
外观
神经网络基础
介绍
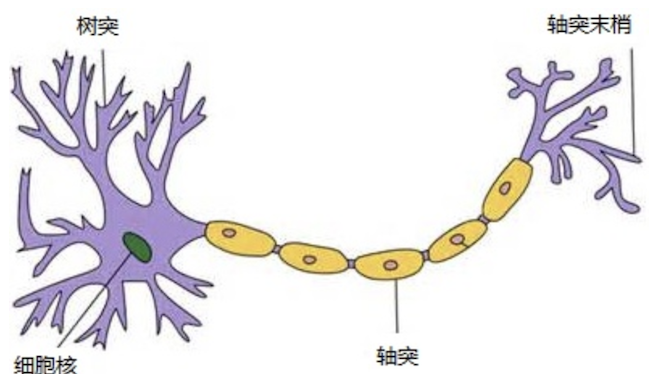
人工神经网络( Artificial Neural Network,简写为ANN)也简称为神经网络(NN),是一种模仿生物神经网络结构和功能的计算模型。人脑可以看做是一个生物神经网络,由众多的神经元连接而成。各个神经元传递复杂的电信号,树突接收到输入信号,然后对信号进行处理,通过轴突输出信号。
神经网络的优点有精度高、可以近似任意的非线性函数、生态丰富;缺点是黑箱、训练时间长、网络结构复杂,需要调整超参数、小数据集上表现不佳,容易过拟合。
本节介绍全连接神经网络,它适合处理以下任务:
- 结构化表格数据,因为有固定特征、无明显空间时间结构,如房屋属性->房屋价格;
- 已经向量化的特征数据,因为复杂的数据被转化为向量了,输入是 embedding 或特征工程后的结果,如图片 → 已提取特征(如 CNN 输出);
- 简单分类、回归问题;
- 低维或无结构数据,因为没有空间关系,没有序列依赖。
不适合处理的任务有:
| 数据类型 | 原因 |
|---|---|
| 图像 | 有空间结构 |
| 语音 | 有时序+频域结构 |
| 长文本 | 有上下文依赖 |
| 图数据 | 有拓扑结构 |
神经网络的运作方式
神经网络是由多个神经元组成,构建神经网络就是在构建神经元。
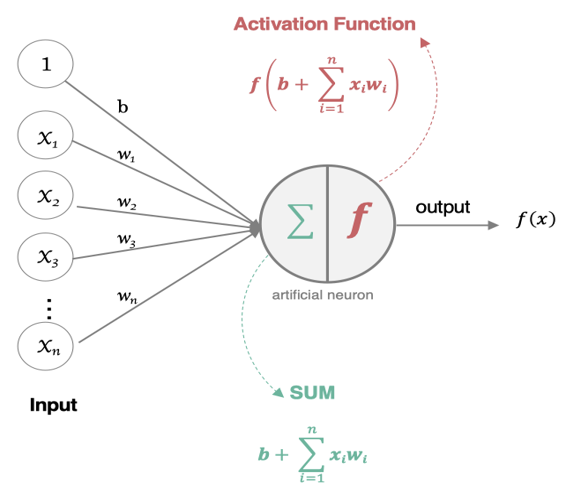
左边的 、、、、 是神经元的树突,也是样本的特征。、、、、 代表这些特征的权重。这些输入组成 做加和,再通过激活函数输出到 。
一个神经网络分为输入层、隐藏层和输出层。其中输入层,有多少个特征,就有多少个神经元;输出层,有多少个标签,就有多少个神经元。隐藏层可以有多个,它们组成一个整体。相邻的层之间,每对神经元都连接,所以这个也被称为全连接层,如下图。
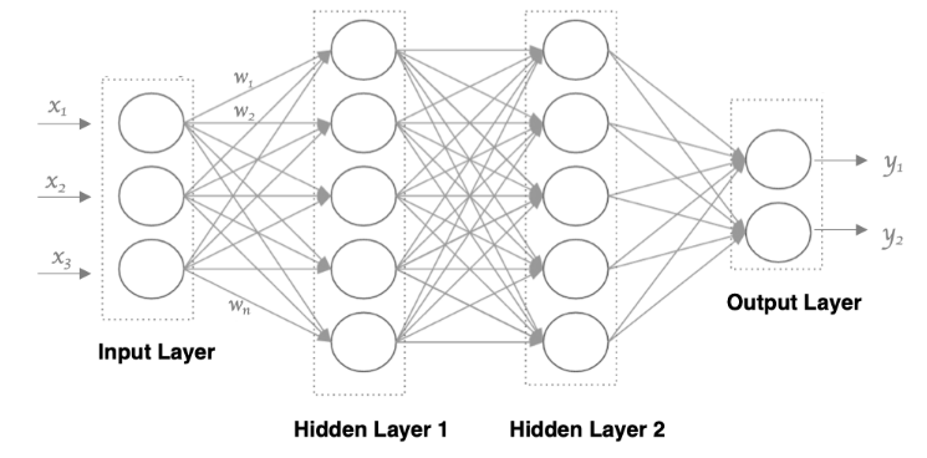
神经网络中信息只向一个方向移动,即从输入节点向前移动,通过隐藏节点,再向输出节点移动。其中的基本部分是:
- 输入层(Input Layer): 即输入x的那一层(如图像、文本、声音等)。每个输入特征对应一个神经元。输入层将数据传递给下一层的神经元。
- 输出层(Output Layer): 即输出y的那一层。输出层的神经元根据网络的任务(回归、分类等)生成最终的预测结果。
- 隐藏层(Hidden Layers): 输入层和输出层之间都是隐藏层,神经网络的“深度”通常由隐藏层的数量决定。隐藏层的神经元通过加权和激活函数处理输入,并将结果传递到下一层。
特点是:
- 同一层的神经元之间没有连接
- 第 N 层的每个神经元和第 N-1层 的所有神经元相连,这就是全连接神经网络
- 全连接神经网络接收的样本数据是二维的,数据在每一层之间需要以二维的形式传递
- 第N-1层神经元的输出就是第N层神经元的输入
- 每个连接都有一个权重值(w系数和b系数)
从输入到输出,叫做前向传播。
每一个神经元工作时,前向传播会产生两个值,内部状态值(加权求和值)和激活值;反向传播时会产生激活值梯度和内部状态值梯度。
内部状态值:神经元或隐藏单元的内部存储值,它反映了当前神经元接收到的输入、历史信息以及网络内部的权重计算结果。
:权重矩阵
:输入值
:偏置
激活值:通过激活函数(如 ReLU、Sigmoid、Tanh)对内部状态值进行非线性变换后得到的结果。激活值决定了当前神经元的输出。
- :激活函数
- :内部状态值
激活函数
激活函数用于对每层的输出数据进行变换,进而为整个网络注入了非线性因素。此时,神经网络就可以拟合各种曲线。
没有引入非线性因素的网络等价于使用一个线性模型。
通过给网络输出增加激活函数,能够实现引入非线性因素,使得网络模型可以逼近任意函数,提升网络对复杂问题的拟合能力。
Sigmoid 激活函数
求导:
图像:
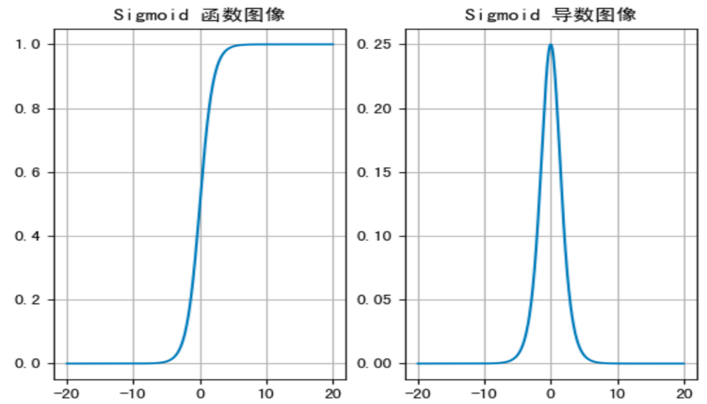
- sigmoid 函数可以将任意的输入映射到 (0, 1) 之间,当输入的值大致在 <-6 或者 >6 时,意味着输入任何值得到的激活值都是差不多的,这样会丢失部分的信息。比如:输入 100 和输出 10000 经过 sigmoid 的激活值几乎都是等于 1 的,但是输入的数据之间相差 100 倍的信息就丢失了。
- 对于 sigmoid 函数而言,输入值在 [-6, 6] 之间输出值才会有明显差异,输入值在 [-3, 3] 之间才会有比较好的效果。
- 通过上述导数图像,我们发现导数数值范围是 (0, 0.25),当输入 <-6 或者 >6 时,sigmoid 激活函数图像的导数接近为 0,此时网络参数将更新极其缓慢,或者无法更新。
- 一般来说,sigmoid 网络在 5 层之内就会产生梯度消失现象。而且,该激活函数并不是以 0 为中心的,所以在实践中这种激活函数使用的很少。sigmoid 函数一般只用于二分类的输出层。
绘制图像代码:
import torch
import matplotlib.pyplot as plt
# 创建画布和坐标轴
_, axes = plt.subplots(1, 2)
# 函数图像
x = torch.linspace(-20, 20, 1000)
# 输入值x通过sigmoid函数转换成激活值y
y = torch.sigmoid(x)
axes[0].plot(x, y)
axes[0].grid()
axes[0].set_title('Sigmoid 函数图像')
# 导数图像
x = torch.linspace(-20, 20, 1000, requires_grad=True)
torch.sigmoid(x).sum().backward()
# x.detach():输入值x的数值
# x.grad:计算梯度,求导
axes[1].plot(x.detach(), x.grad)
axes[1].grid()
axes[1].set_title("Sigmoid 导数图像")
plt.show()tanh 激活函数
导数:
图像:
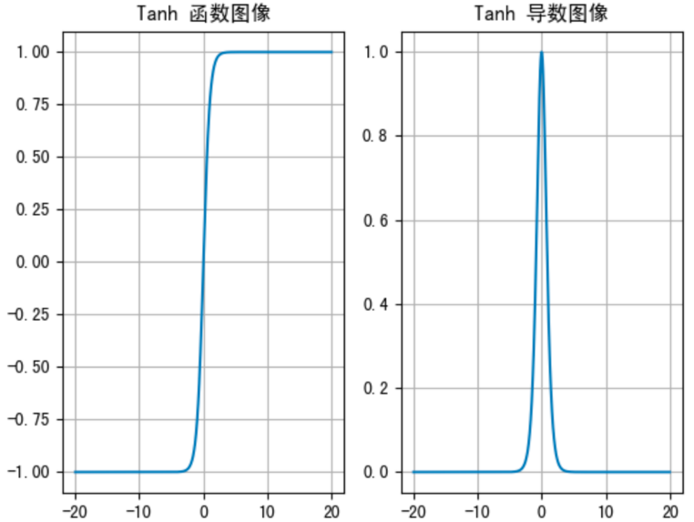
- Tanh 函数将输入映射到 (-1, 1) 之间,图像以 0 为中心,在 0 点对称,当输入 大概<-3 或者 >3 时将被映射为 -1 或者 1。其导数值范围 (0, 1),当输入的值大概 <-3 或者 > 3 时,其导数近似 0。
- 与 Sigmoid 相比,它是以 0 为中心的,且梯度相对于sigmoid大,使得其收敛速度要比 Sigmoid 快,减少迭代次数。然而,从图中可以看出,Tanh 两侧的导数也为 0,同样会造成梯度消失。
- 若使用时可在隐藏层使用 tanh 函数,在输出层使用 sigmoid 函数。
绘制图像代码:
import torch
import matplotlib.pyplot as plt
# 创建画布和坐标轴
_, axes = plt.subplots(1, 2)
# 函数图像
x = torch.linspace(-20, 20, 1000)
y = torch.tanh(x)
axes[0].plot(x, y)
axes[0].grid()
axes[0].set_title("Tanh 函数图像")
# 导数图像
x = torch.linspace(-20, 20, 1000, requires_grad=True)
torch.tanh(x).sum().backward()
axes[1].plot(x.detach(), x.grad)
axes[1].grid()
axes[1].set_title("Tanh 导数图像")
plt.show()ReLU 激活函数
导数:
图像:
- ReLU 激活函数将小于 0 的值映射为 0,而大于 0 的值则保持不变,它更加重视正信号,而忽略负信号,这种激活函数运算更为简单,能够提高模型的训练效率。
- 当 x<0 时,ReLU 导数为0,而当x>0时,则不存在饱和问题。所以,ReLU 能够在x>0时保持梯度不衰减,从而缓解梯度消失问题。然而,随着训练的推进,部分输入会落入小于0区域,导致对应权重无法更新。这种现象被称为“神经元死亡”。
ReLU 是目前最常用的激活函数。与sigmoid相比,ReLU 的优势是:采用 sigmoid 函数,计算量大(指数运算),反向传播求误差梯度时,计算量相对大,而采用 ReLU 激活函数,整个过程的计算量节省很多。 sigmoid 函数反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。 ReLU 会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
绘制图像代码:
import torch
import matplotlib.pyplot as plt
# 创建画布和坐标轴
_, axes = plt.subplots(1, 2)
# 函数图像
x = torch.linspace(-20, 20, 1000)
y = torch.relu(x)
axes[0].plot(x, y)
axes[0].grid()
axes[0].set_title("ReLU 函数图像")
# 导数图像
x = torch.linspace(-20, 20, 1000, requires_grad=True)
torch.ReLU(x).sum().backward()
axes[1].plot(x.detach(), x.grad)
axes[1].grid()
axes[1].set_title("ReLU 导数图像")
plt.show()SoftMax 激活函数
softmax 用于多分类过程中,它是二分类函数 sigmoid 在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。
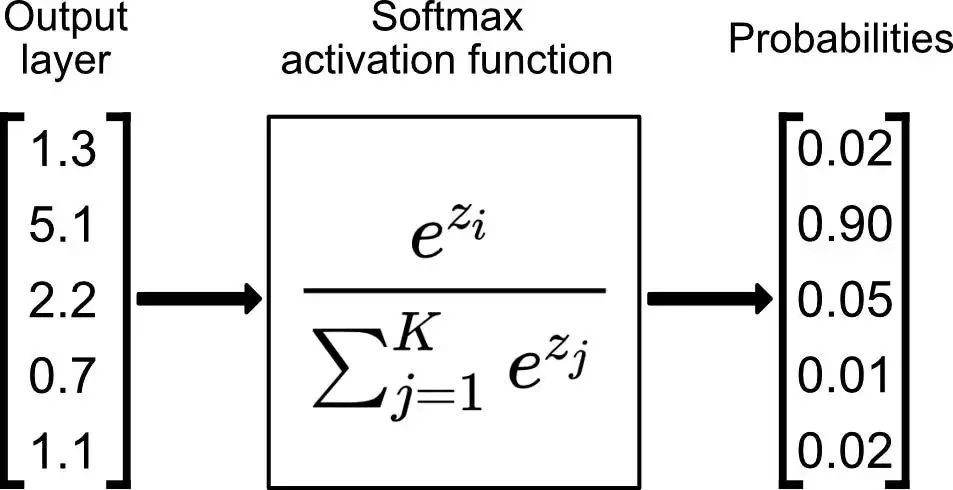
Softmax 就是将网络输出的 logits 通过 softmax 函数,就映射成为 (0,1) 的值,而这些值的累和为 1(满足概率的性质),那么我们将它理解成概率,选取概率最大(也就是值对应最大的)节点,作为我们的预测目标类别。
logits:深度学习模型(特别是分类任务)最后一层线性层输出的原始、未归一化分数。它们反映了模型对每个类别的信心,数值可为任意实数,通常在通过 Softmax 或 Sigmoid 函数映射到 0~1 之间的概率分布之前。数值越大,模型对该分类的信心越强。
Softmax 所得到的所有概率相加值等于 1。
import torch
scores = torch.tensor([0.2, 0.02, 0.15, 0.15, 1.3, 0.5, 0.06, 1.1, 0.05, 3.75])
# dim = 0, 按行计算
probabilities = torch.softmax(scores, dim=0)
print(probabilities)
# tensor([0.0212, 0.0177, 0.0202, 0.0202, 0.0638, 0.0287, 0.0185, 0.0522, 0.0183,
0.7392])其他常见的激活函数
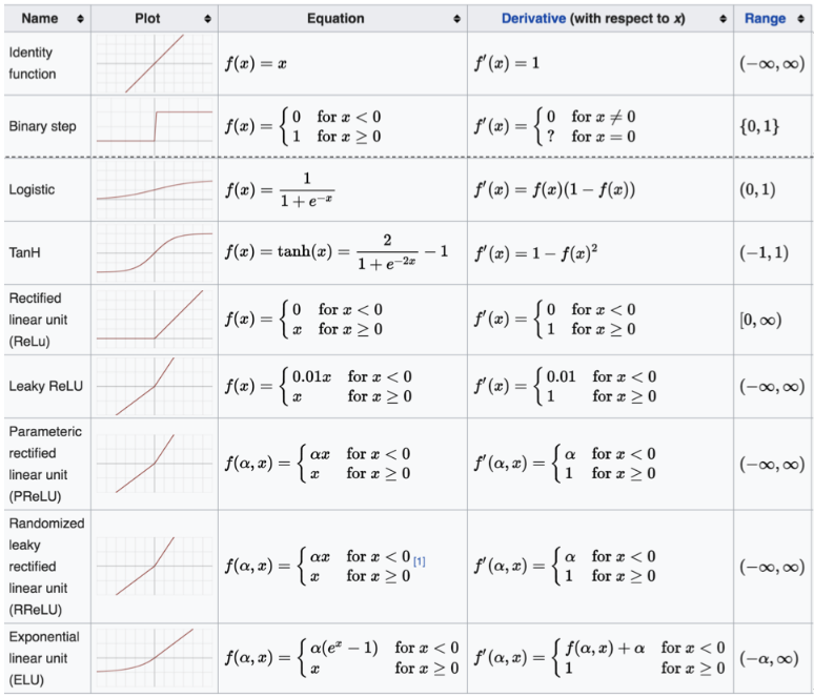
激活函数的选择
对于隐藏层:
- 优先选择 ReLU 激活函数
- 如果 ReLu 效果不好,那么尝试其他激活,如 Leaky ReLu 等。
- 如果你使用了 ReLU,需要注意一下 Dead ReLU 问题, 避免出现 0 梯度从而导致过多的神经元死亡。
- 少使用 sigmoid 激活函数,可以尝试使用 tanh 激活函数
对于输出层:
- 二分类问题选择 sigmoid 激活函数
- 多分类问题选择 softmax 激活函数
- 回归问题选择 identity 激活函数
为什么这么选?
这段总结是深度学习实践中非常经典的“经验法则”,它的核心逻辑在于梯度消失/爆炸、计算效率以及输出分布的匹配。
为了让你更透彻地理解这些规则,我们需要从数学特性以及实际训练中的表现来剖析:
一、 隐藏层:为什么要“优先 ReLU,慎用 Sigmoid”?
隐藏层的作用是提取特征,我们需要它计算快、梯度传导顺畅。
1. 为什么优先选择 ReLU?
ReLU(修正线性单元)的公式是 。
- 解决梯度消失:
- Sigmoid/Tanh 的硬伤: 它们的导数在输入很大或很小时趋近于 0。深层网络中,多个接近 0 的梯度相乘(链式法则),导致梯度传到底层时几乎为 0,深层网络这就“训不动”了。
- ReLU 的优势: 在 的区域,ReLU 的导数恒等于 1。这意味着梯度可以毫无衰减地穿过深层网络,极大地缓解了梯度消失问题,使得深层网络训练成为可能。
- 计算效率极高:
- Sigmoid 需要进行指数运算,计算量大。
- ReLU 只需要一个
if-else判断(或者是 max 操作),计算速度极快。
2. 什么是 Dead ReLU 问题?怎么解决?
虽然 ReLU 很好,但它有一个致命缺陷:“坏死”。
- 现象: 如果在训练过程中,某个神经元的权重更新过大,导致后续的输入 始终小于 0,那么 ReLU 的输出永远是 0,梯度也永远是 0。
- 后果: 这个神经元的参数永远不会再更新了,它“死”了。如果学习率设置过大,可能会导致网络中大量神经元死亡,网络容量下降。
- 解决方案:
- Leaky ReLU / PReLU: 给负区间一个很小的斜率(如 ),这样即使 ,梯度也不为 0,神经元就有机会“复活”。
- 调整参数: 降低学习率,或者使用更好的权重初始化方法(如 He Initialization)。
3. 为什么少用 Sigmoid,可以用 Tanh?
- Sigmoid 的两大缺陷:
- 输出不是零均值的: Sigmoid 输出恒为正 。这会导致下一层神经元的输入也恒为正,在反向传播时,权重的梯度会恒正或恒负,导致权重更新呈现“之”字形震荡,收敛变慢。
- 梯度消失更严重: Sigmoid 的导数最大值只有 0.25,梯度在传递过程中衰减极快。
- Tanh 的优势:
- Tanh 输出范围是 ,是零均值的。这意味着数据以 0 为中心分布,收敛速度通常比 Sigmoid 快。
- 虽然它也有梯度消失问题,但在隐藏层通常比 Sigmoid 表现更好(但在极深网络中仍不如 ReLU)。
二、 输出层:为什么要“看菜下碟碟”?
输出层的作用是给出最终预测结果,它的选择完全取决于你要解决的问题类型(数据的标签分布)。
1. 二分类问题 -> Sigmoid
- 场景: 判断是猫还是狗?是垃圾邮件还是正常邮件?
- 逻辑: 我们需要一个概率值,表示“属于正类”的可能性。
- 数学匹配: Sigmoid 能将实数映射到 区间,正好对应概率的取值范围。输出 0.8 意味着 80% 的概率是正类。
2. 多分类问题 -> Softmax
- 场景: 这张图是猫、狗、还是鸟?(互斥关系)
- 逻辑: 我们需要所有类别的概率之和为 1。
- 数学匹配: Softmax 会将所有输出值进行指数归一化。
这保证了每一类的概率都在 ,且总和为 1,非常符合互斥分类的概率解释。
3. 回归问题 -> Identity (线性激活)
- 场景: 预测房价、预测温度、预测股票价格。
- 逻辑: 输出是一个任意的实数,可能很大,可能很小,可能是负数。
- 数学匹配:
- Sigmoid 输出被限制在 ,不行。
- Tanh 输出被限制在 ,不行。
- Identity(恒等映射) 就是 。它不改变数值范围,直接输出神经元的线性组合结果。配合 MSE(均方误差)损失函数,可以拟合任意范围的数值。
总结对照表
| 层级 | 推荐选择 | 核心原因 | 常见陷阱 |
|---|---|---|---|
| 隐藏层 | ReLU | 导数为1,不梯度消失;计算极快;稀疏激活(模拟生物神经元)。 | Dead ReLU:神经元坏死。改用 Leaky ReLU 或降低学习率。 |
| 隐藏层 | Tanh | 输出零均值,收敛比 Sigmoid 快。 | 依然存在梯度消失问题,深层网络不如 ReLU。 |
| 隐藏层 | Sigmoid | 极少用于隐藏层。 | 梯度消失严重;输出非零均值导致收敛慢。 |
| 输出层 | Sigmoid | 二分类。输出范围 拟合概率。 | - |
| 输出层 | Softmax | 多分类。输出和为 1,拟合互斥概率分布。 | - |
| 输出层 | Identity | 回归。输出范围 。 | 如果没加输出层激活函数,默认就是这个。 |
一句话概括: 隐藏层是为了让梯度“跑得快、跑得远”,所以选 ReLU;输出层是为了让结果“对得上号”,所以看标签选函数。
为什么反向传播需要使用 sum,使用其他的可以吗
问题本质:为什么 backward() 前要使用 sum,是否可以用 mean 或者不使用
- backward() 的要求:只能对“标量(scalar)”进行反向传播
如果是:
criterion = (w**2) / 2.0当 w = torch.tensor([1.0]) 时:
criterion.shape == (1,)这不是标量(而是一维张量),因此不能直接:
criterion.backward() # 会报错必须转成标量:
criterion.sum().backward()- 可以不使用 sum 吗?
可以,有两种方式:
方式 A:本身就是标量(推荐)
w = torch.tensor(1.0, requires_grad=True)
criterion = (w**2) / 2.0
criterion.backward()方式 B:手动传入梯度
criterion.backward(torch.ones_like(criterion))- 可以用 mean 吗
可以,但要注意区别,注意梯度缩放:
sum:
loss = 所有元素直接相加mean:
loss = 所有元素求平均(会除以元素个数)- 当前代码中的情况
因为:
w.shape = (1,)所以:
sum == mean结果完全一样,没有区别
- 多元素情况下的区别
例如:
w = torch.tensor([1.0, 2.0], requires_grad=True)
criterion = (w**2) / 2.0不同写法:
sum:
criterion.sum().backward()
# 梯度 = 正常梯度mean:
criterion.mean().backward()
# 梯度 = 正常梯度 / 元素个数不写:
criterion.backward()
# 报错(不是标量)- 总结
- backward 只能作用于标量
- sum 和 mean 都可以让张量变成标量
- mean 会缩小梯度(除以元素个数)
- 单元素时 sum 和 mean 没区别
- 多元素时要根据需求选择
- 实际开发建议
- 单个 loss:直接使用标量
- batch 训练:通常使用 mean(更稳定)
参数初始化
为什么要进行参数初始化
我们在构建神经网络后,网络中的参数是要初始化的。我们需要初始化的参数主要是权重和偏置,偏置一般初始化为 0 即可,而对权重的初始化则更加重要。
参数初始化的作用:
- 防止梯度消失或爆炸:初始权重值过大或过小会导致梯度在反向传播中指数级增大或缩小。
- 提高收敛速度:合理的初始化使得网络中的激活值分布适中,有助于梯度高效更新。
- 保持对称性破除:权重的初始化需要打破对称性,初始化参数不能一致或相近,否则网络的学习能力会受限。
参数初始化方法
- 均匀分布初始化:权重参数初始化从区间均匀随机取值,默认区间为(0,1)。可以设置为在 均匀分布中生成当前神经元的权重,其中 d 为神经元的输入数量,可打破对称性
- 正态分布初始化:随机初始化从均值为 0,标准差是 1 的高斯分布中取样,使用一些很小的值对参数W进行初始化,可打破对称性
- 全 0 初始化:将神经网络中的所有权重参数初始化为 0,不能打破对称性
- 全 1 初始化:将神经网络中的所有权重参数初始化为 1,不能打破对称性
- 固定值初始化:将神经网络中的所有权重参数初始化为某个固定值,不能打破对称性
- kaiming 初始化,也叫做 HE 初始化,可打破对称性
- xavier 初始化,也叫做 Glorot 初始化,可打破对称性
如果是浅层神经网络,随机初始化即可;如果是深层网络,需要考虑方差平衡,此时就要使用 kaiming 初始化或 xavier 初始化。
Kaiming 初始化(HE 初始化)
该方法特别适用于 ReLU 及其变体(如 Leaky ReLU)的激活函数。
正态分布的 HE 初始化
- 从正态分布 中抽取样本
- 标准差计算公式:
均匀分布的 HE 初始化
- 从均匀分布 中抽取样本
- 边界值计算公式:
参数说明:fan_in 为输入层神经元的个数。
Xavier 初始化(Glorot 初始化)
该方法适用于 Sigmoid 或 Tanh 等饱和激活函数。
正态分布的 Xavier 初始化
- 从正态分布 中抽取样本
- 标准差计算公式:
均匀分布的 Xavier 初始化
- 从均匀分布 中抽取样本
- 边界值计算公式:
参数说明:
fan_in:输入层神经元的个数fan_out:输出层神经元个数
代码演示
- 均匀分布初始化
demo.py
import torch.nn as nn
linear = nn.Linear(5, 3)
# 均匀分布初始化
nn.init.uniform_(linear.weight, a=0, b=1)
nn.init.uniform_(linear.bias, a=0, b=1)
print(f"---均匀分布初始化后---\n权重:\n{linear.weight},\n偏置:\n{linear.bias}\n")运行结果.txt
---均匀分布初始化后---
权重:
Parameter containing:
tensor([[0.8541, 0.7939, 0.7003, 0.1550, 0.6686],
[0.7515, 0.6598, 0.7605, 0.3262, 0.8483],
[0.1581, 0.4006, 0.2162, 0.2969, 0.1051]], requires_grad=True),
偏置:
Parameter containing:
tensor([0.5744, 0.7066, 0.2554], requires_grad=True)代码开始创建了一个有五个输入、三个输出的线性变换层,执行的是公式 :
x是输入向量,形状为(*, 5),其中*表示任意数量的附加维度(包括批处理维度)。A是权重矩阵(Weights),形状为(3, 5)。PyTorch 会在内部自动初始化这个矩阵。b是偏置向量(Bias),形状为(3,)。PyTorch 也会自动初始化它。y是输出向量,形状为(*, 3)。
该层完成两个工作:
- 接受五个特征的输入,给每个特征加上权重,还有一个偏置,输出是第二个参数指定的数量,这里是 3;
- 使用激活函数映射,将线性变换转换为非线性变换。
激活函数在后面如何构建神经网络时会介绍。
- 全 0 初始化
demo.py
import torch.nn as nn
linear = nn.Linear(5, 3)
# 全零初始化
nn.init.zeros_(linear.weight)
nn.init.zeros_(linear.bias)
print(f"---全零初始化后---\n权重:\n{linear.weight},\n偏置:\n{linear.bias}\n")运行结果.txt
---全零初始化后---
权重:
Parameter containing:
tensor([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]], requires_grad=True),
偏置:
Parameter containing:
tensor([0., 0., 0.], requires_grad=True)可以看到,每个样本的权重都是一致的,那么一个线性变换层的五个神经元将没有任何区别,不能破除对称性。
- 正态分布初始化、全 1 初始化、固定值初始化:
demo.py
import torch.nn as nn
linear = nn.Linear(5, 3)
# 正态分布初始化、全 1 初始化、固定值初始化:
nn.init.normal_(linear.weight, mean=0, std=0.01)
print(f"---正态分布初始化后---\n权重:\n{linear.weight}\n")
nn.init.ones_(linear.weight)
print(f"---全 1 初始化后---\n权重:\n{linear.weight}\n")
nn.init.constant_(linear.weight, val=0)
print(f"---固定值初始化后---\n权重:\n{linear.weight}\n")运行结果.txt
---正态分布初始化后---
权重:
Parameter containing:
tensor([[ 0.0094, 0.0053, 0.0106, -0.0038, 0.0095],
[ 0.0078, 0.0096, -0.0055, -0.0053, -0.0005],
[ 0.0157, 0.0097, 0.0002, -0.0113, 0.0237]], requires_grad=True)
---全 1 初始化后---
权重:
Parameter containing:
tensor([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]], requires_grad=True)
---固定值初始化后---
权重:
Parameter containing:
tensor([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]], requires_grad=True)- kaiming 初始化、xavier 初始化
demo.py
import torch.nn as nn
linear = nn.Linear(5, 3)
# kaiming 初始化、xavier 初始化
nn.init.kaiming_normal_(linear.weight)
print(f"kaiming 初始化分类: {linear.weight.data}")
nn.init.xavier_normal_(linear.weight)
print(f"xavier 初始化分类: {linear.weight.data}")运行结果.txt
kaiming 初始化分类: tensor([[ 0.9936, -0.6715, -0.2937, -1.1838, 0.6974],
[ 0.4294, -0.2804, -0.6189, 0.1831, 0.3120],
[-0.3301, -0.8252, 0.1994, 0.2020, 0.1212]])
xavier 初始化分类: tensor([[-0.3073, -0.2801, -0.0925, 0.0721, 0.0358],
[ 0.8859, 0.3836, -0.1816, 0.2389, 0.5227],
[ 0.9477, 0.2053, -0.5335, 0.0435, 0.5402]])搭建神经网络
在 pytorch 中定义深度神经网络其实就是层堆叠的过程,我们需要自定义一个类,继承自 nn.Module,并实现两个方法:
__init__()方法中定义网络中的层结构,主要是全连接层,并进行初始化;forward()方法,在实例化模型的时候,底层会自动调用该函数。该函数中为初始化定义的 layer 传入数据,进行前向传播。
我们来构建如下图所示的神经网络模型:
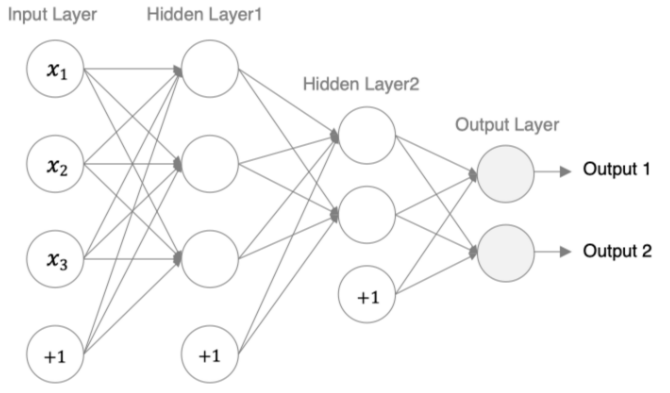
- 第 1 个隐藏层:权重初始化采用标准化的 xavier 初始化 激活函数使用 sigmoid
- 第 2 个隐藏层:权重初始化采用标准化的 He 初始化 激活函数采用 relu
- out 输出层线性层 假若多分类,采用 softmax 做数据归一化
第一个隐藏层中,神经元的个数是是 3,每个神经元的参数为 4(、、、),所以该层有 12 个参数;第二个隐藏层中,神经元的个数是 2,每个神经元的参数为 4,参数为 8;输出层中,神经元个数是 3,参数个数为 3,参数为 6,总数为 26。所以这个神经网络有 26 个参数。
定义类的方法大致如下:
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.linear1 = nn.Linear(10, 5)
self.linear2 = nn.Linear(5, 1)
...
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.linear1(x)
x = self.sigmoid(x)
x = self.linear2(x)
...
x = self.sigmoid(x)
return x__init__() 方法用于实例化模型对象,在这个方法内部,定义神经网络的结构,包括权重和偏置,然后进行参数初始化。forward() 方法定义前向传播的方式,在这里设置激活函数。这样就实现了神经网络的两个步骤:加权求和 + 激活函数,且加权求和在我们设置模型的层对象时,就已经完成计算了。
import torch
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# 第一个隐藏层,输入维度为3,输出维度为3
self.linear1 = nn.Linear(3, 3)
# 第二个隐藏层,输入维度为3,输出维度为2
self.linear2 = nn.Linear(3, 2)
# 输出层,输入维度为2,输出维度为2
self.output = nn.Linear(2, 2)
# 隐藏层1使用 xavier 标准初始化
nn.init.xavier_normal_(self.linear1.weight)
nn.init.zeros_(self.linear1.weight)
# 隐藏层2使用 He 初始化
nn.init.kaiming_normal_(self.linear2.weight)
nn.init.zeros_(self.linear2.weight)
def forward(self, x):
# 第一个隐藏层,使用 Sigmoid 激活函数
x = self.linear1(x) # 权重求和
x = torch.sigmoid(x) # 激活函数
# 第二个隐藏层,使用 ReLU 激活函数
x = self.linear2(x)
x = torch.relu(x)
# 输出层,使用 Softmax 激活函数
x = self.output(x)
x = torch.softmax(x, dim=-1)
return x确定每一层的 输入维数(input dimension) 和 输出维数(output dimension) 的规则其实很简单,本质只取决于 相邻两层神经元数量。
基本原则:
- 输入维数 = 前一层神经元数量
- 输出维数 = 当前层神经元数量
- 图中的 +1 是偏置(bias)节点,不计入输入维数,因为大多数框架(如 PyTorch、TensorFlow)会自动处理 bias。
损失函数
介绍
在深度学习中,损失函数是用来衡量模型参数的质量的函数,衡量的方式是比较网络输出和真实输出的差异:
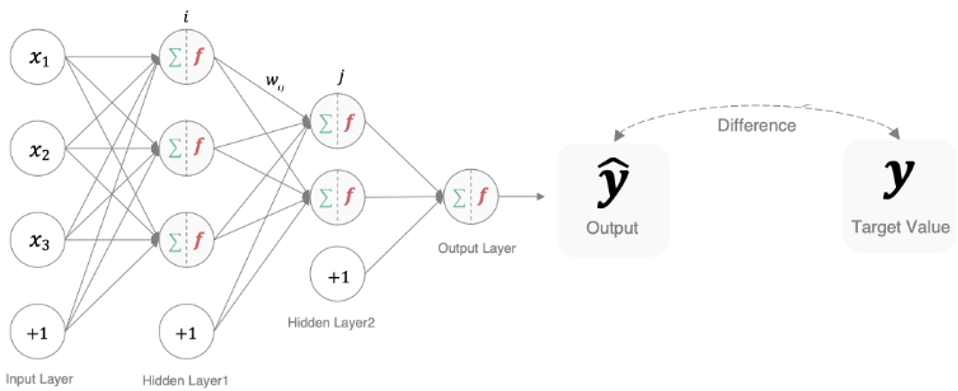
损失函数也可以称为代价函数、误差函数、目标函数。
多分类交叉熵损失函数
在多分类任务通常使用 softmax 将 logits 转换为概率的形式,所以多分类的交叉熵损失也叫做 softmax 损失,它的计算方法是:
是经过 one-hot 编码的标签,是真实值;右边的 是样本, 是样本属于某一类别的预测分数,S 是 softmax 激活函数,将预测分数转换成概率。
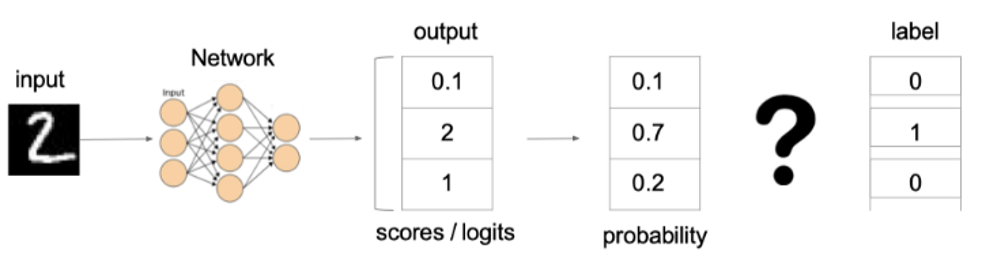
上图中的交叉熵损失为:
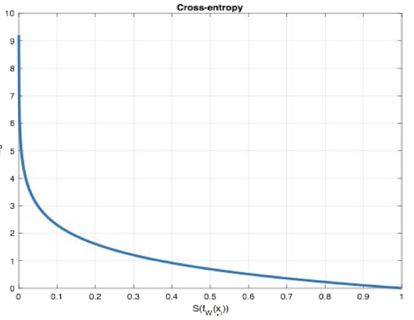
从概率角度理解,我们的目的是最小化正确类别所对应的预测概率的对数的负值(损失值最小),如下图所示:
在 PyTorch 中,使用 nn.CrossEntropyLoss() 实现多分类交叉熵损失函数。
import torch
import torch.nn as nn
y_true = torch.tensor([[0, 1, 0], [1, 0, 0]], dtype=torch.float)
y_pred = torch.tensor([[0.1, 0.8, 0.1], [0.7, 0.2, 0.1]], requires_grad=True, dtype=torch.float)
criterion = nn.CrossEntropyLoss() # 平均损失, 来源于参数: reduction: str = "mean",
loss = criterion(y_pred, y_true)
print(f"损失值: {loss}")
# 损失值: 0.7288381457328796二分类交叉熵损失函数
由于处理二分类时我们使用的是 sigmoid 函数,所以损失函数也需要做相应的调整:
其中,y 是样本 x 属于某一个类别的真实概率, 是样本属于某一类别的预测概率。
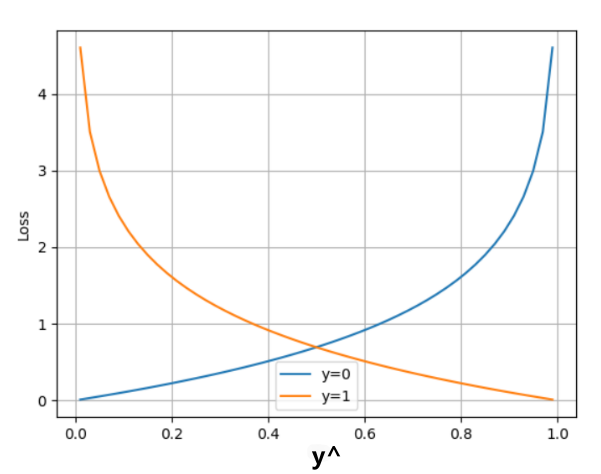
在 PyTorch 中,使用 nn.BCELoss() 实现二分类交叉熵损失函数。
import torch
import torch.nn as nn
y_true = torch.tensor([0, 1, 0], dtype=torch.float)
y_pred = torch.tensor([0.6901, 0.5423, 0.2639])
criterion = nn.BCELoss() # reduction: str = "mean" -> 均值
loss = criterion(y_pred, y_true)
print(f"损失值: {loss}")
# 损失值: 0.6966102719306946这两个损失函数都是处理分类问题的,接下来我们看回归问题使用的损失函数。
MAE 损失函数
MAE,Mean Absolute Loss,也被称为 L1 Loss、平均绝对误差,是以绝对误差作为距离,公式:
公式和线性回归惩罚过拟合的 L1 正则化比较像,所以它的特点也是:
- 具有稀疏性,因此为了惩罚较大的值,会将它作为正则项添加到其他损失中作为约束;
- 梯度在零点不平滑,因为不可导,所以会跳过极小值。
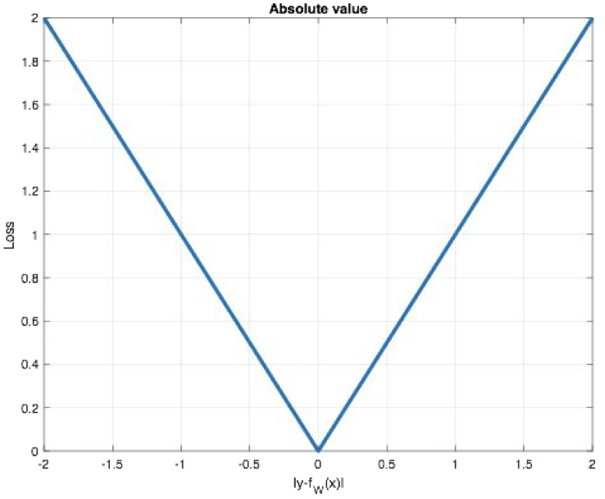
在 PyTorch 中使用 nn.L1Loss() 实现,代码:
import torch
import torch.nn as nn
y_true = torch.tensor([1.0, 1.0, 1.9], requires_grad=True)
y_pred = torch.tensor([2.0, 2.0, 2.0], dtype=torch.float)
criterion = nn.L1Loss() # reduction: str = "mean" -> 均值
loss = criterion(y_pred, y_true)
print(f"损失值: {loss}")
# 损失值: 0.699999988079071MSE 损失函数
Mean Squared Loss、Quadratic Loss,也被称为 L2 Loss 或欧氏距离,以误差的平方和的均值作为距离,公式:
图像:
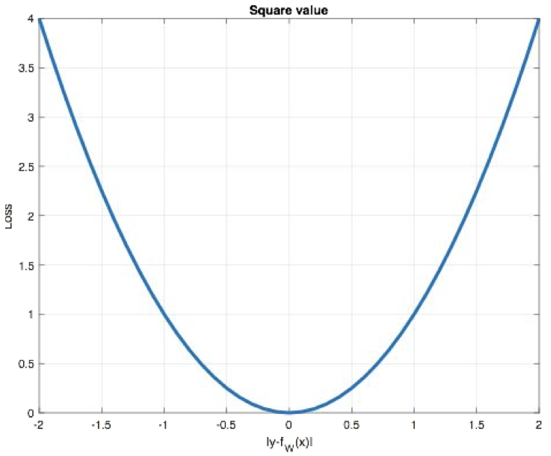
L2 loss也常常作为正则项,但当预测值与目标值相差很大时,梯度容易爆炸。
MSE 在 PyTorch 中使用 nn.MSELoss()实现,代码:
import torch
import torch.nn as nn
y_true = torch.tensor([1.0, 1.0, 1.9], requires_grad=True)
y_pred = torch.tensor([2.0, 2.0, 2.0], dtype=torch.float)
criterion = nn.MSELoss() # reduction: str = "mean" -> 均值
loss = criterion(y_pred, y_true)
print(f"损失值: {loss}")
# 损失值: 0.6700000166893005Smooth L1 损失函数
Smooth L1 结合了 MAE、MSE,这样可以产生稀疏解,又避免了 0 点不可导的问题。公式:
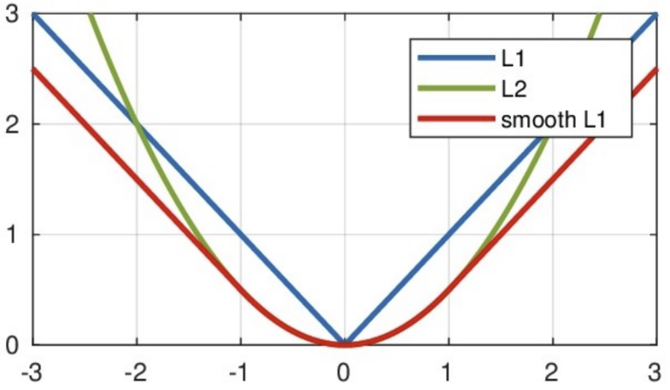
其中: 为真实值和预测值的差值。
从右图中可以看出,该函数实际上就是一个分段函数:
- 在 之间实际上就是 L2 损失,这样解决了 L1 的不光滑问题
- 在 区间外,实际上就是 L1 损失,这样就解决了离群点梯度爆炸的问题
Smooth L1 在 PyTorch 的 API 是 nn.SmoothL1Loss():
import torch
import torch.nn as nn
y_true = torch.tensor([1.0, 1.0, 1.9], requires_grad=True)
y_pred = torch.tensor([2.0, 2.0, 2.0], dtype=torch.float)
criterion = nn.SmoothL1Loss() # reduction: str = "mean" -> 均值
loss = criterion(y_pred, y_true)
print(f"损失值: {loss}")
# 损失值: 0.33500000834465027