
外观
Prompt-Tuning方法
NLP四范式
- 第一范式:基于「传统机器学习模型」的范式,如TF-IDF特征+朴素贝叶斯等机器算法。
- 第二范式:基于「深度学习模型」的范式,如word2vec特征+LSTM等深度学习算法,相比于第一范式,模型准确有所提高,特征工程的工作也有所减少。
- 第三范式:基于「预训练模型+fine-tuning」的范式,如Bert+fine-tuning的NLP任务,相比于第二范式,模型准确度显著提高,模型也随之变得更大,但小数据集就可训练出好模型。
- 第四范式:基于「预训练模型+Prompt+预测」的范式,如Bert+Prompt的范式相比于第三范式,模型训练所需的训练数据显著减少。
Fine-Tuning 方法
Fine-Tuning属于一种迁移学习方式,在自然语言处理(NLP)中,Fine-Tuning是用于将预训练的语言模型适应于特定任务或领域。Fine-Tuning的基本思想是采用已经在大量文本上进行训练的预训练语言模型,然后在小规模的任务特定文本上继续训练它。
缺点:
- 下游任务的目标和预训练的目标差距过大,可能导致过拟合;
- 微调过程中需要大量的监督语料。
解决方法就是引入 Prompt-Tuning 方法,通过添加模板的方法避免引入额外的参数,从而让模型可以在小样本(few-shot)或着零样本(zero-shot)场景下达到理想的效果。
思想
假设一个句子:
[CLS] I like the Disney films very much. [SEP]传统的Fine-tuning方法:将其通过BERT模型获得 [CLS] 表征之后再喂入新增加的MLP分类器进行二分类,预测该句子是积极的(positive)还是消极的(negative),因此需要一定量的训练数据来训练。
Prompt-Tuning方法:
- 构建模板(Template):生成与给定句子相关的一个含有
[MASK]标记的模板。例如It was [MASK],并拼接到原始的文本中,获得Prompt-Tuning的输入:[CLS] I like the Disney films very much. [SEP] It was [MASK]. [SEP].将其喂入BERT模型中,并复用预训练好的MLM分类器,即可直接得到[MASK]预测的各个token的概率分布。 - 标签词映射(Verbalizer):因为
[MASK]只对部分词感兴趣,因此需要建立一个映射关系。例如如果[MASK]预测的词是“great”,则认为是positive类,如果是“terrible”,则认为是negative类。 - 训练:根据Verbalizer,则可以获得指定label word的预测概率分布,并采用交叉信息熵进行训练。此时因为只对预训练好的MLM head进行微调,所以避免了过拟合问题。
面向超大规模参数模型的Prompt-Tuning方法
上下文学习 In-Context Learning
In-Context learning(ICL)最早在GPT3中提出,旨在从训练集中挑选少量的标注样本,设计任务相关的指令形成提示模板,用于指导测试样本生成相应的结果。
- zero-shot learning:在没有标注样本的情况下,根据任务相关的指令和测试样本,直接生成结果。
- one-shot learning:在只有一个标注样本的情况下,根据任务相关的指令和测试样本,生成结果。
- few-shot learning:在有少量标注样本的情况下,根据任务相关的指令和测试样本,生成结果。
指令学习方法 Instruction Tuning
其实Prompt-Tuning本质上是对下游任务的指令,简单的来说:就是告诉模型需要做什么任务,输出什么内容。上文我们提及到的离散或连续的模板,本质上就是一种对任务的提示。
因此,在对大规模模型进行微调时,可以为各种类型的任务定义指令,并进行训练,来提高模型对不同任务的泛化能力。
对比一下。
Prompt:
带女朋友去了一家餐厅,她吃的很开心,这家餐厅太__了。Instruction:
判断这句话的情感:带女朋友去了一家餐厅,她吃的很开心。选项:A=好,B=一般,C=差思维链 Chain of Thought
思维链 (Chain-of-thought,CoT) 的概念是在 Google 的论文 Chain-of-Thought Prompting Elicits Reasoning in Large Language Models" 中被首次提出。
思维链(CoT)是一种改进的提示策略,用于提高 LLM 在复杂推理任务中的性能,如算术推理、常识推理和符号推理。
思维链是一种离散式提示学习,更具体地,大模型下的上下文学习(即不进行训练,将例子添加到当前样本输入的前面,让模型一次输入这些文本进行输出完成任务),相比于之前传统的上下文学习(即通过x1,y1,x2,y2,....xtest作为输入来让大模型补全输出ytest),思维链多了中间的推导提示。
以求解一个数学题为例。

无法正确求解,应用思维链方法:
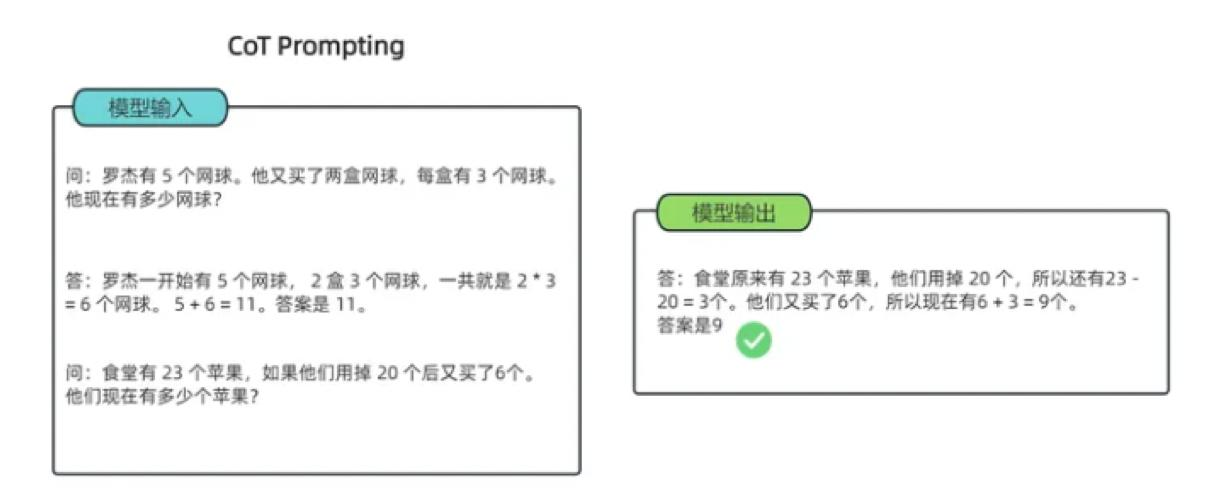
思维链分为两种:
- Few-shot CoT:ICL的一种特殊情况,它通过融合CoT推理步骤,将每个演示〈input,output〉扩充为〈input,CoT,output〉
- Zero-shot CoT:直接生成推理步骤,然后使用生成的CoT 来导出答案.(其中LLM首先由“Let's thinkstepbystep”提示生成推理步骤,然后由“Therefore,theansweris”提示得出最终答案。他们发现,当模型规模超过一定规模时,这种策略会大大提高性能,但对小规模模型无效,显示出显著的涌现能力模式)
思维链的特点:
- 逻辑性:思维链中的每个思考步骤都应该是有逻辑关系的,它们应该相互连接,从而形成一个完整的思考过程
- 全面性:思维链应该尽可能地全面和细致地考虑问题,以确保不会忽略任何可能的因素和影响
- 可行性:思维链中的每个思考步骤都应该是可行的,也就是说,它们应该可以被实际操作和实施
- 可验证性:思维链中的每个思考步骤都应该是可以验证的,也就是说,它们应该可以通过实际的数据和事实来验证其正确性和有效性
PEFT大模型参数高效微调
PEFT(Parameter-Efficient Fine-Tuning)参数高效微调方法是目前大模型在工业界应用的主流方式之一,PEFT 方法仅微调少量或额外的模型参数,固定大部分预训练参数,大大降低了计算和存储成本,同时最先进的 PEFT 技术也能实现了与全量微调相当的性能。
该方法可以使 PLM 高效适应各种下游应用任务,而无需微调预训练模型的所有参数,且让大模型在消费级硬件上进行全量微调(Full Fine-Tuning)变得可行。
Prefix/Prompt-Tuning
- 核心思想:冻结预训练语言模型(PLM)的参数,仅训练一小部分可学习的Prompt参数。
- Prefix-Tuning:在每一层Transformer输入前添加可训练的Prefix向量,用于引导模型生成目标任务结果。
- Prompt-Tuning:直接在输入文本前拼接若干可学习的虚拟Token(Soft Prompt),通过优化这些Prompt参数完成下游任务。
- 特点:
- 参数量极小,仅训练Prompt相关参数
- 适合超大模型(LLM)
- 推理时仍需依赖完整模型
- 不同任务仅需切换Prompt参数
- 优点:
- 训练成本低
- 参数存储开销小
- 易于多任务迁移
- 缺点:
- 小模型效果通常不稳定
- Prompt设计对性能影响较大
Adapter-Tuning
- 核心思想:冻结原始预训练模型参数,在Transformer层中插入轻量级Adapter模块,仅训练Adapter参数。
- Adapter结构:
- 通常为“降维 -> 非线性激活 -> 升维”
- 类似一个小型瓶颈网络(Bottleneck)
- 工作方式:
- 原模型参数保持不变
- 每层Transformer后增加Adapter
- 下游任务训练时只更新Adapter参数
- 特点:
- 参数高效(Parameter-Efficient Fine-Tuning,PEFT)
- 多任务可共享主模型
- 每个任务仅保存Adapter权重
- 优点:
- 微调稳定
- 适合多任务场景
- 能有效减少灾难性遗忘
- 缺点:
- 推理时增加额外网络层
- 会带来少量延迟
LoRA
LoRA(Low-Rank Adaptation of LLMs),即LLMs的低秩适应,是参数高效微调最常用的方法。
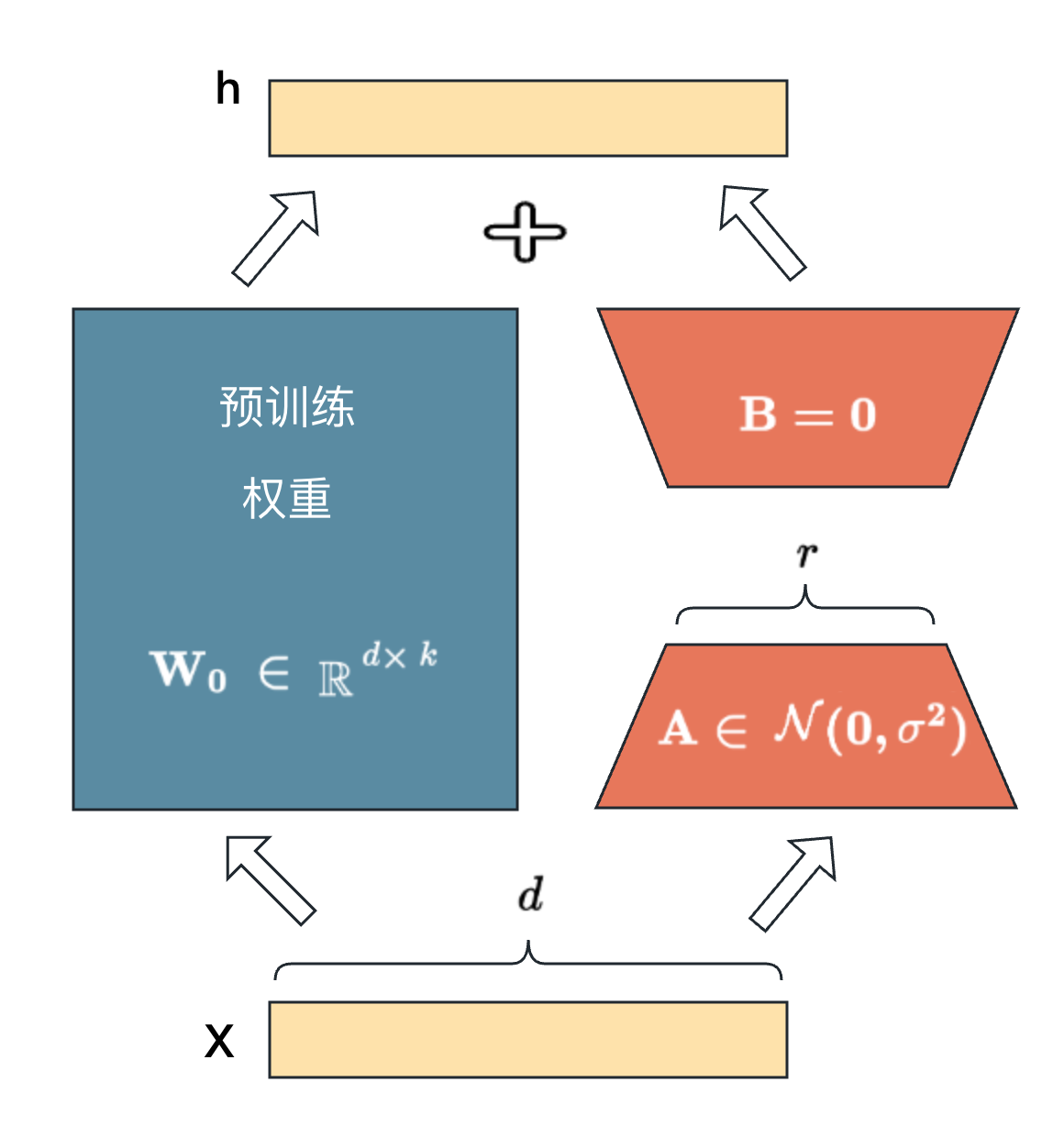
每个大模型中的参数,本质上都以矩阵(Matrix)的形式存储。一个模型通常包含大量高维参数矩阵,例如注意力层中的权重矩阵、前馈网络中的线性层矩阵等。
由于这些参数矩阵维度较高,如果直接对全部参数进行微调,不仅显存占用大,训练成本也非常高。
LoRA(Low-Rank Adaptation)等参数高效微调方法的核心思想,就是利用低秩矩阵分解(Low-Rank Decomposition)来近似参数更新,从而减少需要训练的参数数量。
假设存在一个参数矩阵:
其中:
- (n) 表示输出维度
- (m) 表示输入维度
在传统微调中,我们会直接更新整个矩阵 (W)。
而在 LoRA 中,并不直接修改原始参数矩阵,而是额外引入两个低秩矩阵:
其中:
- (r) 为低秩矩阵的秩(rank)
- 通常 (r \ll n,m)
- 常见取值包括 1、2、4、8、16 等
最终,通过两个低维矩阵的乘积来近似参数更新量:
于是模型参数变为:
由于:
因此,需要训练的参数数量会大幅减少,从而实现:
- 更低的显存占用
- 更快的训练速度
- 更低的微调成本
- 更容易在消费级 GPU 上训练
同时,由于原始参数 (W) 通常被冻结不更新,因此 LoRA 本质上只学习一个“低秩增量”。