
外观
神经网络优化
梯度下降法相关概念
梯度下降法公式:
其中, 是学习率。若学习率太小,那么每次训练后得到的效果都太小,会增大训练的时间成本。如果,学习率太大,那就有可能直接跳过最优解,进入无限的训练中。解决方法是,学习率也需要随着训练的进行而变化。
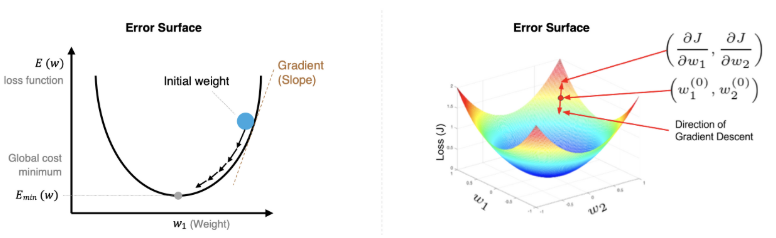
在进行模型训练时,有三个基础的概念:
- Epoch:使用全部数据对模型进行一次完整训练的训练轮次。
- Batch_size:使用训练集中的小部分样本对模型权重进行反向传播的参数更新,每次训练每批次的样本数量。
- Iteration:使用一个 Batch 数据对模型进行一次参数更新的过程。
设数据集有 50000 条训练样本,现在选择 Batch_Size=256 对模型进行训练。
- 每个 Epoch 要训练的图片数量:50000
- 训练集具有的 Batch 个数:
- 每个 Epoch 具有的 Iteration 个数:196
- 10 个 Epoch 具有的 Iteration 个数:1960
在深度学习中,梯度下降不同方式的根本区别就在 Batch Size 不同,如下表所示:
| 梯度下降方式 | 训练集大小 | 批次大小 | 批次数量 |
|---|---|---|---|
| BGD,全梯度下降 | N | N | 1 |
| SGD,随机梯度下降 | N | 1 | N |
| Mini-Batch,随机小批量梯度下降 | N | B | N/B+1 |
注:上表中 Mini-Batch 的 Batch 个数为 N / B + 1 是针对未整除的情况。整除则是 N / B。
反向传播算法
反向传播,Back Propagation,BP 算法,利用损失函数错误值,从后往前,通过梯度下降算法,依次求各个参数的偏导,然后进行参数更新。
下图展示了一个简单的神经网络来举例,激活函数为 sigmoid。
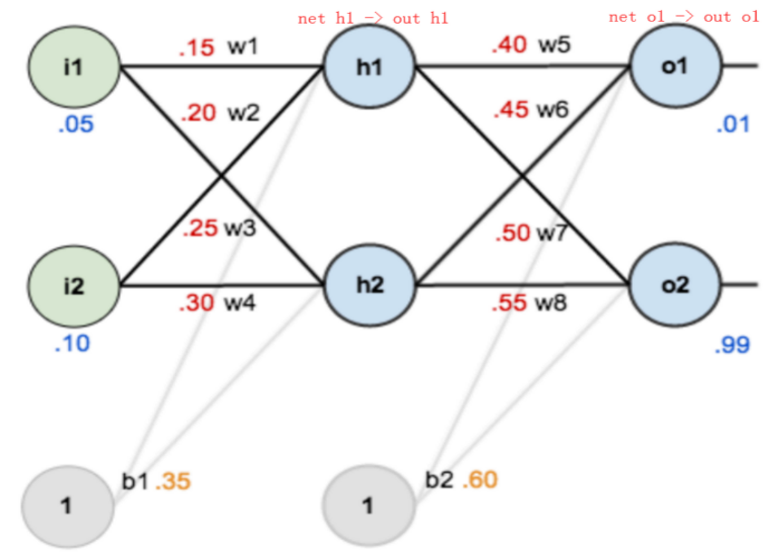
第一步是计算加权求和加激活函数。
首先计算 h1 神经元的加权求和:
然后计算激活函数输出值:
同理,。
按照这个步骤,接着计算 o1 的加权求和:
然后计算激活函数输出值:
同理,
接下来计算损失值:
同理,。
所以:
接下来是反向传播,我们先求误差 对 的导数:
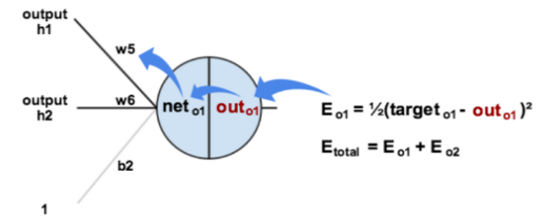
可以看到,这个导数我们拆分成三个偏导相乘,我们从左往右求:
然后来求第二个式子:
最后求 E 对 的导数:
这是个复合函数求导,且求的是 的偏导数,所以右边的可以看做是常数项,于是:
所以:
利用梯度更新参数:
利用此法,求出 ,,。
如果要想求误差 对 的导数,误差 对 的求导路径不止一条,这会稍微复杂一点,但换汤不换药,计算过程如下所示:
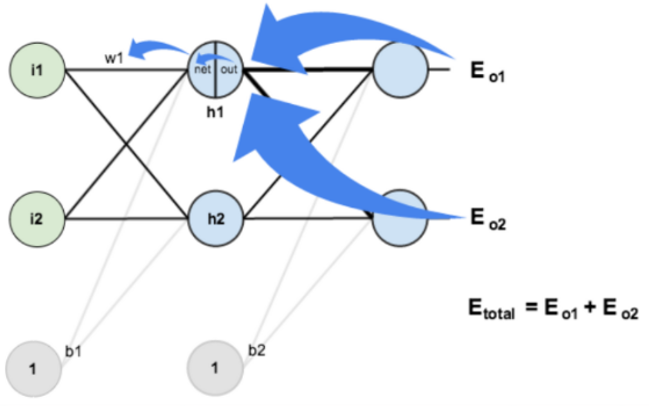
1. 总误差对权重 的偏导数链式法则展开:
2. 权重 的更新计算公式:
梯度下降优化算法
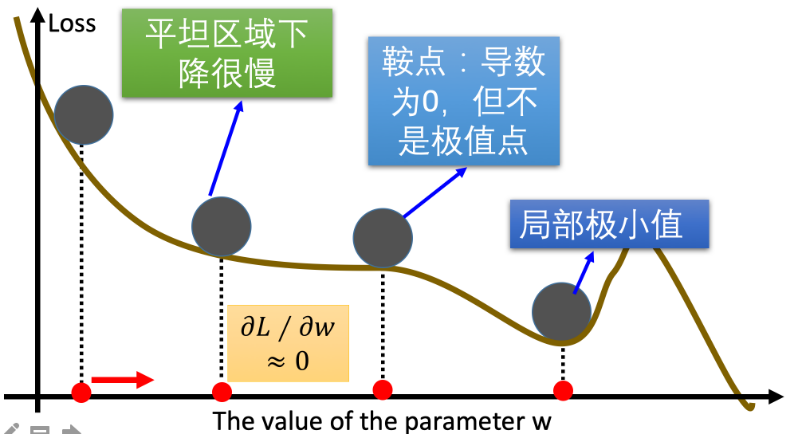
梯度下降优化算法中,可能会碰到以下情况:
- 碰到平缓区域,梯度值较小,参数优化变慢
- 碰到 “鞍点” ,梯度为 0,参数无法优化
- 碰到局部最小值,参数不是最优
对于这些问题, 出现了一些对梯度下降算法的优化方法,例如:Momentum、AdaGrad、RMSprop、Adam 等
指数移动加权平均
指数移动加权平均则是参考各数值,并且各数值的权重都不同,距离越远的数字对平均数计算的贡献就越小(权重较小),距离越近则对平均数的计算贡献就越大(权重越大)。
比如:明天气温怎么样,和昨天气温有很大关系,而和一个月前的气温关系就小一些。计算公式可以用下面的式子来表示:
其中: 表示指数加权平均值 表示 时刻的值 调节权重系数,该值越大平均数越平缓。
通过代码算一下:
import torch
import matplotlib.pyplot as plt
ELEMENT_NUMBER = 30
# 1. 实际平均温度
def dm01():
# 固定随机数种子
torch.manual_seed(0)
# 产生30天的随机温度
temperature = (
torch.randn(
size=[
ELEMENT_NUMBER,
]
)
* 10
)
print(temperature)
# 绘制平均温度
days = torch.arange(1, ELEMENT_NUMBER + 1, 1)
plt.plot(days, temperature, color="r")
plt.scatter(days, temperature)
plt.show()
# 2. 指数加权平均温度
def dm02(beta=0.9):
# 固定随机数种子
torch.manual_seed(0)
# 产生30天的随机温度
temperature = (
torch.randn(
size=[
ELEMENT_NUMBER,
]
)
* 10
)
print(temperature)
exp_weight_avg = []
# idx从1开始
for idx, temp in enumerate(temperature, 1):
# 第一个元素的 EWA 值等于自身
if idx == 1:
exp_weight_avg.append(temp)
continue
# 第二个元素的 EWA 值等于上一个 EWA 乘以 β + 当前气温乘以 (1-β)
# idx-2:2-2=0,exp_weight_avg列表中第一个值的下标值
new_temp = exp_weight_avg[idx - 2] * beta + (1 - beta) * temp
exp_weight_avg.append(new_temp)
days = torch.arange(1, ELEMENT_NUMBER + 1, 1)
plt.plot(days, exp_weight_avg, color="r")
plt.scatter(days, temperature)
plt.show()
if __name__ == "__main__":
dm01() # 不考虑 权重系数, 每个值的权重都一致.
dm02(0.5) # 考虑 权重系数, 值越小, 数据越陡.
dm02(0.9) # 考虑 权重系数, 值越大, 数据越平缓.9tensor([-11.2584, -11.5236, -2.5058, -4.3388, 8.4871, 6.9201, -3.1601,
-21.1522, 3.2227, -12.6333, 3.4998, 3.0813, 1.1984, 12.3766,
-1.4347, -1.1161, -6.1358, 0.3159, -4.9268, 2.4841, 4.3970,
1.1241, -8.4106, -23.1604, -1.0231, 7.9244, -2.8967, 0.5251,
5.2286, 23.0221])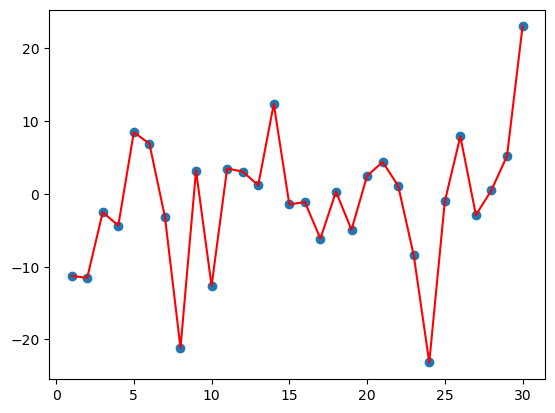
tensor([-11.2584, -11.5236, -2.5058, -4.3388, 8.4871, 6.9201, -3.1601,
-21.1522, 3.2227, -12.6333, 3.4998, 3.0813, 1.1984, 12.3766,
-1.4347, -1.1161, -6.1358, 0.3159, -4.9268, 2.4841, 4.3970,
1.1241, -8.4106, -23.1604, -1.0231, 7.9244, -2.8967, 0.5251,
5.2286, 23.0221])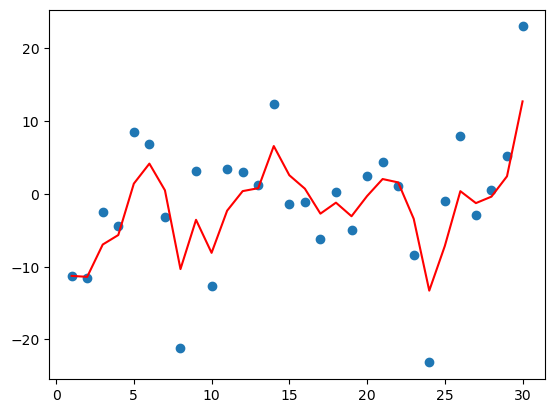
tensor([-11.2584, -11.5236, -2.5058, -4.3388, 8.4871, 6.9201, -3.1601,
-21.1522, 3.2227, -12.6333, 3.4998, 3.0813, 1.1984, 12.3766,
-1.4347, -1.1161, -6.1358, 0.3159, -4.9268, 2.4841, 4.3970,
1.1241, -8.4106, -23.1604, -1.0231, 7.9244, -2.8967, 0.5251,
5.2286, 23.0221])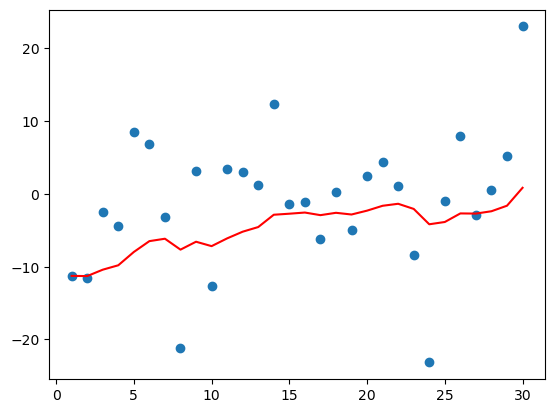
从上图可以看出:
- 指数加权平均绘制出的气温变化曲线更加平缓,
- β 的值越大,则绘制出的折线越加平缓,波动越小。(1-β 越小,t 时刻的 St 越不依赖 Yt 的值)
- β 值一般默认都是 0.9
动量算法 Momentum
动量法用于优化梯度。
梯度计算公式:
参数更新公式:
其中:
- 是当前时刻指数加权平均梯度值
- 是历史指数加权平均梯度值
- 是当前时刻的梯度值
- 是调节权重系数,通常取 0.9 或 0.99
- 是学习率
- 是当前时刻模型权重参数
Momentum 在 PyTorch 中的 API 在反向传播算法中使用参数 momentum 指定。
import torch
import torch.optim as optim
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
# 定义损失函数
criterion = (w**2) / 2.0
# 创建优化器(函数对象) -> 基于SGD(随机梯度下降), 加入参数 momentum, 就是动量法
# 参1: (待优化的)参数列表, 参2: 学习率, 参3: 动量参数.
optimizer = optim.SGD(params=[w], lr=0.01, momentum=0.9)
# 若momentum=0(默认), 表示只考虑本次梯度
optimizer.zero_grad()
criterion.sum().backward()
optimizer.step()
print(f"w: {w}, w.grad: {w.grad}")
# w: tensor([0.9900], requires_grad=True), w.grad: tensor([1.])
# 再次执行优化过程
criterion = (w**2) / 2.0
optimizer.zero_grad()
criterion.sum().backward()
optimizer.step()
print(f"w: {w}, w.grad: {w.grad}")
# w: tensor([0.9711], requires_grad=True), w.grad: tensor([0.9900])AdaGrad
AdaGrad 通过对不同的参数分量使用不同的学习率,AdaGrad 的学习率总体会逐渐减小。
其计算步骤如下:
- 初始化学习率 ,初始化参数 ,初始化小常数
- 初始化梯度累积变量
- 从训练集中采样 个样本的小批量,计算梯度
- 累积平方梯度:
- 学习率 的计算公式:
- 权重参数更新公式:
- 重复 3~7 步动作不断优化学习率
AdaGrad 缺点是可能会使得学习率过早、过量的降低,导致模型训练后期学习率太小,较难找到最优解。
AdaGrad 在 PyTorch 中的 API 为 torch.optim.Adagrad:
import torch
import torch.optim as optim
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
# 定义损失函数
criterion = (w**2) / 2.0
# 基于AdaGrad(自适应学习率)
optimizer = optim.Adagrad(params=[w], lr=0.01)
# 计算梯度值: 梯度清零 + 反向传播 + 参数更新
optimizer.zero_grad()
criterion.sum().backward()
optimizer.step()
print(f"w: {w}, w.grad: {w.grad}")
# w: tensor([0.9900], requires_grad=True), w.grad: tensor([1.])
# 第2次更新权重参数
criterion = (w**2) / 2.0
optimizer.zero_grad()
criterion.sum().backward()
optimizer.step()
print(f"w: {w}, w.grad: {w.grad}")
# w: tensor([0.9830], requires_grad=True), w.grad: tensor([0.9900])RMSProp
AdaGrad 的缺点是可能使学习率过早、过量地降低。RMSProp 优化算法是对 AdaGrad 的优化. 最主要的不同是,其使用指数加权平均梯度替换历史梯度的平方和。其计算过程如下:
- 初始化学习率 ,初始化参数 ,初始化小常数
- 初始化梯度累积变量
- 从训练集中采样 个样本的小批量,计算梯度
- 使用指数加权计算平均累积平方梯度:
- 学习率 的计算公式:
- 权重参数更新公式:
- 重复 3~7 步动作不断优化学习率
RMSProp 在 PyTorch 中的 API 为 torch.optim.RMSProp
import torch
import torch.optim as optim
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
# 定义损失函数
criterion = (w**2) / 2.0
# 基于AdaGrad(自适应学习率)
optimizer = optim.RMSprop(params=[w], lr=0.01, alpha=0.99)
# 计算梯度值: 梯度清零 + 反向传播 + 参数更新
optimizer.zero_grad()
criterion.sum().backward()
optimizer.step()
print(f"w: {w}, w.grad: {w.grad}")
import torch
import torch.optim as optim
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
# 定义损失函数
criterion = (w**2) / 2.0
# 基于AdaGrad(自适应学习率)
optimizer = optim.RMSprop(params=[w], lr=0.01, alpha=0.99)
# 计算梯度值: 梯度清零 + 反向传播 + 参数更新
optimizer.zero_grad()
criterion.sum().backward()
optimizer.step()
print(f"w: {w}, w.grad: {w.grad}")
# w: tensor([0.9900], requires_grad=True), w.grad: tensor([1.])
# 第2次更新权重参数
criterion = (w**2) / 2.0
optimizer.zero_grad()
criterion.sum().backward()
optimizer.step()
print(f"w: {w}, w.grad: {w.grad}")
# w: tensor([0.9830], requires_grad=True), w.grad: tensor([0.9900])
# 第2次更新权重参数
criterion = (w**2) / 2.0
optimizer.zero_grad()
criterion.sum().backward()
optimizer.step()
print(f"w: {w}, w.grad: {w.grad}")
# w: tensor([0.8329], requires_grad=True), w.grad: tensor([0.9000])Adam
Momentum 使用指数加权平均计算优化梯度值,AdaGrad、RMSProp 使用自适应学习率。Adam 优化算法(Adaptive Moment Estimation,自适应矩估计)将 Momentum 和 RMSProp 算法结合在一起,可同时优化学习率和梯度。
原理:Adam 是结合了 Momentum 和 RMSProp 优化算法的优点的自适应学习率算法。它计算了梯度的一阶矩(平均值)和二阶矩(梯度的方差)的自适应估计,从而动态调整学习率。
梯度计算公式:
权重参数更新公式:
其中, 是梯度的一阶矩估计, 是梯度的二阶矩估计, 和 是偏差校正后的估计。
Adam 在 PyTorch 中的 API 为 torch.optim.Adam(params, lr, betas)。
import torch
import torch.optim as optim
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
criterion = (w ** 2) / 2.0
optimizer = optim.Adam(params=[w], lr=0.01, betas=(0.9, 0.999)) # betas=(梯度用的 衰减系数, 学习率用的 衰减系数)
optimizer.zero_grad()
criterion.sum().backward()
optimizer.step()
print(f'w: {w}, w.grad: {w.grad}')
# w: tensor([0.9900], requires_grad=True), w.grad: tensor([1.])
criterion = (w ** 2) / 2.0
optimizer.zero_grad()
criterion.sum().backward()
optimizer.step()
print(f'w: {w}, w.grad: {w.grad}')
# w: tensor([0.9800], requires_grad=True), w.grad: tensor([0.9900])学习率衰减方法
除了通过上述算法自动优化学习率,还可以手动优化学习率。
优化学习率可以使模型前期收敛速度快,后期收敛速度慢。
等间隔学习率衰减
等间隔学习率衰减方式如下所示:
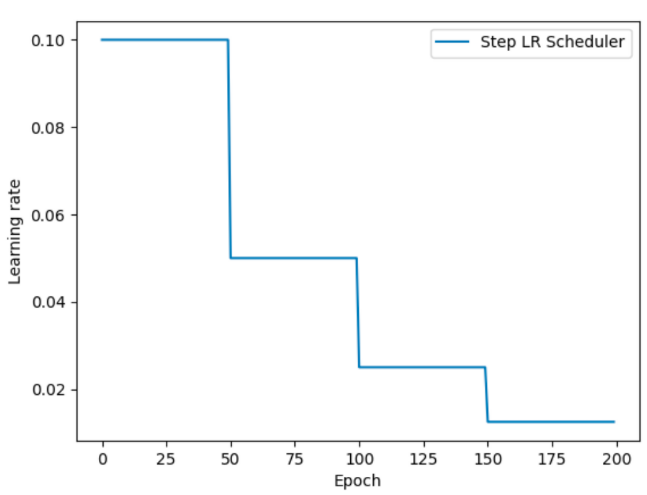
PyTorch API:
# step_size:调整间隔数=50
# gamma:调整系数=0.5
# 调整方式:lr = lr * gamma
lr_scheduler.StepLR(optimizer, step_size, gamma=0.1)示例:
demo.py
from matplotlib import pyplot as plt
import torch
# 定义学习率、训练轮数、训练的批次数
lr, epochs, iteration = 0.1, 200, 10
# 创建数据集
y_true = torch.tensor([0])
# 输入特征
x = torch.tensor([1.0], dtype=torch.float32)
# 权重参数w, 需要自动微分(求导)
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
# 创建优化器对象, 动量法 -> 加速模型的收敛, 减少震荡
# 参1: 待优化的参数, 参2: 学习率, 参3: 动量系数
optimizer = torch.optim.SGD([w], lr=lr, momentum=0.9)
# 创建等间隔学习率衰减对象.
# 参1: 优化器对象, 参2: 间隔的轮数(多少轮调整一次学习率), 参3: 学习率衰减系数.
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.5) # [0.1, 0.1, 0.1... 0.05...]
# 创建两个列表, 分别表示: 训练轮数, 每轮训练用的学习率
# epoch_list = [0, 1, 2, 3.... 50, 51, 52...100, 101, 101... 150, 151...199]
# lr_list = [0.1, 0.1, 0.1, 0.05........,0.025........., 0.0125...]
lr_list, epoch_list = [], []
# 循环遍历训练轮数, 进行具体的训练.
for epoch in range(epochs): # epoch: 0 ~ 199
# 获取当前轮数和学习率, 并保存到列表中
epoch_list.append(epoch)
lr_list.append(scheduler.get_last_lr()) # 获取最后的lr(learning rate, 学习率)
# 循环遍历, 每轮每批次进行训练.
for batch in range(iteration):
# 先计算预测值, 然后基于损失函数计算损失
y_pred = w * x
# 计算损失, 最小二乘法.
loss = (y_pred - y_true) ** 2
# 梯度清零 + 反向传播 + 优化器更新参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 更新学习率
scheduler.step()
print(f"lr_list: {lr_list}") # [0.1, 0.1, 0.1..., 0.05........,0.025........., 0.0125...]
plt.plot(epoch_list, lr_list)
plt.xlabel("Epoch")
plt.ylabel("Learning Rate")
plt.show()运行结果.txt
lr_list: [[0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125]]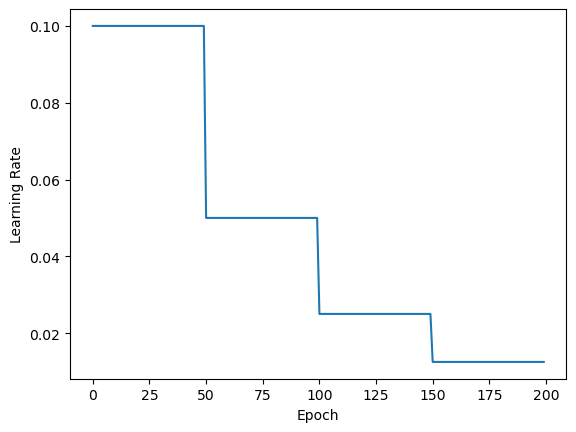
指定间隔学习率衰减
指定间隔学习率衰减的效果如下:
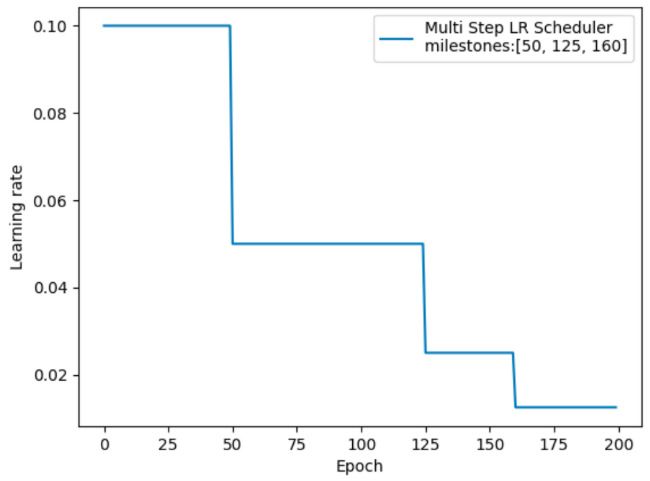
PyTorch API:
# milestones:设定调整轮次:[50, 125, 160]
# gamma:调整系数
# 调整方式:lr = lr * gamma
optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1)代码示例:
demo.py
import torch
from torch import optim
import matplotlib.pyplot as plt
# 设置学习率、训练轮数和迭代次数
lr, epochs, iteration = 0.1, 200, 10
# 定义真实值
y_true = torch.tensor([0])
# 定义输入数据x
x = torch.tensor([1.0], dtype=torch.float32)
# 定义权重参数w,并设置需要计算梯度
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
# 定义优化器为SGD,设置学习率和动量
optimizer = optim.SGD([w], lr=lr, momentum=0.9)
# 定义学习率调整策略,在第50、125、160轮时将学习率减半
milestones = [50, 125, 160]
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=milestones, gamma=0.5)
# 初始化学习率和轮数的列表
lr_list, epoch_list = [], []
# 开始训练循环
for epoch in range(epochs):
# 记录当前轮数
epoch_list.append(epoch)
# 记录当前学习率
lr_list.append(scheduler.get_last_lr())
# 批量训练循环
for batch in range(iteration):
# 计算预测值
y_pred = w * x
# 计算损失函数
loss = (y_pred - y_true) ** 2
# 清空梯度
optimizer.zero_grad()
# 反向传播计算梯度
loss.backward()
optimizer.step()
scheduler.step()
print(f'lr_list: {lr_list}')
# 打印学习率变化列表
plt.plot(epoch_list, lr_list)
plt.xlabel('Epoch')
# 绘制学习率变化曲线
plt.ylabel('Learning Rate')
plt.show()运行结果.txt
lr_list: [[0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.1], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.05], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.025], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125], [0.0125]]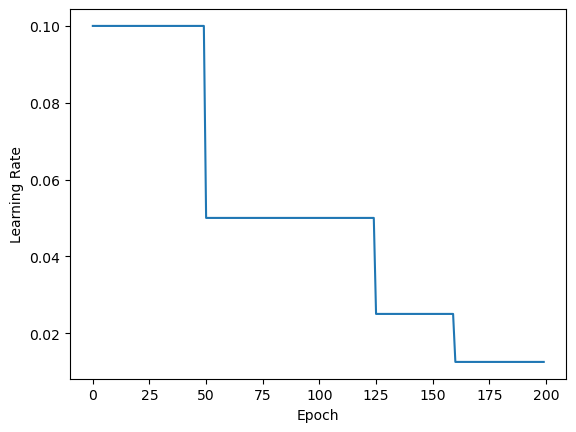
按指数学习率衰减
按指数学习率衰减的效果如下:
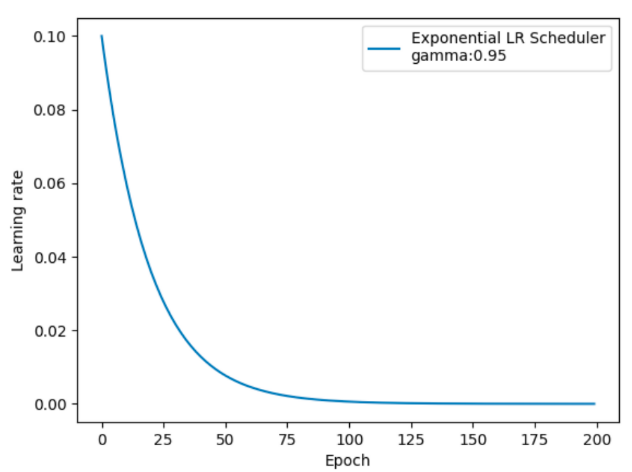
PyTorch API:
# gamma:指数的底
# 调整方式
# lr= lr∗ gamma^epoch
optim.lr_scheduler.ExponentialLR(optimizer, gamma)代码示例:
demo.py
import torch
from torch import optim
import matplotlib.pyplot as plt
# 设置学习率、训练轮数和每次epoch的迭代次数
lr, epochs, iteration = 0.1, 200, 10
# 创建真实值张量,值为0
y_true = torch.tensor([0])
# 创建输入特征x,值为1.0,数据类型为float32
x = torch.tensor([1.0], dtype=torch.float32)
# 创建权重参数w,初始值为1.0,需要计算梯度,数据类型为float32
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
# 创建随机梯度下降优化器,使用动量0.9
optimizer = optim.SGD([w], lr=lr, momentum=0.9)
# 创建学习率调度器,使用指数衰减,衰减系数为0.95
scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.95)
# 初始化学习率和epoch列表,用于记录变化
lr_list, epoch_list = [], []
# 开始训练循环
for epoch in range(epochs):
# 记录当前epoch
epoch_list.append(epoch)
# 记录当前学习率
lr_list.append(scheduler.get_last_lr())
# 每个epoch内的迭代
for batch in range(iteration):
# 计算预测值
y_pred = w * x
# 计算损失函数,使用均方误差
loss = (y_pred - y_true) ** 2
optimizer.zero_grad()
loss.backward()
# 反向传播计算梯度
optimizer.step()
# 更新参数
scheduler.step()
# 更新学习率
print(f"lr_list: {lr_list}")
plt.plot(epoch_list, lr_list)
plt.xlabel("Epoch")
# 绘制学习率随epoch变化的曲线
plt.ylabel("Learning Rate")
# 设置x轴标签
plt.show() # 设置y轴标签运行结果.txt
lr_list: [[0.1], [0.095], [0.09025], [0.0857375], [0.08145062499999998], [0.07737809374999999], [0.07350918906249998], [0.06983372960937498], [0.06634204312890622], [0.0630249409724609], [0.05987369392383786], [0.05688000922764597], [0.05403600876626367], [0.05133420832795048], [0.04876749791155295], [0.046329123015975304], [0.04401266686517654], [0.04181203352191771], [0.039721431845821824], [0.037735360253530734], [0.035848592240854196], [0.03405616262881148], [0.03235335449737091], [0.030735686772502362], [0.029198902433877242], [0.027738957312183378], [0.026352009446574207], [0.025034408974245494], [0.023782688525533217], [0.022593554099256556], [0.021463876394293726], [0.020390682574579037], [0.019371148445850084], [0.01840259102355758], [0.0174824614723797], [0.016608338398760712], [0.015777921478822676], [0.014989025404881541], [0.014239574134637464], [0.01352759542790559], [0.012851215656510309], [0.012208654873684792], [0.011598222130000552], [0.011018311023500524], [0.010467395472325497], [0.009944025698709221], [0.00944682441377376], [0.00897448319308507], [0.008525759033430816], [0.008099471081759275], [0.007694497527671311], [0.007309772651287745], [0.006944284018723357], [0.006597069817787189], [0.006267216326897829], [0.005953855510552938], [0.005656162735025291], [0.005373354598274026], [0.005104686868360324], [0.004849452524942308], [0.004606979898695193], [0.004376630903760433], [0.0041577993585724116], [0.0039499093906437905], [0.0037524139211116006], [0.0035647932250560204], [0.003386553563803219], [0.003217225885613058], [0.0030563645913324047], [0.0029035463617657843], [0.002758369043677495], [0.00262045059149362], [0.002489428061918939], [0.002364956658822992], [0.002246708825881842], [0.00213437338458775], [0.0020276547153583622], [0.001926271979590444], [0.0018299583806109217], [0.0017384604615803755], [0.0016515374385013568], [0.0015689605665762888], [0.0014905125382474742], [0.0014159869113351004], [0.0013451875657683454], [0.001277928187479928], [0.0012140317781059316], [0.001153330189200635], [0.0010956636797406032], [0.001040880495753573], [0.0009888364709658944], [0.0009393946474175996], [0.0008924249150467197], [0.0008478036692943836], [0.0008054134858296644], [0.0007651428115381812], [0.000726885670961272], [0.0006905413874132084], [0.0006560143180425479], [0.0006232136021404205], [0.0005920529220333994], [0.0005624502759317294], [0.0005343277621351429], [0.0005076113740283857], [0.00048223080532696635], [0.00045811926506061804], [0.0004352133018075871], [0.00041345263671720774], [0.00039278000488134735], [0.00037314100463728], [0.000354483954405416], [0.00033675975668514516], [0.0003199217688508879], [0.00030392568040834347], [0.0002887293963879263], [0.00027429292656852995], [0.00026057828024010345], [0.00024754936622809826], [0.00023517189791669334], [0.00022341330302085867], [0.00021224263786981574], [0.00020163050597632494], [0.0001915489806775087], [0.00018197153164363326], [0.0001728729550614516], [0.00016422930730837902], [0.00015601784194296006], [0.00014821694984581206], [0.00014080610235352146], [0.0001337657972358454], [0.0001270775073740531], [0.00012072363200535044], [0.00011468745040508291], [0.00010895307788482875], [0.00010350542399058731], [9.833015279105794e-05], [9.341364515150504e-05], [8.874296289392978e-05], [8.430581474923329e-05], [8.009052401177162e-05], [7.608599781118304e-05], [7.228169792062389e-05], [6.866761302459269e-05], [6.523423237336306e-05], [6.19725207546949e-05], [5.8873894716960144e-05], [5.5930199981112136e-05], [5.3133689982056524e-05], [5.0477005482953695e-05], [4.7953155208806006e-05], [4.55554974483657e-05], [4.327772257594741e-05], [4.111383644715004e-05], [3.9058144624792534e-05], [3.7105237393552906e-05], [3.524997552387526e-05], [3.34874767476815e-05], [3.1813102910297426e-05], [3.0222447764782554e-05], [2.8711325376543424e-05], [2.727575910771625e-05], [2.5911971152330435e-05], [2.461637259471391e-05], [2.3385553964978216e-05], [2.2216276266729303e-05], [2.1105462453392836e-05], [2.0050189330723194e-05], [1.9047679864187035e-05], [1.8095295870977683e-05], [1.71905310774288e-05], [1.6331004523557357e-05], [1.5514454297379488e-05], [1.4738731582510512e-05], [1.4001795003384986e-05], [1.3301705253215736e-05], [1.2636619990554949e-05], [1.2004788991027201e-05], [1.140454954147584e-05], [1.0834322064402047e-05], [1.0292605961181944e-05], [9.777975663122847e-06], [9.289076879966705e-06], [8.82462303596837e-06], [8.38339188416995e-06], [7.964222289961452e-06], [7.566011175463379e-06], [7.18771061669021e-06], [6.8283250858556995e-06], [6.4869088315629144e-06], [6.162563389984768e-06], [5.85443522048553e-06], [5.561713459461253e-06], [5.28362778648819e-06], [5.019446397163781e-06], [4.768474077305592e-06], [4.530050373440312e-06], [4.303547854768296e-06], [4.088370462029881e-06], [3.883951938928387e-06], [3.689754341981967e-06]]
正则化
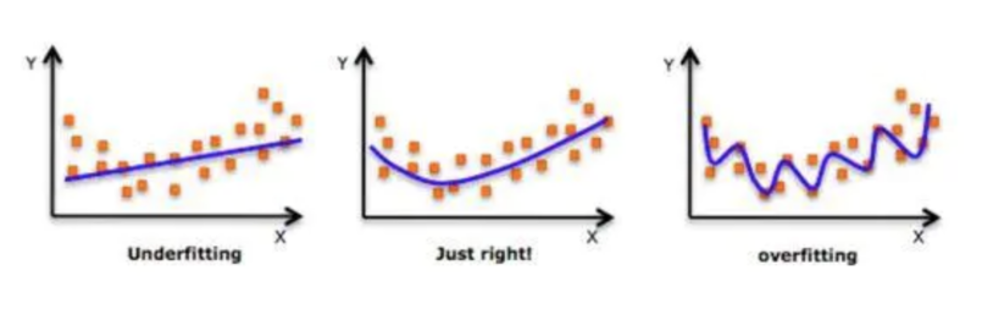
在设计机器学习算法时希望在新样本上的泛化能力强。许多机器学习算法都采用相关的策略来减小测试误差,这些策略被统称为正则化。
神经网络强大的表示能力经常遇到过拟合,所以需要使用不同形式的正则化策略。
目前在深度学习中使用较多的策略有范数惩罚,DropOut,特殊的网络层等,接下来我们对其进行详细的介绍。
Dropout 正则化
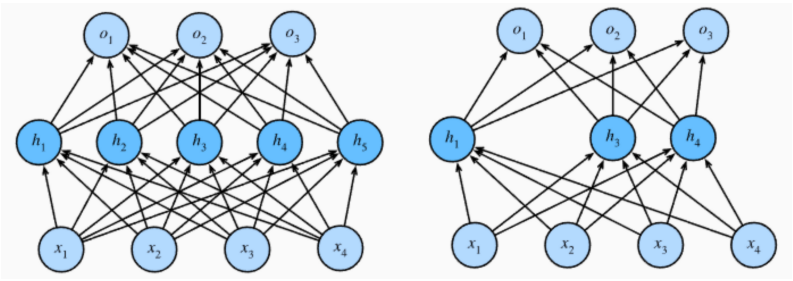
在训练过程中,Dropout 的实现是让神经元以超参数 p 的概率停止工作或者激活被置为 0,未被置为0的进行缩放,缩放比例为 1/(1-p)。训练过程可以认为是对完整的神经网络的一些子集进行训练,每次基于输入数据只更新子网络的参数。
注意,在测试过程中,随机失活不起作用。
PyTorch API:torch.nn.Dropout(p),其中 p 为神经元失活的概率。
demo.py
import torch
import torch.nn as nn
# 创建一个1行4列的随机整数张量,值范围在0到10之间,并转换为浮点类型
t1 = torch.randint(0, 10, size=(1, 4)).float()
print(f"t1: {t1}")
# 创建一个线性层,输入维度为4,输出维度为5
linear1 = nn.Linear(4, 5)
# 将输入张量t1通过线性层进行变换
l1 = linear1(t1)
print(f"l1: {l1}")
# 对线性层的输出应用ReLU激活函数
output = torch.relu(l1)
print(f"output: {output}")
# 创建一个Dropout层,设置失活概率为0.5
dropout = nn.Dropout(p=0.5)
# 对ReLU的输出应用Dropout,随机将一部分神经元置0
d1 = dropout(output)
print(f"d1(随机失活后的数据): {d1}")运行结果.txt
t1: tensor([[3., 4., 7., 1.]])
l1: tensor([[-0.6592, -3.2035, -4.8324, 0.2795, -2.2601]],
grad_fn=<AddmmBackward0>)
output: tensor([[0.0000, 0.0000, 0.0000, 0.2795, 0.0000]], grad_fn=<ReluBackward0>)
d1(随机失活后的数据): tensor([[0., 0., 0., 0., 0.]], grad_fn=<MulBackward0>)批量归一化
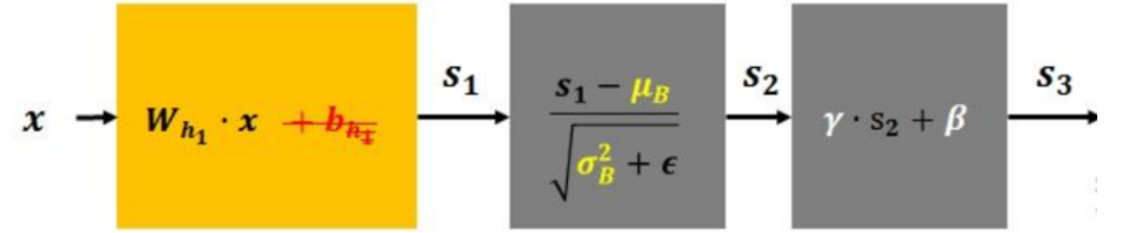
先对数据标准化,再对数据重构(缩放+平移),如下所示:
- 和 是可学习参数,它相当于对标准化后的值做了一个线性变换, 是系数, 是偏置;
- 通常指定为 1e-5,避免分母为 0;
- 表示变量的均值;
- 表示变量的方差。
批量归一化层在计算机视觉领域使用较多。
PyTorch API:torch.nn.BatchNorm2d/BatchNorm1d
demo.py
import torch
import torch.nn as nn
# 创建一个BatchNorm2d层,参数包括:
# num_features: 2 (输入特征的数量)
# eps: 1e-05 (保证数值稳定性的小常数)
# momentum: 0.1 ( running_mean和running_var的更新速率)
# affine: True (启用可学习的仿射变换参数weight和bias)
m = nn.BatchNorm2d(2, eps=1e-05, momentum=0.1, affine=True) # affine参数设为True表示weight和bias将被使用
# 创建一个随机输入张量,形状为(1, 2, 3, 4),表示:
# batch_size=1, channels=2, height=3, width=4
input = torch.randn(1, 2, 3, 4)
print("input-->", input)
# 将输入通过BatchNorm2d层进行归一化处理
output = m(input)
print("output-->", output)
print(output.size()) # 输出张量的尺寸
# 打印BatchNorm2d层的可学习参数
print(m.weight) # 打印权重参数,形状为(2,)
print(m.bias) # 打印偏置参数,形状为(2,)运行结果.txt
input--> tensor([[[[ 0.0987, -1.8033, 0.7302, -0.1818],
[ 0.7389, -0.1907, -0.5074, 0.3025],
[-0.6416, -0.8441, -0.9390, 1.2396]],
[[-1.2640, -0.4456, -0.0787, -0.4525],
[-1.9161, 1.5405, 2.3303, 0.9832],
[-1.0789, -1.8741, 1.1470, 0.0403]]]])
output--> tensor([[[[ 0.3254, -2.0085, 1.1003, -0.0188],
[ 1.1110, -0.0297, -0.4183, 0.5756],
[-0.5830, -0.8315, -0.9480, 1.7255]],
[[-0.9023, -0.2738, 0.0079, -0.2791],
[-1.4031, 1.2515, 1.8579, 0.8234],
[-0.7602, -1.3709, 0.9493, 0.0994]]]],
grad_fn=<NativeBatchNormBackward0>)
torch.Size([1, 2, 3, 4])
Parameter containing:
tensor([1., 1.], requires_grad=True)
Parameter containing:
tensor([0., 0.], requires_grad=True)