
外观
RNN 模型变体
LSTM 模型
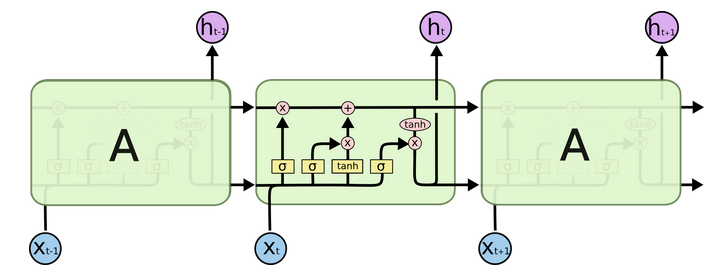
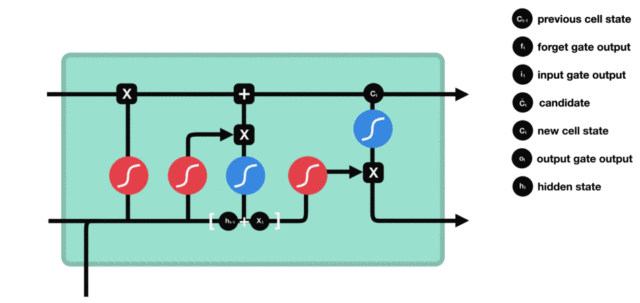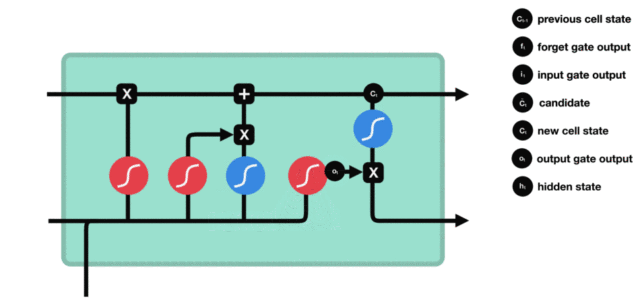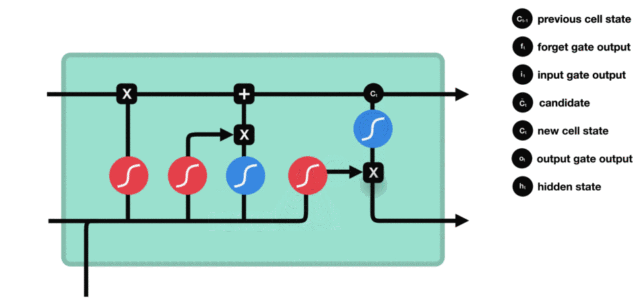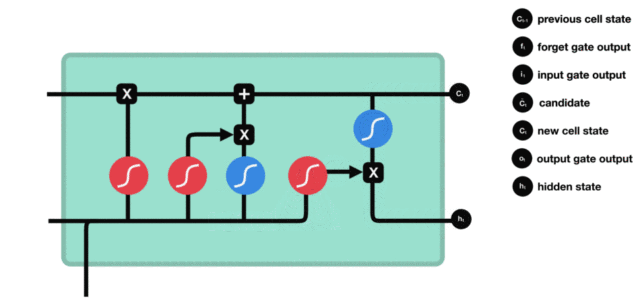
LSTM(Long Short-Term Memory)也称长短时记忆结构,它是传统 RNN 的变体,与经典 RNN 相比能够有效捕捉长序列之间的语义关联,缓解梯度消失或爆炸现象。同时 LSTM 的结构更复杂,它的核心结构可以分为四个部分去解析:
- 遗忘门
- 输入门
- 细胞状态
- 输出门
LSTM 的结构如下图所示:

遗忘门
首先来看遗忘门,遗忘门由下面的部分组成:
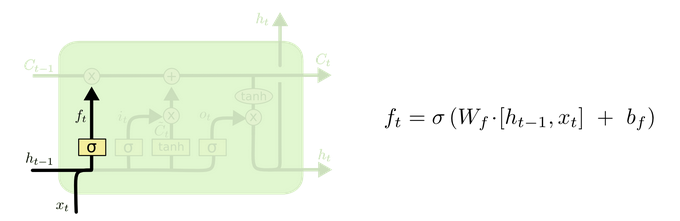
为激活函数。
与传统 RNN 的内部结构计算非常相似,首先将当前时间步输入 x(t) 与上一个时间步隐含状态 h(t-1) 拼接,得到[x(t), h(t-1)],然后通过一个全连接层做变换,最后通过 sigmoid 函数进行激活得到 f(t)。我们可以将 f(t) 看作是门值,好比一扇门开合的大小程度,门值都将作用在通过该扇门的张量。遗忘门门值将作用的上一层的细胞状态上,代表遗忘过去的多少信息,又因为遗忘门门值是由 x(t)、h(t-1) 计算得来的。因此整个公式意味着根据当前时间步输入和上一个时间步隐含状态 h(t-1) 来决定遗忘多少上一层的细胞状态所携带的过往信息。
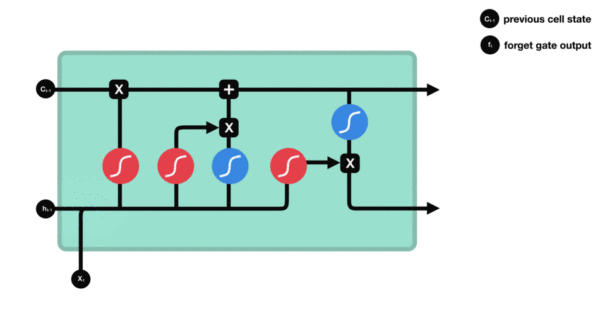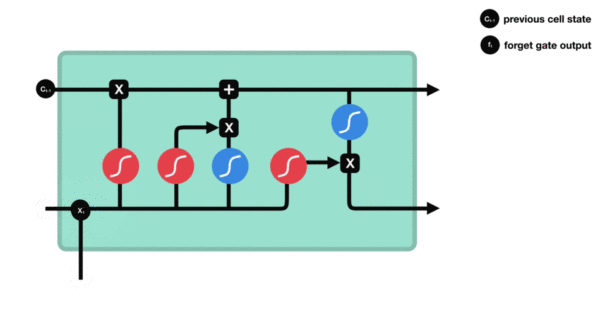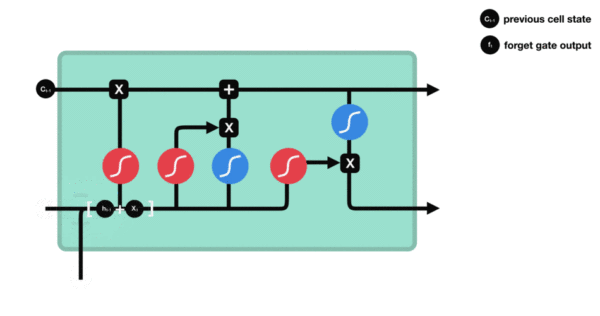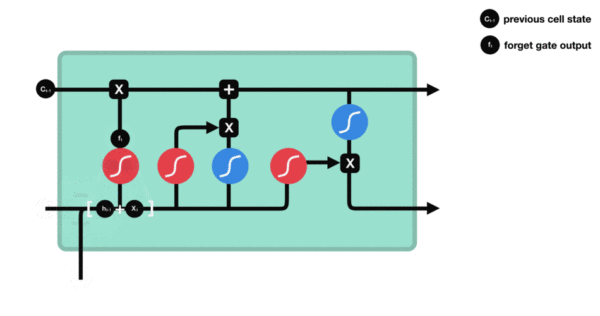
激活函数 sigmiod 用于帮助调节流经网络的值,sigmoid 函数将值压缩在 0 和 1 之间。
输入门
输入门的结构:
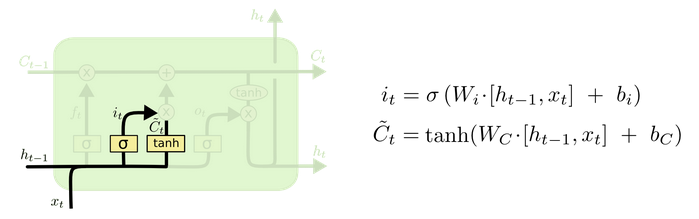
我们看到输入门的计算公式有两个,第一个就是产生输入门门值的公式,它和遗忘门公式几乎相同,区别只是在于它们之后要作用的目标上。这个公式意味着输入信息有多少需要进行过滤。输入门的第二个公式是与传统 RNN 的内部结构计算相同。对于 LSTM 来讲,它得到的是当前的细胞状态,而不是像经典 RNN 一样得到的是隐含状态。
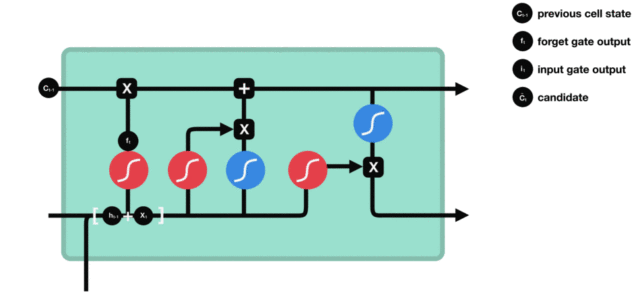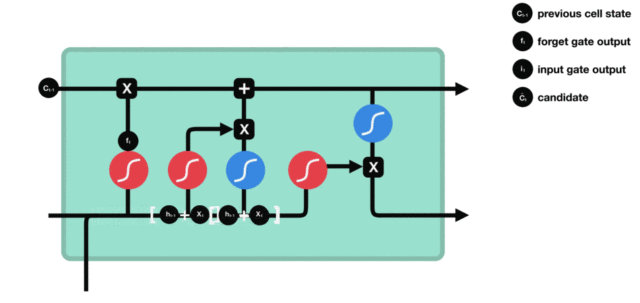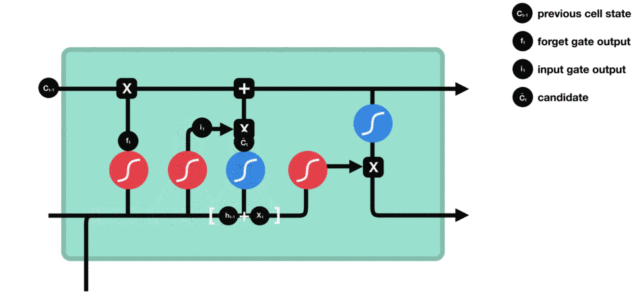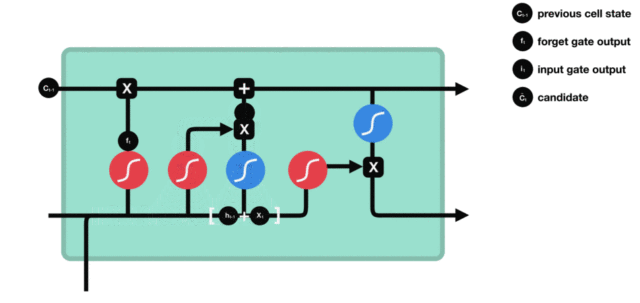
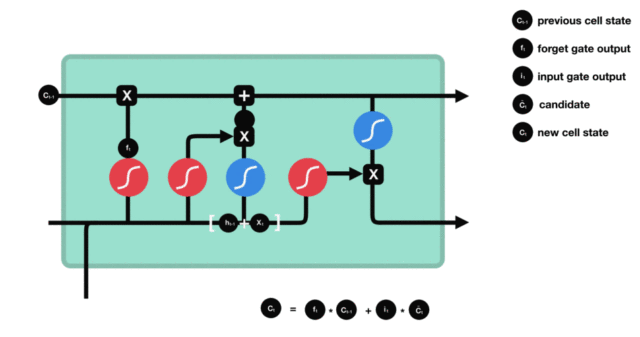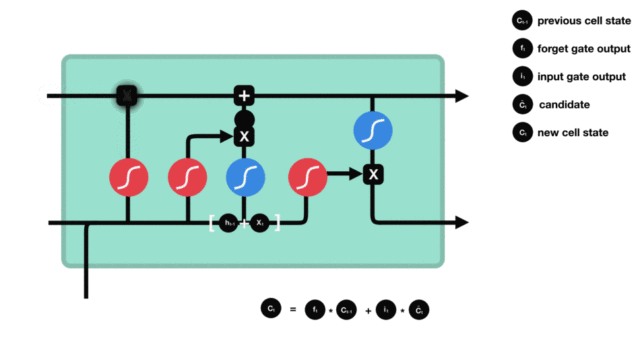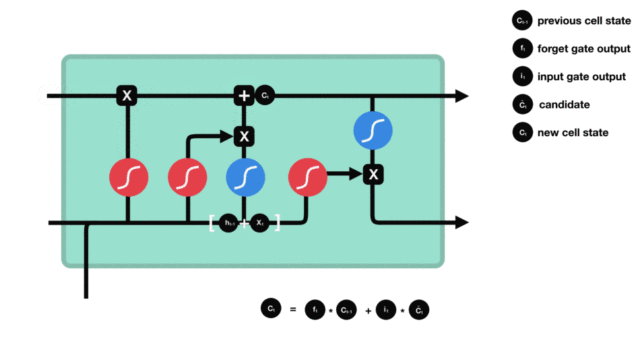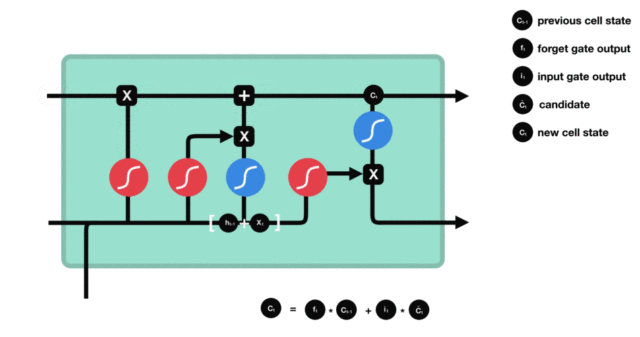
细胞状态
下图是细胞状态的更新图:
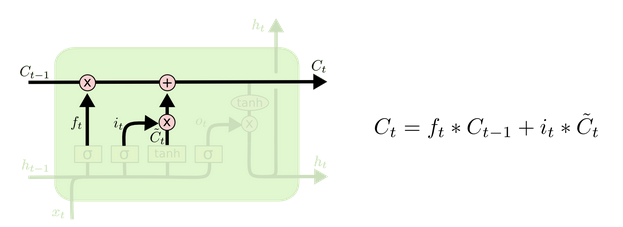
细胞更新的结构与计算公式非常容易理解,这里没有全连接层,只是将刚刚得到的遗忘门门值与上一个时间步得到的 C(t-1) 相乘,再加上输入门门值与当前时间步得到的未更新 C(t) 相乘的结果。最终得到更新后的 C(t) 作为下一个时间步输入的一部分。整个细胞状态更新过程就是对遗忘门和输入门的应用。
细胞状态更新图演示:
输出门
输出门结构与公式:
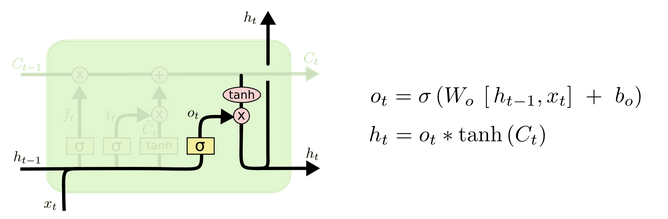
输出门部分的公式也是两个,第一个即是计算输出门的门值,它和遗忘门,输入门计算方式相同。第二个即是使用这个门值产生隐含状态 h(t),它将作用在更新后的细胞状态 C(t) 上,并做 tanh 激活,最终得到 h(t) 作为下一时间步输入的一部分。整个输出门的过程,就是为了产生隐含状态 h(t)。
输出门内部结构过程演示:
BiLSTM
Bi-LSTM 即双向LSTM,它没有改变 LSTM 本身任何的内部结构,只是将 LSTM 应用两次且方向不同,再将两次得到的 LSTM 结果进行拼接作为最终输出。
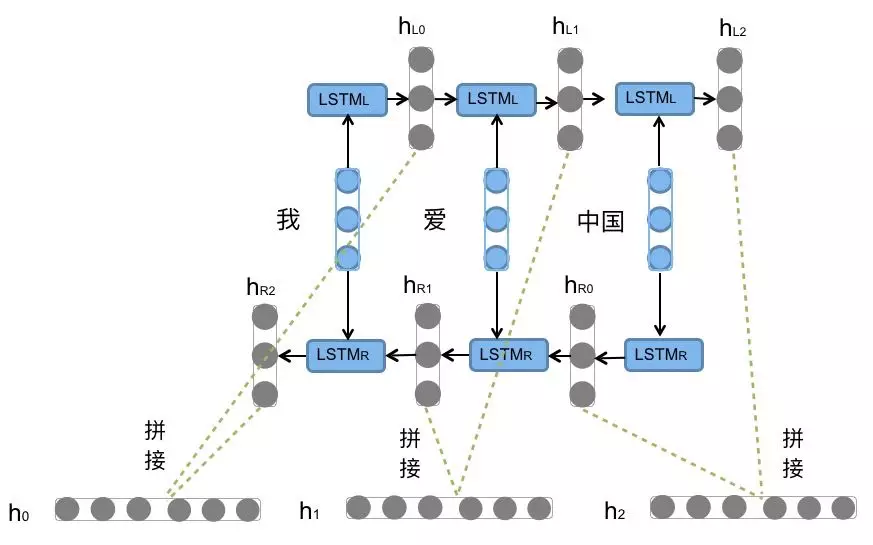
我们看到图中对“我爱中国”这句话或者叫这个输入序列,进行了从左到右和从右到左两次 LSTM 处理,将得到的结果张量进行了拼接作为最终输出。这种结构能够捕捉语言语法中一些特定的前置或后置特征,增强语义关联,但是模型参数和计算复杂度也随之增加了一倍,一般需要对语料和计算资源进行评估后决定是否使用该结构。
LSTM API
位置:在 torch.nn 工具包之中,通过 torch.nn.LSTM 可调用。
nn.LSTM 类初始化主要参数解释:
input_size:输入张量 x 中特征维度的大小。hidden_size:隐层张量 h 中特征维度的大小。num_layers:隐含层的数量。bidirectional:是否选择使用双向 LSTM,如果为 True,则使用;默认不使用。
nn.LSTM 类实例化对象主要参数解释:
input:输入张量 x。h0:初始化的隐层张量 h。c0:初始化的细胞状态张量 c。
nn.LSTM 使用示例:
# 定义LSTM的参数含义: (input_size, hidden_size, num_layers)
# 定义输入张量的参数含义: (sequence_length, batch_size, input_size)
# 定义隐藏层初始张量和细胞初始状态张量的参数含义:
# (num_layers * num_directions, batch_size, hidden_size)
>>> import torch.nn as nn
>>> import torch
>>> rnn = nn.LSTM(5, 6, 2)
>>> input = torch.randn(1, 3, 5)
>>> h0 = torch.randn(2, 3, 6)
>>> c0 = torch.randn(2, 3, 6)
>>> output, (hn, cn) = rnn(input, (h0, c0))
>>> output
tensor([[[ 0.0447, -0.0335, 0.1454, 0.0438, 0.0865, 0.0416],
[ 0.0105, 0.1923, 0.5507, -0.1742, 0.1569, -0.0548],
[-0.1186, 0.1835, -0.0022, -0.1388, -0.0877, -0.4007]]],
grad_fn=<StackBackward>)
>>> hn
tensor([[[ 0.4647, -0.2364, 0.0645, -0.3996, -0.0500, -0.0152],
[ 0.3852, 0.0704, 0.2103, -0.2524, 0.0243, 0.0477],
[ 0.2571, 0.0608, 0.2322, 0.1815, -0.0513, -0.0291]],
[[ 0.0447, -0.0335, 0.1454, 0.0438, 0.0865, 0.0416],
[ 0.0105, 0.1923, 0.5507, -0.1742, 0.1569, -0.0548],
[-0.1186, 0.1835, -0.0022, -0.1388, -0.0877, -0.4007]]],
grad_fn=<StackBackward>)
>>> cn
tensor([[[ 0.8083, -0.5500, 0.1009, -0.5806, -0.0668, -0.1161],
[ 0.7438, 0.0957, 0.5509, -0.7725, 0.0824, 0.0626],
[ 0.3131, 0.0920, 0.8359, 0.9187, -0.4826, -0.0717]],
[[ 0.1240, -0.0526, 0.3035, 0.1099, 0.5915, 0.0828],
[ 0.0203, 0.8367, 0.9832, -0.4454, 0.3917, -0.1983],
[-0.2976, 0.7764, -0.0074, -0.1965, -0.1343, -0.6683]]],
grad_fn=<StackBackward>)LSTM 优势:LSTM 的门结构能够有效减缓长序列问题中可能出现的梯度消失或爆炸,虽然并不能杜绝这种现象,但在更长的序列问题上表现优于传统 RNN。
LSTM 缺点:由于内部结构相对较复杂,因此训练效率在同等算力下较传统 RNN 低很多。
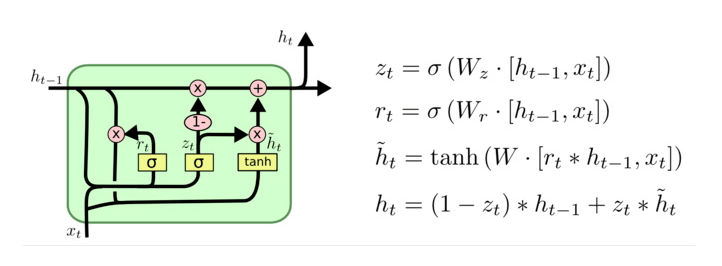
GRU 模型
GRU(Gated Recurrent Unit)也称门控循环单元结构,它也是传统 RNN 的变体,同 LSTM 一样能够有效捕捉长序列之间的语义关联,缓解梯度消失或爆炸现象。同时它的结构和计算要比 LSTM 更简单,它的核心结构可以分为两个部分去解析:
- 更新门
- 重置门
GRU 模型的结构如下:
GRU 的更新门和重置门结构:
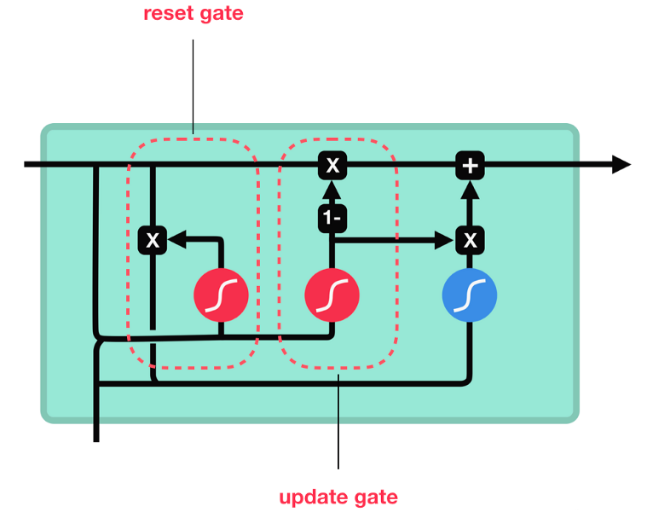
和之前分析过的 LSTM 中的门控一样,首先计算更新门和重置门的门值,分别是 z(t) 和 r(t),计算方法就是使用 X(t) 与 h(t-1) 拼接进行线性变换,再经过 sigmoid 激活。之后重置门门值作用在了 h(t-1) 上,代表控制上一时间步传来的信息有多少可以被利用。接着就是使用这个重置后的 h(t-1) 进行基本的 RNN 计算,即与 x(t) 拼接进行线性变化,经过 tanh 激活,得到新的 h(t)。最后更新门的门值会作用在新的 h(t),而 1 - 门值会作用在 h(t-1) 上,随后将两者的结果相加,得到最终的隐含状态输出 h(t),这个过程意味着更新门有能力保留之前的结果,当门值趋于 1 时,输出就是新的 h(t),而当门值趋于 0 时,输出就是上一时间步的 h(t-1)。
Bi-GRU 介绍
Bi-GRU 与 Bi-LSTM 的逻辑相同,都是不改变其内部结构,而是将模型应用两次且方向不同,再将两次得到的 LSTM 结果进行拼接作为最终输出。具体参见上小节中的 Bi-LSTM。
GRU API
位置:在 torch.nn 工具包之中,通过 torch.nn.GRU 可调用。
nn.GRU 类初始化主要参数解释:
input_size:输入张量 x 中特征维度的大小hidden_size:隐层张量 h 中特征维度的大小num_layers:隐含层的数量bidirectional:是否选择使用双向 LSTM,如果为True,则使用;默认不使用
nn.GRU 类实例化对象主要参数解释:
input:输入张量 xh0:初始化的隐层张量 h
nn.GRU 使用示例:
>>> import torch
>>> import torch.nn as nn
>>> rnn = nn.GRU(5, 6, 2)
>>> input = torch.randn(1, 3, 5)
>>> h0 = torch.randn(2, 3, 6)
>>> output, hn = rnn(input, h0)
>>> output
tensor([[[-0.2097, -2.2225, 0.6204, -0.1745, -0.1749, -0.0460],
[-0.3820, 0.0465, -0.4798, 0.6837, -0.7894, 0.5173],
[-0.0184, -0.2758, 1.2482, 0.5514, -0.9165, -0.6667]]],
grad_fn=<StackBackward>)
>>> hn
tensor([[[ 0.6578, -0.4226, -0.2129, -0.3785, 0.5070, 0.4338],
[-0.5072, 0.5948, 0.8083, 0.4618, 0.1629, -0.1591],
[ 0.2430, -0.4981, 0.3846, -0.4252, 0.7191, 0.5420]],
[[-0.2097, -2.2225, 0.6204, -0.1745, -0.1749, -0.0460],
[-0.3820, 0.0465, -0.4798, 0.6837, -0.7894, 0.5173],
[-0.0184, -0.2758, 1.2482, 0.5514, -0.9165, -0.6667]]],
grad_fn=<StackBackward>)GRU 的优势:GRU 和 LSTM 作用相同,在捕捉长序列语义关联时,能有效抑制梯度消失或爆炸,效果都优于传统 RNN,且计算复杂度相比 LSTM 要小。
GRU 的缺点:GRU 仍然不能完全解决梯度消失问题,同时其作为 RNN 的变体,有着 RNN 结构本身的一大弊端,即不可并行计算,这在数据量和模型体量逐步增大的未来,是 RNN 发展的关键瓶颈。
RNN 人名分类案例
案例:数据集格式为“人的姓氏 国家”,如“Lee Chinese”、“Daniel English”,代表当前姓氏所属的国家是哪一个。
数据集加载
数据集加载的步骤比较固定,都是原始数据 → 张量 → 自定义数据集对象 → 数据加载器。
import torch
from torch.utils.data import Dataset
all_letters = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
n_letters = len(all_letters)
categories = ["Chinese", "English", ...]
class NameClassDataset(Dataset):
def __init__(self, my_list_x, my_list_y):
self.my_list_x = my_list_x
self.my_list_y = my_list_y
self.sample_len = len(my_list_x)
def __len__(self):
return self.sample_len
def __getitem__(self, index):
index = min(max(index, 0), self.sample_len - 1)
x = self.my_list_x[index]
y = self.my_list_y[index]
tensor_x = torch.zeros(len(x), n_letters)
for idx, letter in enumerate(x):
letter_idx = all_letters.find(letter)
tensor_x[idx][letter_idx] = 1 # 做 onehot 编码
tensor_y = torch.tensor(categories.index(y), dtype=torch.long)
return tensor_x, tensor_y
def get_dataloader():
my_list_x, my_list_y = read_data('data/name_classfication.txt')
name_class_dataset = NameClassDataset(my_list_x, my_list_y)
my_dataloader = DataLoader(name_class_dataset, batch_size=1, shuffle=True)
for x, y in my_dataloader:
print(f'x.shape: {x.shape}, {x}')
print(f'y.shape: {y.shape}, {y}')搭建神经网络
import torch
from torch import nn
class My_RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1):
super().__init__()
self.input_size = input_size # 输入特征维度,和词汇表长度一致
self.hidden_size = hidden_size
self.output_size = output_size # 输出特征维度,和国家数量一致,因为输出的是每个国家的概率
self.num_layers = num_layers
self.rnn = nn.RNN(self.input_size, self.hidden_size, self.num_layers)
self.linear = nn.Linear(self.hidden_size, self.output_size)
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input, hidden):
input = input.unsqueeze(1)
output, hn = self.rnn(input, hidden)
tmp_output = output[-1]
tmp_output = self.linear(tmp_output)
return self.softmax(tmp_output), hn
def init_hidden(self):
return torch.zeros(self.num_layers, 1, self.hidden_size)模型训练
import torch
from torch import nn
from torch import optim
from torch.utils.data import DataLoader
from tqdm import tqdm
import time
epochs = 50
def train_rnn():
my_list_x, my_list_y = read_data("data/name_classfication.txt")
name_class_dataset = NameClassDataset(my_list_x, my_list_y)
input_size, n_hidden, output_size = 57, 128, 18
my_rnn = My_RNN(input_size, n_hidden, output_size)
criterion = nn.NLLLoss()
optimizer = optim.Adam(my_rnn.parameters(), lr=1e-2)
start_time = time.time()
total_iter_num = 0
total_loss = 0.0
total_loss_list = []
total_acc_num = 0
total_acc_list = []
for epoch in range(epochs):
print(f"\n开始第 {epoch + 1}/{epochs} 轮训练...")
train_dataloader = DataLoader(name_class_dataset, batch_size=1, shuffle=True)
for i, (x, y) in enumerate(tqdm(train_dataloader)):
output, hidden = my_rnn(x[0], my_rnn.init_hidden())
my_loss = criterion(output, y)
optimizer.zero_grad()
my_loss.backward()
optimizer.step()
total_iter_num += 1
total_loss += my_loss.item()
pred_tag = torch.argmax(output).item()
total_acc_num += 1 if pred_tag == y else 0
# 每一百次记录一次训练进度
if total_iter_num % 100 == 0:
avg_loss = total_loss / total_iter_num
total_loss_list.append(avg_loss)
avg_acc = total_acc_num / total_iter_num
total_acc_list.append(avg_acc)
# 每两千次记录一次训练进度
if total_iter_num % 2000 == 0:
avg_loss = total_loss / total_iter_num
end_time = int(time.time() - start_time)
print(f"轮次: {epoch + 1}, 训练的样本数: {total_iter_num}, 平均损失: {avg_loss:.5f}, 训练耗时:{end_time}秒, 准确率: {avg_acc:.3f}")
torch.save(my_rnn.state_dict(), f"./model/my_rnn_gz03_{epoch + 1}.bin")
total_time = int(time.time() - start_time)
print(f"\n训练完成, 总耗时: {total_time}秒, 共训练了 {total_iter_num} 个样本!")
return total_loss_list, total_time, total_acc_list模型预测
def lineToTensor(line):
tensor_x = torch.zeros(len(line), n_letters)
for i, letter in enumerate(line):
letter_idx = all_letters.find(letter)
tensor_x[i][letter_idx] = 1
return tensor_xdef dm_predict_run(x):
n_letters, n_hidden, n_categories = 57, 128, 18
x_tensor = lineToTensor(x)
my_rnn = My_RNN(n_letters, n_hidden, n_categories)
my_rnn.load_state_dict(torch.load(my_rnn_path))
with torch.no_grad():
output, hidden = my_rnn(x_tensor, my_rnn.init_hidden())
# 从预测结果中获取概率最高的3个类别
# k -> 取前3个最大的元素
# dim -> 获取最大值的维度, 即: 在第1维度(类别维度)上进行操作
# largest=True, 表示获取最大值
topv, topi = output.topk(3, 1, True)
print(f'rnn-> {x}')
for i in range(3):
value = topv[0][i].item() # 概率值(转换为: Python的标量)
category_idx = topi[0][i].item() # 类别索引
category = categorys[category_idx] # 类别名称
print(f'value: {value}, category: {category}')注意力机制介绍
以机器翻译任务为例:
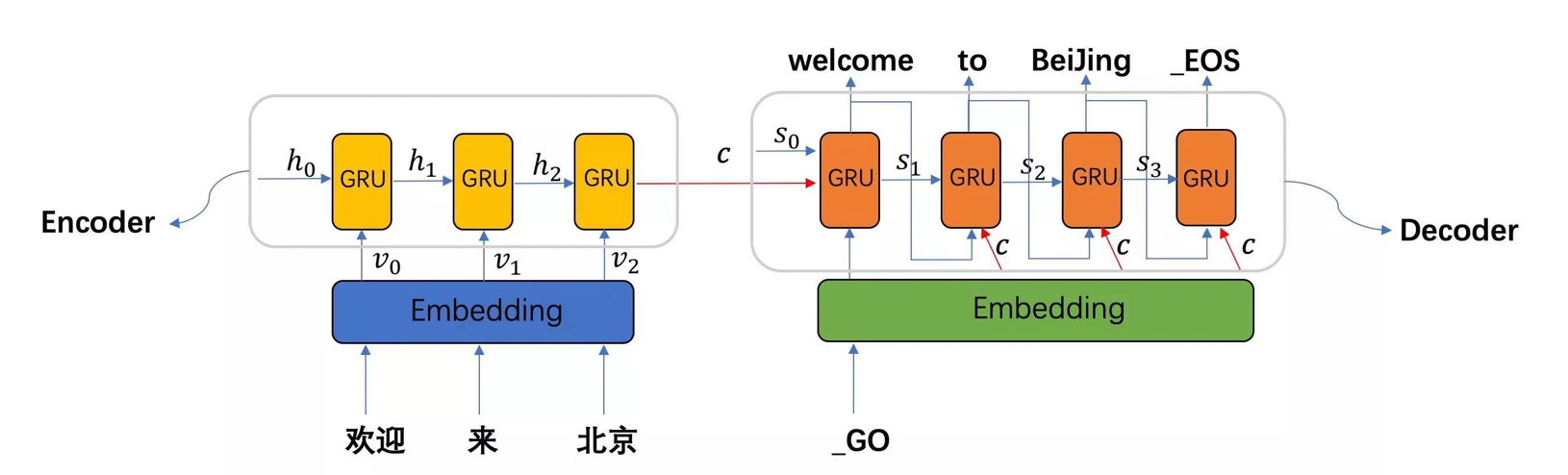
机器翻译的模型是一个 seq2seq 模型,它分为三部分:编码器、解码器、中间语义张量 c。
图中表示的是将“欢迎来北京”翻译成英文。编码器首先处理中文输入,通过 GRU 模型获得每个时间步的输出张量,再将它们拼接成中间语义张量 c,解码器将使用 c 以及每一个时间步的隐藏张量,逐个生成对应的翻译语言。
早期在解决机器翻译这一类 seq2seq 问题时,做法通常是利用一个编码器和一个解码器构建一个端到端的神经网络模型,但是它存在两个问题:
- 若翻译的句子很长,模型的计算量很大,准确率严重下降;
- 翻译时,一个词可能有不同的意思,但是网络对这些词向量没有区分度,没有考虑词与词的关联性,导致翻译效果比较差。
所以注意力机制被提出。
注意力机制早在上世纪九十年代就有研究,最早注意力机制应用在视觉领域,后来伴随着 2017 年 Transformer 模型结构的提出,注意力机制在 NLP、CV 相关问题的模型网络设计上被广泛应用。“注意力机制”实际上就是想将人的感知方式、注意力的行为应用在机器上,让机器学会去感知数据中的重要和不重要的部分。
同样的如果我们在机器翻译中,我们要让机器注意到每个词向量之间的相关性,有侧重地进行翻译,模拟人类理解的过程。
对于模型的每一个输入项,可能是图片中的不同部分,或者是语句中的某个单词分配一个权重,这个权重的大小就代表了我们希望模型对该部分一个关注程度。这样一来,通过权重大小来模拟人在处理信息的注意力的侧重,有效的提高了模型的性能,并且一定程度上降低了计算量。
深度学习中的注意力机制通常可分为三类:软注意(全局注意)、硬注意(局部注意)和自注意(内注意)。
- 软注意机制(Soft/Global Attention):对每个输入项的分配的权重为 0-1 之间,也就是某些部分关注的多一点,某些部分关注的少一点,因为对大部分信息都有考虑,但考虑程度不一样,所以相对来说计算量比较大。
- 硬注意机制(Hard/Local Attention,了解即可): 对每个输入项分配的权重非 0 即 1,和软注意不同,硬注意机制只考虑那部分需要关注,哪部分不关注,也就是直接舍弃掉一些不相关项。优势在于可以减少一定的时间和计算成本,但有可能丢失掉一些本应该注意的信息。
- 自注意力机制(Self/Intra Attention): 对每个输入项分配的权重取决于输入项之间的相互作用,即通过输入项内部的“表决”来决定应该关注哪些输入项。和前两种相比,在处理很长的输入时,具有并行计算的优势。
软注意力机制
- 需要注意:注意力机制是一种通用的思想和技术,不依赖于任何模型。换句话说,注意力机制可以用于任何模型。我们这里只是以文本处理领域的 Encoder-Decoder 框架为例进行理解。这里我们分别以普通 Encoder-Decoder 框架以及加 Attention 的 Encoder-Decoder 框架分别做对比。
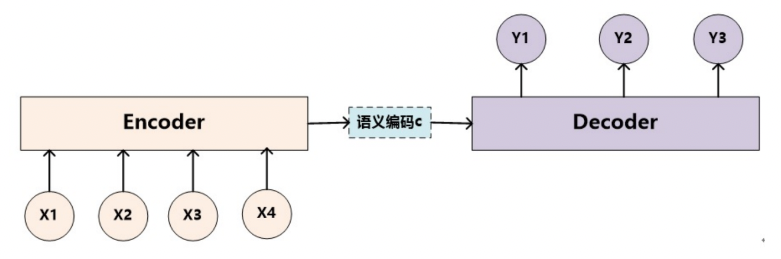
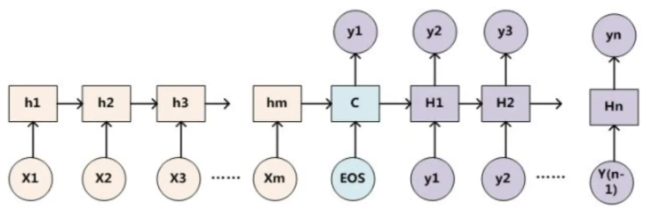
上图是 Encoder-Decoder 框架的一种抽象表示形式。
上图图例可以把它看作由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对,我们的目标是给定输入句子 Source,期待通过 Encoder-Decoder 框架来生成目标句子 Target。Source 和 Target 可以是同一种语言,也可以是两种不同的语言。而 Source 和 Target 分别由各自的单词序列构成:
Encoder 顾名思义就是对输入句子 Source 进行编码,将输入句子通过非线性变换转化为中间语义表示C:
对于解码器 Decoder 来说,其任务是根据句子 Source 的中间语义表示 C 和之前已经生成的历史信息,,,到 来生成 i 时刻要生成的单词 。
上述图中展示的 Encoder-Decoder 框架是没有体现出“注意力模型”的,所以可以把它看作是注意力不集中的分心模型。因为在生成目标句子的单词时,无论生成哪个单词,它们使用的输入句子 Source 的语义编码 C 都是一样的,没有任何区别。而语义编码 C 有事通过对 Source 经过 Edcoder 编码产生的。因此对于 target 中的任何一个单词,source 中任意单词对某个目标单词 来说影响力都是相同的,这就是为什么说图 1 中的模型没有体现注意力的原因。
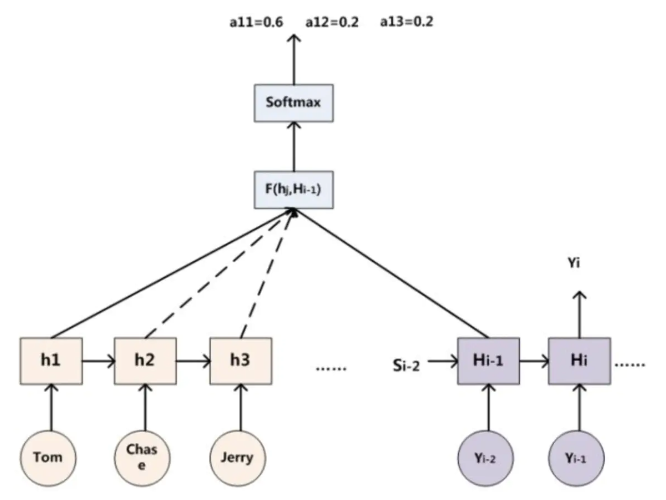
举例说明,为何添加 Attention:
比如机器翻译任务,输入 source 为:Tom chase Jerry,输出 target 为:“汤姆”,“追逐”,“杰瑞”。
在翻译“Jerry”这个中文单词的时候,普通 Encoder - Decoder 框架中,source 里的每个单词对翻译目标单词“杰瑞”贡献是相同的,很明显这里不太合理,显然“Jerry”对于翻译成“杰瑞”更重要。
如果引入 Attention 模型,在生成“杰瑞”的时候,应该体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:
(Tom,0.3)(Chase,0.2)(Jerry,0.5)
每个英文单词的概率代表了翻译当前单词“杰瑞”时,注意力分配模型分配给不同英文单词的注意力大小。
因此,基于上述例子所示,对于 target 中任意一个单词都应该有对应的 source 中的单词的注意力分配概率。而且,由于注意力模型的加入,原来在生成 target 单词时候的中间语义 C 就不再是固定的,而是会根据注意力概率变化的 C,加入了注意力模型的 Encoder - Decoder 框架就变成了图 2 所示。
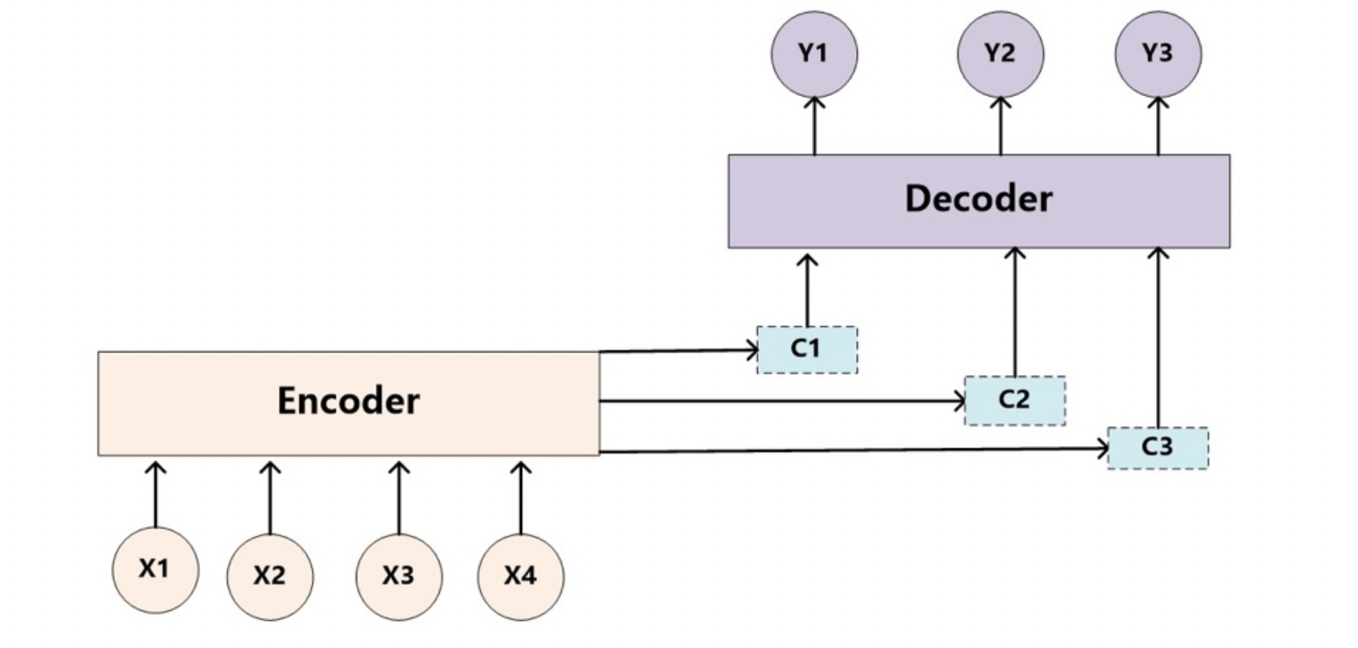
而每个 Ci 可能对应着不同的源语句子单词的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:
f2 函数代表 Encoder 对输入英文单词的某种变换函数。例如,如果 Encoder 使用的是 RNN 模型,那么 的输出通常对应某个时刻输入之后的隐藏层状态值。
代表 Encoder 根据单词的中间表示合成整个句子中间语义表示的变换函数。一般情况下, 函数采用的形式是对构成元素进行加权求和,即如下公式:
Lx 代表输入句子 source 的长度, 代表在 target 输出第 个单词时,source 输入句子中的第 个单词的注意力分配系数,而 则是 source 输入句子中第 个单词的语义编码。
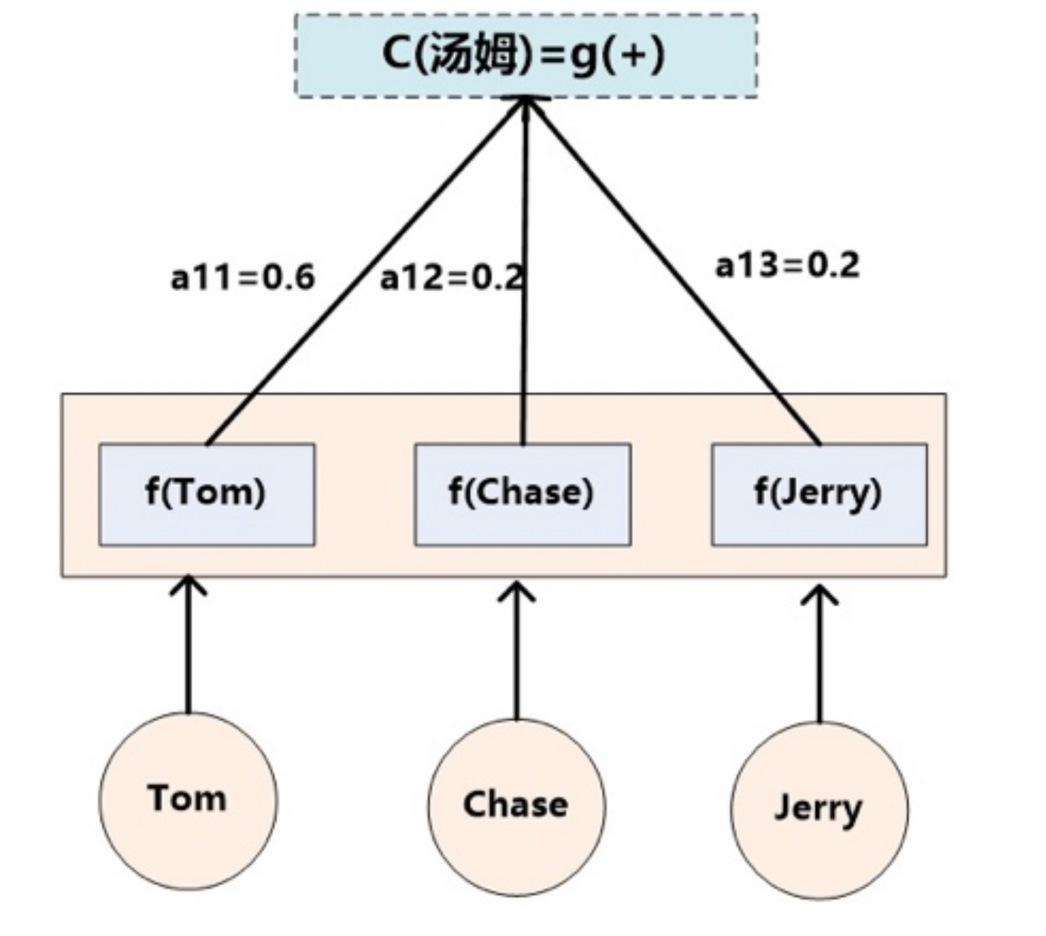
假设 下标 就是上面例子所说的“汤姆”,那么 ,,,,分别表示输入句子中每个单词的语义编码。
对应的注意力模型权值则分别是 0.6、0.2、0.2,所以 函数本质上就是加权求和函数。
如果形象表示的话,翻译中文单词“汤姆”的时候,数学公式对应的中间语义表示 的形成过程类似下图 3。
为了便于说明,我们假设Encoder-Decoder框架中,Encoder和Decoder都采用RNN模型,如下图4所示:
那么注意力分配概率分布值的通用计算过程如下:
上图中 表示 source 中第 个单词对应的隐层节点状态; 表示 target 中第 个单词的隐层节点状态。
注意力计算的是 target 中第 个单词对 source 中每个单词的对齐可能性,即 ,其中 可以采用不同的计算方式。
函数 的输出再经过 softmax 进行归一化,从而得到注意力分配的概率分布。
上面就是经典 Soft Attention 模型的基本思想,区别主要在于函数 的具体设计不同。
软注意力机制(Soft Attention)
核心思想:对所有输入位置分配连续概率权重(可微),再进行加权求和。
数学形式:
对于第 i 个 target:
特点:
- 权重是连续值(0~1)
- 所有输入位置都会参与计算
- 计算过程可微分,可以用反向传播直接训练
- 是 Encoder-Decoder Attention 和 Transformer 的基础形式
优点:
- 训练稳定
- 可并行优化
- 工业界主流方案
缺点:
- 计算复杂度较高(O(n²))
- 注意力分配是“软选择”,不够稀疏
硬注意力机制(Hard Attention)
核心思想:在输入中只选择一个或少数几个位置作为输出依据。
数学形式:
特点:
- 权重是离散的(0 或 1)
- 本质是选择或采样过程
- 不可直接微分
训练方法:
- 强化学习(REINFORCE)
- Gumbel-Softmax 近似
优点:
- 更符合“聚焦关键位置”的直觉
- 计算可能更稀疏
缺点:
- 训练不稳定
- 梯度方差大
- 工程上使用较少
自注意力机制(Self-Attention)
核心思想:序列内部的每个 token 之间两两计算关联关系。
数学形式:
其中:
- Q(Query):当前“要查询什么”
- K(Key):每个位置“提供什么信息索引”
- V(Value):每个位置“实际携带的信息内容”
特点:
- Q、K、V 来自同一个输入序列
- 每个 token 都会与其他所有 token 交互
- 支持并行计算
- 能建模长距离依赖关系
优点:
- 表达能力强
- 可并行计算
- 适合长序列建模
缺点:
- 计算复杂度 O(n²)
- 内存开销较大
注意力计算规则
注意力需要指定三个输入:QKV,通过计算公式得到的注意力的结果,代表 Query 在 Key 和 Value 作用下的注意力表示。当 Q=K=V 时,称为自注意力计算规则;当 QKV 不相等时称为一般注意力计算规则。
例子:seq2seq 架构翻译应用中的Q、K、V解释:
seq2seq 模型架构包括三部分,分别是 encoder(编码器)、decoder(解码器)、中间语义张量 c。
图中表示的是一个中文到英文的翻译:欢迎 来 北京 → welcome to BeiJing。编码器首先处理中文输入"欢迎 来 北京",通过 GRU 模型获得每个时间步的输出张量,最后将它们拼接成一个中间语义张量 c;接着解码器将使用这个中间语义张量 c 以及每一个时间步的隐层张量, 逐个生成对应的翻译语言.
在上述机器翻译架构中加入 Attention 的方式有两种:
第一种 tensorflow 版本(传统方式),如下图所示:
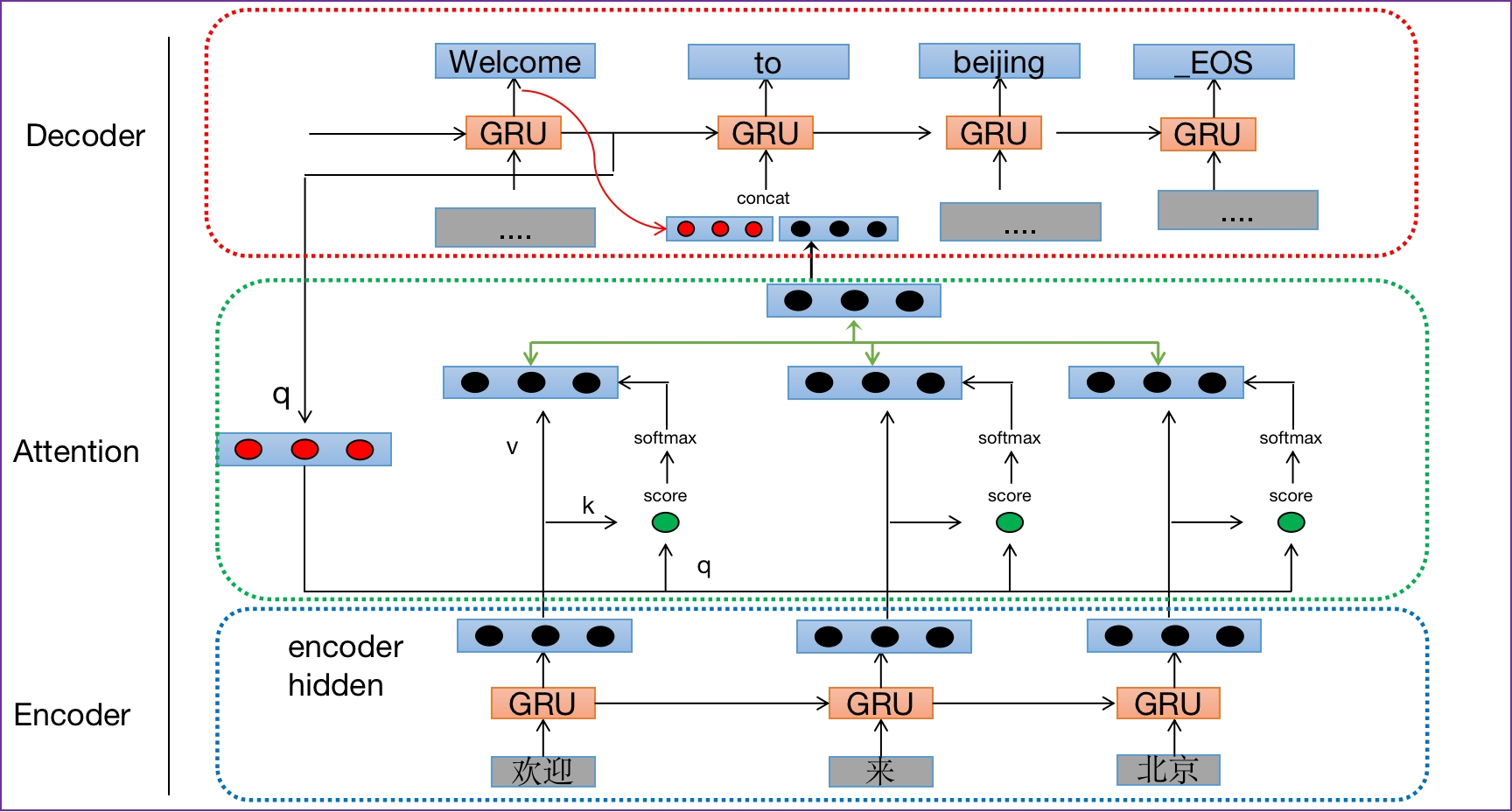
上图翻译应用中的 Q、K、V 解释:
- 查询张量 Q:解码器每一步输出或者是当前输入的 x
- 键张量 K:编码部分每个时间步的结果组合而成
- 值张量 V:编码部分每个时间步的结果组合而成
第二种 PyTorch 版本,改进版:
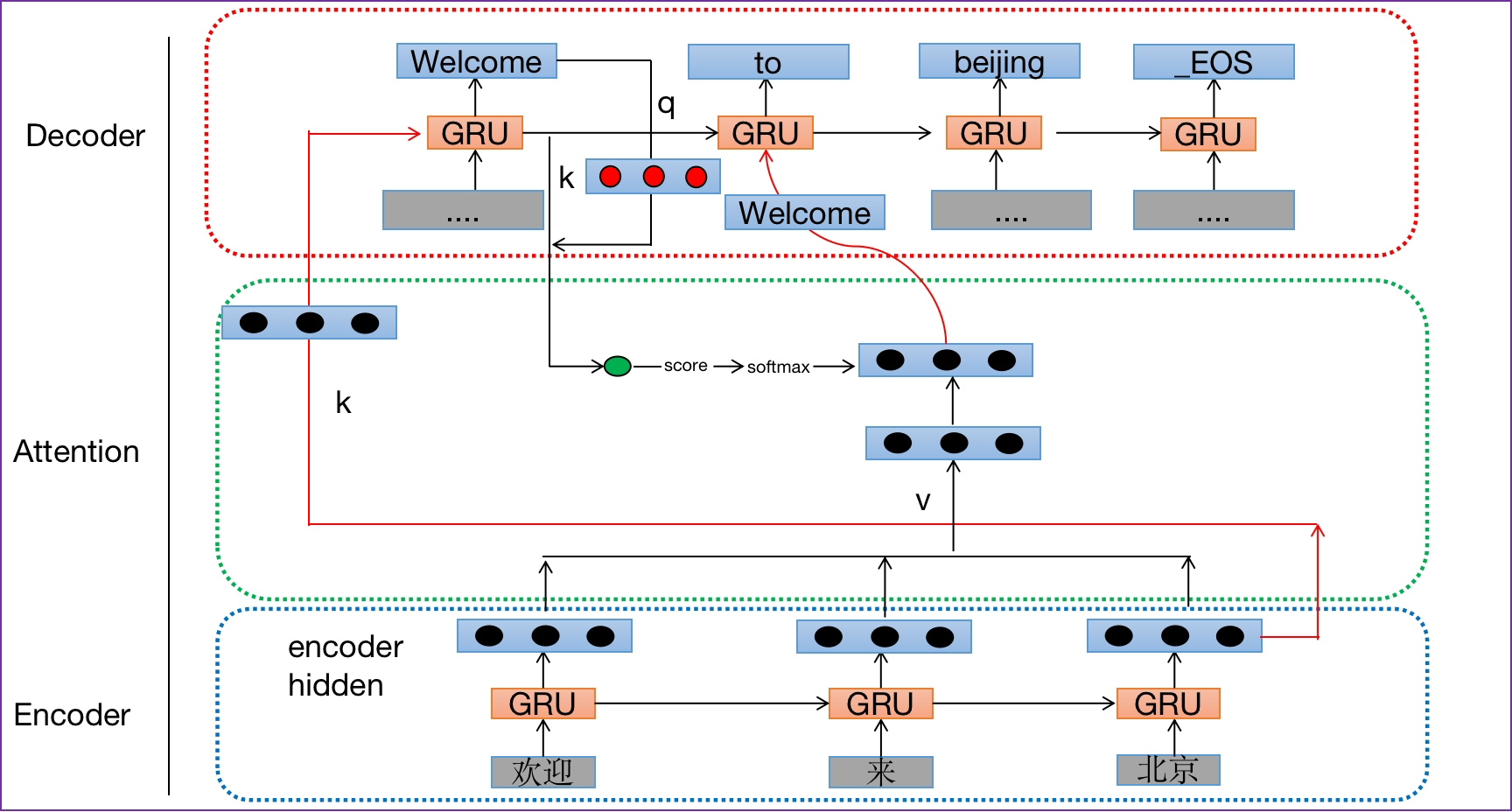
上图翻译应用中的Q、K、V解释
查询张量Q: 解码器每一步的输出或者是当前输入的x
键张量K: 解码器上一步的隐藏层输出
值张量V:编码部分每个时间步输出结果组合而成
两个版本对比:
pytorch版本的是乘型attention,tensorflow版本的是加型attention。pytorch这里直接将与上一个unit隐状态prev_hidden拼接起来✖W得到score,之后将score过softmax得到attenion_weights.
解码过程如下:
(1)采用自回归机制,比如:输入“go”来预测“welcome”,输入“welcome”来预测"to",输入“to”来预测“Beijing”。在输入“welcome”来预测"to"解码中,可使用注意力机制
(2)查询张量Q:一般可以是“welcome”词嵌入层以后的结果,查询张量Q为生成谁就是谁的查询张量(比如这里为了生成“to”,则查询张量就是“to”的查询张量,请仔细体会这一点)
(3) 键向量K:一般可以是上一个时间步的隐藏层输出
(4)值向量V:一般可以是编码部分每个时间步的结果组合而成
(5)查询张量Q来生成“to”,去检索“to”单词和“欢迎”、“来”、“北京”三个单词的权重分布,注意力结果表示(用权重分布 乘以内容V)
常见的注意力计算规则
将 Q,K 进行纵轴拼接,做一次线性变化,再使用 softmax 处理获得结果,最后与 V 做张量乘法。
将 Q,K 进行纵轴拼接,做一次线性变化后再使用 tanh 函数激活,然后再进行内部求和,最后使用 softmax 处理获得结果,再与 V 做张量乘法。
将 Q 与 K 的转置做点积运算,然后除以一个缩放系数,再使用 softmax 处理获得结果,最后与 V 做张量乘法。
说明:当注意力权重矩阵和 V 都是三维张量且第一维代表为 batch 条数时,则做 bmm 运算。bmm 是一种特殊的张量乘法运算。
bmm 运算演示:
# 如果参数1形状是(b × n × m), 参数2形状是(b × m × p), 则输出为(b × n × p)
>>> input = torch.randn(10, 3, 4)
>>> mat2 = torch.randn(10, 4, 5)
>>> res = torch.bmm(input, mat2)
>>> res.size()
torch.Size([10, 3, 5])深度神经网络注意力机制
注意力机制是注意力计算规则能够应用的深度学习网络的载体,同时包括一些必要的全连接层以及相关张量处理,使其与应用网络融为一体。使用自注意力计算规则的注意力机制称为自注意力机制。
说明:NLP 领域中,当前的注意力机制大多数应用于 seq2seq 架构,即编码器和解码器模型。
请思考:为什么要在深度神经网络中引入注意力机制?
- 1、RNN 等循环神经网络,随着时间步的增长,前面单词的特征会遗忘,造成对句子特征提取不充分。
- 2、RNN 等循环神经网络是一个时间步一个时间步地提取序列特征,效率低下。
- 3、研究者开始思考,能不能对 32 个单词(序列)同时提取事物特征,而且还是并行的,所以引入注意力机制!
注意力机制的作用
- 在解码器端的注意力机制:能够根据模型目标有效地聚焦编码器的输出结果,当其作为解码器的输入时提升效果,改善以往编码器输出是单一定长张量,无法存储过多信息的情况。
- 在编码器端的注意力机制:主要解决表征问题,相当于特征提取过程,得到输入的注意力表示,一般使用自注意力(self-attention)。
注意力机制在网络中实现的图形表示:
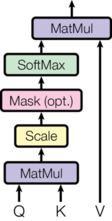
注意力机制实现步骤
- 第一步:根据注意力计算规则,对 Q,K,V 进行相应的计算。
- 第二步:根据第一步采用的计算方法,如果是拼接方法,则需要将 Q 与第二步的计算结果再进行拼接;如果是转置点积,一般是自注意力,Q 与 V 相同,则不需要进行与 Q 的拼接。
- 第三步:最后为了使整个 attention 机制按照指定尺寸输出,使用线性层作用在第二步的结果上做一个线性变换,得到最终对 Q 的注意力表示。
- 常见注意力机制的代码分析:
# 任务描述:
# 有QKV:v是内容比如32个单词,每个单词64个特征,k是32个单词的索引,q是查询张量
# 我们的任务:输入查询张量q,通过注意力机制来计算如下信息:
# 1、查询张量q的注意力权重分布:查询张量q和其他32个单词相关性(相识度)
# 2、查询张量q的结果表示:有一个普通的q升级成一个更强大q;用q和v做bmm运算
# 3 注意:查询张量q查询的目标是谁,就是谁的查询张量。
# eg:比如查询张量q是来查询单词"我",则q就是我的查询张量
import torch
import torch.nn as nn
import torch.nn.functional as F
# MyAtt类实现思路分析
# 1 init函数 (self, query_size, key_size, value_size1, value_size2, output_size)
# 准备2个线性层 注意力权重分布self.attn 注意力结果表示按照指定维度进行输出层 self.attn_combine
# 2 forward(self, Q, K, V):
# 求查询张量q的注意力权重分布, attn_weights[1,32]
# 求查询张量q的注意力结果表示 bmm运算, attn_applied[1,1,64]
# q 与 attn_applied 融合,再按照指定维度输出 output[1,1,32]
# 返回注意力结果表示output:[1,1,32], 注意力权重分布attn_weights:[1,32]
class MyAtt(nn.Module):
# 32 32 32 64 32
def __init__(self, query_size, key_size, value_size1, value_size2, output_size):
super(MyAtt, self).__init__()
self.query_size = query_size
self.key_size = key_size
self.value_size1 = value_size1
self.value_size2 = value_size2
self.output_size = output_size
# 线性层1 注意力权重分布
self.attn = nn.Linear(self.query_size + self.key_size, self.value_size1)
# 线性层2 注意力结果表示按照指定维度输出层 self.attn_combine
self.attn_combine = nn.Linear(self.query_size+self.value_size2, output_size)
def forward(self, Q, K, V):
# 1 求查询张量q的注意力权重分布, attn_weights[1,32]
# [1,1,32],[1,1,32]--> [1,32],[1,32]->[1,64]
# [1,64] --> [1,32]
# tmp1 = torch.cat( (Q[0], K[0]), dim=1)
# tmp2 = self.attn(tmp1)
# tmp3 = F.softmax(tmp2, dim=1)
attn_weights = F.softmax( self.attn(torch.cat( (Q[0], K[0]), dim=-1)), dim=-1)
# 2 求查询张量q的结果表示 bmm运算, attn_applied[1,1,64]
# [1,1,32] * [1,32,64] ---> [1,1,64]
attn_applied = torch.bmm(attn_weights.unsqueeze(0), V)
# 3 q 与 attn_applied 融合,再按照指定维度输出 output[1,1,64]
# 3-1 q与结果表示拼接 [1,32],[1,64] ---> [1,96]
output = torch.cat((Q[0], attn_applied[0]), dim=-1)
# 3-2 shape [1,96] ---> [1,32]
output = self.attn_combine(output).unsqueeze(0)
# 4 返回注意力结果表示output:[1,1,32], 注意力权重分布attn_weights:[1,32]
return output, attn_weights调用:
if __name__ == '__main__':
query_size = 32
key_size = 32
value_size1 = 32 # 32个单词
value_size2 = 64 # 64个特征
output_size = 32
Q = torch.randn(1, 1, 32)
K = torch.randn(1, 1, 32)
V = torch.randn(1, 32, 64)
# V = torch.randn(1, value_size1, value_size2)
# 1 实例化注意力类 对象
myattobj = MyAtt(query_size, key_size, value_size1, value_size2, output_size)
# 2 把QKV数据扔给注意机制,求查询张量q的注意力结果表示、注意力权重分布
output, attn_weights = myattobj(Q, K, V)
print('查询张量q的注意力结果表示output--->', output.shape, output)
print('查询张量q的注意力权重分布attn_weights--->', attn_weights.shape, attn_weights)输出效果:
查询张量q的注意力结果表示output---> torch.Size([1, 1, 32]) tensor([[[ 0.3135, -0.0539, 0.0597, -0.0046, -0.3389, -0.1238, 1.0385,
0.8896, -0.0268, -0.0705, -0.8409, 0.6547, 0.5909, -0.6048,
0.6303, -0.2233, 0.7678, -0.3140, 0.3635, -0.3234, -0.1053,
0.5845, 0.1163, -0.2203, -0.0812, -0.0868, 0.0218, -0.0597,
0.6923, -0.1848, -0.8266, -0.0614]]], grad_fn=<UnsqueezeBackward0>)
查询张量q的注意力权重分布attn_weights---> torch.Size([1, 32]) tensor([[0.0843, 0.0174, 0.0138, 0.0431, 0.0110, 0.0308, 0.0608, 0.0216, 0.0101,
0.0406, 0.0462, 0.0111, 0.0349, 0.0065, 0.0383, 0.0526, 0.0151, 0.0193,
0.0294, 0.0632, 0.0322, 0.0072, 0.0294, 0.0388, 0.0135, 0.0443, 0.0594,
0.0332, 0.0117, 0.0168, 0.0293, 0.0344]], grad_fn=<SoftmaxBackward0>)常见的注意力机制变体
在深度学习特别是大语言模型的发展过程中,为了优化计算效率、模型性能和显存占用,研究者提出了多种注意力机制的变体。下面介绍几种主流的注意力机制变体。
Multi-Head Attention (MHA, 多头注意力)
Multi-Head Attention 是 Transformer 模型的核心组件,最早由 Vaswani 等人在 2017 年提出。
核心思想:通过多组"头"并行地学习不同的注意力表示,每组头独立地关注序列中不同的位置和语义信息。
数学公式:
其中每个头的计算:
参数说明:
- :头的数量(如 8、12、16 等)
- :第 个头的 Query 投影矩阵
- :第 个头的 Key 投影矩阵
- :第 个头的 Value 投影矩阵
- :输出投影矩阵
- 通常
优势:
- 多视角表示:每个头可以学习序列中不同的依赖关系和模式
- 表达能力增强:多头机制丰富了模型的表示能力
- 并行计算:各头之间可以并行计算,训练效率高
缺点:
- 计算开销大:每个头都需要独立的 K、V 投影,KV Cache 存储成本高
- 显存占用高:推理时需要缓存所有头的 Key 和 Value
典型应用:
- Transformer (Vaswani et al., 2017)
- BERT、GPT 系列模型 -几乎所有现代大语言模型的基础
Multi-Query Attention (MQA, 多查询注意力)
MQA 由 Google 在 2019 年提出,旨在减少推理时的 KV Cache 显存占用。
核心思想:多个 Query 头共享同一组 Key 和 Value,每个 Query 头仍有独立的 Q 投影,但 K 和 V 只有一份(或很少几份),被所有头共享。
数学公式:
参数对比:
| 注意力类型 | Q 投影矩阵数 | K 投影矩阵数 | V 投影矩阵数 | KV Cache 大小 |
|---|---|---|---|---|
| MHA | h 个 | h 个 | h 个 | |
| MQA | h 个 | 1 个 | 1 个 |
其中 为序列长度, 为隐藏层维度。
优势:
- 显存占用大幅降低:推理时 KV Cache 减少到原来的
- 推理速度提升:减少了内存带宽压力
- 吞吐量增加:显存允许更大的 batch size
缺点:
- 表达能力可能下降:K、V 的信息被所有头共享,表示能力受限
- 需要更多训练技巧:可能需要更长的训练时间才能收敛
典型应用:
- PaLM (Google, 2022)
- LaMDA (Google)
- BLOOM (BigScience)
Grouped-Query Attention (GQA, 分组查询注意力)
GQA 由 Ainslie 等人在 2023 年提出,是 MHA 和 MQA 的折中方案。
核心思想:将 Query 头分成若干组,每组内的头共享同一组 K、V。既保留了 MHA 的表达能力,又减少了 MQA 的显存占用。
数学公式:
设有 个 Query 头,分为 组,每组有 个头。
其中 表示第 个头所属的组索引。
参数对比:
| 注意力类型 | Q 头数 | K/V 组数 | KV Cache 大小 | 性能 |
|---|---|---|---|---|
| MHA | h | h | 最优 | |
| MQA | h | 1 | 1 | 最差 |
| GQA | h | g | g | 中等 |
特殊案例:
- :退化为 MHA
- :退化为 MQA
- 常见配置: 或
优势:
- 性价比最优:在性能和显存之间取得平衡
- 灵活性高:可以通过调整 在性能和效率间权衡
- 实验效果好:在同等参数规模下,GQA 性能接近 MHA,远超 MQA
典型应用:
- LLaMA 2 & 3 (Meta)
- Mistral 系列
- Gemma (Google)
- Qwen 2 (Alibaba)
Multi-head Latent Attention (MLA, 多头潜在注意力)
MLA 由 DeepSeek 在 DeepSeek-V2 模型中提出(2024),是针对 MoE(混合专家)架构优化的注意力机制。
核心思想:通过低秩分解将 Key 和 Value 压缩到较小的潜在维度,大幅减少 KV Cache 显存占用,同时保持多头注意力的表达能力。
数学公式:
传统的 MHA:
MLA 引入压缩矩阵 和 (潜在维度 ):
其中:
- W^K_U, W^V^V \in \mathbb{R}^{d_{model} \times d_{lk}}:上投影矩阵
- :压缩后的 KV(用于缓存)
- 推理时只需缓存 ,维度远小于原始 K、V
同时保留解耦的 Query:
关键创新:
- KV 低秩分解:将 分解为 和 的乘积
- 潜在缓存:只缓存压缩后的 ,而非完整的 K、V
- 解耦设计:Query 保持多头结构,Key/Value 压缩到潜在空间
显存对比(假设 ):
| 注意力类型 | 单个 token 的 KV Cache | 相对大小 |
|---|---|---|
| MHA | bytes = 32KB | 100% |
| GQA (g=8) | bytes = 8KB | 25% |
| MLA | bytes = 4KB | 12.5% |
优势:
- 极致显存优化:KV Cache 减少到原来的 10% 左右
- 支持超长序列:在有限显存下支持更长的上下文
- 适合 MoE 架构:与混合专家模型配合,大幅提升吞吐量
- 保持性能:通过解耦设计保持了多头注意力的表达能力
缺点:
- 实现复杂:需要额外的上投影/下投影操作
- 训练开销:增加了模型结构的复杂度
典型应用:
- DeepSeek-V2 / V3 (DeepSeek)
- 专为 MoE + 长序列场景设计
Flash Attention
Flash Attention 由 Tri Dao 等人在 2022 年提出,是一种针对注意力计算算法层面的优化,而非架构层面的变体。
核心思想:通过分块计算(Tiling)和重计算(Recomputation),将注意力计算从 O(N²) 的内存访问复杂度优化为 O(N²) 的计算复杂度和 O(N) 的内存复杂度。
问题背景:
传统注意力计算的问题:
- 内存瓶颈:需要实例化 的注意力矩阵( 是序列长度)
- HBM(显存)带宽受限:反复读写 HBM,计算单元利用率低
例如:对于 的序列:
- 注意力矩阵大小: bytes = 16MB
- 每层都要多次读写这个矩阵
Flash Attention 解决方案:
分块计算(Tiling):
- 将 Q、K、V 分成小块(block),每个块大小适合 SRAM(静态随机存取存储器)
- 在 SRAM 内完成注意力计算,减少 HBM 访问
- 逐块更新输出,避免实例化完整注意力矩阵
在线 Softmax(Online Softmax):
- 使用在线算法(Online Algorithm)计算 Softmax
- 无需存储完整的注意力分数矩阵
- 逐步累加分子和分母
算法流程(简化版):
输入:Q, K, V (序列长度 N)
输出:O (注意力结果)
初始化:O = 0, m = -∞, l = 0
将 Q, K, V 分块为大小为 B_r, B_c 的块
for Q 的每个块 Q_i in SRAM:
for K, V 的每个块 K_j, V_j in SRAM:
# 计算 attention scores
S_j = Q_i @ K_j.T / sqrt(d)
# 更新 softmax 统计量
m_new = max(m, max(S_j, dim=-1))
l_new = exp(m - m_new) * l + exp(S_j - m_new).sum(dim=-1)
# 更新输出
O = exp(m - m_new) * O + exp(S_j - m_new) @ V_j
# 更新统计量
m = m_new
l = l_new优化效果:
| 指标 | 标准 Attention | Flash Attention |
|---|---|---|
| 时间复杂度 | O(N²d) | O(N²d) |
| 空间复杂度 | O(N²) | O(N) |
| HBM 访问 | O(N²) 次 | O(N²) 次(但每次块更小) |
| 实际速度 | 慢(内存受限) | 快 2-4x |
优势:
- 速度提升 2-4x:减少 HBM 访问,充分利用 GPU 算力
- 显存占用降低:无需存储完整注意力矩阵
- 支持更长序列:在有限显存下支持 2x-4x 更长上下文
- 完全兼容:不改变模型架构,即插即用
版本演进:
- Flash Attention 1 (2022):基础版本,仅支持前向
- Flash Attention 2 (2023):支持反向传播,算法进一步优化
- Flash Attention 3 (2024):针对 H100 GPU 优化,利用 Tensor Cores
典型应用:
- LLaMA 2/3、Mistral、Gemma 等所有现代大模型
- 长上下文模型(如 32k、128k、1M token)
- 训练和推理的标准配置
注意力机制对比总结
| 变体 | 提出时间 | 核心创新 | KV Cache | 性能 | 速度 | 应用场景 |
|---|---|---|---|---|---|---|
| MHA | 2017 | 多头并行 | h | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 通用,最常见 |
| MQA | 2019 | 共享 KV | 1 | ⭐⭐⭐ | ⭐⭐⭐⭐ | 推理优先 |
| GQA | 2023 | 分组 KV | g | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 性价比最优 |
| MLA | 2024 | 潜在压缩 | 极小 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | MoE + 长序列 |
| FlashAttention | 2022 | 算法优化 | -(算法层面) | 相同 | ⭐⭐⭐⭐⭐ | 所有场景必备 |
选择建议:
- 研究/通用:MHA + FlashAttention
- 生产环境:GQA + FlashAttention(最佳性价比)
- 极致推理:MLA + FlashAttention(配合 MoE)
- 长序列优先:任何架构 + FlashAttention
RNN 实现文本翻译
任务目的
目的:给定一段英文,翻译为法文 典型的文本分类任务:每个时间步去预测应该属于哪个法文单词
数据格式
注意:两列数据,第一列是英文文本,第二列是法文文本,中间用制表符号 "\t" 隔开
i am from brazil . je viens du bresil .
i am from france . je viens de france .
i am from russia . je viens de russie .
i am frying fish . je fais frire du poisson .
i am not kidding . je ne blague pas .实现流程
- 获取数据:案例中是直接给定的
- 数据预处理:脏数据清洗、数据格式转换、数据源 Dataset 的构造、数据迭代器 Dataloader 的构造
- 模型搭建:编码器和解码器等一系列模型
- 模型评估(测试)
- 模型上线 —— API 接口
数据预处理
定义样本清洗函数和构建字典
样本清洗函数:将脏数据进行清洗,以免影响模型训练
构建字典:一方面是为了将文本进行数字表示,还有一方面进行解码的时候将预测索引数字映射为真实的文本
样本清洗函数代码实现:
# 文本清洗工具函数
def normalizeString(s):
"""字符串规范化函数,参数 s 代表传入的字符串"""
s = s.lower().strip()
# 在 . ! ? 前加一个空格,这里的 \1 表示第一个分组(正则中的 \num)
s = re.sub(r"([.!?])", r" \1", s)
# s = re.sub(r"([.!?])", r" ", s)
# 使用正则表达式将字符串中不是大小写字母和正常标点的都替换成空格
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s构建字典代码实现:
def my_getdata():
# 1. 读取数据
with open(data_path, 'r', encoding='utf-8') as fr:
sentens_str = fr.read()
sentences = sentens_str.strip().split('\n')
# 2. 构建数据源 pair
my_pairs = [[normalizeString(s) for s in l.split('\t')] for l in sentences]
# 3.1 初始化两个字典
english_word2index = {"SOS": 0, "EOS": 1}
english_word_n = 2
french_word2index = {"SOS": 0, "EOS": 1}
french_word_n = 2
# 3.2 遍历 my_pairs
for pair in my_pairs:
for word in pair[0].split(' '):
if word not in english_word2index:
english_word2index[word] = english_word_n
english_word_n += 1
for word in pair[1].split(' '):
if word not in french_word2index:
french_word2index[word] = french_word_n
french_word_n += 1
english_index2word = {v: k for k, v in english_word2index.items()}
french_index2word = {v: k for k, v in french_word2index.items()}
return (
english_word2index,
english_index2word,
english_word_n,
french_word2index,
french_index2word,
french_word_n,
my_pairs
)构建 Dataset
目的:
使用 Pytorch 框架,一般遵从一个规矩:使用 Dataset 方法构造数据源,让模型进行使用。
构造数据源的过程中:必须继承 torch.utils.data.Dataset 类,必须构造两个魔法方法:__len__(),__getitem__()
__len__():一般返回样本的总个数,可以直接 len(dataset 对象) 获得结果
__getitem__():可以根据某个索引取出样本值,可以直接用 dataset[index] 获得结果
代码实现:
# 3. 构建数据源 Dataset
class Seq2SeqDaset(Dataset):
def __init__(self, my_pairs):
self.my_pairs = my_pairs
self.sample_len = len(my_pairs)
def __len__(self):
return self.sample_len
def __getitem__(self, index):
# 1. index 异常值处理 [0, self.sample_len-1]
index = min(max(index, 0), self.sample_len - 1)
# 2. 根据 index 取出样本数据
x = self.my_pairs[index][0]
y = self.my_pairs[index][1]
# 3. 文本数字化
x1 = [english_word2index[word] for word in x.split(' ')]
tensor_x = torch.tensor(x1, dtype=torch.long, device=device)
y1 = [french_word2index[word] for word in y.split(' ')]
y1.append(EOS_token)
tensor_y = torch.tensor(y1, dtype=torch.long, device=device)
return tensor_x, tensor_y构建 Dataloader
目的:为了将 Dataset 再次封装,变成一个可迭代对象,可以进行 for 循环,同时可以自动增加 batch 维度(batch_size),并支持随机打乱数据
代码实现:
# 4. 构建数据迭代器 dataloader
def get_dataloader():
# 1. 实例化 dataset
my_dataset = Seq2SeqDaset(my_pairs)
# 2. 实例化 dataloader
my_dataloader = DataLoader(dataset=my_dataset, batch_size=1, shuffle=True)
return my_dataloader模型搭建
搭建编码器 GRU 模型
注意事项:GRU 模型默认 batch_first = False,需要注意输入数据形状。 dataloader 返回 x 的形状为 [batch_size, seq_len, input_size]。这里使用 batch_first = True,方便直接对接输入。
代码实现:
# 5. 构建 GRU 编码器模型
class EncoderGRU(nn.Module):
def __init__(self, vocab_size, hidden_size):
super().__init__()
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.embed = nn.Embedding(self.vocab_size, self.hidden_size)
self.gru = nn.GRU(self.hidden_size, self.hidden_size, batch_first=True)
def forward(self, input, hidden):
input_x = self.embed(input)
output, hidden = self.gru(input_x, hidden)
return output, hidden
def inithidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)搭建解码器(无 Attention)
class DecoderGRU(nn.Module):
def __init__(self, vocab_size, hidden_size):
super().__init__()
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.embed = nn.Embedding(self.vocab_size, self.hidden_size)
self.gru = nn.GRU(self.hidden_size, self.hidden_size, batch_first=True)
self.out = nn.Linear(self.hidden_size, self.vocab_size)
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input, hidden):
input_x = self.embed(input)
input_x = F.relu(input_x)
output, hidden = self.gru(input_x, hidden)
output = self.out(output[0])
return self.softmax(output), hidden
def inithidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)搭建带 Attention 的解码器
注意事项:
Attention 需要三个参数:Q、K、V
- Q:上一时间步预测结果
- K:上一时间步隐藏状态
- V:编码器输出
核心公式:
class AttentionDecoderGRU(nn.Module):
def __init__(self, vocab_size, hidden_size, dropout_p=0.1, max_length=MAX_LENGTH):
super().__init__()
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.dropout_p = dropout_p
self.max_length = max_length
self.embed = nn.Embedding(self.vocab_size, self.hidden_size)
self.attn = nn.Linear(self.hidden_size * 2, self.max_length)
self.droupout = nn.Dropout(p=self.dropout_p)
self.attn_combin = nn.Linear(self.hidden_size * 2, self.hidden_size)
self.gru = nn.GRU(self.hidden_size, self.hidden_size, batch_first=True)
self.out = nn.Linear(self.hidden_size, self.vocab_size)
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input, hidden, encoder_output):
input_x = self.embed(input)
input_x = self.droupout(input_x)
attn_weight = F.softmax(
self.attn(torch.cat((input_x[0], hidden[0]), dim=-1)),
dim=-1
)
attn_applied = torch.bmm(
attn_weight.unsqueeze(0),
encoder_output.unsqueeze(0)
)
output1 = self.attn_combin(
torch.cat((input_x[0], attn_applied[0]), dim=-1)
).unsqueeze(0)
relu_output = F.relu(output1)
gru_output, hidden = self.gru(relu_output, hidden)
output = self.out(gru_output[0])
return self.softmax(output), hidden, attn_weight
def inithidden(self):
return torch.zeros(1, 1, self.hidden_size, device=device)模型训练
1. 获取数据
2. 构建 Dataset
3. 构建 Dataloader
4. 实例化模型
5. 定义损失函数
6. 定义优化器
7. 训练循环(epoch + batch)
8. 反向传播与参数更新
9. 保存模型(代码保持结构,仅标点与空格规范化)
模型预测
1. 加载模型
2. 数据预处理
3. 输入模型
4. 生成预测结果核心逻辑:
with torch.no_grad():
# 前向推理,不计算梯度注意力公式: