
外观
Agent
一个 Agent,简单来说,就是一个能够感知环境、做出决策并采取行动来完成特定目标的“智能体”。最基础的LLM(大型语言模型),比如deepseek、ChatGPT,在回答问题时其实就已经是一个基础的Agent。它感知你的问题(环境),做出回答的决策,并生成文本(行动)。
但一个真正的Agent远不止于此。它需要更强的“能动性”,能够自主地进行反思、规划,甚至与其他Agent协作。这正是将基础LLM升级为高级Agent的关键。
Agentic
Agentic 是一个形容词,它描述的是一个系统所表现出的“像 Agent 一样的程度”。
一个系统越是 Agentic,它就越表现出自主性、目标导向性和主动性。它不是一个具体的实体,而是一种行为模式或设计思想。
- 低 Agentic 系统:一个简单的聊天机器人,只能根据预设规则回答问题。
- 高 Agentic 系统:一个能自动调试代码、部署应用并监控其运行状态的 AI 软件工程师。
正如OpenAI的AI主管 Lilian Weng(翁丽莲) 在她那篇关于自主智能体(Autonomous Agents) 的里程碑式博客文章《LLM Powered Autonomous Agents》中所强调的,具备智能体特性agentic的 AI,不会傻傻地等待下一步指令,而是会主动进行思考,发现自己犯了错,然后自己去修正。意识到需要外部信息,然后主动去调用工具。面对复杂任务时,自己去拆解成小步骤。
所以,智能体是载体,而它拥有的、让它变得强大的核心能力,正是这篇文章系统阐述的,规划、记忆和工具使用等关键组件。文章《LLM Powered Autonomous Agents》是智能体系统领域的里程碑之作,其价值在于系统化梳理了智能体的核心概念,提出ReAct 等模式,奠定了理论框架;通过案例和细节为工程实践提供了指导;推动了从被动响应到主动解决问题的 AI 范式转变;并以通俗语言连接了学术与工业,促进了技术普及,影响了智能体系统的研究与应用。” Agentic 特性并非凭空出现,它通过多种具体的工作模式来实现。下面我们将深入探索五种最常见的Agentic模式,它们定义了Agent在不同场景下的“工作风格”。值得一提的是,这些模式的演化路径与 ReAct 思想有着紧密的联系,后者被视为开启了Agentic系统设计的大门。
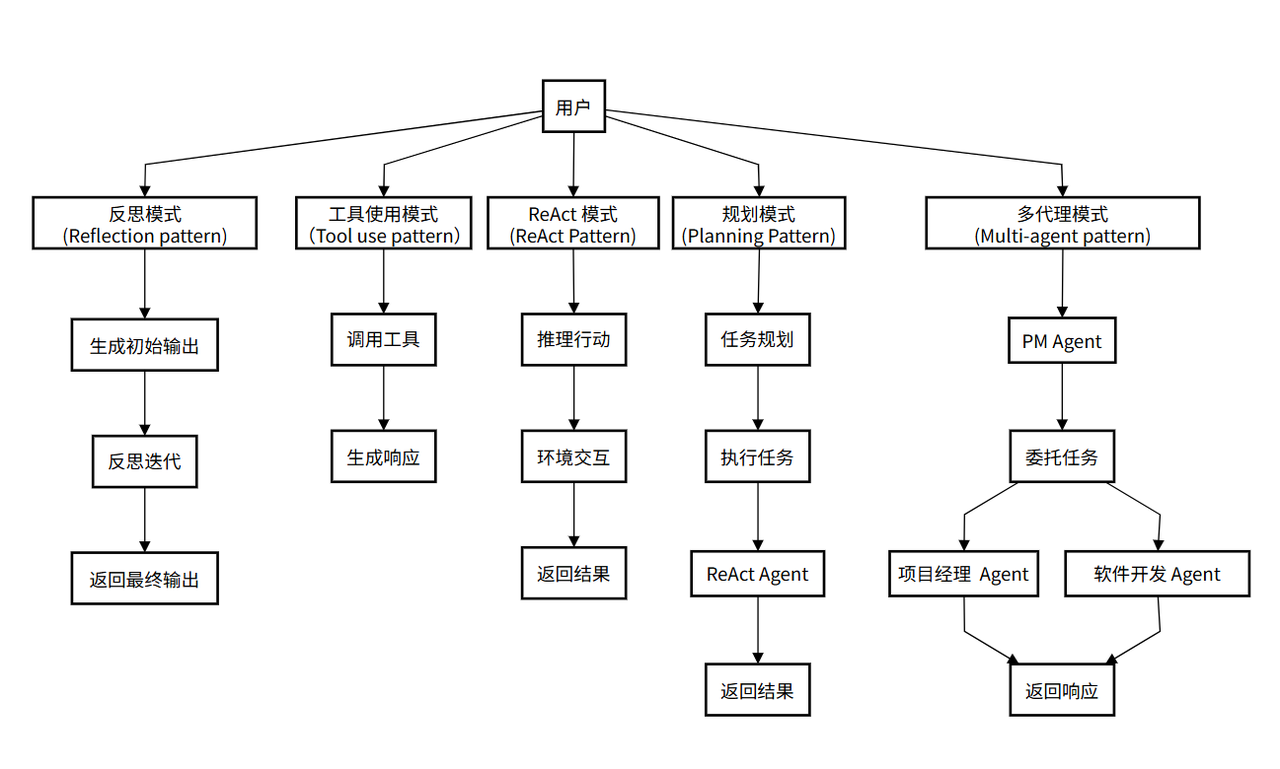
Agent 常用的五种模式
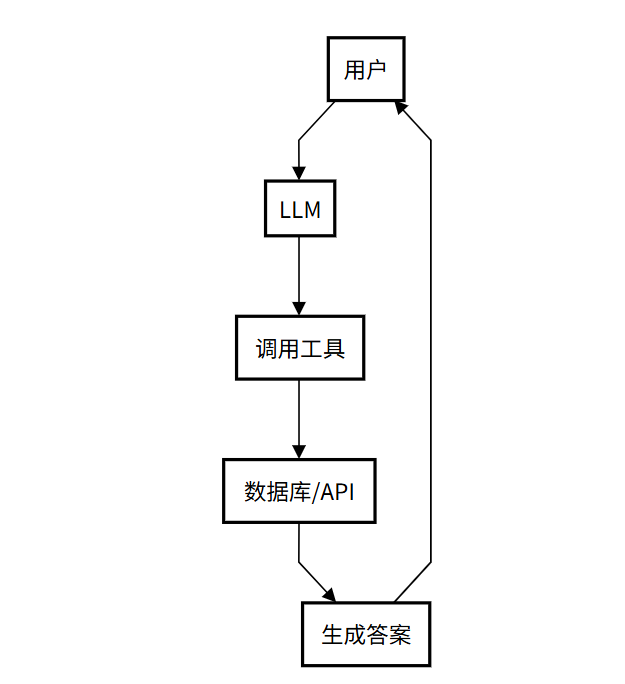
工具使用模式
核心精髓: 工具使用模式可以看作是 ReAct 模式的前身或简化版。它允许 Agent 调用外部工具来弥补自身知识的不足,但通常缺乏 ReAct 模式中那种细致入微的“思考-行动-观察”循环。它的局限在于其推理能力较弱,通常只适用于单步、直接的任务,缺乏动态调整和迭代的能力。
工作流程(像请教专家):
- 用户问问题:提出一个问题。
- LLM 想想:小助手判断需要外援。
- 调用工具:它找来数据库或 API 查资料。
- 给出答案:根据查到的东西,生成回复。
- 交给你:答案回到你手里。
如一个客服 Agent 接到“查询我的订单状态”的请求。它不会胡乱猜测,而是思考需要查询订单信息,然后行动调用 query_order_status(order_id) 这个工具(API),最后根据返回的结果回答用户。
示例中 Langchain 版本为 1.3。
from langchain.agents import create_agent
from langchain_core.tools import tool
from langchain_ollama import ChatOllama
# =========================
# 1. 初始化模型
# =========================
llm = ChatOllama(
model="qwen2.5:7b",
temperature=0.8,
)
# =========================
# 2. 定义工具
# =========================
@tool
def multiply(a: int, b: int) -> int:
"""
计算两个整数的乘积
"""
print(f"正在执行乘法: {a} * {b}")
return a * b
@tool
def search_weather(city: str) -> str:
"""
查询指定城市天气
"""
print(f"正在查询天气: {city}")
if "北京" in city:
return "北京今天是晴天,气温25摄氏度。"
if "上海" in city:
return "上海今天是阴天,有小雨,气温22摄氏度。"
return f"抱歉,没有找到 {city} 的天气信息。"
tools = [
multiply,
search_weather,
]
# =========================
# 3. 创建 Agent
# =========================
agent = create_agent(
model=llm,
tools=tools,
system_prompt="""
你是一个智能助手。
当用户询问天气时调用 search_weather。
当用户需要计算时调用 multiply。
不要编造工具结果。
""",
)
# =========================
# 4. 执行函数
# =========================
def ask(query: str):
print(f"\n用户: {query}")
result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": query,
}
]
}
)
print("\nAgent回复:")
# 最新 LangChain 返回消息列表
for message in result["messages"]:
if hasattr(message, "content") and message.content:
print(message.content)
# =========================
# 5. 测试
# =========================
if __name__ == "__main__":
ask("上海今天的天气怎么样?")
ask("30乘以5是多少?")
ask("30乘以5是多少?顺便查询上海天气")用户: 上海今天的天气怎么样?
正在查询天气: 上海
Agent回复:
上海今天的天气怎么样?
上海今天是阴天,有小雨,气温22摄氏度。
上海今天是阴天,有小雨,气温22摄氏度。请注意携带雨具出行。
用户: 30乘以5是多少?
正在执行乘法: 30 * 5
Agent回复:
30乘以5是多少?
150
30乘以5的结果是150。
用户: 30乘以5是多少?顺便查询上海天气
正在执行乘法: 30 * 5
正在查询天气: 上海
Agent回复:
30乘以5是多少?顺便查询上海天气
150
上海今天是阴天,有小雨,气温22摄氏度。
30乘以5的结果是150。
查询结果显示,上海今天是阴天,有小雨,气温22摄氏度。请记得带伞哦!ReAct 模式
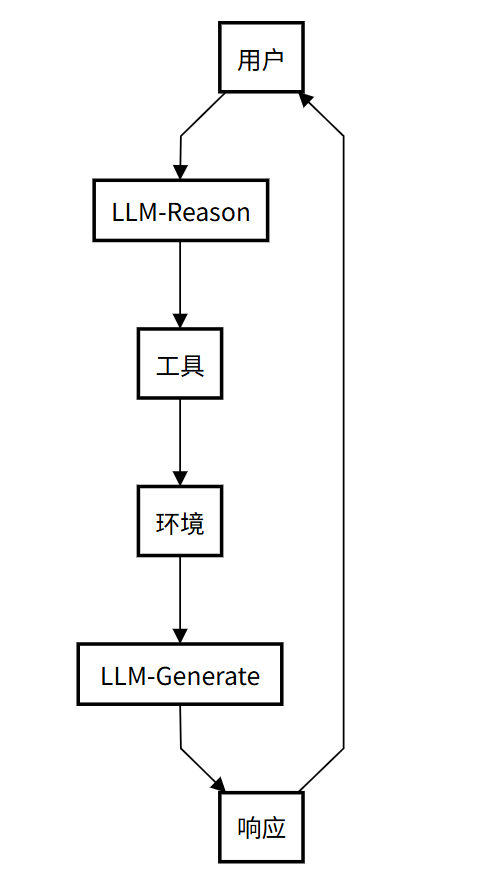
几乎所有高级的 Agent 模式都离不开一个核心思想——ReAct (Reason + Act)。这是 Agent 实现“思考”与“行动”循环的基础。
核心精髓: ReAct(Reasoning and Acting)模式是Agentic思想的奠基性贡献。它将“思考”(Reasoning)和“行动”(Acting)紧密地结合在一起,形成一个动态的循环。这个模式让Agent不再是简单地调用工具,而是像人类一样“边想边做”。ReAct 模式最早由 Yao 等人于 2022 年提出(论文《ReAct: Synergizing Reasoning and Acting in Language Models》),并在 Lilian Weng 的博客中得到系统阐述,成为Agentic系统设计的基础。
工作流程:
- 思考: Agent接收用户请求,推理任务需求并制定初步行动计划。
- 行动: 根据思考结果,决定并执行具体行动(如调用工具)。
- 行动输入: 为选定的工具提供必要参数。
- 观察: 接收工具执行结果,作为对环境的“观察”。
- 循环迭代: 将观察结果反馈给自己,再次思考并决定下一步,直到达到目标。
如研究助理agent:任务是“查找关于‘大型语言模型在教育领域的应用’的最新研究论文”。
- Thought: 我需要去学术搜索引擎搜索相关论文。
- Action:
search_arxiv("large language models in education") - Observation: (返回了10篇论文的标题和摘要)
- Thought: 结果太多了,我需要筛选出最近一年且被引用次数最多的论文。
- Action:
filter_papers(results, min_year=2023, sort_by="citations") - Observation: (返回了3篇最相关的论文)
- Thought: 我已经找到了最相关的论文,现在可以总结并回答用户了。
from langchain.agents import create_agent
from langchain_core.tools import tool
from langchain_ollama import ChatOllama
# =====================
# 初始化模型
# =====================
llm = ChatOllama(
model="qwen2.5:7b",
temperature=0.8,
)
# =====================
# 工具定义
# =====================
@tool
def multiply(numbers_str: str) -> int:
"""
计算两个整数乘积
输入格式:
100,25
"""
print(f"正在执行乘法: {numbers_str}")
a_str, b_str = numbers_str.split(",")
return int(a_str.strip()) * int(b_str.strip())
@tool
def search_weather(city: str) -> str:
"""
查询城市天气
"""
print(f"正在查询天气: {city}")
if "北京" in city:
return "北京今天是晴天,气温25摄氏度。"
if "上海" in city:
return "上海今天是阴天,有小雨,气温22摄氏度。"
return f"没有找到 {city} 的天气信息"
tools = [
multiply,
search_weather,
]
# =====================
# 创建 Agent
# =====================
agent = create_agent(
model=llm,
tools=tools,
system_prompt="""
你是一个智能助手。
规则:
1. 计算乘法时必须调用 multiply
2. 查询天气时必须调用 search_weather
3. 多个任务依次处理
4. 不允许编造工具结果
5. 获得工具结果后再回答用户
""",
)
# =====================
# 执行函数
# =====================
def run(query: str):
print(f"\n用户: {query}")
result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": query
}
]
}
)
print("\nAgent回复:")
for msg in result["messages"]:
if hasattr(msg, "content") and msg.content:
print(msg.content)
# =====================
# 测试
# =====================
if __name__ == "__main__":
run("上海今天的天气怎么样?")
run("100乘以25等于多少?")
run("100乘以25等于多少?上海天气怎么样?")用户: 上海今天的天气怎么样?
正在查询天气: 上海
Agent回复:
上海今天的天气怎么样?
上海今天是阴天,有小雨,气温22摄氏度。
上海今天是阴天,有小雨,气温22摄氏度。请记得携带雨具出行。
用户: 100乘以25等于多少?
正在执行乘法: 100,25
Agent回复:
100乘以25等于多少?
2500
100乘以25等于2500。
用户: 100乘以25等于多少?上海天气怎么样?
正在执行乘法: 100,25
正在查询天气: 上海
Agent回复:
100乘以25等于多少?上海天气怎么样?
2500
上海今天是阴天,有小雨,气温22摄氏度。
100乘以25等于2500。上海今天是阴天,有小雨,气温22摄氏度。反思模式
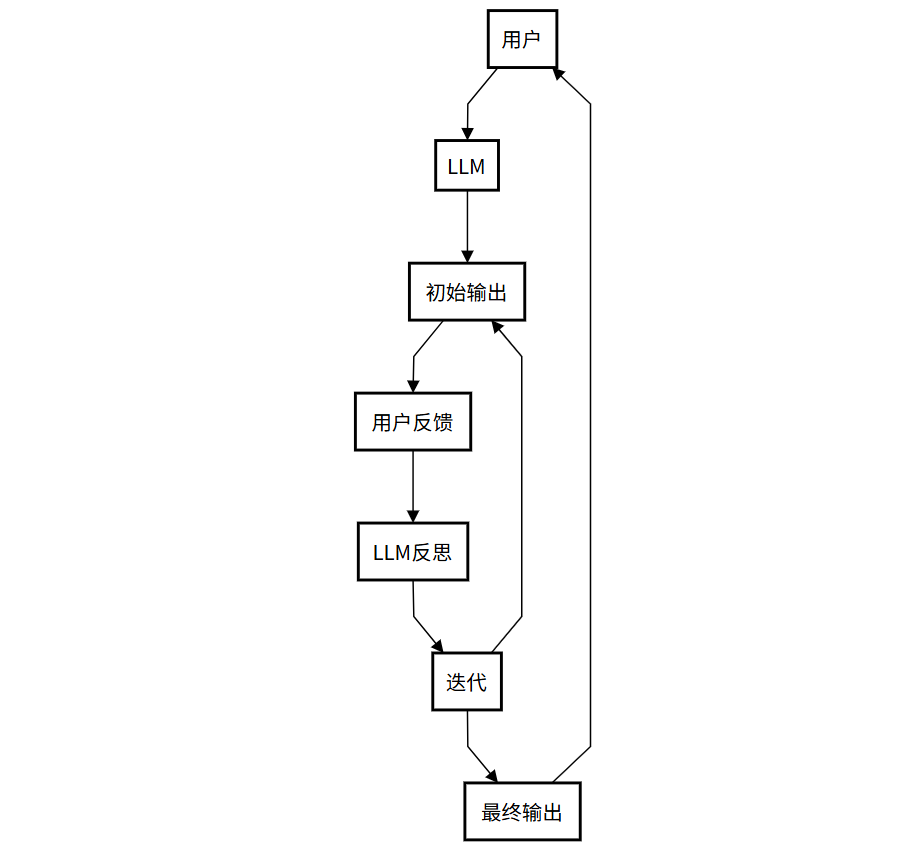
为了提高任务完成的质量,Agent 在完成一个步骤或整个任务后,会进行自我评估和反思,并根据反思结果进行修正。
核心精髓:反思模式是 ReAct 模式中“思考”环节的深化。它强调 Agent 在完成任务后,能够像人类一样进行自我审查和评估。这个过程让 Agent 能够从错误中学习,持续优化自己的表现。
工作流程:
- 用户问问题:你给小助手提个问题。
- LLM 给出初稿:小助手先试着回答,写个初步答案。
- 用户反馈:用户查看答案行不行,提出意见。
- LLM 自己反思:小助手想想哪里不对,改改答案。
- 反复调整:可能来回改几次,直到你满意。
- 交给你:最终答案交到你手里。
如AI 代码生成器:任务是“写一个 Python 函数来计算斐波那契数列”。
- Action: Agent 快速生成了一个使用递归实现的函数。
- Reflection (Self-Critique): Agent 开始反思生成的代码。“这个递归实现在计算较大数值时,会因为重复计算而导致性能低下。我应该优化它。”
- Action (Refinement): Agent 重新编写代码,使用了带缓存(memoization)的动态规划方法,大大提高了效率,然后将优化后的代码作为最终答案。
from langchain_ollama import ChatOllama
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# =========================
# 1. 初始化本地 Ollama 模型
# =========================
llm = ChatOllama(
model="qwen2.5:7b",
temperature=0.8,
)
# =========================
# 2. 初始回答链
# =========================
initial_response_prompt = ChatPromptTemplate.from_template(
"请根据以下问题给出你的初步回答:{question}"
)
initial_response_chain = (
initial_response_prompt
| llm
| StrOutputParser()
)
# =========================
# 3. 反思链
# =========================
reflection_prompt = ChatPromptTemplate.from_template(
"""
你是一个专业的、善于反思的AI助手。
你之前给出了以下回答:
---
{previous_response}
---
现在,你收到了用户反馈:
---
{user_feedback}
---
请认真分析回答中的不足。
然后生成一个更加准确、更完善、更详细的新回答。
新回答:
"""
)
reflection_chain = (
reflection_prompt
| llm
| StrOutputParser()
)
# =========================
# 4. 反射流程
# =========================
def reflect_and_refine(query: str, feedback: str):
"""
模拟一次完整的 Reflection 流程
"""
print("=== 启动 Reflection ===")
print(f"\n用户问题:\n{query}")
# 第一次回答
print("\n正在生成初始回答...\n")
initial_response = initial_response_chain.invoke(
{
"question": query
}
)
print(initial_response)
# 用户反馈
print("\n用户反馈:")
print(feedback)
# 第二次回答
print("\n正在根据反馈进行反思...\n")
refined_response = reflection_chain.invoke(
{
"previous_response": initial_response,
"user_feedback": feedback,
}
)
print(refined_response)
return refined_response
# =========================
# 5. 主程序
# =========================
if __name__ == "__main__":
question = "请用一句话介绍 LangChain。"
feedback = (
"回答太简单了,请详细说明 LangChain 的核心组件,"
"并解释 Chain、Agent、Tool 三者之间的区别。"
)
reflect_and_refine(question, feedback)=== 启动 Reflection ===
用户问题:
请用一句话介绍 LangChain。
正在生成初始回答...
LangChain 是一个将语言模型与链式逻辑推理相结合的框架,旨在通过串联多个步骤来解决复杂问题。
用户反馈:
回答太简单了,请详细说明 LangChain 的核心组件,并解释 Chain、Agent、Tool 三者之间的区别。
正在根据反馈进行反思...
感谢您的反馈,您提出的问题确实需要进一步的详细说明。LangChain 是一种先进的架构设计,它通过结合语言模型和链式逻辑推理来解决复杂问题。在这个框架中,核心组件包括 Chain(任务链)、Agent(智能代理)以及 Tool(工具)。下面我将分别介绍这三者之间的区别与作用。
1. **Task Chain (任务链)**:Task Chain 是 LangChain 中负责串联多个步骤、逐步解决问题的主要结构。它由一系列有序的任务组成,每个任务根据其前一个任务的结果来执行,最终达到预期的目标或解决方案。这些任务可能涉及自然语言处理(NLP)、知识图谱查询、数据分析等。
2. **Agent (智能代理)**:Agent 是 LangChain 中用于实际执行任务的关键组件。它能够理解用户的请求,并基于当前的环境信息和先前的知识进行决策与操作。Agent 通过与各种工具交互来获取或提供必要信息,以完成复杂的任务链中的单个步骤。Agent 的核心功能包括理解和生成自然语言、搜索相关信息等。
3. **Tool (工具)**:在 LangChain 中,Tool 被视为外部资源或服务的接口。它们能够帮助 Agent 获取必要的数据、执行特定操作或将结果转换为所需的格式。这些工具可以是API(如天气预报API)、数据库查询工具或其他任何能够提供所需信息和服务的技术系统。
通过上述介绍可以看出,在 LangChain 的框架中,Task Chain 负责定义解决问题的方法论;Agent 作为连接用户需求与外部资源的桥梁;而 Tool 则为 Agent 提供执行具体任务所需的手段。三者相辅相成、紧密配合,共同构建起一个高效且智能的问题解决体系。
希望这个解释能够帮助您更好地理解 LangChain 的核心组件及其工作原理。如果您有任何其他问题或需要进一步的信息,请随时告知。生成第二个回答的时间可能比较长,因为没加流式输出。
规划模式
当任务非常复杂,无法通过简单的 ReAct 循环一步到位时,Agent 需要先进行宏观规划。
核心思想:先将一个大目标分解成一个详细的、有序的计划(Plan),然后再逐一执行计划中的每个步骤(每个步骤可能是一个 ReAct 循环)。
AI 旅行规划师:任务是“帮我规划一个为期五天的巴黎家庭亲子游”。
- Planning Phase: Agent 首先生成一个计划:
- 步骤一:确定旅行日期和预算。
- 步骤二:根据亲子游的特点,搜索并筛选合适的景点(如迪士尼、卢浮宫儿童区)。
- 步骤三:规划每日行程,确保节奏轻松,并预订门票。
- 步骤四:搜索并推荐适合家庭入住的酒店和餐厅。
- 步骤五:汇总所有信息,生成一份详细的旅行计划文档。
- Execution Phase: Agent 开始按顺序执行上述步骤,每一步都可能调用搜索、预订等工具。
from langchain.agents import create_agent
from langchain_core.tools import tool
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_ollama import ChatOllama
# =========================
# LLM
# =========================
llm = ChatOllama(
model="qwen2.5:7b",
temperature=0.8,
)
# =========================
# Tools
# =========================
@tool
def multiply(a: int, b: int) -> int:
"""计算两个整数的乘积"""
print(f"正在执行乘法: {a} × {b}")
return a * b
@tool
def search_weather(city: str) -> str:
"""查询城市天气"""
print(f"正在查询天气: {city}")
if "北京" in city:
return "北京今天晴天,25℃"
if "上海" in city:
return "上海今天阴天,有小雨,22℃"
return f"没有找到 {city} 的天气信息"
tools = [multiply, search_weather]
# =========================
# Planner
# =========================
planner_prompt = ChatPromptTemplate.from_template(
"""
你是一个任务规划师。
请把用户任务拆分成多个步骤。
每行一个步骤。
例如:
用户:
请先查上海天气,然后计算20乘以30
输出:
查上海天气
计算20乘以30
用户:
{user_input}
"""
)
planner_chain = (
planner_prompt
| llm
| StrOutputParser()
)
# =========================
# Executor Agent
# =========================
agent = create_agent(
model=llm,
tools=tools,
system_prompt="""
你是一个工具执行专家。
你的职责:
1. 根据任务自动选择工具
2. 调用工具
3. 返回结果
不要编造工具结果。
"""
)
# =========================
# Workflow
# =========================
def execute_planning_pattern(query: str):
print("==========")
print("开始规划")
print("==========")
plan = planner_chain.invoke({
"user_input": query
})
tasks = [
line.strip("- ")
for line in plan.splitlines()
if line.strip()
]
print("\n任务列表:")
for i, task in enumerate(tasks, start=1):
print(f"{i}. {task}")
print("\n==========")
print("开始执行")
print("==========")
results = []
for i, task in enumerate(tasks, start=1):
print(f"\n执行任务{i}: {task}")
response = agent.invoke(
{
"messages": [
{
"role": "user",
"content": task
}
]
}
)
result = response["messages"][-1].content
print("结果:", result)
results.append(result)
print("\n==========")
print("汇总结果")
print("==========")
for i, result in enumerate(results, start=1):
print(f"{i}. {result}")
if __name__ == "__main__":
query = "请先计算50乘以60,然后告诉我上海天气怎么样"
execute_planning_pattern(query)==========
开始规划
==========
任务列表:
1. 计算50乘以60
2. 查上海天气
==========
开始执行
==========
执行任务1: 计算50乘以60
正在执行乘法: 50 × 60
结果: 50 乘以 60 的结果是 3000。
执行任务2: 查上海天气
正在查询天气: 上海
结果: 上海今天的天气是阴天,并且会有小雨,气温约为22℃。
==========
汇总结果
==========
1. 50 乘以 60 的结果是 3000。
2. 上海今天的天气是阴天,并且会有小雨,气温约为22℃。多智能体协同
对于极其复杂的系统性任务,单个 Agent 可能难以胜任。这时,可以设计多个具有不同角色和能力的 Agent,让它们协同工作。
核心精髓: 多智能体模式是Agentic思想的终极体现,它模拟了人类团队协作的工作方式。它不再依赖一个Agent单打独斗,而是创建多个具有不同专长的Agent,让它们各司其职、相互协作,共同完成一个复杂的任务。尽管多智能体模式功能强大,但实现时需要解决Agent间的通信效率、任务冲突等问题,这对系统设计提出了更高要求。
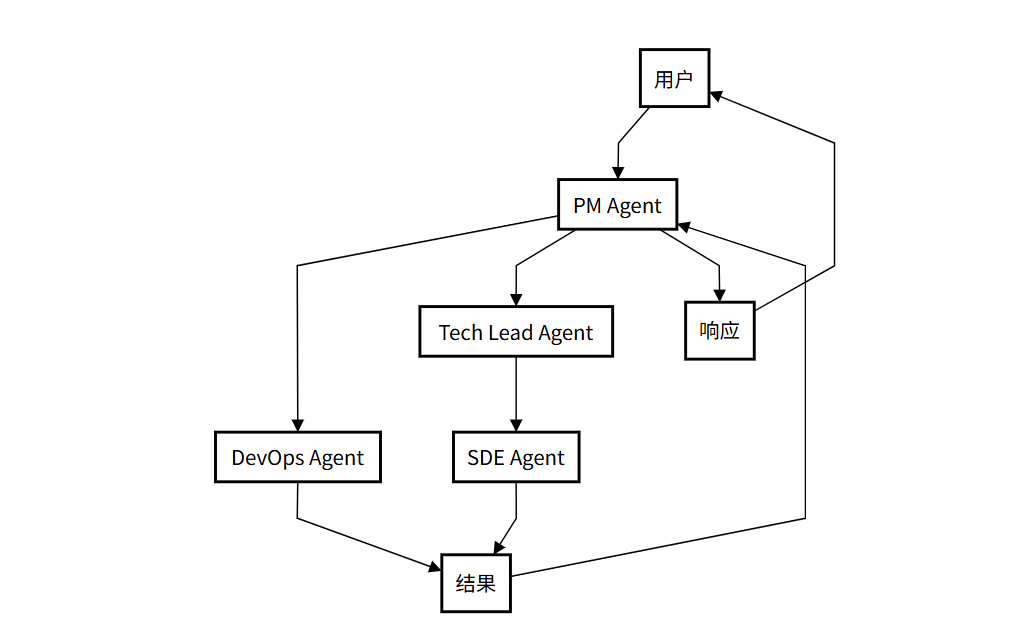
以下是该模式的⼯作流程介绍:
用户问问题:你提个大需求(比如开发一个软件项目)。
PM Agent:项目经理 Agent 分析需求并分配任务(协调整个团队)。
委托任务:任务交给 DevOps 和 Tech Lead(DevOps 负责运维,Tech Lead 负责技术领导)。
执行任务:DevOps(处理部署和测试) 和 SDE(编写代码)干活(具体实施任务)。
结果汇总:大家干完后,把结果汇报给 PM Agent(统一收集反馈)。
交给你:PM Agent 整合所有结果,给你最终答案(交付完成的项目)。
这个流程通过多个智能体协作,模拟真实团队工作,确保复杂任务高效完成。 如自动化软件开发团队:
项目经理 Agent: 负责理解用户需求,并将其分解成具体的开发任务。
程序员 Agent: 接收任务,编写代码。
测试工程师 Agent: 编写测试用例,对程序员 Agent 写的代码进行测试,并报告 Bug。
代码审查员 Agent: 审查代码质量和规范性。
协调者 (Orchestrator): 负责在这些 Agent 之间传递信息、分配任务,确保整个团队高效协作,最终交付一个完整的软件功能。
# -*- coding: utf-8 -*-
from langchain.agents import create_agent
from langchain_core.tools import tool
from langchain_ollama import ChatOllama
# ======================
# LLM
# ======================
llm = ChatOllama(
model="qwen2.5:7b",
temperature=0.8,
)
# ======================
# 工具
# ======================
@tool
def multiply(a: int, b: int) -> int:
"""计算两个整数的乘积"""
print(f"\n[工具] multiply({a}, {b})")
return a * b
@tool
def add(a: int, b: int) -> int:
"""计算两个整数的和"""
print(f"\n[工具] add({a}, {b})")
return a + b
@tool
def search_weather(city: str) -> str:
"""查询指定城市天气"""
print(f"\n[工具] search_weather({city})")
if city == "北京":
return "北京今天晴天,25℃"
if city == "上海":
return "上海今天阴天,22℃"
return f"暂无 {city} 的天气信息"
@tool
def get_current_date() -> str:
"""获取当前日期"""
import datetime
print("\n[工具] get_current_date()")
return datetime.date.today().strftime("%Y-%m-%d")
# ======================
# 数学 Agent
# ======================
math_agent = create_agent(
model=llm,
tools=[multiply, add],
system_prompt="""
你是一个数学专家。
遇到计算问题时必须调用工具。
不要自己心算。
""",
)
# ======================
# 信息 Agent
# ======================
info_agent = create_agent(
model=llm,
tools=[search_weather, get_current_date],
system_prompt="""
你是一个信息查询专家。
遇到天气和日期问题时必须调用工具。
""",
)
# ======================
# 工作流
# ======================
def multi_agent_workflow():
print("===== 数学 Agent =====")
math_result = math_agent.invoke({"messages": [{"role": "user", "content": "计算25乘以4"}]})
print(math_result)
print("\n===== 信息 Agent =====")
info_result = info_agent.invoke({"messages": [{"role": "user", "content": "查询北京天气和当前日期"}]})
print(info_result)
if __name__ == "__main__":
multi_agent_workflow()A2A 协议
2025年4月9日,Google 正式发布了 Agent2Agent Protocol(以下简称 “A2A”)。该协议为不同类型的智能体之间搭建了一座高效沟通与协作的桥梁,无论是独立Agent与独立Agent、独立Agent与企业Agent,亦或是企业Agent与企业Agent,都能借助该协议实现通信交互和协作。
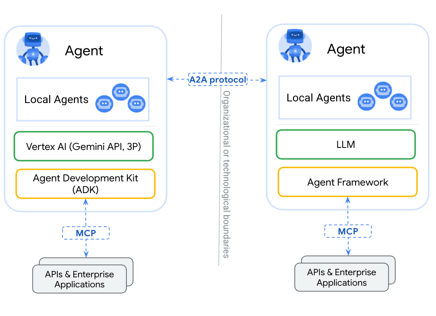
架构
A2A核心角色:
- User:用户
- Client Agent:将用户的问题下发给Agent host
- Agent host:进行计划,并来决定远程调用哪些agent
- Agent Server:提供远程服务的agent
核心概念
Agent Skill
AgentSkill描述代理的具体能力或功能模块,例如处理特定任务的技能。它包括技能名称、描述、示例、输入/输出模式等。在A2A协议中,技能是代理卡片(AgentCard)的组成部分,用于细粒度服务发现。支持扩展标签和示例,便于代理间匹配调用。
from python_a2a import AgentSkill
ticket_skill = AgentSkill(
name="book_ticket",
description="预订火车票的技能",
examples=["预订从上海到北京的火车票"],
input_modes=["text/plain"],
output_modes=["text/plain"]
)
print(ticket_skill)
print(ticket_skill.to_dict())AgentSkill(name='book_ticket', description='预订火车票的技能', id='9a8281dd-b8d6-4db4-9fe4-ba97a8f54251', tags=[], examples=['预订从上海到北京的火车票'], input_modes=['text/plain'], output_modes=['text/plain'])
{'id': '9a8281dd-b8d6-4db4-9fe4-ba97a8f54251', 'name': 'book_ticket', 'description': '预订火车票的技能', 'tags': [], 'examples': ['预订从上海到北京的火车票'], 'inputModes': ['text/plain'], 'outputModes': ['text/plain']}Agent Card
AgentCard 是 Server Agent 的名片,它主要描述了 Server Agent 的能力、认证机制等信息。Client Agent通过获取不同 Server Agent 的 AgentCard,了解不同 Server Agent 的能力,来决断具体的任务执行应该调用哪个 Server Agent 。AgentCard是A2A协议中Agent代理的元数据描述卡片,用于代理发现和服务注册。它包含代理的名称、描述、URL、版本、技能列表、能力(如流式传输支持)和输入/输出模式等信息。AgentCard允许其他代理或系统查询和调用该代理的服务,是A2A生态系统的入口点。在源码中,它支持序列化为JSON格式,便于网络传输。
from python_a2a import AgentCard, AgentSkill
ticket_skill = AgentSkill(
name="book_ticket",
description="预订火车票的技能",
examples=["预订从上海到北京的火车票"],
input_modes=["text/plain"],
output_modes=["text/plain"]
)
agent_card = AgentCard(
name="TicketAgent",
description="一个可以预订票务的代理",
url="http://127.0.0.1:5009",
version="1.0.0",
skills=[ticket_skill],
capabilities={"streaming": True}
)
print(agent_card)
print(agent_card.to_dict())AgentCard(name='TicketAgent', description='一个可以预订票务的代理', url='http://127.0.0.1:5009', version='1.0.0', protocol_version='0.3.0', preferred_transport='JSONRPC', authentication=None, capabilities={'streaming': True}, default_input_modes=['text/plain'], default_output_modes=['text/plain'], skills=[AgentSkill(name='book_ticket', description='预订火车票的技能', id='fe70946c-7a0f-4cbe-9f41-18537294df00', tags=[], examples=['预订从上海到北京的火车票'], input_modes=['text/plain'], output_modes=['text/plain'])], provider=None, documentation_url=None)
{'name': 'TicketAgent', 'description': '一个可以预订票务的代理', 'url': 'http://127.0.0.1:5009', 'version': '1.0.0', 'protocolVersion': '0.3.0', 'preferredTransport': 'JSONRPC', 'capabilities': {'streaming': True}, 'defaultInputModes': ['text/plain'], 'defaultOutputModes': ['text/plain'], 'skills': [{'id': 'fe70946c-7a0f-4cbe-9f41-18537294df00', 'name': 'book_ticket', 'description': '预订火车票的技能', 'tags': [], 'examples': ['预订从上海到北京的火车票'], 'inputModes': ['text/plain'], 'outputModes': ['text/plain']}]}Task State
TaskState任务状态枚举类,TaskState 是一个枚举类,定义了任务的可能状态,如提交(SUBMITTED)、完成(COMPLETED)、失败(FAILED)等。它是任务生命周期的基础,用于确保状态一致性和可读性。
TaskState 有如下状态:
| 状态名称 | 值 | 中文描述 |
|---|---|---|
| SUBMITTED | submitted | 任务已提交 |
| WORKING | working | 任务正在处理中 |
| INPUT_REQUIRED | input-required | 任务需要输入 |
| COMPLETED | completed | 任务已完成 |
| CANCELLED | cancelled | 任务已取消 |
| FAILED | failed | 任务已失败 |
| UNKNOWN | unknown | 任务状态未知 |
- 状态名称:TaskState 枚举的成员名称(例如 TaskState.SUBMITTED),用于代码中的类型安全引用。
- 值:枚举的字符串值(例如 "submitted"),用于序列化(如 JSON)或与外部系统交互。
- 中文描述:每个状态的作用和场景,帮助开发者理解其在任务生命周期中的意义。
from python_a2a import TaskState
if TaskState.COMPLETED == 'completed':
print('任务完成')
state = TaskState.COMPLETED
print('转换后的状态值:', state.value)
print(state)任务完成
转换后的状态值: completed
TaskState.COMPLETEDTask Status
TaskStatus 表示 A2A 任务的当前状态对象,包括状态枚举(TaskState)、附加消息和时间戳。它用于跟踪任务进度,支持序列化和格式转换,是任务处理的动态表示。
TaskStatus 依赖 TaskState。每个 TaskStatus 实例必须有一个 TaskState 作为其 state 字段。
TaskStatus 和 TaskState 结合使用:
from python_a2a import TaskState, TaskStatus
status_completed = TaskStatus(state=TaskState.COMPLETED, message={'info': '任务成功完成'})
status_failed = TaskStatus(state=TaskState.FAILED, message={'error': '无法处理请求'})
print('完成状态:', status_completed.to_dict())
print('失败状态:', status_failed.to_dict())完成状态: {'state': 'completed', 'timestamp': '2026-06-14T22:15:53.497944', 'message': {'info': '任务成功完成'}}
失败状态: {'state': 'failed', 'timestamp': '2026-06-14T22:15:53.497944', 'message': {'error': '无法处理请求'}}使用场景:
- SUBMITTED:任务刚创建,等待服务器处理。
- WAITING:任务依赖外部资源(如 API 调用)。
- INPUT_REQUIRED:需要用户提供更多信息(如出发地)。
- COMPLETED:任务成功结束,生成结果(如票务预订成功)。
- CANCELED:用户或系统取消任务。
- FAILED:任务因错误失败(如无效输入)。
- UNKNOWN:处理外部传入的无效状态。
关系:TaskState 是 TaskStatus 的实例化实参(或称为“构造函数参数”)。具体来说:
TaskStatus 类有一个必填参数 state: TaskState,即创建 TaskStatus 实例时,必须传入一个 TaskState 的枚举成员(例如 TaskState.COMPLETED)。
这是一种“组合”关系:TaskStatus “包含”一个 TaskState 实例,作为其核心组成部分。TaskState 定义了“状态的种类”,而 TaskStatus 则“包装”它,添加额外上下文(如错误消息或时间戳)。
在 Task 对象中,task.status 就是一个 TaskStatus 实例,其 task.status.state 指向 TaskState。
A2A Server
A2AServer是A2A协议的核心实现类,用于构建代理服务器。它继承自BaseA2AServer,支持处理任务(handle_task)、消息(handle_message)和路由设置(setup_routes)。它管理任务存储、流式订阅,并支持Google A2A兼容模式。它提供了Flask路由支持、任务处理逻辑和错误处理,确保代理间通信的可靠性。
在继承 A2AServer 的情况下,会有一个task,通常不需要手动创建 Task 对象,因为 A2AServer 的内置机制会自动处理传入的请求并将其解析为 Task 对象,传递给 handle_task 方法。
handle_task:handle_task用于解析任务输入、处理查询、封装结果并返回task任务对象。
Task:Task 是 A2A 协议中的核心工作单元,即任务,它是有生命周期的。由Client Agent创建,其状态由Server Agent维护。一个Task用于达到特定的目标或者结果。Agent Client和Server Client在Task中交换Mesaage,Server Agent生成的结果叫做Artifact。在Server Agent的 handle_task 方法中作为输入和输出载体,用于传递请求和响应。它的设计支持灵活的消息格式和状态管理,确保代理间的可靠通信。
from python_a2a import A2AServer, run_server, AgentCard, AgentSkill, TaskStatus, TaskState
ticket_card = AgentCard(
name="TicketAgentServer",
description="票务代理",
url="http://127.0.0.1:5009",
skills=[AgentSkill(name="book_ticket", description="预订票务")]
)
class TicketServer(A2AServer):
def __init__(self):
super().__init__(agent_card=ticket_card)
def handle_task(self, task):
print(f"[{self.agent_card.name}] 收到任务====: {task}")
task.status = TaskStatus(state=TaskState.COMPLETED)
print(f"[{self.agent_card.name}] 任务完成====: {task}")
return task
if __name__ == "__main__":
server = TicketServer()
print(f"[{server.agent_card.name}] 启动成功,服务地址: {server.agent_card.url}")
run_server(server, host="127.0.0.1", port=5009, debug=False)
服务器收到任务和完成任务:
[TicketAgentServer] 收到任务====: Task(id='76953f64-2e0c-458c-8176-0a4a980e1ae4', session_id='122ad1c5-f2dd-4662-a6ec-e5013a8e5a29', status=TaskStatus(state=<TaskState.SUBMITTED: 'submitted'>, message=None, timestamp='2026-06-15T00:58:55.271197'), message={'content': {'text': '我想预订从上海到北京的火车票', 'type': <ContentType.TEXT: 'text'>}, 'role': 'user', 'message_id': '6aaf325b-c93e-413f-82b5-af1c59387823'}, history=[], artifacts=[], metadata={})
[TicketAgentServer] 任务完成====: Task(id='76953f64-2e0c-458c-8176-0a4a980e1ae4', session_id='122ad1c5-f2dd-4662-a6ec-e5013a8e5a29', status=TaskStatus(state=<TaskState.COMPLETED: 'completed'>, message=None, timestamp='2026-06-15T00:58:55.271197'), message={'content': {'text': '我想预订从上海到北京的火车票', 'type': <ContentType.TEXT: 'text'>}, 'role': 'user', 'message_id': '6aaf325b-c93e-413f-82b5-af1c59387823'}, history=[], artifacts=[], metadata={})artifacts
artifacts 是 A2A 协议中 Task 对象的一个关键字段,用于存储任务的输出产物(结果)。它是一个列表,包含多个产物,每个产物是一个字典,通常包含 "parts" 键,指向一个内容部分的列表。artifacts 是任务处理结果的结构化容器,支持多种类型(如文本、函数响应、错误),确保客户端能够解析和使用代理的输出。
task.artifacts = [
{
"parts": [
{"type": "text", "text": "处理结果"},
{"type": "error", "message": "错误描述"},
{"type": "function_response", "name": "func_name", "response": {...}}
]
}
]parts:一个列表,包含具体的输出内容。
每个 part 是一个字典,包含:
- "type":内容类型(如 "text"、"error"、"function_response"、"function_call")。
- 具体键值:根据类型不同,例如 "text" 用于文本,"message" 用于错误,"name" 和 "response" 用于函数响应。
常见类型:
- text:纯文本结果,如用户查询的响应。
- error:错误信息,包含错误描述。
- function_response:函数调用结果,包含函数名和返回数据。
- function_call:发起的函数调用,包含函数名和参数。
from python_a2a import A2AServer, run_server, AgentCard, AgentSkill, TaskStatus, TaskState
ticket_card = AgentCard(
name="TicketAgentServer",
description="票务代理",
url="http://127.0.0.1:5010",
skills=[AgentSkill(name="book_ticket", description="预订票务")]
)
class TicketServer(A2AServer):
def __init__(self):
super().__init__(agent_card=ticket_card)
def handle_task(self, task):
query = (task.message or {}).get("content", {}).get("text", "")
print(f"[{self.agent_card.name} 日志] 收到 A2A 任务: '{query}'")
print("收到A2A任务的task:=>", task)
if "上海" in query and "北京" in query:
# 这里的结果可以来自于 MCP 模块,这里我们直接模拟结果
train_result = "上海到北京的火车票已经预订成功! G1001,10车1A "
else:
train_result = "请输入明确的出发地和目的地。"
print(f"[{self.agent_card.name} 日志] 返回结果: {train_result}")
task.artifacts = [{"parts": [{"type": "function_response", "name": "func_name", "response": {"add":"1+2"}},{"type": "text", "text": train_result},{"type": "text", "text": train_result}]}]
task.status = TaskStatus(state=TaskState.COMPLETED)
print(f"[{self.agent_card.name} 日志] 任务处理完毕")
print(f"[{self.agent_card.name} 日志] 输出结果task: {task}")
print(f"[{self.agent_card.name} 日志] 输出结果task.artifacts: {task.artifacts}")
return task
if __name__ == "__main__":
server = TicketServer()
print(f"[{server.agent_card.name}] 启动成功,服务地址: {server.agent_card.url}")
run_server(server, host="127.0.0.1", port=5010, debug=True)同步客户端:
import asyncio
from python_a2a import A2AClient, Task, Message, MessageRole, TextContent
import json
async def main():
# 初始化票务代理客户端(忽略天气客户端以简化测试)
ticket_client = A2AClient("http://127.0.0.1:5010")
print("[主控客户端日志] 初始化完成,准备开始任务...")
print("-" * 50)
# 任务:预订火车票
ticket_query = "预订一张从北京到上海的火车票"
print(f"[主控客户端日志] 任务:预订票务 -> '{ticket_query}'")
# 创建消息
message = Message(
content=TextContent(text=ticket_query),
role=MessageRole.USER
)
# 创建任务
task = Task(
id="task-123",
message=message.to_dict()
)
try:
# 使用 send_task 获取完整 Task 响应
ticket_result = await ticket_client.send_task_async(task)
print("[主控客户端日志] 收到票务预订完整结果:")
print(json.dumps(ticket_result.to_dict(), indent=4, ensure_ascii=False))
# 解析 artifacts 中的 parts
print("\n[主控客户端日志] 解析 artifacts 中的 parts:")
for artifact in ticket_result.artifacts:
if "parts" in artifact:
for part in artifact["parts"]:
part_type = part.get("type")
if part_type == "text":
print(f"Text 结果: {part.get('text')}")
elif part_type == "error":
print(f"Error 消息: {part.get('message')}")
elif part_type == "function_response":
print(f"Function Response: name={part.get('name')}, response={part.get('response')}")
else:
print(f"未知类型: {part}")
except Exception as e:
print(f"[主控客户端日志] 错误:{str(e)}")
print("-" * 50)
print("[主控客户端日志] 所有任务完成!")
if __name__ == "__main__":
print("请确保 ticket_agent.py 正在运行...")
asyncio.run(main())
""""
注意:
根本是 ask 方法只提取 "text" 类型的 part,
而 send_task_async 或 send_task 返回完整 Task,包括 artifacts。
"""异步客户端:
# courseware/a2a_demo/test_client.py
import asyncio
from python_a2a import A2AClient
async def main():
# 1. 初始化两个专家 Agent 的客户端
ticket_client = A2AClient("http://127.0.0.1:5010")
print("[主控客户端日志] 初始化完成,准备开始任务...")
print("-" * 50)
#预订火车票
ticket_query = "预订一张从北京到上海的火车票"
print(f"[主控客户端日志]预订票务 -> '{ticket_query}'")
ticket_result = ticket_client.ask(ticket_query)
print(f"[主控客户端日志] 收到票务预订结果: {ticket_result}")
print("-" * 50)
print("[主控客户端日志] 所有任务完成!")
if __name__ == "__main__":
print("请确保 agent_server在运行 正在运行...")
asyncio.run(main())Agent Network
AgentNetwork 是 A2A 协议中的代理网络管理类,定义在 network.py 中,用于集中管理和发现 A2A 兼容代理。它维护一个代理列表,支持通过 URL 或客户端实例添加代理,并缓存代理的元数据(如 AgentCard)。 作用:
- 简化多代理协作,提供代理添加、get_agent、list_agents 和 discover_agents 等方法,支持代理发现和移除。适用于构建分布式代理系统,避免手动管理多个客户端。
核心特性:
- 添加代理:通过 add 方法,支持 URL(自动创建 A2AClient)或现有客户端。
- 代理元数据:自动缓存 AgentCard,便于查询代理能力。
- 发现代理:通过 discover_agents 从 URL 列表自动发现代理。
from python_a2a import AgentNetwork
network = AgentNetwork(name="MyNetwork")
network.add("TicketAgent", "http://127.0.0.1:5010")
client = network.get_agent("TicketAgent")
print(client.ask("预订一张从北京到上海的火车票"))
print("agent network=============")
print(network.agent_cards)AIAgentRouter
AIAgentRouter 是使用 LLM 智能路由查询到合适代理的类,定义在 router.py 中。它分析查询意图和上下文,选择最佳代理。 在多代理网络中,路由用户查询到最匹配的代理,支持语义分析、历史上下文和缓存。响应格式为代理名称和置信度,避免手动选择代理。 核心特性:
- LLM 驱动:使用 LLM 客户端(如 ChatOpenAI)生成路由提示,分析查询匹配代理描述和技能。
- 上下文支持:包含对话历史(max_history_tokens 限制令牌数)。
- 缓存优化:类似查询使用缓存减少 LLM 调用。
- 回退机制:LLM 失败时,使用关键词匹配回退路由。
- 系统提示:自定义提示指导路由决策。
from python_a2a import AIAgentRouter, AgentNetwork
from langchain_openai import ChatOpenAI
from config import Config
conf = Config()
from python_a2a import AgentNetwork
network = AgentNetwork(name='MyNetwork')
network.add('TicketAgent', 'http://127.0.0.1:5010')
llm = ChatOpenAI(model=conf.model_name, base_url=conf.api_url, api_key=conf.api_key, temperature=0)
router = AIAgentRouter(llm_client=llm, agent_network=network)
agent_name, confidence = router.route_query('预订票')
print(agent_name, confidence)