
外观
聚类算法
K-means
一种典型的无监督学习算法,主要用于将相似的样本自动归到一个类别中。
在聚类算法中根据样本之间的相似性,将样本划分到不同的类别中,对于不同的相似度计算方法,会得到不同的聚类结果,常用的相似度计算方法有欧式距离法。
流程
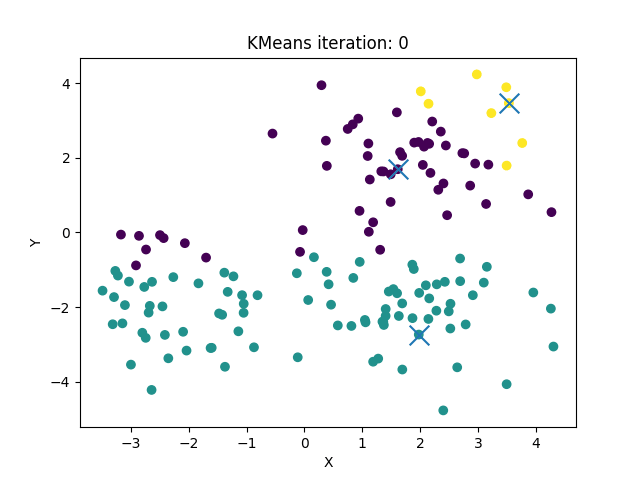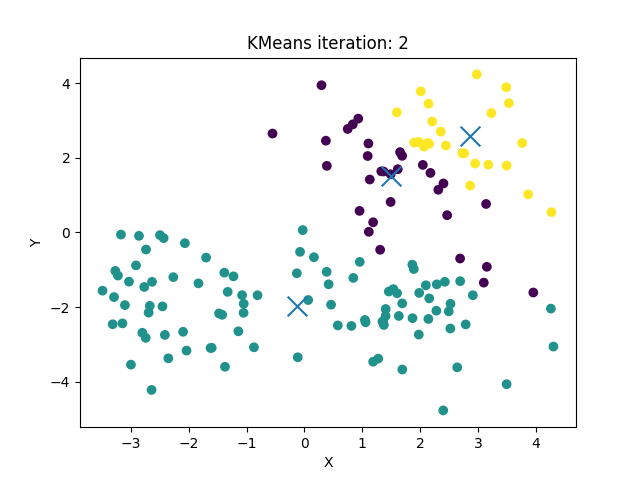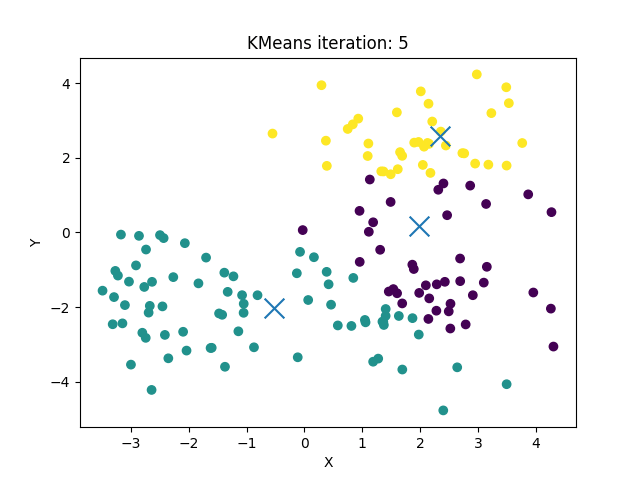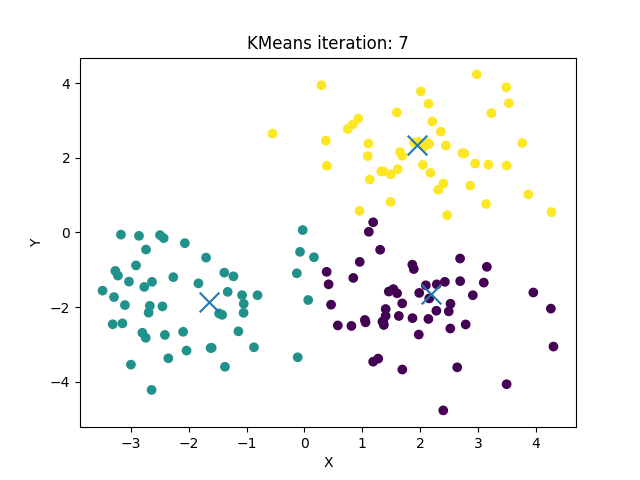
- 随机设置K个特征空间内的点作为初始的聚类中心
- 对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
- 接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
- 如果计算得出的新中心点与原中心点一样(质心不再移动),那么结束,否则重新进行第二步过程
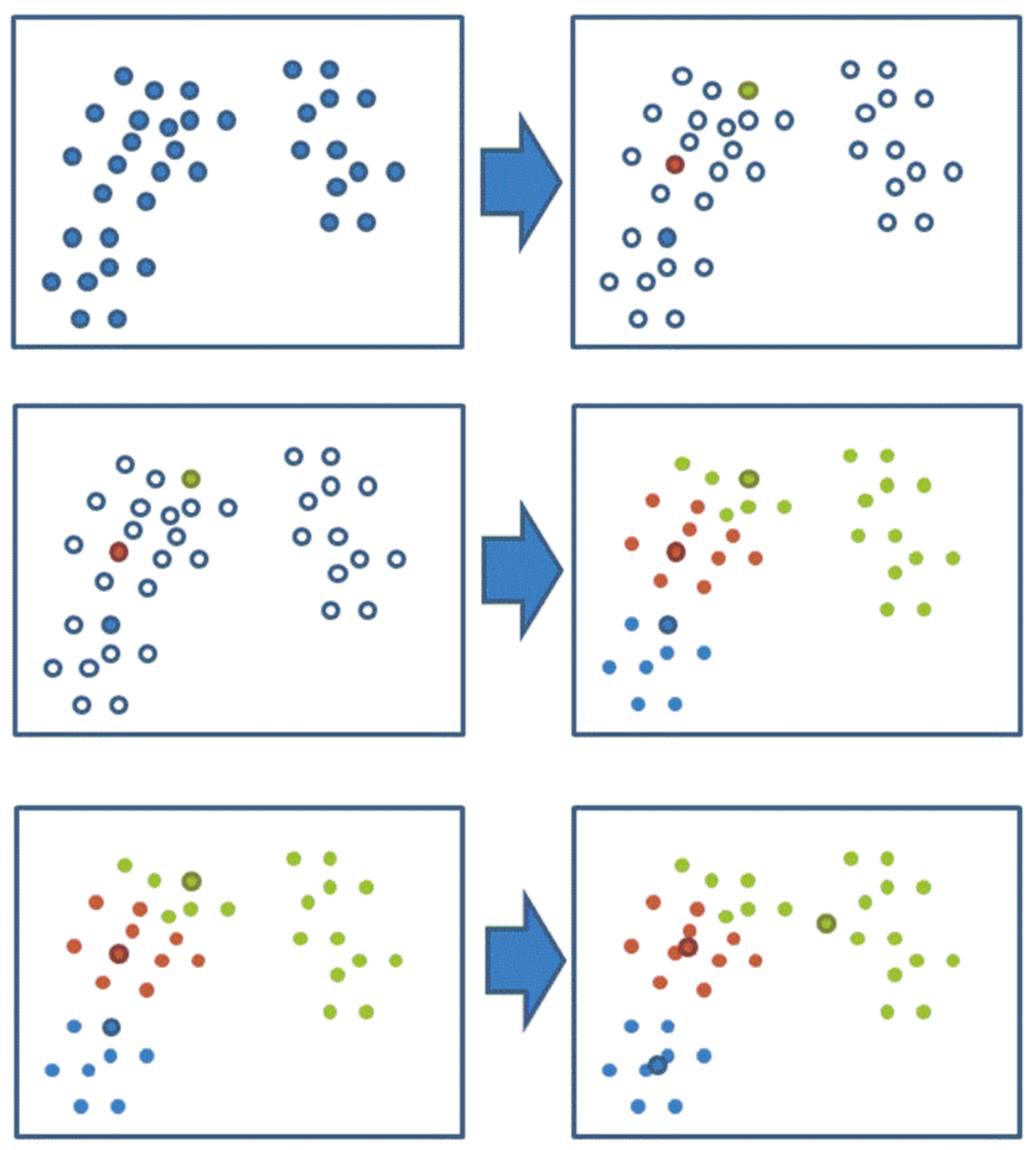
可视化 Kmeans 的流程:
sklearn API
sklearn.cluster.KMeans(
n_clusters=8,
max_iter=300,
random_state=None,
)其中 n_clusters 参数很重要,意思是开始聚类的中心数量,默认为 8。
常用属性:
| 属性 | 类型 | 含义 |
|---|---|---|
cluster_centers_ | ndarray | 聚类中心坐标 |
labels_ | ndarray | 每个训练样本所属簇 |
inertia_ | float | SSE(样本到所属簇中心的平方距离之和) |
n_iter_ | int | 实际运行的迭代次数 |
n_features_in_ | int | 训练数据的特征数量 |
feature_names_in_ | ndarray | 输入特征名称(如果数据有列名) |
下面使用 sklearn 随机创建一些符合高斯分布的点,然后通过聚类算法分类。
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
X, y = make_blobs(
n_samples=1000,
n_features=2,
centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.3, 0.5, 0.3],
random_state=0,
)
plt.scatter(X[:, 0], X[:, 1], marker="o", c=y)
plt.show()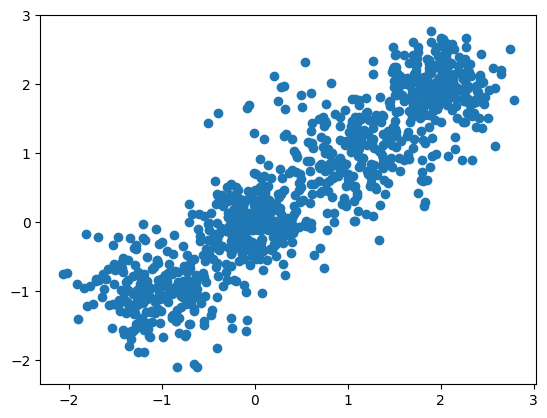
接下来开始分类,期望的类别是 4 个。
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
from sklearn.metrics import calinski_harabasz_score
X, y = make_blobs(
n_samples=1000,
n_features=2,
centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.3, 0.5, 0.3],
random_state=0,
)
estimator = KMeans(n_clusters=4, random_state=23)
y_pred = estimator.fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()
print(f"评价指标(评分): {calinski_harabasz_score(X, y_pred)}") # 评价指标(评分): 3278.0091359845114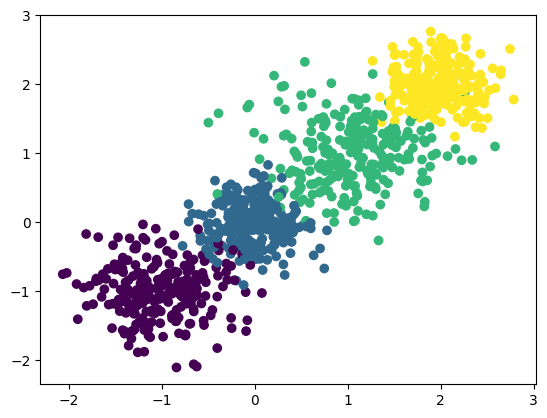
SSE 误差平方和
表示聚类中心的个数; 表示簇; 表示样本; 表示簇的质心。
SSE 越小,表示数据点越接近它们的中心,聚类效果越好。
SC 聚数
是 SSE 误差平方和的改良版,结合了聚类的凝聚度和分离度,用于评估聚类的效果。
表示样本 i 到同一簇内其他点不相似程度的平均值; 表示样本 i 到其他簇的平均不相似程度的最小值。
其计算过程如下:
- 计算每一个样本 i 到同簇内其他样本的平均距离 ,该值越小,说明簇内的相似程度越大
- 计算每一个样本 i 到最近簇 j 内的所有样本的平均距离 ,该值越大,说明该样本越不属于其他簇 j
- 计算所有样本的平均轮廓系数
- 轮廓系数的范围为:[-1, 1],值越大聚类效果越好
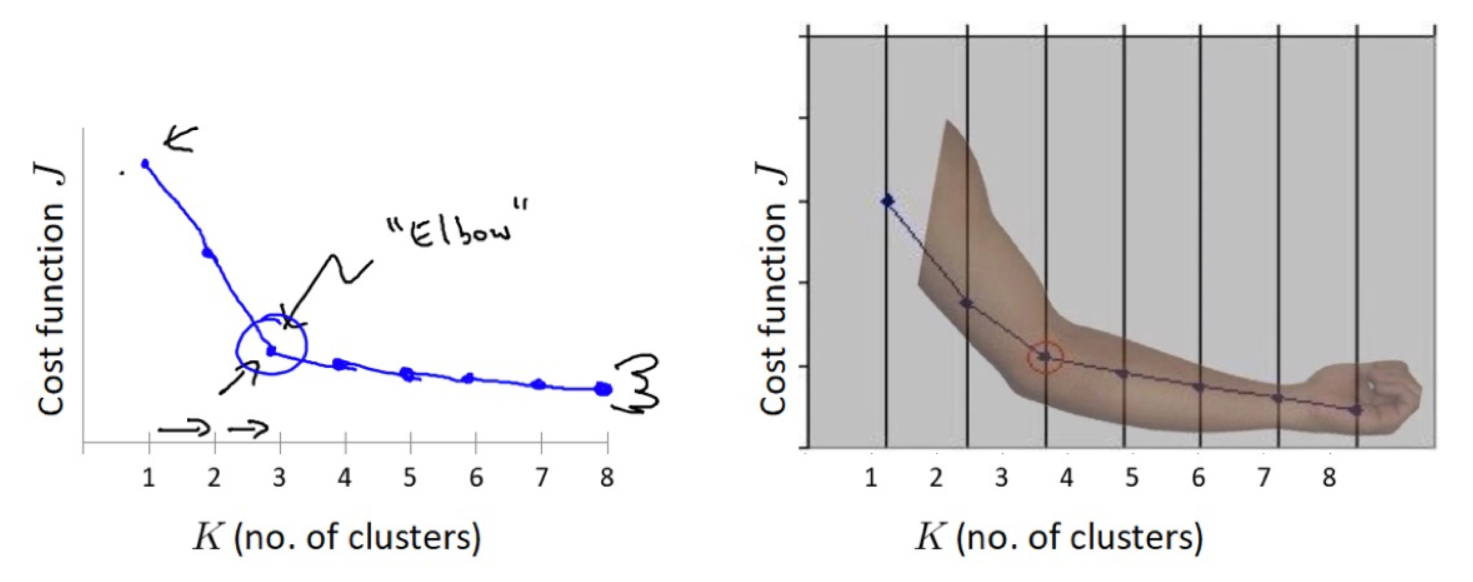
肘部法
肘部法可以用来确定 K 值。
- 对于 n 个点的数据集,迭代计算 k 从 1 到 n,每次聚类完成后计算 SSE。
- SSE 是会逐渐变小的,因为每个点都是它所在的簇中心本身。
- SSE 变化过程中会出现一个拐点,下降率突然变缓时即认为是最佳 n_clusters 值。
- 在决定什么时候停止训练时,肘形判据同样有效,数据通常有更多的噪音,在增加分类无法带来更多回报时,我们停止增加类别。
肘部法没有 API,可以借助循环实现。
k_range = [1, 2, 3, 4, 5]
for k in k_range:
estimator = KMeans(n_clusters=k, random_state=0)
y_pred = estimator.fit_predict(X)
print(f"K={k}, SSE={estimator.inertia_}")CH 系数
CH 系数结合了聚类的凝聚度(Cohesion)和分离度(Separation)、质心的个数,希望用最少的簇进行聚类。
SSW 的含义:
- 表示质心
- 表示某个样本
- SSW 值是计算每个样本点到质心的距离,并累加起来
- SSW 表示表示簇内的内聚程度,越小越好
- 表示样本数量
- 表示质心个数
SSB 的含义:
- 表示质心, 表示质心与质心之间的中心点, 表示样本的个数
- SSB 表示簇与簇之间的分离度,SSB 越大越好