
外观
Transformer
2018 年 10 月,Google 发出一篇论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》,BERT 模型横空出世,并横扫 NLP 领域11项任务的最佳成绩。
论文地址:https://arxiv.org/pdf/1810.04805.pdf
而在 BERT 中发挥重要作用的结构就是 Transformer,之后又相继出现 XLNET,roBERT 等模型击败了BERT,但是他们的核心没有变,仍然是:Transformer。
相比之前占领市场的 LSTM 和 GRU 模型,Transformer 有两个显著的优势:
Transformer 能够利用分布式 GPU 进行并行训练,提升模型训练效率。
在分析预测更长的文本时,捕捉间隔较长的语义关联效果更好。
架构
基于 seq2seq 架构的 transformer 模型可以完成 NLP 领域研究的典型任务,如机器翻译,文本生成等。同时又可以构建预训练语言模型,用于不同任务的迁移学习。
在接下来的架构分析中,我们将假设使用 Transformer 模型架构处理从一种语言文本到另一种语言文本的翻译工作,因此很多命名方式遵循 NLP 中的规则。 比如: Embeddding 层将称作文本嵌入层,Embedding 层产生的张量称为词嵌入张量,它的最后一维将称作词向量等。
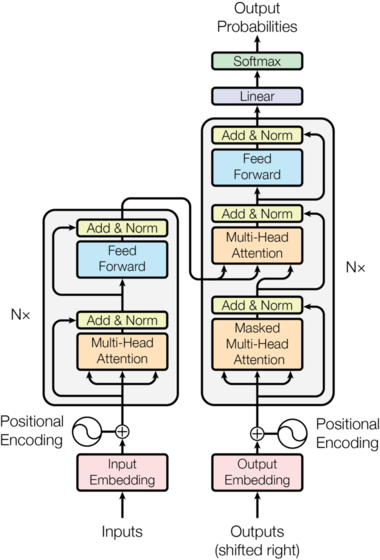
Transformer 分为四部分:输入、编码器、解码器、输出。
输入部分
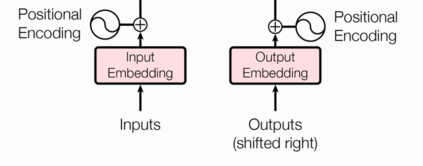
输入部分包含源文本嵌入层及其位置编码器、目标文本嵌入层及其位置编码器。
作用:将文本中的词汇转换为向量表示,希望在这样的高维空间捕捉词汇间的关系。
文本嵌入层
文本嵌入层负责将源文本和目标文本的词汇转换为向量表示,为了捕捉词汇间的关系。
import torch
import torch.nn as nn
import math
# torch中变量封装函数Variable
from torch.autograd import Variable
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
# 参数d_model 每个词汇的特征尺寸 词嵌入维度
# 参数vocab 词汇表大小
super(Embeddings, self).__init__()
self.d_model = d_model
self.vocab = vocab
self.lut = nn.Embedding(self.vocab, self.d_model)
def forward(self, x):
# 将x传给self.lut并与根号下self.d_model相乘作为结果返回
# x经过词嵌入后 增大x的值, 词嵌入后的embedding_vector+位置编码信息,值量纲差差不多
return self.lut(x) * math.sqrt(self.d_model)位置编码器
因为在 Transformer 的编码器结构中,并没有针对词汇位置信息的处理,因此需要在 Embedding 层后加入位置编码器,将词汇位置不同可能会产生不同语义的信息加入到词嵌入张量中,以弥补位置信息的缺失。
公式:
对于位置 pos 和维度 i:
对于偶数维:
对于奇数维:
好处:计算更快,尤其是句子很长时,不需要每个位置都重新算三角函数。
目的:
- 记住词的顺序:通过周期性函数,给每个位置贴独特的标签,让模型区分不同顺序的词汇。
- 计算高效:靠线性组合推导新位置编码,不用重复计算三角函数。
- 适应任意长度:不管句子多长,都能随时算编码,泛化能力强。
- 模型处理语言时,更聪明,更灵活。
实现:
"""
案例:
演示输入部分的 嵌入层 和 位置编码介绍.
总结(回顾):
输入部分由2部分组成, 分别是:
词嵌入层(Word Embedding)
位置编码(Positional Encoding)
"""
# 导包
import torch
import torch.nn as nn # neural network: 神经网络
import numpy as np
import math
import matplotlib.pyplot as plt
# todo 1.定义函数, 实现: 输入部分之 -> 词嵌入层
class Embeddings(nn.Module): # 叫Embeddings的目的是为了和Python的类名做区分, 实际开发写: Embedding
# 1. 初始化函数
# 参1: 词汇表大小(去重后单词的总个数), 参2: 词嵌入的维度
def __init__(self, vocab_size, d_model):
# 1.1 初始化父类信息.
super().__init__()
# 1.2 定义变量, 接收: 词汇表大小, 词嵌入的维度
self.vocab_size = vocab_size
self.d_model = d_model
# '欢迎来广州' -> {0: '欢迎', 1: '来', 2: '广州'} -> 把0(单词索引)转成 [值1, 值2, 值3, 值4...] 词向量形式
# 1.3 定义词嵌入层, 将单词索引映射为词向量.
self.embed = nn.Embedding(vocab_size, d_model)
# 2. 定义前向传播方法
def forward(self, x):
# 将输入的单词索引映射为词向量, 并乘以 根号d_model进行缩放.
# 缩放的目的: 为了平衡梯度, 避免梯度消失或梯度爆炸.
return self.embed(x) * math.sqrt(self.d_model)
# todo 2.测试Embeddings(词嵌入层)
def use_embedding():
# 1. 定义变量, 记录: 词表大小(1000), 词嵌入维度(512).
vocab_size, d_model = 1000, 512
# 2. 实例化Embeddings类.
my_embed = Embeddings(vocab_size, d_model)
# 3. 创建张量, 包含2个句子, 每个句子4个词.
x = torch.tensor([
# ['我', '爱', '吃', '猪脚饭'], # 单词
# ['你', '爱', '吃', '螺蛳粉']
[100, 2, 421, 600], # 单词索引
[500, 888, 3, 615]
])
# 4. 计算嵌入结果.
result = my_embed(x)
# 5. 打印结果.
print(f'result: {result.shape}, {result}') # [2, 4, 512]
# todo 3. 定义函数, 实现: 输入部分之 -> 位置编码层
class PositionEncoding(nn.Module):
# 1. 初始化函数.
# 参1: 词向量的维度(512), 参2: 随机失活概率. 参3: 最大句子长度.
def __init__(self, d_model, dropout, max_len=60):
# 1.1 初始化父类成员.
super().__init__()
# 1.2 定义dropout层, 防止过拟合.
self.dropout = nn.Dropout(p=dropout)
# 1.3 定义pe, 用于保存位置编码结果. 形状: [max_len, d_model] -> [60, 512]
pe = torch.zeros(max_len, d_model)
# 1.4 定义一个位置列向量, 从0 到 max_len - 1
# 形状改变: [60] -> [60, 1]
position = torch.arange(0, max_len).unsqueeze(1) # 形状: [60, 1]
# 1.5 定义1个转换(变化矩阵), 本质是公式里的: 1 / 10000^(2i/d_model)
# 公式推导: 10000^(2i/d_model) = e^((2i/d_model) * ln(10000))
# 1/上述内容, 所以求倒数: e^((2i/d_model) * -ln(10000)) -> e^(2i * -ln(10000)/d_model)
# torch.arange(0, d_model, 2) -> [0, 2, 4, 6, 8.....510] 偶数维度
# [0, 2, 4, 6, 8.....510] + 1 -> [1, 3, 5, 7, 9.....511] 奇数维度
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model)) # 形状: [1, 256]
# 1.6 计算三角函数里面的值.
# position形状: [max_len, 1] -> [60, 1]
# div_term形状: [1, 256]
# position * div_term = [60, 256]
position_value = position * div_term
# 1.7 进行pe的赋值, 偶数位置使用 正弦函数(sin)
# pe形状: [60, 512], position_value形状: [60, 256]
pe[:, 0::2] = torch.sin(position_value) # 形状: [60, 256]
# 1.8 进行pe的赋值, 奇数位置使用 余弦函数(cos)
pe[:, 1::2] = torch.cos(position_value) # 形状: [60, 256]
# 1.9 将pe进行升维, 增加1个批次维度.
pe = pe.unsqueeze(0) # [1, 60, 512]
# 1.10 将pe注册到模型的缓冲区, 利用它, 但是不更新它的参数.
# 回顾: sin(α + β) = sin(α)cos(β) + cos(α)sin(β), cos(α + β) = cos(α)cos(β) - sin(α)sin(β)
# 带入: sin(5) = sin(3 + 2) = ....
# pe会作为模型的一部分, 在模型保存, 加载的时候会被处理, 而在模型训练时它的值不会被优化器更新(因为: 位置编码是固定规则)
self.register_buffer('pe', pe)
# 2. 前向传播.
def forward(self, x):
# 1. 这段代码是位置编码的核心逻辑, 负责把 '词向量' 和 '位置编码' 融合(相加)
# 参数x: 词向量, 形状为: [batch_size, seq_len, d_model] -> [1, 60, 512]
# self.pe 的形状: [1, max_len, d_model] -> 假设: [1, 1000, 512]
x = x + self.pe[:, :x.size(1)] # [1, 60, 512] + [1, 60, 512]
# 2. 随机失活, 不改变形状, 形状还是: [batch_size, seq_len, d_model] -> [1, 60, 512]
return self.dropout(x)
# todo 4. 测试 Positional_Encoding(位置编码层)
def use_position():
# 1. 定义词汇表大小 和 词嵌入维度.
vocab_size = 1000
d_model = 512
# 2. 实例化Embeddings层.
my_embed = Embeddings(vocab_size, d_model) # [1000, 512]
# 3. 创建输入张量, 形状: [2, 4] -> 2个句子, 每个句子4个单词
x = torch.tensor([
[100, 2, 421, 600], # 单词索引
[500, 888, 3, 615]
])
# 4. 计算词嵌入结果.
embed_x = my_embed(x) # 形状: [2, 4, 512] -> [batch_size, seq_len, d_model]
# 5. 实例化PositionEncoding层.
my_position = PositionEncoding(d_model, dropout=0.1)
# 6. 计算位置编码结果.
position_x = my_position(embed_x) # [2, 4, 512]
# 7. 返回结果.
return position_x
# todo 5. 测试plot_Positional(可视化位置编码)
def plot_position():
# 1. 实例化位置编码器.
# 参1: 词嵌入维度(维度小方便画图看规律), 参2: 随机失活概率, 参3: 最大序列长度.
my_position = PositionEncoding(20, dropout=0, max_len=100)
# 2. 生成全0的输入, 观察位置编码的模式.
# (1, 100, 20) -> 批次大小, 句子长度, 词嵌入维度.
y = my_position(torch.zeros(1, 100, 20))
# 3. 打印输出形状.
print(f'y.shape: {y.shape}') # [1, 100, 20]
# 4. 设置图表大小.
plt.figure(figsize=(20, 15))
# 5. 绘制位置编码第4到第7列, 100个词的[4, 5, 6, 7]列
plt.plot(np.arange(100), y[0, :, 4:8].detach().numpy())
# 6. 添加图例.
plt.legend([f'dim {p}' for p in [4, 5, 6, 7]])
# 7. 显示图表.
plt.show()
if __name__ == '__main__':
# 1. 测试词嵌入.
# use_embedding()
# 2. 测试位置编码.
# result = use_position()
# print(f'result: {result.shape}, {result}')
# 3. 测试位置编码的可视化.
plot_position()编码器
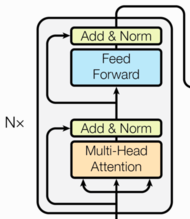
编码器由多个编码器层堆叠而成,每个编码器层由两个子层连接结构组成:
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
掩码张量
掩代表遮掩,码是张量的数值,尺寸不固定,一般只有 1 和 0 两种元素,代表位置是否遮掩。
在 transformer 中应用 attention 时,有一些生成的 attention 张量中的值有可能是计算了未来信息得到的,未来信息被看到是因为训练时会把整个输出结果一次性进行 Embedding,但是理论上,解码器的输出不是一次就能产生最终结果的,而是一次次叠加,因此,未来的信息可能被提前利用。所以,我们会进行遮掩。
上三角矩阵和np.triu
# 上三角矩阵:下面矩阵中0组成的形状为上三角矩阵
'''
[[[0. 1. 1. 1. 1.]
[0. 0. 1. 1. 1.]
[0. 0. 0. 1. 1.]
[0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0.]]]
# np.triu()函数功能介绍
# def triu(m, k)
# m:表示一个矩阵
# K:表示对角线的起始位置(k取值默认为0)
# return: 返回函数的上三角矩阵
'''
def dm_test_nptriu():
# 测试产生上三角矩阵
print(np.triu([[1, 1, 1, 1, 1],
[2, 2, 2, 2, 2],
[3, 3, 3, 3, 3],
[4, 4, 4, 4, 4],
[5, 5, 5, 5, 5]], k=1))
print(np.triu([[1, 1, 1, 1, 1],
[2, 2, 2, 2, 2],
[3, 3, 3, 3, 3],
[4, 4, 4, 4, 4],
[5, 5, 5, 5, 5]], k=0))
print(np.triu([[1, 1, 1, 1, 1],
[2, 2, 2, 2, 2],
[3, 3, 3, 3, 3],
[4, 4, 4, 4, 4],
[5, 5, 5, 5, 5]], k=-1))
# 结果输出:
[[0 1 1 1 1]
[0 0 2 2 2]
[0 0 0 3 3]
[0 0 0 0 4]
[0 0 0 0 0]]
[[1 1 1 1 1]
[0 2 2 2 2]
[0 0 3 3 3]
[0 0 0 4 4]
[0 0 0 0 5]]
[[1 1 1 1 1]
[2 2 2 2 2]
[0 3 3 3 3]
[0 0 4 4 4]
[0 0 0 5 5]]生成掩码函数:
# 下三角矩阵作用: 生成字符时,希望模型不要使用当前字符和后面的字符。
# 使用遮掩mask,防止未来的信息可能被提前利用
# 实现方法: 1 - 上三角矩阵
# 函数 subsequent_mask 实现分析
# 产生上三角矩阵 np.triu(m=np.ones((1, size, size)), k=1).astype('uint8')
# 返回下三角矩阵 torch.from_numpy(1 - my_mask )
def subsequent_mask(size):
# 产生上三角矩阵 产生一个方阵
subsequent_mask = np.triu(m = np.ones((1, size, size)), k=1).astype('uint8')
# 返回下三角矩阵
return torch.from_numpy(1 - subsequent_mask)调用:
def dm_test_subsequent_mask():
# 产生5*5的下三角矩阵
size = 5
sm = subsequent_mask(size)
print('下三角矩阵--->\n', sm)输出:
下三角矩阵--->
tensor([[[1, 0, 0, 0, 0],
[1, 1, 0, 0, 0],
[1, 1, 1, 0, 0],
[1, 1, 1, 1, 0],
[1, 1, 1, 1, 1]]], dtype=torch.uint8)可视化:

注意力机制
公式:
代码:
# 自注意力机制函数attention 实现思路分析
# attention(query, key, value, mask=None, dropout=None)
# 1 求查询张量特征尺寸大小 d_k
# 2 求查询张量q的权重分布socres q@k^T /math.sqrt(d_k)
# 形状[2,4,512] @ [2,512,4] --->[2,4,4]
# 3 是否对权重分布scores进行 scores.masked_fill(mask == 0, -1e9)
# 4 求查询张量q的权重分布 p_attn F.softmax()
# 5 是否对p_attn进行dropout if dropout is not None:
# 6 求查询张量q的注意力结果表示 [2,4,4]@[2,4,512] --->[2,4,512]
# 7 返回q的注意力结果表示 q的权重分布
def attention(query, key, value, mask=None, dropout=None):
# query, key, value:代表注意力的三个输入张量
# mask:代表掩码张量
# dropout:传入的dropout实例化对象
# 1 求查询张量特征尺寸大小
d_k = query.size()[-1]
# 2 求查询张量q的权重分布socres q@k^T /math.sqrt(d_k)
# [2,4,512] @ [2,512,4] --->[2,4,4]
scores = torch.matmul(query, key.transpose(-2, -1) ) / math.sqrt(d_k)
# 3 是否对权重分布scores 进行 masked_fill
if mask is not None:
# 根据mask矩阵0的位置 对sorces矩阵对应位置进行掩码
scores = scores.masked_fill(mask == 0, -1e9)
# 4 求查询张量q的权重分布 softmax
p_attn = F.softmax(scores, dim=-1)
# 5 是否对p_attn进行dropout
if dropout is not None:
p_attn = dropout(p_attn)
# 返回 查询张量q的注意力结果表示 bmm-matmul运算, 注意力查询张量q的权重分布p_attn
# [2,4,4]*[2,4,512] --->[2,4,512]
return torch.matmul(p_attn, value), p_attn多头注意力机制
多头注意力机制是 Transformer 的核心组件,它通过多组注意力机制并行处理输入,使模型能够从不同的表示子空间学习信息。
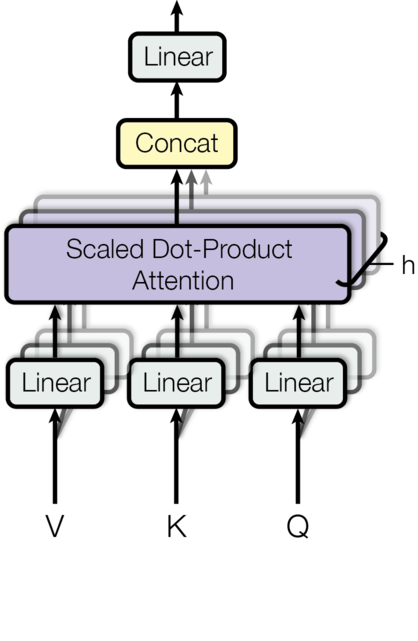
核心思想:
将 Q、K、V 通过线性变换映射到多个子空间,在每个子空间中独立进行注意力计算,最后将所有子空间的输出拼接起来。
数学形式:
其中:
参数说明:
- :头的数量(论文中 )
- :每个头中 key、query 的维度()
- :每个头中 value 的维度()
- :第 个头的 Query 投影矩阵
- :第 个头的 Key 投影矩阵
- :第 个头的 Value 投影矩阵
- :输出投影矩阵
代码实现:
# 定义多头注意力类
class MultiHeadedAttention(nn.Module):
def __init__(self, head, embedding_dim, dropout=0.1):
# head: 代表头的数量
# embedding_dim: 代表词嵌入维度
super(MultiHeadedAttention, self).__init__()
# 确保词嵌入维度能被头数整除
assert embedding_dim % head == 0
# 获得每个头获得的词嵌入维度
self.d_k = embedding_dim // head
self.head = head
# 获得四个线性层,分别是 Q、K、V 以及输出的线性层
self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
# query, key, value: 输入的三个张量
# mask: 掩码张量
if mask is not None:
# 扩展掩码维度,适应多头注意力
mask = mask.unsqueeze(1)
# 获取 batch_size
batch_size = query.size(0)
# 1. Q、K、V 的线性变换 + 维度调整
# zip(self.linears, (query, key, value))
# 将 query, key, value 分别通过三个线性层
# - view: 重塑张量形状 [batch_size, seq_len, embedding_dim] -> [batch_size, seq_len, head, d_k]
# - transpose: 交换维度 [batch_size, seq_len, head, d_k] -> [batch_size, head, seq_len, d_k]
query, key, value = \
[l(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2. 计算注意力
# x: 注意力结果表示
# self.attn: 注意力权重
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3. 多头结果的拼接
# transpose: [batch_size, head, seq_len, d_k] -> [batch_size, seq_len, head, d_k]
# contiguous: 确保张量在内存中是连续的
# view: [batch_size, seq_len, head, d_k] -> [batch_size, seq_len, embedding_dim]
x = x.transpose(1, 2).contiguous().view(batch_size, -1,
self.head * self.d_k)
# 4. 通过最后一个线性层
return self.linears[-1](x)多头注意力的优势:
- 多视角学习:每个头可以学习不同的表示子空间,捕捉不同的依赖关系
- 并行计算:多个头可以并行计算,提高计算效率
- 表达能力:相比单头注意力,多头注意力有更强的表达能力
前馈全连接层
在编码器和解码器的每个子层中,除了注意力子层外,还有一个前馈全连接子层(Position-wise Feed-Forward Network)。
数学形式:
其中:
- :第一层权重矩阵()
- :第二层权重矩阵
- :偏置项
特点:
- 逐位置应用:对不同位置的词向量独立进行相同的变换
- 两层全连接:第一层将维度从 扩展到 ,第二层压缩回
- ReLU 激活:使用 ReLU 激活函数
代码实现:
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
# d_model: 词嵌入维度
# d_ff: 中间隐藏层维度
super(PositionwiseFeedForward, self).__init__()
# 两层线性层
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
# Dropout 层
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# x: [batch_size, seq_len, d_model]
# 第一层线性变换 + ReLU 激活 + Dropout
# [batch_size, seq_len, d_model] -> [batch_size, seq_len, d_ff]
return self.w_2(self.dropout(F.relu(self.w_1(x))))规范化层和残差连接
Transformer 使用 Layer Normalization(层归一化)和残差连接(Residual Connection)来稳定训练。
残差连接:
其中 是子层本身(可以是注意力层或前馈层)。
Layer Normalization:
在每个样本内部进行归一化,公式:
其中:
- :均值
- :标准差
- :可学习的缩放和偏移参数
代码实现:
class SublayerConnection(nn.Module):
def __init__(self, size, dropout):
# size: 词嵌入维度
super(SublayerConnection, self).__init__()
# 层归一化
self.norm = nn.LayerNorm(size)
# Dropout
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
# x: 上一层的输出
# sublayer: 子层函数(注意力层或前馈层)
# 残差连接 + 层归一化
# 先执行 sublayer(x),再进行 dropout,最后与 x 相加
return x + self.dropout(sublayer(self.norm(x)))编码器层
编码器层是编码器的基本组成单元,由两个子层组成:
- 多头自注意力子层
- 前馈全连接子层
每个子层都使用残差连接和层归一化。
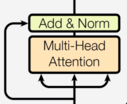
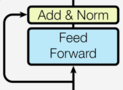
代码实现:
class EncoderLayer(nn.Module):
def __init__(self, size, self_attn, feed_forward, dropout):
# size: 词嵌入维度
# self_attn: 多头注意力实例
# feed_forward: 前馈网络实例
super(EncoderLayer, self).__init__()
# 多头自注意力子层
self.self_attn = self_attn
# 前馈全连接子层
self.feed_forward = feed_forward
# 两个子层连接结构(残差连接 + 层归一化)
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
# x: 输入张量 [batch_size, seq_len, d_model]
# mask: 掩码张量
# 第一个子层:多头自注意力
# lambda x:self.self_attn(x, x, x, mask) 表示 Q=K=V(自注意力)
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
# 第二个子层:前馈全连接
return self.sublayer[1](x, self.feed_forward)辅助函数 clones:
def clones(module, N):
# module: 要克隆的模块
# N: 克隆次数
# 生成 N 个相同的模块,每个模块有独立的参数
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])编码器
编码器由 个编码器层堆叠而成(论文中 )。
代码实现:
class Encoder(nn.Module):
def __init__(self, layer, N):
# layer: 编码器层
# N: 编码器层数
super(Encoder, self).__init__()
# N 个编码器层
self.layers = clones(layer, N)
# 层归一化
self.norm = nn.LayerNorm(layer.size)
def forward(self, x, mask):
# x: 输入张量
# mask: 掩码张量
# 依次通过 N 个编码器层
for layer in self.layers:
x = layer(x, mask)
# 最后进行层归一化
return self.norm(x)解码器
解码器由 个解码器层堆叠而成(论文中 )。
每个解码器层由三个子层组成:
- 多头掩码自注意力子层:关注已生成的输出部分
- 多头编码器-解码器注意力子层:关注编码器的输出
- 前馈全连接子层
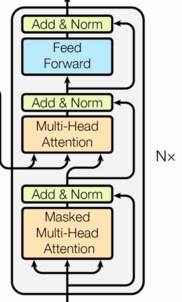
解码器层
代码实现:
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
# size: 词嵌入维度
# self_attn: 多头自注意力实例
# src_attn: 编码器-解码器注意力实例
# feed_forward: 前馈网络实例
super(DecoderLayer, self).__init__()
# 多头掩码自注意力子层
self.self_attn = self_attn
# 编码器-解码器注意力子层
self.src_attn = src_attn
# 前馈全连接子层
self.feed_forward = feed_forward
# 三个子层连接结构
self.sublayer = clones(SublayerConnection(size, dropout), 3)
self.size = size
def forward(self, x, memory, source_mask, target_mask):
# x: 目标端输入 [batch_size, target_len, d_model]
# memory: 编码器输出 [batch_size, source_len, d_model]
# source_mask: 源端掩码
# target_mask: 目标端掩码
# 第一个子层:多头掩码自注意力
# Q=K=V,使用 target_mask 防止看到未来信息
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, target_mask))
# 第二个子层:编码器-解码器注意力
# Q 来自目标端,K=V 来自编码器输出
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, source_mask))
# 第三个子层:前馈全连接
return self.sublayer[2](x, self.feed_forward)解码器
代码实现:
class Decoder(nn.Module):
def __init__(self, layer, N):
# layer: 解码器层
# N: 解码器层数
super(Decoder, self).__init__()
# N 个解码器层
self.layers = clones(layer, N)
# 层归一化
self.norm = nn.LayerNorm(layer.size)
def forward(self, x, memory, source_mask, target_mask):
# x: 目标端输入
# memory: 编码器输出
# source_mask: 源端掩码
# target_mask: 目标端掩码
# 依次通过 N 个解码器层
for layer in self.layers:
x = layer(x, memory, source_mask, target_mask)
# 最后进行层归一化
return self.norm(x)输出部分
输出部分由线性层和 Softmax 层组成,将解码器的输出映射到词表大小的概率分布。
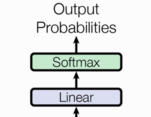
代码实现:
class Generator(nn.Module):
def __init__(self, d_model, vocab_size):
# d_model: 词嵌入维度
# vocab_size: 词表大小
super(Generator, self).__init__()
# 线性层:将 d_model 维映射到 vocab_size 维
self.proj = nn.Linear(d_model, vocab_size)
def forward(self, x):
# x: 解码器输出 [batch_size, seq_len, d_model]
# 线性变换 + log_softmax
# [batch_size, seq_len, d_model] -> [batch_size, seq_len, vocab_size]
return F.log_softmax(self.proj(x), dim=-1)Transformer 模型构建
将所有组件组合起来构建完整的 Transformer 模型。
代码实现:
class TransformerModel(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
# encoder: 编码器
# decoder: 解码器
# src_embed: 源端嵌入层
# tgt_embed: 目标端嵌入层
# generator: 输出层
super(TransformerModel, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, source, target, source_mask, target_mask):
# source: 源端输入 [batch_size, source_len]
# target: 目标端输入 [batch_size, target_len]
# source_mask: 源端掩码
# target_mask: 目标端掩码
# 1. 编码器前向传播
# source_embed: [batch_size, source_len, d_model]
# memory: [batch_size, source_len, d_model]
memory = self.encoder(self.src_embed(source), source_mask)
# 2. 解码器前向传播
# target_embed: [batch_size, target_len, d_model]
# output: [batch_size, target_len, d_model]
output = self.decoder(self.tgt_embed(target), memory,
source_mask, target_mask)
# 3. 输出层映射到词表
# [batch_size, target_len, vocab_size]
return self.generator(output)模型构建函数:
def make_model(source_vocab, target_vocab, N=6, d_model=512,
d_ff=2048, head=8, dropout=0.1):
# source_vocab: 源端词表大小
# target_vocab: 目标端词表大小
# N: 编码器和解码器层数
# d_model: 词嵌入维度
# d_ff: 前馈网络中间层维度
# head: 多头注意力头数
# dropout: Dropout 概率
# 深拷贝注意力模块
c = copy.deepcopy
# 1. 多头注意力实例
attn = MultiHeadedAttention(head, d_model)
# 2. 前馈网络实例
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
# 3. 位置编码实例
position = PositionEncoding(d_model, dropout)
# 4. 构建编码器
encoder = Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N)
# 5. 构建解码器
decoder = Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N)
# 6. 源端嵌入层:词嵌入 + 位置编码
src_embed = nn.Sequential(Embeddings(source_vocab, d_model), c(position))
# 7. 目标端嵌入层:词嵌入 + 位置编码
tgt_embed = nn.Sequential(Embeddings(target_vocab, d_model), c(position))
# 8. 输出生成器
generator = Generator(d_model, target_vocab)
# 9. 组装完整的 Transformer 模型
model = TransformerModel(encoder, decoder, src_embed, tgt_embed, generator)
return model优势
- 并行计算:相比 RNN,Transformer 可以并行处理整个序列,大幅提升训练效率
- 长距离依赖:自注意力机制可以捕捉任意距离的依赖关系
- 可解释性:注意力权重可视化可以帮助理解模型的决策过程
- 通用性强:可以应用于各种 NLP 任务(翻译、分类、生成等)
应用
- 预训练语言模型:BERT、GPT、T5 等
- 机器翻译:Google 翻译等商业系统
- 文本分类:情感分析、主题分类等
- 文本生成:对话系统、文本摘要等
- 代码生成:Copilot、CodeT5 等
发展
- 效率优化:Linformer、Performer、Reformer 等降低计算复杂度
- 多模态:ViT(视觉)、AudioLM(音频)等扩展到其他模态
- 大模型:GPT-3、GPT-4、PaLM 等超大规模语言模型
- 指令微调:ChatGPT、InstructGPT 等对齐人类偏好
Transformer 已经成为现代 NLP 的基石,其影响远超自然语言处理领域,推动了深度学习在多个方向的发展。