
外观
线性回归
线性回归(Linear regression)是利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式。
公式:
其中, 是 条特征,在这里代表 、、……、; 是特征 的权重; 是偏置,。
在线性回归中,从数据中获取的规律就是学习权重系数 ; 越大,这个这个权重的数据对标签影响最大。
因为求解的 都是 (常数项),所以叫线性模型。
上面公式代表的是多元线性回归(元,自变量,特征值),如果只有一个特征,公式就是 ,也称为一元线性回归。
导数
定义
当函数 的自变量 在一点 上产生一个增量 时,函数输出值的增量 与自变量增量 的比值在 趋于0时的极限 如果存在, 即为在 处的导数,记作 或 。
导数是函数的局部性质。一个函数在某一点的导数描述了这个函数在这一点附近的变化率。
函数在某一点的导数就是该函数所代表的曲线在这一点上的切线斜率。
常见函数的导数
| 公式 | 例子 |
|---|---|
导数的四则运算
| 公式 | 例子 |
|---|---|
复合函数求导: 是外函数 是内函数。先对外函数求导,再对内函数求导。
导数为 0 的位置就是函数的极值点。
偏导数
偏导数用于研究多元函数中某一个变量变化时,函数值的变化率,同时保持其他变量不变。设函数:
则:
- 对 的偏导:只让 变化, 固定
- 对 的偏导:只让 变化, 固定
定义:
向量
向量是有大小和方向的,几何意义上表示:
- 向量
- 向量
向量基本运算
向量转置
范数
范数(norm)是数学中的一种基本概念,具有长度的意义。
范数(L1范数):向量中各个元素绝对值之和,如
2范数(L2范数):向量的模长,每个元素平方求和,再开平方根,如
p-范数:向量中每个元素p次幂求和后开p次方根,如
矩阵
矩阵是一个按行和列排列的数表,通常用于表示线性映射或线性变换。
一个 的矩阵写作:
- :行数
- :列数
- :第 行第 列元素
记作:
特殊矩阵
一行向量:
两列向量:
方阵(行数=列数):;对称方阵:沿着主对角线,元素对称
单位矩阵,可以用 或 表示:
矩阵加法和减法
矩阵乘法
规则:
- 对应行列元素相乘
- 然后求和
设:
则:
维度关系:
向量和矩阵的关系
向量是特殊的矩阵:
- 列向量: 矩阵
- 行向量:矩阵
矩阵可以看成多个向量的组合:
即:
- 每一列是一个列向量
- 矩阵是多个向量的组合
矩阵与向量相乘
设:
则:
展开形式:
矩阵乘法的性质
不满足交换律
例如:
则:
两者维度不同,因此通常:
特殊情况下可能交换
若:
- 与 为同阶方阵
- 且满足特定条件
则可能:
例如:
满足结合律
矩阵乘法满足结合律:
若:
则:
单位矩阵
矩阵与单位矩阵相乘等于矩阵本身:
其中 为单位矩阵
逆矩阵
若:
存在矩阵 使得:
则:
- 为 的逆矩阵
- 记作:
矩阵转置
性质:
- , 为常数
损失函数
什么是损失函数
误差:样本的预测值减去真实值。样本的预测值就是通过自变量 x 计算出的 y。
损失函数:衡量每个样本预测值和真实值效果的函数。一元线性回归中,用 表示。
常用损失函数
最小二乘:
均方误差:
平均绝对误差:
为真实值, 为预测值。
简要区别:
| 名称 | 是否平方 | 是否取平均 | 是否对异常值敏感 |
|---|---|---|---|
| 最小二乘 | ✅️ | ❌️ | 高 |
| MSE | ✅️ | ✅️ | 高 |
| MAE | ❌️ | ✅️ | 低 |
正规方程法
正规方程法是一种解析解方法,用于在线性回归中直接求解最优参数,而无需迭代优化(如梯度下降)。
问题背景
在线性回归中,我们希望最小化均方误差(MSE)损失函数:
其中:
- :样本数量
- :特征数量
- :特征矩阵(已包含偏置列1)
- :参数向量
- :真实值向量
正规方程推导
对损失函数求导并令其等于 0:
得到:
若 可逆,则:
这就是正规方程(Normal Equation)。
核心公式
矩阵维度说明
| 符号 | 维度 |
|---|---|
算法步骤
- 构造特征矩阵 (第一列为1)
- 计算
- 求逆矩阵
- 计算
- 得到参数:
公式理解
各符号含义
为特征矩阵,形式为:
维度为:
含义:
- m: 样本数量
- n: 特征数量
- 第一列为1,是为了计算偏置项
真实值向量
维度为:
含义:每个样本对应的真实标签。
模型参数
维度为:
含义:线性回归模型的权重。
模型形式:
矩阵形式:
公式理解:
- 是一个 向量,即参数向量。
梯度下降法
梯度下降法,Gradient Descent,GD,在机器学习里很常用。
释义:沿着梯度下降的方向求解损失函数的极小值,用于寻找线性回归中的最优超参数。
单变量梯度下降
梯度:单变量函数中,梯度是某点的切线斜率(该点的导数值),有方向为函数增长最快的方向。多变量函数中,梯度是某点的偏导数,有方向为偏导数分量的向量方向。
步骤:
- 输入:初始化位置 ;每步距离为 。输出:从位置 到达山底。
- 步骤1:令初始化位置为山的任意位置 ;
- 步骤2:在当前位置环顾四周,如果四周都比 高返回 ,否则执行步骤3;
- 步骤3:在当前位置环顾四周,寻找坡度最陡的方向,令其为 方向;
- 步骤4:沿着 方向往下走,长度为 ,到达新的位置 ;
- 步骤5:在 位置环顾四周,如果四周都比 高,则返回 ,否则转到步骤3。
公式:
- 为下一点的梯度值, 为当前值。
- 为学习率(步长),不能太大,也不能太小。太大会震荡,太小走的太慢,迭代次数太多。在机器学习中,此参数选择 。
- 为损失函数。
梯度是上升最快的方向,但是我们要求的是极小值,所以要走下降最快的方向,需要的是导数的相反数。
例:函数 ,取学习率为 0.4,求 为何值时 值最小。
函数关于 的导数为:
初始化起点为:1 ,学习率:
我们开始进行梯度下降的迭代计算过程:
第一步:
第二步:
第三步:
第四步:
第五步:
....
第N步: 已经极其接近最优值 , 也接近最小值。
经过四次的运算,即走了四步,基本抵达了函数的最低点。
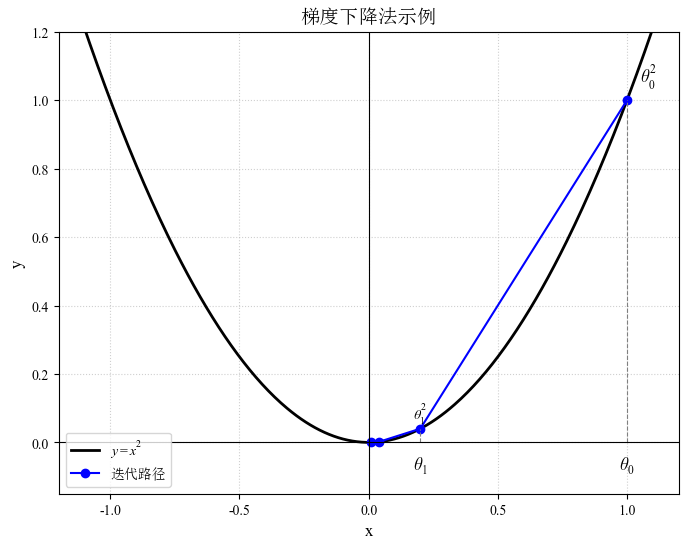
多变量梯度下降
例:,求当 和 为何值时, 最小。
函数关于 的导数为:
函数关于 的导数为:
则 的梯度为:
初始值: 起点为: ,学习率为:
最小值是 点,下面使用梯度下降法一步步的计算。
我们开始进行梯度下降的迭代过程:
第一步:
第二步:
第 步: 已经极其接近最优值, 也接近最小值。
梯度下降法分类
设:
- :样本总数
- :特征数(不含偏置时)
- :第 个样本的特征向量
- :第 个样本的第 个特征
- :第 个样本的真实标签
- :模型参数
- :学习率(learning rate)
- :模型对第 个样本的预测值
全梯度下降(FGD, Full Gradient Descent)
特点:每次参数更新都使用全部 个样本计算梯度:
特征:
- 梯度精确(是真实损失函数的完整梯度)
- 收敛路径稳定
- 计算成本高(每次迭代需要遍历全部样本)
- 适合小规模数据集
随机梯度下降(SGD, Stochastic Gradient Descent)
特点:每次迭代仅随机选取 1 个样本计算梯度:
其中 为随机选取的样本索引。
特征:
- 单次计算量极小
- 更新频繁
- 梯度具有随机噪声
- 收敛路径震荡
- 适合大规模数据
小批量梯度下降(Mini-batch Gradient Descent)
特点: 每次迭代随机选取 个样本():
其中:
- :batch_size
- :当前小批量起始索引
特殊情况:
- 若 → 等价于 SGD
- 若 → 等价于 FGD
特征:
- 计算效率与稳定性之间的折中
- 现代深度学习的主流方法
- 易于利用 GPU 并行
随机平均梯度下降(SAG, Stochastic Average Gradient)
核心思想:
- 每次随机选取 1 个样本计算梯度
- 保存所有样本的“最近一次梯度”
- 使用所有历史梯度的平均值更新参数
其中:
- 每个 存储的是“该样本最近一次计算的梯度”
SAG 具体步骤
- 随机选择一个样本(如 D),计算梯度并存储
- 使用当前已存储梯度的平均值更新参数
- 再随机选择一个样本(如 G),更新其梯度
- 若再次选中 D,则重新计算 D 的梯度并替换旧值
- 始终使用“全部样本最近一次梯度的平均值”更新参数
- 迭代直到收敛
| 算法名称 | 主要特点 | 优缺点/备注 |
|---|---|---|
| 全梯度下降算法 FGD | 由于使用全部数据集,训练速度较慢 | 处理大规模数据时计算成本高。 |
| 随机梯度下降算法 SGD | 简单,高效,不稳定 | 每次只使用一个样本迭代;若遇上噪声则容易陷入局部最优解。 |
| 小批量梯度下降算法 mini-batch | 结合了 SG 的“胆大”和 FG 的“心细”,表现介于两者之间 | 目前使用最多;避开了 FG 效率低和 SG 收敛不稳定的缺点。 |
| 随机平均梯度下降算法 SAG | 训练初期表现不佳,优化速度较慢 | 因为初始梯度常设为 0,而每轮更新都会结合上一轮梯度值。 |
| 梯度下降 | 正规方程 |
|---|---|
| 需要选择学习率,且要注意学习率的值不能过大也不能过小 | 不需要学习率 |
| 需要迭代求解 | 一次运算得出 |
| 特征数量大可以使用 | 可用于小数据量场景、精准的数据场景 |
| 应用场景:更加普适,迭代的计算方式,适合于嘈杂、大数据应用场景 | 缺点:计算量大、容易受到噪声、特征强相关性的影响 |
| 注意:梯度下降在各种损失函数(目标函数)求解中大量使用。深度学习中更是如此,深度学习模型参数很轻松就上亿,只能通过迭代的方式求最优解。 | 注意: 的逆矩阵不存在时,无法求解 注意:计算 的逆矩阵非常耗时如果数据规律不是线性的,无法使用或效果不好 |
梯度下降分类详解
设样本回归方程为 ,其中 为标签, 为权重, 为特征。
设样本数据只有三个点:,,,真实关系是 。
首先使用全梯度下降计算,取 ,学习率 ,全梯度均方误差公式 ,其中 。
,。
第一次更新,平均梯度 ,于是更新 。
第二次更新,此时 ,预测 分别为 、、,求和为 ,平均梯度 ,于是更新 。
第三次更新,此时 ,预测 分别为 、、,求和为 ,平均梯度 ,于是更新 。
可以看到:
- 全梯度下降更新更平滑
- 没有随机抖动
- 收敛过程稳定单调
接下来使用随机梯度下降,均方误差:,为方便求导,系数使用 。
对 求偏导:。
取 ,学习率 。
第一次更新,使用样本 :预测 ,计算梯度 ,更新参数 。
第二次更新,使用样本 : 预测 ,计算梯度 ,更新参数 。
第三次更新,使用样本 : 预测 ,计算梯度 ,更新参数 。
可以看到:
- 每处理一个样本,参数就更新一次
- 参数在不断逼近真实值 2
- 更新过程是“抖动前进”的,不够平滑
但是随机梯度下降的弊端也很明显:
- 每次只用一个样本,非常容易受到噪声(异常值)的影响;
- 收敛路径抖动严重;
- 需要较小学习率。
使用随机平均梯度下降能够保留随机梯度下降的低单次计算成本,同时接近全梯度下降的稳定性。
我们仍使用 ,其中 取 、、, 取 、、。
取 ,学习率 ,此时梯度缓存为 。
第一次更新:首先选择样本 1,梯度 ,由于这是第一个样本计算出的梯度,因此缓存变为 ,此时平均梯度为 ,更新 。
第二次更新:假设这次选择样本 2,梯度 ,由于这是第二个样本,所以缓存变为 ,平均梯度为 ,于是更新 。
第三次更新:假设这次选择样本 1,此时需要重新计算样本 1 的梯度:,此时需要更新旧缓存的梯度,将 更改成 ,然后重新计算平均梯度 ,更新参数 。
代码实现:
demo.py
import numpy as np
# =========================
# 数据定义
# =========================
x = np.array([1.0, 2.0, 3.0])
y = np.array([2.0, 4.0, 6.0])
eta = 0.1 # 学习率
sample_order = [0, 1, 0] # 依次选择 样本1、样本2、样本1
# =========================
# 一、随机梯度下降(SGD)
# =========================
print("===== SGD 演示 =====")
w_sgd = 0.0
for step, idx in enumerate(sample_order, start=1):
xi = x[idx]
yi = y[idx]
# 计算梯度
gradient = (w_sgd * xi - yi) * xi
# 更新参数
w_sgd = w_sgd - eta * gradient
print(f"\n第{step}步:")
print(f"选中样本: x={xi}, y={yi}")
print(f"梯度: {gradient:.4f}")
print(f"更新后 w: {w_sgd:.4f}")
print("\nSGD 最终 w =", round(w_sgd, 4))
# =========================
# 二、随机平均梯度下降(SAG)
# =========================
print("\n\n===== SAG 演示 =====")
w_sag = 0.0
gradient_cache = np.zeros(len(x)) # 梯度缓存
for step, idx in enumerate(sample_order, start=1):
xi = x[idx]
yi = y[idx]
# 重新计算该样本梯度
new_gradient = (w_sag * xi - yi) * xi
# 替换缓存中的旧梯度
gradient_cache[idx] = new_gradient
# 计算平均梯度
avg_gradient = np.mean(gradient_cache)
# 更新参数
w_sag = w_sag - eta * avg_gradient
print(f"\n第{step}步:")
print(f"选中样本: x={xi}, y={yi}")
print(f"新的梯度: {new_gradient:.4f}")
print(f"当前缓存: {[round(g,4) for g in gradient_cache]}")
print(f"平均梯度: {avg_gradient:.4f}")
print(f"更新后 w: {w_sag:.4f}")
print("\nSAG 最终 w =", round(w_sag, 4))运行结果.txt
===== SGD 演示 =====
第1步:
选中样本: x=1.0, y=2.0
梯度: -2.0000
更新后 w: 0.2000
第2步:
选中样本: x=2.0, y=4.0
梯度: -7.2000
更新后 w: 0.9200
第3步:
选中样本: x=1.0, y=2.0
梯度: -1.0800
更新后 w: 1.0280
SGD 最终 w = 1.028
===== SAG 演示 =====
第1步:
选中样本: x=1.0, y=2.0
新的梯度: -2.0000
当前缓存: [np.float64(-2.0), np.float64(0.0), np.float64(0.0)]
平均梯度: -0.6667
更新后 w: 0.0667
第2步:
选中样本: x=2.0, y=4.0
新的梯度: -7.7333
当前缓存: [np.float64(-2.0), np.float64(-7.7333), np.float64(0.0)]
平均梯度: -3.2444
更新后 w: 0.3911
第3步:
选中样本: x=1.0, y=2.0
新的梯度: -1.6089
当前缓存: [np.float64(-1.6089), np.float64(-7.7333), np.float64(0.0)]
平均梯度: -3.1141
更新后 w: 0.7025
SAG 最终 w = 0.7025回归评估方法
我们需要衡量预测值和真实值的差距,需要使用测评函数进行评价。
平均绝对误差(Mean Absolute Error,MAE)
为样本数量, 为实际值, 为预测值。MAE 越小模型预测越准确。
# sklearn 中 MAE 的 API
from sklearn.metrics import mean_absolute_error
mean_absolute_error(y_test, y_predict)均方误差(Mean Squared Error,MSE)
为样本数量, 为实际值, 为预测值。MSE 越小模型预测越准确。
# Sklearn 中 MSE 的 API
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test, y_predict)均方根误差(Root Mean Squared Error,RMSE)
为样本数量, 为实际值, 为预测值。RMSE 越小模型预测越准确。
from sklearn.metrics import root_mean_squared_error
root_mean_squared_error(y_test, y_predict)三种指标的比较
我们绘制了一条直线 用来拟合 这些数据点,其中 为噪声。
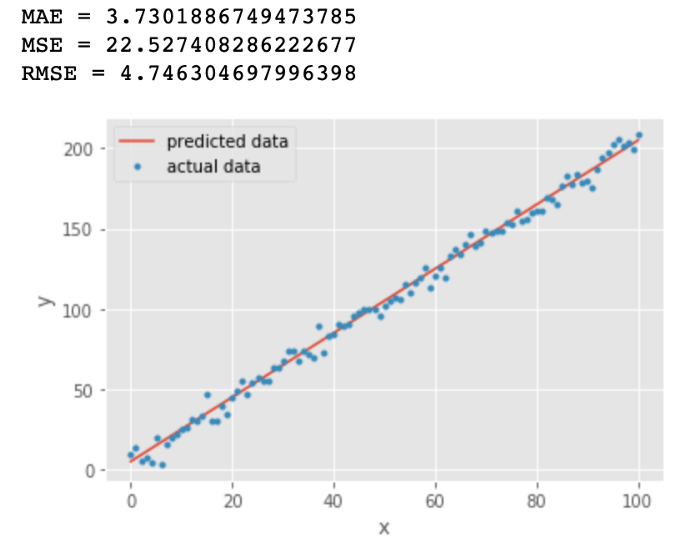
从上图中我们发现 MAE 和 RMSE 非常接近,都表明模型的误差很低。我们对比 MAE 和 RMSE 的公式,RSME 的计算公式中有一个平方,因此大的误差将被平方,导致增加 RMSE 的值。
结论:RMSE 会放大预测误差较大的样本对结果的影响,而 MAE 只是给出了平均误差。
打个比方,如果一组有 3 个样本的特征,误差分别是 1、2、3,那么使用平均绝对误差计算的结果是 ,使用均方根误差计算的结果是 ,所以说 RSME 对误差敏感。
波士顿房价预测案例
线性回归 API
class sklearn.linear_model.LinearRegression(
*,
fit_intercept=True,
copy_X=True,
tol=1e-6,
n_jobs=None,
positive=False
)参数:
fit_intercept: 是否计算截距,默认 True。copy_X: 是否复制输入数据。tol: 求解精度(用于最小二乘)。n_jobs: 并行计算的线程数。positive: 是否强制回归系数为正。
属性:
coef_: 回归系数。intercept: 截距。n_features_in_: 输入特征数量。rank_: 矩阵秩。singular_: 奇异值。
sklearn.linear_model.SGDRegressor(loss="squared_loss", fit_intercept=True, learning_rate ='constant', eta0=0.01)- 参数:
loss(损失函数类型),fit_intercept(是否计算偏置)learning_rate(学习率) - 属性:
SGDRegressor.coef_(回归系数)SGDRegressor.intercept(偏置)
波士顿房价字段释义

波士顿房价案例代码——正规方程法
demo.py
# 导包
# from sklearn.datasets import load_boston # 数据
from sklearn.preprocessing import StandardScaler # 特征处理
from sklearn.model_selection import train_test_split # 数据集划分
from sklearn.linear_model import LinearRegression # 正规方程的回归模型
from sklearn.metrics import mean_squared_error, root_mean_squared_error, mean_absolute_error # 均方误差评估, RMSE, MAE
import pandas as pd
import numpy as np
# 1. 加载 波士顿房价数据.
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]]) # hstack()函数作用: 水平拼接数组
target = raw_df.values[1::2, 2]
# print(f'特征: {data.shape}') # (506, 13)
# print(f'标签: {target.shape}') # (506,)
#
# print(f'特征数据: {data[:5]}')
# print(f'标签数据: {target[:5]}')
# 2. 数据的预处理. 切分训练集 和 测试集.
# 参1: 特征数据. 参2: 标签数据. 参3: 测试集占训练集的比例. 参4: 随机种子.
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=23)
# 3. 特征工程(特征提取, 特征预处理...)
# 3.1 创建标准化对象.
transfer = StandardScaler()
# 3.2 对训练集进行标准化.
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4. 模型训练.
# 4.1 创建 线性回归 正规方程 模型对象.
estimator = LinearRegression(fit_intercept=True) # fit_intercept: 是否需要截距(Bias, 偏置), 默认是True
# 4.2 模型训练.
estimator.fit(x_train, y_train)
# 4.3 打印模型计算出的 w(权重, weight) 和 b(偏置, bias).
print(f"权重: {estimator.coef_}")
print(f"偏置: {estimator.intercept_}")
# 5. 模型预测.
y_pre = estimator.predict(x_test)
print(f"预测结果为: {y_pre}")
# 6. 模型评估
# 参1: 测试集的标签数据. 参2: 预测结果.
print(f"均方误差为: {mean_squared_error(y_test, y_pre)}") # MSE: 均方误差, 公式: 每个样本的误差平方和 / 样本总数
print(f"均方根误差为: {root_mean_squared_error(y_test, y_pre)}") # RMSE: 均方根误差, 公式: 每个样本的误差平方和 / 样本总数, 开平方根
print(f"平均绝对误差为: {mean_absolute_error(y_test, y_pre)}") # MAE: 平均绝对误差, 公式: 每个样本的误差 绝对值和 / 样本总数运行结果.txt
权重: [-0.83324131 1.06806852 0.10120867 0.8526869 -2.24617776 2.50534445
0.14075282 -3.10875131 2.38399309 -1.65525639 -1.91042436 0.88987647
-3.9779892 ]
偏置: 22.563613861386163
预测结果为: [25.61587252 27.12586692 27.2088525 16.76603362 38.00811547 17.05443719
20.26113342 28.70919709 33.96194692 37.65615799 16.21901641 27.51736638
25.7187111 26.43299408 21.31864713 20.01859619 30.87402793 30.98608893
29.23266456 28.95514577 18.96926991 17.33534451 24.74641894 24.21793059
13.8394873 22.78879429 32.94398003 28.62425477 29.11102704 38.11386992
18.22086333 15.67529394 20.0137507 20.30595835 20.53027273 37.07808
25.45522971 31.21980602 13.76404735 36.06105193 8.85561067 13.50823899
11.35806828 19.64395577 35.88548656 20.30249401 13.0696301 22.12998418
12.74438772 38.93664974 22.73399592 3.30910813 17.58596169 18.29423866
24.13601366 32.74378072 5.53761184 21.52990404 17.81376459 22.31765421
17.9309305 21.51118474 20.93420687 42.69323506 30.72062844 29.52582704
20.45099249 16.5047906 30.89037231 14.12930467 20.27573153 11.00666366
21.93241329 18.63703789 15.85233969 14.08091012 14.93188705 23.48466571
13.10674564 32.02338044 23.10506853 25.5961718 25.09756853 12.32727247
22.46185725 21.24709959 36.22525835 40.25079579 29.30312518 16.38918008
16.38615981 20.72277336 20.71664588 19.30088389 24.20833923 13.66921042
42.91672981 17.23760986 27.68885365 25.08605564 17.71101551 23.19018216]
均方误差为: 21.953471731537103
均方根误差为: 4.685453204497629
平均绝对误差为: 3.6689886710784814波士顿房价案例代码——梯度下降法
demo.py
# 导包
from sklearn.preprocessing import StandardScaler # 特征处理
from sklearn.model_selection import train_test_split # 数据集划分
from sklearn.linear_model import SGDRegressor # 梯度下降的回归模型
from sklearn.metrics import mean_squared_error, root_mean_squared_error, mean_absolute_error # 均方误差评估, RMSE, MAE
import pandas as pd
import numpy as np
# 1. 加载 波士顿房价数据.
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]]) # hstack()函数作用: 水平拼接数组
target = raw_df.values[1::2, 2]
# print(f'特征: {data.shape}') # (506, 13)
# print(f'标签: {target.shape}') # (506,)
#
# print(f'特征数据: {data[:5]}')
# print(f'标签数据: {target[:5]}')
# 2. 数据的预处理. 按照8:2 切分 训练集和测试集.
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=23)
# 3. 特征工程(特征提取, 特征预处理...)
# 3.1 创建 标准化对象.
transfer = StandardScaler()
# 3.2 对训练集和测试集进行标准化处理.
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4. 模型训练.
# estimator = LinearRegression(fit_intercept=True) # 正规方程法 线性回归对象.
# 4.1 创建 梯度下降 线性回归 模型对象.
# 参1: fit_intercept: 是否计算截距.
# 参2: learning_rate: 学习率模式 -> 常量, 即: 不会发生改变.
# 参3: eta0: 学习率.
estimator = SGDRegressor(fit_intercept=True, learning_rate='constant', eta0=0.01)
# 4.2 模型训练.
estimator.fit(x_train, y_train)
# 4.3 打印 权重 和 偏置.
print(f'权重: {estimator.coef_}')
print(f'偏置: {estimator.intercept_}')
# 5. 模型预测.
y_pre = estimator.predict(x_test)
# 6. 模型评估
# MSE: 均方误差, 每个误差的平方和 / 样本总数
print(f'均方误差: {mean_squared_error(y_test, y_pre)}') # 参1: 测试集的真实标签, 参2: 测试集的预测标签
# RMSE: 均方根误差, 均方误差的平方根
print(f'均方根误差: {root_mean_squared_error(y_test, y_pre)}') # 参1: 测试集的真实标签, 参2: 测试集的预测标签
# MAE: 平均绝对误差, 每个误差绝对值和 / 样本总数
print(f'平均绝对误差: {mean_absolute_error(y_test, y_pre)}') # 参1: 测试集的真实标签, 参2: 测试集的预测标签运行结果.txt
权重: [-1.40913388 1.19490108 0.05721086 0.76542423 -2.43335625 2.61393644
-0.09813844 -3.07669079 2.36051852 -1.68818177 -1.76633133 1.16715187
-4.13930702]
偏置: [22.46576583]
均方误差: 23.642307816128877
均方根误差: 4.8623356338419175
平均绝对误差: 3.7882730727789893正则化
欠拟合
欠拟合:一个假设在训练数据上不能获得更好的拟合,并且在测试数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。(模型过于简单)
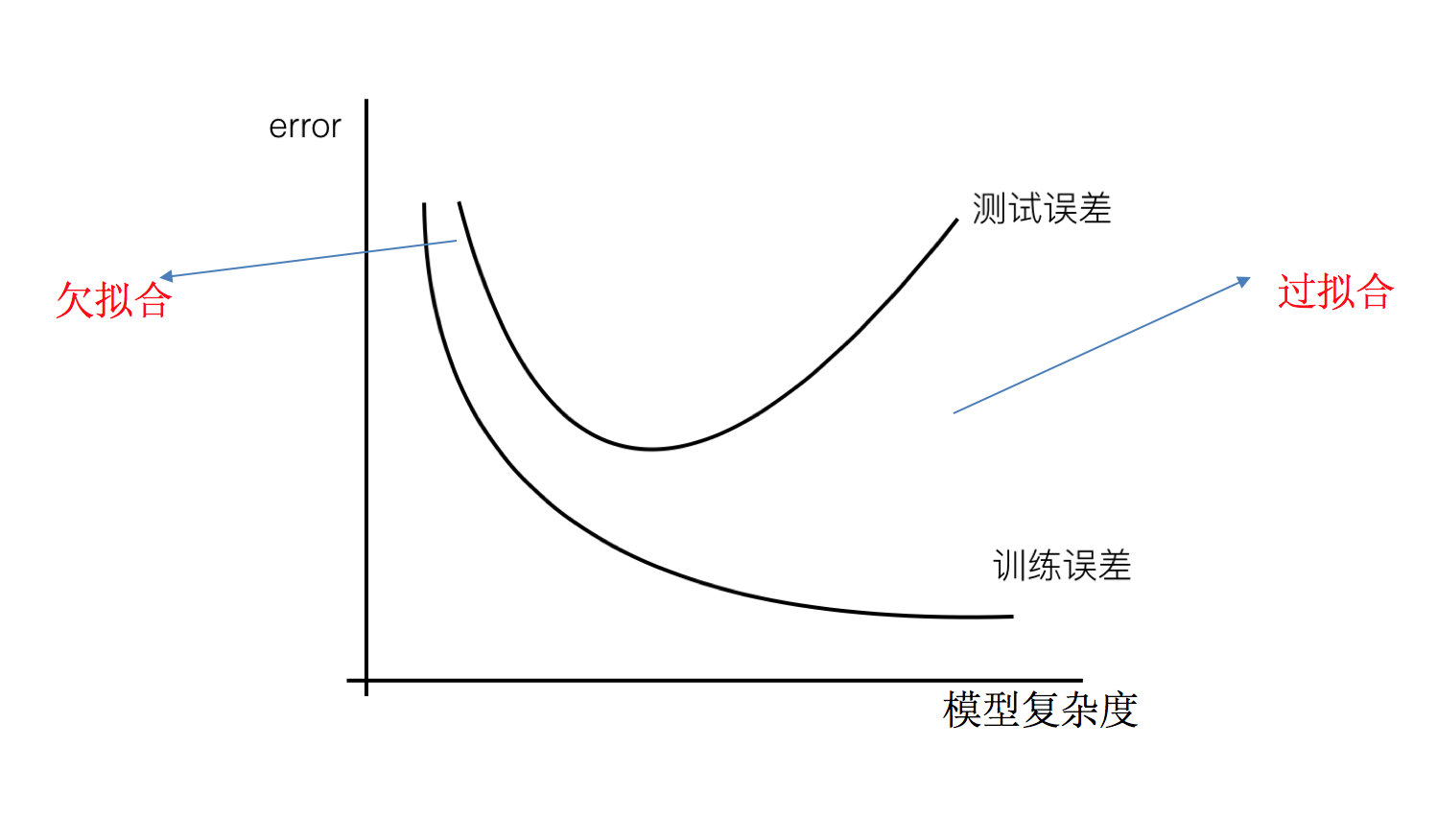
这个图表示的是模型复杂度和识别误差的二维坐标系,在数据集规模一致的情况下,模型越复杂,对训练集的理解就越好,所以训练误差会越来越低。在最开始,模型复杂度不足以支持数据集的庞大规模时,会表现成在训练集和测试集上都不好。随着模型复杂度的提升,模型能够越来越理解训练集,但是模型会刻意地“记住”训练集,导致它在测试集上识别效果不好。
欠拟合出现的原因是模型学习到的特征太少,解决方法有:
- 添加其他特征:有时出现欠拟合是因为特征项不够导致的,可以添加其他特征项来解决;“组合”、“泛化”、“相关性”三类特征是特征添加的重要手段
Python代码举例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error # 计算均方误差
# 1. 准备x, y数据, 增加上噪声.
# 用于设置随机数生成器的种子(seed), 种子一样, 每次生成相同序列.
np.random.seed(666)
# x: 随机数, 范围为 (-3, 3), 100个.
x = np.random.uniform(-3, 3, size=100)
# loc: 均值, scale: 标准差, normal: 正态分布.
y = 0.5 * x**2 + x + 2 + np.random.normal(0, 1, size=100)
# 2. 实例化 线性回归模型.
estimator = LinearRegression()
# 3. 训练模型
X = x.reshape(-1, 1)
estimator.fit(X, y)
# 4. 模型预测.
y_predict = estimator.predict(X)
print("预测值:", y_predict)
# 5. 计算均方误差 => 模型评估
print(f"均方误差: {mean_squared_error(y, y_predict)}")
# 6. 画图
plt.scatter(x, y) # 散点图
plt.plot(x, y_predict, color="r") # 折线图(预测值, 拟合回归线)
plt.show() # 具体的绘图
print(mean_squared_error(y, y_predict)) # 3.0750025765636577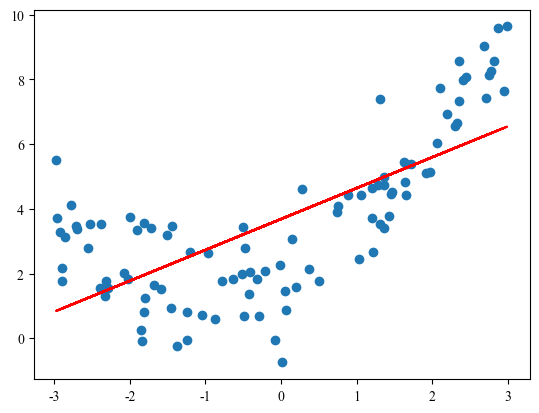
过拟合
一个假设在训练数据上能够获得比其他假设更好的拟合,但是在测试数据集上却不能很好地拟合数据(体现在准确率下降),此时认为这个假设出现了过拟合的现象。(模型过于复杂)
过拟合出现的原因是样本的特征太多,存在一些嘈杂特征,模型视图兼顾各个测试数据点。
解决方法有:重新清洗数据、增大数据的训练量、正则化、减少特征维度,防止维灾难。其中正则化在机器学习、深度学习中大量使用。
Python代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error # 计算均方误差
# 1. 准备x, y数据, 增加上噪声.
# 用于设置随机数生成器的种子(seed), 种子一样, 每次生成相同序列.
np.random.seed(666)
# x: 随机数, 范围为 (-3, 3), 100个.
x = np.random.uniform(-3, 3, size=100)
# loc: 均值, scale: 标准差, normal: 正态分布.
y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 2. 实例化 线性回归模型.
estimator = LinearRegression()
# 3. 训练模型
X = x.reshape(-1, 1)
# hstack() 函数用于将多个数组在行上堆叠起来, 即: 数据增加高次项.
X3 = np.hstack([X, X**2, X**3, X**4, X**5, X**6, X**7, X**8, X**9, X**10])
estimator.fit(X3, y)
# 4. 模型预测.
y_predict = estimator.predict(X3)
print("预测值:", y_predict)
# 5. 计算均方误差 => 模型评估
print(f'均方误差: {mean_squared_error(y, y_predict)}')
# 6. 画图
plt.scatter(x, y) # 散点图
# sort() 该函数直接返回一个排序后的新数组。
# numpy.argsort() 该函数返回的是数组值从小到大排序时对应的索引值
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r') # 折线图(预测值, 拟合回归线)
plt.show() # 具体的绘图
# 均方误差为1.0508466763764155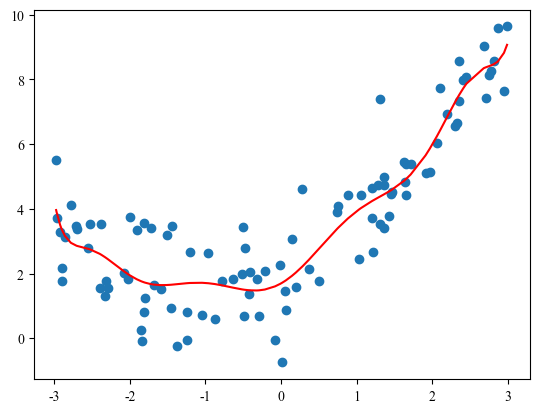
如果是正好拟合,样本中特征应只有一次项和二次项,图形将是一个光滑的二次曲线。
如何正则化
正则化:模型训练时,数据有些特征会影响模型复杂度,或者某个特征的异常值较多,所以要减少这个特征对模型的影响。
在线性回归中,如果某个高次项的权重 过大,就会出现过拟合。通过正则化,可以减少权重。

L1 正则化
假设 是未加正则项的损失, 是一个超参数,控制正则化项的大小,则优化后的损失函数为:
L1 正则化用来进行特征选择,主要原因在于 L1 正则化会使得较多的参数为 0,从而产生稀疏解,可以将 0 对应的特征遗弃,进而用来选择特征。一定程度上 L1 正则也可以防止模型过拟合。
稀疏解:在参数向量中,大量元素为 0(或接近 0)的解。
设模型参数为 ,若其中大多数 ,则称该解是稀疏的。
也叫惩罚系数。 越大,对某个参数的惩罚就越大。
考虑一个优化问题,它的损失函数为:
意思是找一个 ,让这个表达式的值最小,这样模型拟合效果最好。
前面的式子 希望 接近 ,如果 ,则这一项等于零,也就是离得越远,惩罚越大,这叫做二次损失(平方误差)。
第二部分 ,意思是惩罚 的大小, 越大,惩罚越大, 控制惩罚强度,这是 L1 正则项。
在 sklearn 中,对应的 API 是 from sklearn.linear_model import Lasso,将 LinearRegression 替换成 Lasso 就可以了。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Lasso
from sklearn.metrics import mean_squared_error # 计算均方误差
# 1. 准备x, y数据, 增加上噪声.
# 用于设置随机数生成器的种子(seed), 种子一样, 每次生成相同序列.
np.random.seed(666)
# x: 随机数, 范围为 (-3, 3), 100个.
x = np.random.uniform(-3, 3, size=100)
# loc: 均值, scale: 标准差, normal: 正态分布.
y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 2. 实例化 线性回归模型.
estimator = Lasso(alpha=0.1)
# 3. 训练模型
X = x.reshape(-1, 1)
# hstack() 函数用于将多个数组在行上堆叠起来, 即: 数据增加高次项.
X3 = np.hstack([X, X**2, X**3, X**4, X**5, X**6, X**7, X**8, X**9, X**10])
estimator.fit(X3, y)
# 4. 模型预测.
y_predict = estimator.predict(X3)
print("预测值:", y_predict)
# 5. 计算均方误差 => 模型评估
print(f'均方误差: {mean_squared_error(y, y_predict)}')
# 6. 画图
plt.scatter(x, y) # 散点图
# sort() 该函数直接返回一个排序后的新数组。
# numpy.argsort() 该函数返回的是数组值从小到大排序时对应的索引值
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r') # 折线图(预测值, 拟合回归线)
plt.show() # 具体的绘图
print(mean_squared_error(y, y_predict))
# 优化前的均方误差是 1.0508466763764155,优化后的是 1.1333300553891887,一定程度上解决了过拟合的问题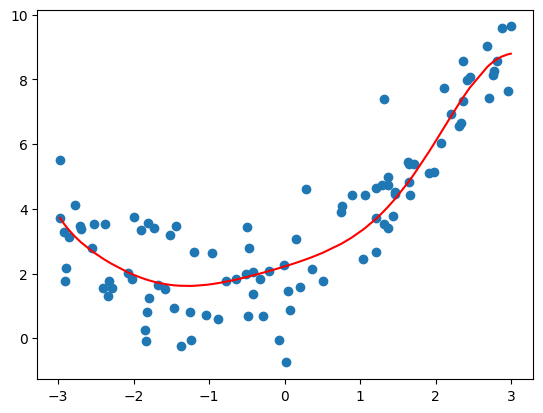
L2 正则化
损失函数:
L2 正则化不会让参数的权重等于 0,只会让权重无限趋近于 0。
API:from sklearn.linear_model import Ridge。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error # 计算均方误差
# 1. 准备x, y数据, 增加上噪声.
# 用于设置随机数生成器的种子(seed), 种子一样, 每次生成相同序列.
np.random.seed(666)
# x: 随机数, 范围为 (-3, 3), 100个.
x = np.random.uniform(-3, 3, size=100)
# loc: 均值, scale: 标准差, normal: 正态分布.
y = 0.5 * x ** 2 + x + 2 + np.random.normal(0, 1, size=100)
# 2. 实例化 线性回归模型.
estimator = Ridge(alpha=0.1)
# 3. 训练模型
X = x.reshape(-1, 1)
# hstack() 函数用于将多个数组在行上堆叠起来, 即: 数据增加高次项.
X3 = np.hstack([X, X**2, X**3, X**4, X**5, X**6, X**7, X**8, X**9, X**10])
estimator.fit(X3, y)
# 4. 模型预测.
y_predict = estimator.predict(X3)
print("预测值:", y_predict)
# 5. 计算均方误差 => 模型评估
print(f'均方误差: {mean_squared_error(y, y_predict)}')
# 6. 画图
plt.scatter(x, y) # 散点图
# sort() 该函数直接返回一个排序后的新数组。
# numpy.argsort() 该函数返回的是数组值从小到大排序时对应的索引值
plt.plot(np.sort(x), y_predict[np.argsort(x)], color='r') # 折线图(预测值, 拟合回归线)
plt.show() # 具体的绘图
print(mean_squared_error(y, y_predict))
# 优化前的均方误差是 1.0508466763764155,优化后的是 1.0515567511025437为什么 L1 正则化可以产生稀疏解,L2 正则化不行
关键在于 绝对值函数在 0 点的导数性质,以及优化算法如何利用梯度更新参数。
先看绝对值函数:
1 绝对值函数在 0 的导数
绝对值函数可以写成分段形式:
求导:
可以看到:
- 从右边接近 0,导数 = 1
- 从左边接近 0,导数 = -1
左右导数不相等,因此:
不可导。
2 不可导在优化中的意义
在优化问题中我们最小化:
关注正则项:
其梯度:
一个重要特征:
梯度大小是常数 。
3 对参数更新的影响
假设梯度下降更新:
只看 L1 项:
当
梯度:
更新:
权重 持续减小。
当
梯度:
更新:
权重 持续增大。
因此无论:
- 正权重
- 负权重
都会被 向 0 推动。
4 为什么容易变成 0
因为:
L1 的梯度是常数。
当参数已经很小:
更新:
可能 直接跨过 0。
在很多优化算法(例如坐标下降)中,会直接:
这就是 稀疏解产生的原因。
5 和 L2 的本质区别
L2 正则:
梯度:
特点:
- 当
- 梯度
因此:
权重只会 越来越小,但很难 刚好等于 0。
6 一个直观对比
| 正则 | 梯度 | 靠近0时行为 |
|---|---|---|
| L1 | 常数 | 会直接推到0 |
| L2 | 越来越小 |
所以:
- L1 → 稀疏解
- L2 → 权重收缩
逻辑回归
逻辑回归(Logistic Regression)是机器学习中最基础且高效的二分类算法之一,常用于预测特定事件发生的概率(如垃圾邮件识别、疾病诊断、点击率预估)。它将线性回归的预测值通过 Sigmoid函数 映射到 0 到 1 之间,输出的是概率值,常用于离散类标签的预测。
激活函数
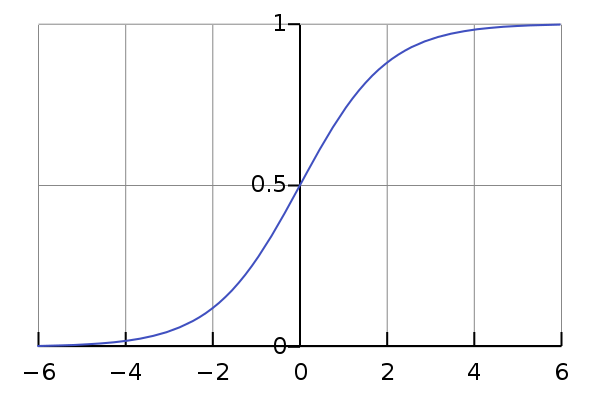
又称 Sigmoid 函数、S 型函数,公式:
它用于将范围为 值映射到 。
它是单调递增函数,拐点在 的位置,导函数为 。
数学基础
概率:事件发生的可能性。
联合概率:两个或多个随机变量同时发生的概率。
条件概率:表示事件 A 在另外一个事件 B 已经发生的条件下发生的概率,记为 。
极大似然估计:利用观测到的结果估计模型算法中的未知参数,思想是选择一个 ,使得“当前已经发生的数据”出现的概率最大。。
假设有一枚不均匀的硬币,出现正面的概率和反面的概率是不同的。假定出现正面的概率为 ,抛了6次得到如下现象 。每次投掷事件都是相互独立的。则根据产生的现象D,来估计参数 是多少?
于是问题转化为,求一个 ,让这个概率最大。
于是求导:
令 ,解得 ,于是取 。
对数:若 ,则 。若底数为 ,记作 ,若底数为 10,记作 。
对数的性质:
- ;
- ;
- 。
对数能够将概率相乘的式子改成 log 相加的形式。
逻辑回归原理
逻辑回归:英文 Logistic Regression,是一种分类模型,把线性回归的输出作为逻辑回归的输入。
基本思想:利用线性模型 ,根据特征的重要性计算出一个值,然后使用 sigmoid 函数将 的输出映射为 间的值,最后通过阈值判断它属于哪个类别。
线性回归的输入作为逻辑回归的输出。
逻辑回归的损失函数
其中 ,是逻辑回归的输出结果; 是样本所属类别,若该样本属于正样本,那么此值为 1,反之此值为 0。
假设第 个样本,通过 sigmoid 函数预测到它属于正样本的概率是 。若它属于正样本,那么 就为 1,那么该项的损失函数值就为 。,所以 ,和其他损失函数基本一致。
混淆矩阵
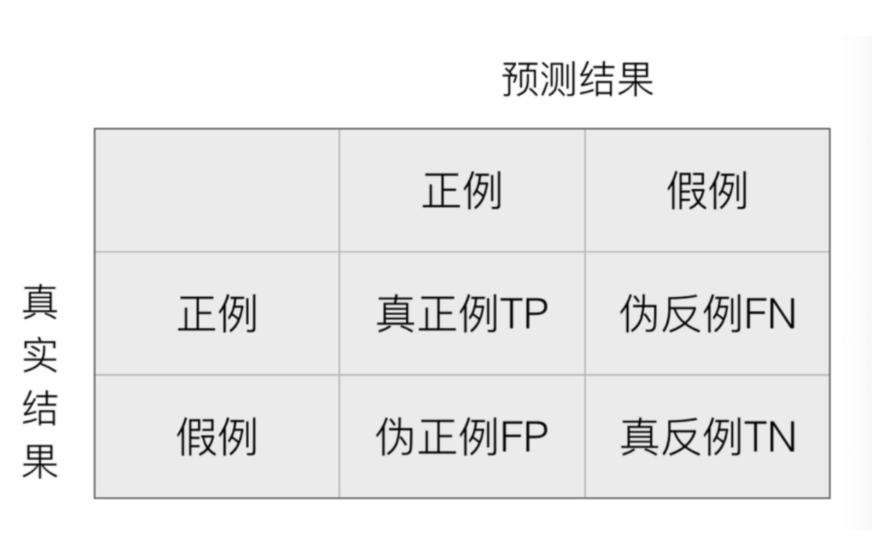
混淆矩阵作用在测试集样本集中:
- 真实值是正例的样本中,被分类为正例的样本数量有多少,这部分样本叫做真正例(TP,True Positive)
- 真实值是正例的样本中,被分类为假例的样本数量有多少,这部分样本叫做伪反例(FN,False Negative)
- 真实值是假例的样本中,被分类为正例的样本数量有多少,这部分样本叫做伪正例(FP,False Positive)
- 真实值是假例的样本中,被分类为假例的样本数量有多少,这部分样本叫做真反例(TN,True Negative)
例子:
样本集中有 6 个恶性肿瘤样本,4 个良性肿瘤样本,我们假设恶性肿瘤为正例,则:
模型 A: 预测对了 3 个恶性肿瘤样本,4 个良性肿瘤样本
- 真正例 TP:3
- 伪反例 FN:3
- 伪正例 FP:0
- 真反例 TN:4
模型 B: 预测对了 6 个恶性肿瘤样本,1个良性肿瘤样本
- 真正例 TP:6
- 伪反例 FN:0
- 伪正例 FP:3
- 真反例 TN:1
模型评估指标
准确率:指的是模型预测正确的样本占所有样本的比重,正样本和负样本都包含。
精确率:也叫查准率,指的是模型对正例样本的预测准确率。
召回率:也叫查全率,指的是模型预测为真正例的样本占所有真正例样本的比重。
F1-Score:对模型的精度和召回率都有要求时,可用此指标。
样本集中有 6 个恶性肿瘤样本,4 个良性肿瘤样本,我们假设恶性肿瘤为正例,则:
模型 A:预测对了 3 个恶性肿瘤样本,4 个良性肿瘤样本
- 真正例 TP:3
- 伪反例 FN:3
- 假正例 FP:0
- 真反例 TN:4
- 精准率:
- 召回率:
- F1-score:
模型 B:预测对了 6 个恶性肿瘤样本,1个良性肿瘤样本
- 真正例 TP:6
- 伪反例 FN:0
- 假正例 FP:3
- 真反例 TN:1
- 精准率:
- 召回率:
- F1-score:
逻辑回归 API
sklearn.linear_model.LogisticRegression(
penalty="deprecated",
*,
C=1.0,
l1_ratio=0.0,
dual=False,
tol=1e-4,
fit_intercept=True,
intercept_scaling=1,
class_weight=None,
random_state=None,
solver="lbfgs",
max_iter=100,
verbose=0,
warm_start=False,
n_jobs=None,
)penalty="deprecated": 正则化类型,取值可以是"l2"、"l1"、"elasticnet"、None。C=1.0: 正则强度的倒数。l1_ratio: 仅在penalty="elasticnet"且solver="saga"时有效,此时表示 L1 的比例 ,取值范围 。solver: 优化算法。
| solver | 支持正则 | 适用场景 |
|---|---|---|
"lbfgs" | L2 | 默认,适合中小数据 |
"liblinear" | L1, L2 | 小数据,支持 dual |
"sag" | L2 | 大规模数据 |
"saga" | L1, L2, elasticnet | 大规模 + 稀疏数据 |
"newton-cg" | L2 | 中等规模 |
fit_intercept: 是否拟合截距项 。random_state: 随机种子。
示例:癌症预测
查看数据集部分数据,以及数据缺失情况。
import pandas as pd
data = pd.read_csv("./data/breast-cancer-wisconsin.csv")
print("查看数据信息: ")
data.info()
print(f"\n查看数据前五行:\n{data.head()}")查看数据信息:
<class 'pandas.DataFrame'>
RangeIndex: 699 entries, 0 to 698
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Sample code number 699 non-null int64
1 Clump Thickness 699 non-null int64
2 Uniformity of Cell Size 699 non-null int64
3 Uniformity of Cell Shape 699 non-null int64
4 Marginal Adhesion 699 non-null int64
5 Single Epithelial Cell Size 699 non-null int64
6 Bare Nuclei 699 non-null str
7 Bland Chromatin 699 non-null int64
8 Normal Nucleoli 699 non-null int64
9 Mitoses 699 non-null int64
10 Class 699 non-null int64
dtypes: int64(10), str(1)
memory usage: 60.2 KB
查看数据前五行:
Sample code number Clump Thickness Uniformity of Cell Size \
0 1000025 5 1
1 1002945 5 4
2 1015425 3 1
3 1016277 6 8
4 1017023 4 1
Uniformity of Cell Shape Marginal Adhesion Single Epithelial Cell Size \
0 1 1 2
1 4 5 7
2 1 1 2
3 8 1 3
4 1 3 2
Bare Nuclei Bland Chromatin Normal Nucleoli Mitoses Class
0 1 3 1 1 2
1 10 3 2 1 2
2 2 3 1 1 2
3 4 3 7 1 2
4 1 3 1 1 2训练模型和评估。
demo.py
# 导包
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression # 逻辑回归模型
from sklearn.preprocessing import StandardScaler # 标准化
from sklearn.model_selection import train_test_split # 训练集和测试集分割
from sklearn.metrics import accuracy_score # 模型评估
# 1. 加载数据.
data = pd.read_csv("./data/breast-cancer-wisconsin.csv")
data.info() # 查看数据信息
# 2. 数据预处理.
# 2.1 把 ? 替换成 np.nan, 参1: 要被替换的值, 参2: 用来替换的值, 参3: 是否替换源数据, 默认为False
data.replace("?", np.nan, inplace=True)
# 2.2 缺失值处理 -> 删除.
data.dropna(axis=0, inplace=True) # axis=0, 表示行, 删除包含缺失值的行.
# 2.3 打印处理后的信息.
# data.info()
# 3. 特征工程(提取, 预处理...)
# 3.1 特征提取之 提取特征和标签.
x = data.iloc[:, 1:-1] # 按照行号, 列索引获取数据, :表示所有行 1:-1 表示从第1列到最后1列, 包左不包右
# y = data.iloc[:, -1] # 获取最后一列
# y = data['Class'] # 获取最后一列, 效果同上
y = data.Class # 获取最后一列, 效果同上
# 3.2 查看下特征 和 标签.
print(x[:5])
print(y[:5])
print(x.shape, y.shape)
# 3.3 切割训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=23)
# 3.4 特征工程: 标准化
# 3.4.1 创建标准化对象.
transfer = StandardScaler()
# 3.4.2 对训练集进行标准化. 训练 + 标准化
x_train = transfer.fit_transform(x_train)
# 3.4.3 对测试集进行标准化. 标准化
x_test = transfer.transform(x_test)
# 4. 模型训练.
# 4.1 创建模型对象 -> 逻辑回归模型
estimator = LogisticRegression()
# 4.2 模型训练.
estimator.fit(x_train, y_train)
# 5. 模型预测.
y_pre = estimator.predict(x_test)
print(f"预测值为: {y_pre}")
# 6. 模型评估.
# 正确率(准确率), 公式为: 预测对的 / 样本总数
print(f"预测前评估, 正确率: {estimator.score(x_test, y_test)}") # 测试集的特征, 标签.
print(f"预测后评估, 正确率: {accuracy_score(y_test, y_pre)}") # 测试集的标签, 预测值.
# 思考: 逻辑回归模型能用 准确率来评测吗?
# 答案: 可以, 但是结果不精准, 因为逻辑回归模型主要用于 二分类, 即: A类还是B类, 不能说 97%的A类, 3%的B类.
# 所以要通过 混淆矩阵来评测, 即: 精确率, 召回率, F1值(F1-Score), ROC曲线, AUC值.运行结果.txt
<class 'pandas.DataFrame'>
RangeIndex: 699 entries, 0 to 698
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Sample code number 699 non-null int64
1 Clump Thickness 699 non-null int64
2 Uniformity of Cell Size 699 non-null int64
3 Uniformity of Cell Shape 699 non-null int64
4 Marginal Adhesion 699 non-null int64
5 Single Epithelial Cell Size 699 non-null int64
6 Bare Nuclei 699 non-null str
7 Bland Chromatin 699 non-null int64
8 Normal Nucleoli 699 non-null int64
9 Mitoses 699 non-null int64
10 Class 699 non-null int64
dtypes: int64(10), str(1)
memory usage: 60.2 KB
Clump Thickness Uniformity of Cell Size Uniformity of Cell Shape \
0 5 1 1
1 5 4 4
2 3 1 1
3 6 8 8
4 4 1 1
Marginal Adhesion Single Epithelial Cell Size Bare Nuclei \
0 1 2 1
1 5 7 10
2 1 2 2
3 1 3 4
4 3 2 1
Bland Chromatin Normal Nucleoli Mitoses
0 3 1 1
1 3 2 1
2 3 1 1
3 3 7 1
4 3 1 1
0 2
1 2
2 2
3 2
4 2
Name: Class, dtype: int64
(683, 9) (683,)
预测值为: [2 2 2 2 2 4 4 4 4 2 2 2 2 4 2 2 2 2 4 2 4 2 2 2 4 4 4 2 2 2 4 4 2 2 2 4 4
2 2 2 4 2 2 2 4 4 2 2 4 2 4 4 2 4 2 2 4 4 4 2 2 2 4 4 4 2 2 2 2 4 2 2 2 2
2 2 2 4 2 2 2 2 2 4 2 2 2 4 4 2 4 4 4 2 4 4 2 2 4 2 2 2 2 4 4 4 4 2 2 2 4
4 4 4 2 2 4 2 2 4 4 2 2 2 2 2 4 4 2 2 2 2 4 2 2 2 4]
预测前评估, 正确率: 0.9781021897810219
预测后评估, 正确率: 0.9781021897810219