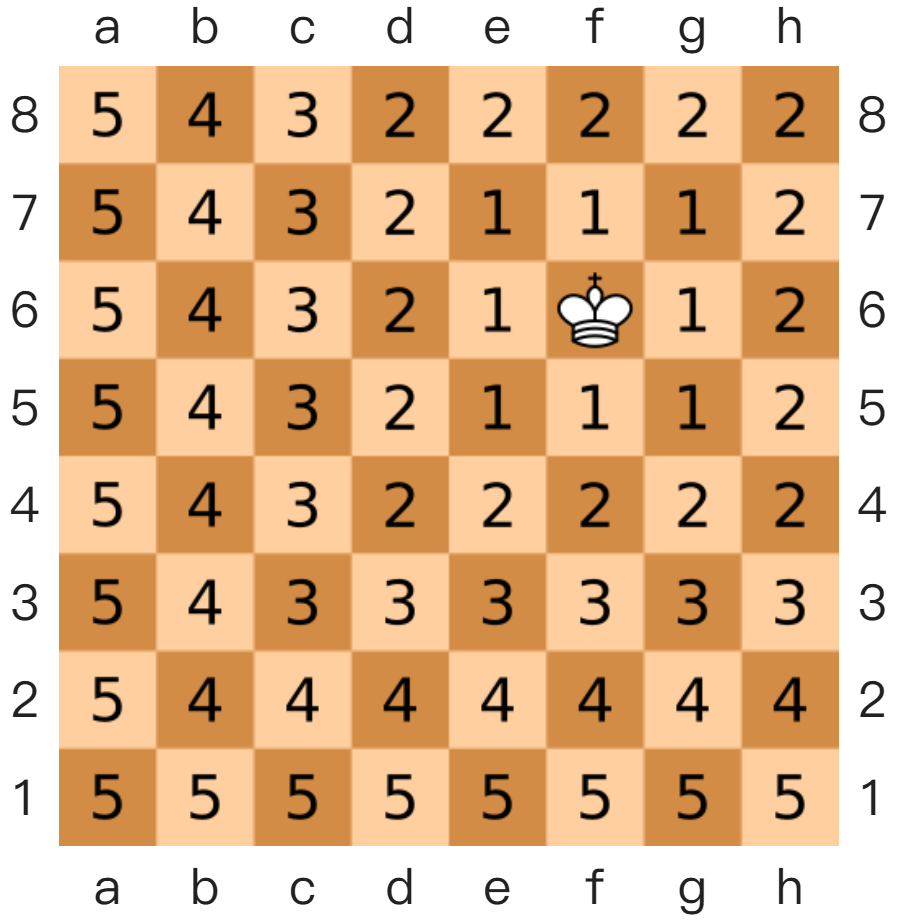
闵式距离
闵可夫斯基距离,不是一种新的距离的度量方式,而是距离的组合,是对多个距离度量公式的概括性的表述。
两个 维变量 和 间的闵可夫斯基距离定义为:
其中 是一个变参数:
- 时,此公式就是曼哈顿距离;
- 时,此公式就是欧氏距离;
- 时,此公式就是切比雪夫距离。
根据 的不同,闵式距离可表示某一类种的距离。
特征预处理
如果不同特征间量纲不同,取值范围有差异,容易影响目标检测的结果,模型(算法)会无法学到其他特征。
量纲:量纲是用来描述一个物理量或数值所依赖的基本单位类型,用于说明“这个量本质上属于什么类别”。
| 编号 | 身高(m) | 体重(kg) | 视力(0.2–2.0) | 健康状况 |
|---|---|---|---|---|
| 1 | 1.70 | 67 | 1.5 | 1 |
| 2 | 1.71 | 80 | 0.8 | 2 |
| 3 | 1.75 | 70 | 1.5 | 1 |
| 4 | 1.76 | 68 | 1.2 | 1 |
| 5 | 1.80 | 80 | 1.8 | 1 |
| 6 | 1.81 | 90 | 0.6 | 2 |
上个表格中,体重的单位是kg,对模型的预测影响很大,需要处理。
这里介绍两种常用的特征缩放方法,归一化和标准化。
归一化
思想是将原始数据变换为 之间,默认是 。
若映射范围是 ,公式为 ,如果自定义范围 ,则公式为 。
通过 sklearn 实现:
sklearn.preprocessing.MinMaxScaler(feature_range=(0, 1))feature_range: 缩放区间,默认是 。
此方法返回一个 MinMaxScaler 对象,使用这个对象的 fit_transform(data) 就可以对数据集进行归一化操作。
# 导包
from sklearn.preprocessing import MinMaxScaler # 归一化对象
# 1. 准备数据集(归一化之前的原数据).
x_train = [[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]]
# 2. 创建归一化对象.
# 参数feature_range 表示生成范围, 默认为: 0, 1 如果就是这个区间, 则参数可以省略不写.
transfer = MinMaxScaler()
# transfer = MinMaxScaler(feature_range=(3, 5))
# 3. 对原数据集进行归一化操作.
x_train_new = transfer.fit_transform(x_train)
# 4. 打印处理后的数据.
print("归一化后的数据集为: \n")
print(x_train_new)
# 归一化后的数据集为:
# [[1. 0. 0. 0. ]
# [0. 1. 1. 0.83333333]
# [0.5 0.5 0.6 1. ]]归一化受到最大值与最小值的影响,这种方法容易受到异常数据的影响,鲁棒性较差,适合传统精确小数据场景。
鲁棒性:鲁棒性指系统、模型或算法在存在噪声、异常、扰动或不确定性的情况下,仍能保持稳定性能和合理输出的能力。
标准化
通过对原始数据进行标准化,将数据转换为均值为 0 标准差为 1 的标准正态分布的数据。
公式:,其中 为样本平均值,也可用 代替; 为样本标准差。
通过 sklearn 实现:
sklearn.preprocessing.StandardScaler()此方法返回一个 StandardScaler 对象,和 MinMaxScaler 一样,使用 fit_transform(data) 就可以处理数据。
# 1.导入工具包
from sklearn.preprocessing import StandardScaler
# 2.数据(只有特征)
x = [[90, 2, 10, 40], [60, 4, 15, 45], [75, 3, 13, 46]]
# 3.实例化
process = StandardScaler()
# 4.fit_transform 处理
data = process.fit_transform(x)
# print(data)
print(process.mean_) # [75. 3. 12.66666667 43.66666667]
print(process.var_) # [150. 0.66666667 4.22222222 6.88888889]对于标准化来说,如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大。现代的机器学习场景中,数据集的规模会很大,我们多使用标准化处理数据,而不使用归一化。
KNN 超参数优化
交叉验证
交叉验证是优化超参数的一种方法。在 KNN 算法中,“K 个临近值”的“K”就是超参数。
单次切分数据集,结果依赖这一次划分的质量。而将数据多次拆分,结果更稳定,更接近真实泛化能力。
交叉验证的思想是将数据集分成 n 份,一份做测试集,n-1 做训练集,然后进行 n 次训练。第一次训练,将第一份数据集当测试集,其他当训练集;第二次训练,将第二份数据集当测试集,其他当训练集,以此类推。使用训练集和测试集多次评估模型,取平均值做交叉验证,即为模型得分。
| 折次 | 第1份 | 第2份 | 第3份 | 第4份 | 准确率 |
|---|---|---|---|---|---|
| 第1折 | 验证集 | 训练集 | 训练集 | 训练集 | 80% |
| 第2折 | 训练集 | 验证集 | 训练集 | 训练集 | 78% |
| 第3折 | 训练集 | 训练集 | 验证集 | 训练集 | 75% |
| 第4折 | 训练集 | 训练集 | 训练集 | 验证集 | 82% |
交叉验证法,是划分数据集的一种方法,目的是得到更加准确可信的模型评分。
网格搜索
模型有很多超参数,其能力也存在很大的差异。需要手动产生很多超参数组合,来训练模型每组超参数都采用交叉验证评估,最后选出最优参数组合建立模型。
只需要将若干参数传递给网格搜索对象,它自动帮我们完成不同超参数的组合、模型训练、模型评估,最终返回一组最优的超参数。
网格搜索通常内置交叉验证:
for 每个参数组合:
做K折交叉验证
计算平均得分
选择得分最高的参数网格搜索的思想是将所有参数穷举测试,如 n_neighbors ∈ {3,5,7}, weights ∈ {uniform, distance},组合为
(3,uniform)
(3,distance)
(5,uniform)
(5,distance)
(7,uniform)
(7,distance)每种组合都训练 + 评估 → 选最优。
| 项 | 交叉验证 | 网格搜索 |
|---|---|---|
| 作用 | 评估模型稳定性 | 找最优超参数 |
| 关注点 | 数据划分 | 参数组合 |
| 是否训练多次 | 是 | 是(更多) |
| 是否自动调参 | 否 | 是 |
具体实现
sklearn 的 GridSearchCV 类实现了网格搜索:
sklearn.preprocessing.GridSearchCV(estimator=模型, param_grid=参数字典, cv=交叉验证次数)from sklearn.datasets import load_iris # 加载鸢尾花测试集的.
from sklearn.model_selection import train_test_split, GridSearchCV # 分割训练集和测试集的, 寻找最优超参的(网格搜索 + 交叉验证).
from sklearn.preprocessing import StandardScaler # 数据标准化的
from sklearn.neighbors import KNeighborsClassifier # KNN算法 分类对象
from sklearn.metrics import accuracy_score # 模型评估的, 计算模型预测的准确率
# 1. 加载鸢尾花数据集.
iris_data = load_iris()
# 2. 数据预处理, 这里是: 切分训练集和测试集, 比例: 8:2
# 参1: 数据集的特征数据, 参数2: 数据集的标签数据, 参数3: 测试集的比例, 参数4: 随机种子.
x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=22)
# 3. 特征工程 -> 特征预处理 -> 标准化.
# 3.1 创建标准化对象.
transfer = StandardScaler()
# 3.2 对训练集和测试集的特征数据进行标准化.
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4. 模型训练.
# 4.1 创建 KNN分类对象.
estimator = KNeighborsClassifier()
# 4.2 定义字典, 记录 超参可能出现的情况(值).
param_dict = {'n_neighbors': [i for i in range(1, 11)]} # i的值: 1 ~ 10
# 4.3 创建 GridSearchCV对象 -> 寻找最优超参, 使用网格搜索 + 交叉验证方式
# 参1: 要计算最优超参的模型对象
# 参2: 该模型超参可能出现的值
# 参3: 交叉验证的折数, 这里的4折表示: 每个超参组合, 都会进行4次交叉验证. 这里共计是 4 * 10 = 40次.
# 返回值 estimator -> 处理后的模型对象.
estimator = GridSearchCV(estimator, param_dict, cv=4)
# 4.4 具体的模型训练动作.
estimator.fit(x_train, y_train)
# 4.5 打印最优超参组合.
print(f'最优评分: {estimator.best_score_}') # 0.9666666666666668
print(f'最优超参组合: {estimator.best_params_}') # {'n_neighbors': 3}
print(f'最优的估计器对象: {estimator.best_estimator_}') # KNeighborsClassifier(n_neighbors=3)
print(f'具体的交叉验证结果: {estimator.cv_results_}')
# 5. 模型评估.
# 5.1 获取最优超参的 模型对象.
# estimator = estimator.best_estimator_ # 获取最优的模型对象.
estimator = KNeighborsClassifier(n_neighbors=3)
# 5.2 模型训练.
estimator.fit(x_train, y_train)
# 5.3 模型预测.
y_pre = estimator.predict(x_test)
# 5.4 模型评估.
# 参1: 测试集. 参2: 预测集
print(f'准确率: {accuracy_score(y_test, y_pre)}') # 0.9666666666666667使用 KNN 算法对鸢尾花分类
莺尾花数据集介绍
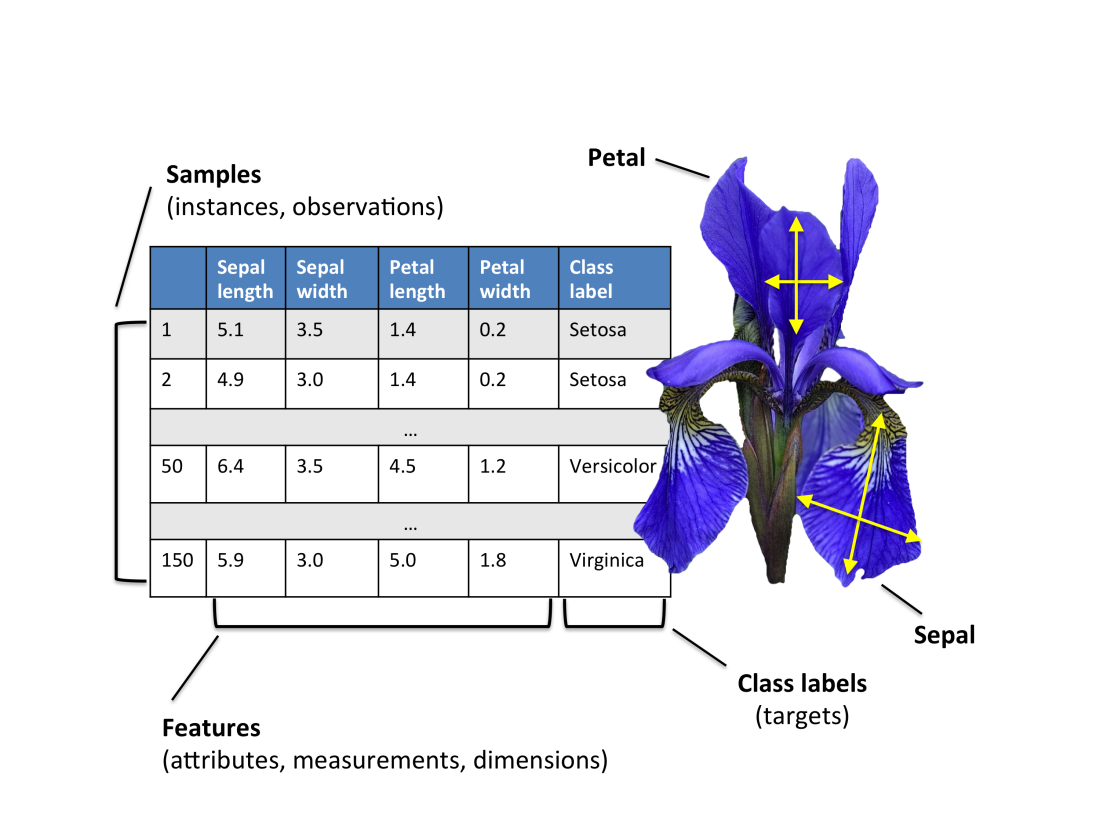
鸢尾花数据集是机器学习中最经典的入门数据集之一,常用于:分类算法演示、聚类算法演示、特征分析练习、可视化教学,属于监督学习中的多分类数据集。
它有四个特征字段:
| 特征名 | 含义 | 单位 |
|---|---|---|
| sepal length | 花萼长度 | cm |
| sepal width | 花萼宽度 | cm |
| petal length | 花瓣长度 | cm |
| petal width | 花瓣宽度 | cm |
有三个标签类别:
| 类别编号 | 类别名 |
|---|---|
| 0 | setosa(山鸢尾) |
| 1 | versicolor(变色鸢尾) |
| 2 | virginica(维吉尼亚鸢尾) |

demo.py
from sklearn.datasets import load_iris
dataset = load_iris()
print(f"查看数据集的前5行数据: \n{dataset.data[:5]}\n")
print(f"查看数据集的特征名称: {dataset.feature_names}\n")
print(f"查看数据集的标签名称: {dataset.target_names}\n")
print(f"查看数据集的标签值: \n{dataset.target}\n")
# print(f"查看数据集的描述信息: \n{dataset.DESCR}\n")
print(f"查看数据集的文件名: {dataset.filename}")运行结果.txt
查看数据集的前5行数据:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]
查看数据集的特征名称: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
查看数据集的标签名称: ['setosa' 'versicolor' 'virginica']
查看数据集的标签值:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
查看数据集的文件名: iris.csv莺尾花数据集可视化
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns # 用于可视化
from sklearn.datasets import load_iris
plt.rcParams["font.family"] = ["Times New Roman", "SimSun"] # 英文字体为新罗马,中文字体为宋体
plt.rcParams["font.serif"] = ["Times New Roman", "SimSun"] # 衬线字体
plt.rcParams["font.sans-serif"] = ["Times New Roman", "SimSun", "Arial", "SimHei"] # 无衬线字体,与Latex相关
plt.rcParams["mathtext.fontset"] = "custom" # 设置LaTeX字体为用户自定义,这里演示,就不用computer modern了
plt.rcParams["axes.unicode_minus"] = False
dataset = load_iris()
df = pd.DataFrame(dataset.data, columns=dataset.feature_names)
df["target"] = dataset.target
sns.lmplot(data=df, x="sepal length (cm)", y="sepal width (cm)", hue="target") # 绘制散点图
# plt.tight_layout()
plt.title("莺尾花数据集可视化")
plt.show()
分割数据集
将数据集分为测试集和数据集,要使用到 sklearn.model_selection.train_test_split函数。
def train_test_split(*arrays,
test_size=None,
train_size=None,
random_state=None,
shuffle=None) -> List:
...arrays: 要分割的数据,可以是 Python 列表、Numpy 数组、Scipy-Sparse矩阵、Pandas DataFrame。test_size: 测试集数量,如果是浮点数,则表示测试集的占比;如果是整数,则代表测试集的数量。train_size: 训练集数量,如果是浮点数,则表示训练集的占比;如果是整数,则代表训练集的数量。random_state: 随机种子,如果种子一致,生成的随机数一致,那么分割的结果也一致。shuffle: 是否打乱。
返回值跟 *arrays 参数有关。如果传入的是 train_test_split(A1, A2, A3, ..., AN),返回值就是 A1_train, A1_test, A2_train, A2_test, A3_train, A3_test, ..., AN_train, AN_test。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
dataset = load_iris()
print(f"数据集的类型为: {type(dataset.data)}") # <class 'numpy.ndarray'>
# 拆分数据集
x_train, x_test, y_train, y_test = train_test_split(dataset.data, dataset.target, test_size=0.2)
print(f"{len(x_train)=}, {len(x_test)=}, {len(y_train)=}, {len(y_test)=}")
# len(x_train)=120, len(x_test)=30, len(y_train)=120, len(y_test)=30模型训练
使用 sklearn.neighbors.KNeighborsClassifier 训练模型,并预测自定义数据。
demo.py
from sklearn.datasets import load_iris # 加载鸢尾花测试集的
from sklearn.model_selection import train_test_split # 分割训练集和测试集的
from sklearn.preprocessing import StandardScaler # 数据标准化的
from sklearn.neighbors import KNeighborsClassifier # KNN算法 分类对象
from sklearn.metrics import accuracy_score # 模型评估的, 计算模型预测的准确率
iris_data = load_iris()
# 2. 数据的预处理, 这里是把150条数据, 按照 8:2的比例, 切分训练集和测试集.
x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=23)
# 3. 特征工程(提取, 预处理...)
# 思考1: 特征提取: 因为源数据只有4个特征列, 且都是我们用的, 所以这里无需做特征提取.
# 思考2: 特征预处理: 因为源数据的4列特征差值不大, 所以我们无需做特征预处理, 但是, 加入特征预处理会让我们的代码更完善, 所以加入.
# 3.1 创建标准化对象.
transfer = StandardScaler()
# 3.2 对特征列进行标准化, 即: x_train: 训练集的特征数据, x_test: 测试集的特征数据.
# fit_transform: 兼具fit和transform的功能, 即: 训练, 转换. 该函数适用于: 第一次进行标准化的时候使用. 一般用于处理: 训练集.
x_train = transfer.fit_transform(x_train)
# transform: 只有转换. 该函数适用于: 重复进行标准化动作时使用, 一般用于对测试集进行标准化.
x_test = transfer.transform(x_test)
# 4. 模型训练.
# 4.1 创建模型对象.
estimator = KNeighborsClassifier(n_neighbors=3)
# 4.2 具体的训练模型的动作.
estimator.fit(x_train, y_train) # 传入: 训练集的特征数据, 训练集的标签数据
# 5. 模型预测.
# 场景1: 对刚才切分的 测试集(30条) 进行测试.
# 5.1 直接预测即可, 获取到: 预测结果
y_pre = estimator.predict(x_test) # x_test: 测试集的特征数据
# 5.2 打印预测结果.
print(f"预测值为: {y_pre}")
# 场景2: 对新的数据集(源数据150条 之外的数据) 进行测试.
# 5.1 自定义测试数据集.
my_data = [[7.8, 2.1, 3.9, 1.6]]
# 5.2 对数据集进行标准化处理.
my_data = transfer.transform(my_data)
# 5.3 模型预测.
y_pre_new = estimator.predict(my_data)
print(f"预测值为: {y_pre_new}")
# 5.4 查看上述数据集, 每种分类的预测概率.
y_pre_proba = estimator.predict_proba(my_data)
print(f"(各分类)预测概率为: {y_pre_proba}") # [[0, 0.66666667, 0.33333333]] -> 0分类的概率, 1分类的概率, 2分类的概率.
# 6. 模型评估.
# 方式1: 直接评分, 基于: 测试集的特征 和 测试集集的标签.
print(f"正确率(准确率): {estimator.score(x_test, y_test)}") # 0.9666666666666667
# 方式2: 基于 测试集的标签 和 预测结果 进行评分.
print(f"正确率(准确率): {accuracy_score(y_test, y_pre)}") # 0.9666666666666667运行结果.txt
预测值为: [2 2 1 0 2 1 0 2 0 1 1 0 2 0 0 1 1 1 2 0 2 0 0 0 2 0 0 2 1 1]
预测值为: [1]
(各分类)预测概率为: [[0. 0.66666667 0.33333333]]
正确率(准确率): 0.9666666666666667
正确率(准确率): 0.9666666666666667常见问题
为什么模型在做标准化的时候先使用 fit_transform(),后使用 transform()?
模型标准化的公式为:,这里需要一个 、,都需要从样本的数据中计算得出。在 sklearn 中,这些参数通过 StandardScaler 对象的 fit() 方法得出,内部会得到 mean_ 和 std_ 这两个值。transform() 方法是在 fit() 的基础上做运算,如果不先 fit(),会报错。fit_transform() 方法就是先 fit(),并将参数保存到对象内,再 transform()。
测试集必须只用 transform(),防止数据泄露。否则模型会“偷看数据”,导致测试集均值/方差被重新计算、测试集信息参与了参数生成,评估结果会被污染,泛化能力评估失真。
使用 KNN 算法完成手写数字识别
手写数字数据集,即 MNIST 手写数字识别数据集,于 1999 年发布,是机器学习中一个经典的数据集,至今仍被机器学习初学者使用,以及作为分类算法基准测试的基础。
数据集包括 60000 条训练数据和 10000 条测试数据,每一个样本都是一个 28×28 的灰度图,共 784 个像素。每个像素取值范围为 0~255,取值越大代表颜色越深。数据集共 785 列,第一列是标签,代表该行样本属于什么数字,其余列为 784 像素的像素值。
数据集可从网络上下载到。
绘制数字
绘制数字的目的是方便调试,这里给出代码。
import pandas as pd
from collections import Counter
import matplotlib.pyplot as plt
def show_digit(idx):
# 1. 读取数据集, 获取到源数据.
df = pd.read_csv("./手写数字识别.csv")
# print(df) # (42000行 * 785列)
# 2. 判断传入的索引是否越界.
if idx < 0 or idx > len(df) - 1:
print("索引越界!")
return
# 3. 走这里, 说明没有越界, 就正常获取数据.
x = df.iloc[:, 1:]
y = df.iloc[:, 0]
# 4. 查看用户传入的索引对应的图片 -> 是几?
print(f"该图片对应的数字是: {y.iloc[idx]}")
print(f"查看所有的标签的分布情况: {Counter(y)}")
# 5. 查看下 用户传入的索引对应的图片 的形状
print(x.iloc[idx].shape) # (784,) 我们要想办法把 (784,) 转换成 (28, 28)
# print(x.iloc[idx].values) # 具体的784个像素点数据
# 6. 把 (784,) 转换成 (28, 28)
x = x.iloc[idx].values.reshape(28, 28)
# print(x) # 28 * 28像素点
# 7. 具体的绘制灰度图的动作.
plt.imshow(x, cmap="gray") # 灰度图
plt.axis("off") # 不显示坐标轴
plt.show()
if __name__ == "__main__":
# 绘制数字
# show_digit(9)
# show_digit(20)
show_digit(99)训练模型
from matplotlib import pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import joblib
# 读取数据集
data = pd.read_csv("./手写数字识别.csv")
# 拆分特征列和标签列
x = data.drop("label", axis=1) # 特征
y = data["label"] # 标签
# 拆分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=21, stratify=y) # stratify=y 保持标签的比例(数据均衡)
# 特征归一化
x_train = x_train / 255
x_test = x_test / 255
# 模型训练
model = KNeighborsClassifier(n_neighbors=3)
# params = {"n_neighbors": range(1, 20), "metric": ["euclidean", "manhattan"]}
# model = GridSearchCV(model, params, cv=5)
model.fit(x_train, y_train)
# print(f'最佳参数: {model.best_params_}')
# 保存模型
joblib.dump(model, "./手写数字识别.pkl")
# 加载模型
model = joblib.load("./手写数字识别.pkl")
# 预测
y_pred = model.predict(x_test)
print(f"准确率: {accuracy_score(y_test, y_pred)}")
# 输入图片预测
x = plt.imread('./demo.png')
print(f"图片的数字是: {model.predict(x.reshape(1, -1))}")