
外观
Milvus 向量数据库
Milvus 是一款开源的向量数据库(2019年提出),其唯一目标是存储、索引和管理由深度神经网络和其他机器学习 (ML)模型生成的大规模嵌入向量。
作为一个专门设计用于处理输入向量查询的数据库,它能够处理万亿级别的向量索引。与现有的关系型数据库主要处 理遵循预定义模式的结构化数据不同,Milvus 从底层设计用于处理从非结构化数据转换而来的嵌入向量。
随着互联网的发展和演变,非结构化数据变得越来越常见,包括电子邮件、论文、物联网传感器数据、Facebook 照 片、蛋白质结构等等。为了使计算机能够理解和处理非结构化数据,使用嵌入技术将它们转换为向量。Milvus 存储 和索引这些向量。Milvus 能够通过计算它们的相似距离来分析两个向量之间的相关性。如果两个嵌入向量非常相 似,则意味着原始数据源也很相似。
有关概念
非结构化数据:非结构化数据包括图像、视频、音频和自然语言等信息,这些信息不遵循预定义的模型或组织方式。这种数据类型占据了世界数据的约 80%,可以使用各种人工智能(AI)和机器学习(ML)模型将其转换为向量。
嵌入向量:嵌入向量是对非结构化数据(如电子邮件、物联网传感器数据、Instagram 照片、蛋白质结构等)的特征抽象。数学上,嵌入向量是一个浮点数或二进制数的数组。现代的嵌入技术被用于将非结构化数据转换为嵌入向量。
向量相似度搜索:向量相似度搜索是将向量与数据库进行比较,以找到与查询向量最相似的向量的过程。使用近似最近邻搜索算法加速搜索过程。如果两个嵌入向量非常相似,那么原始数据源也是相似的。
Collection 和 Field:与传统数据库引擎类似,您也可以在 Milvus 中创建数据库,并为某些用户分配权限来管理它们。那么这些用户就有权管理数据库中的集合。一个 Milvus 集群最多支持 64 个数据库。
在关系数据库中,表和字段的结构可以与Milvus中的Collection和Field进行对应:
| Milvus | 关系数据库 | 描述 |
|---|---|---|
| Collection | 表 | 集合相当于关系数据库中1代表,用于组织数据 |
| Field | 字段 | 字段Schema相当于表中的列 |
| is_primary | 主键 | 主键字段,用于唯一标识每个向量 |
| dtype | 数据类型 | 字段的数据类型,如浮点数、整数、二进制等 |
| max_length | 最大长度 | 字段的最大长度,仅对字符串类型有效 |
| dim | - | 向量字段的维度没有直接对应,但可以视为特殊数据处理 |
注意:1个collection最多支持4个向量Field。
Field Schema
Field schema 是字段的逻辑定义。我们在定义集合架构和管理集合之前需要定义的第一件事就是定义 Field schema。
Milvus 集合仅支持一个主键。
| 属性 | 描述 | 备注 |
|---|---|---|
| name | 要创建关键的集合中的字段名称 | String,必填 |
| dtype | 字段的数据类型 | 必填 |
| description | 字段描述 | String,选填 |
| is_primary | 是否为主键字段 | Boolean(true 或者 false),主键字段必填 |
| auto_id(主键字段必填) | 切换以启用或禁用自动 ID(主键)分配 | True或False |
| max_length(VARCHAR字段必需) | 允许插入的字符串的最大长度 | [1, 65535] |
| dim | 向量的维数 | ∈[1,32768] |
| is_partition_key | 该字段是否区分区键字段 | Boolean(true 或者 false) |
Collection Schema
collection schema 是 collection 的逻辑定义。我们需要在定义 collection schema 之前定义。
| 属性 | 描述 | 备注 |
|---|---|---|
| field | 集合中要创建的字段 | 必填 |
| description | 集合描述 | String,选填 |
| partition_key_field | 设计用作分区键的字段的名称 | String,选填 |
| enable_dynamic_field | 是否启用动态字段 | Boolean(true 或者 false) |
Milvus 的特点
- 在处理大规模数据集的向量搜索时具有高性能。
- 开发者优先的社区,提供多语言支持和工具链。
- 云扩展性和高可靠性,即使出现故障也不会受到影响。
- 通过将标量过滤与向量相似度搜索配对,实现混合搜索。
支持的索引和度量
索引是数据的组织单位。在搜索或查询插入的实体之前,必须声明索引类型和相似度度量。如果您未指定索引类型, 则 Milvus 将默认使用暴力搜索。
索引类型
大多数由 Milvus 支持的向量索引类型使用近似最近邻搜索(ANNS),包括:
FLAT
FLAT最适合在小型、百万级数据集上寻求完全准确和精确搜索结果的场景。
这是最简单的索引方式,进行暴力搜索(brute-force),可以保证精确度,但效率低,尤其在数据量大时。
适合场景:在小型、百万级数据集上寻求完全精确的搜索结果。
IVF_FLAT
IVF_FLAT 是一种基于倒排的索引方法,广泛用于在大规模数据集上实现高效的近似最近邻搜索。它适用于在 精度和查询速度之间寻求平衡的场景。
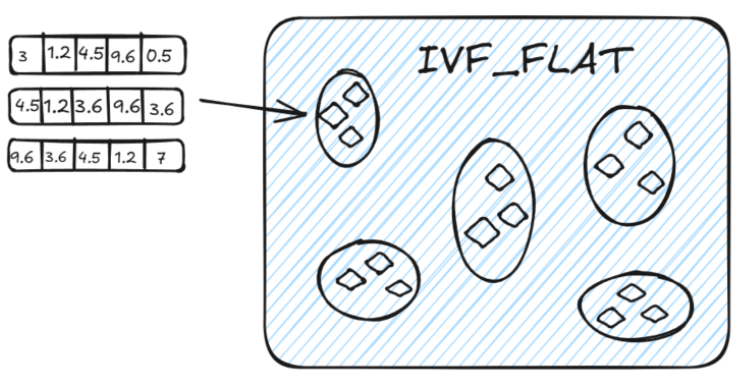
步骤:
- 聚类:IVF_FLAT通过聚类算法(如k-means)将高维空间中的向量划分为多个子空间(簇)。每个簇包 含一组相似的向量,并且每个簇会有一个代表向量,通常是簇的中心点。
- 倒排索引:为每个簇创建倒排索引。每个向量会被映射到它所属的簇,这样在查询时,系统只需关注与查询向量相似的簇,而不需要搜索整个高维空间,从而显著降低搜索的时间复杂度。
- 查询处理:
- 查询时,IVF_FLAT首先将查询向量分配到距离最近的簇中心(即子空间)。
- 然后在该簇内执行精确的线性搜索,从而查找与查询向量相似的向量。
- 为了优化查询,IVF_FLAT使用一个参数 nprobe 来控制搜索的簇数。nprobe 控制搜索时考虑的簇的数量,从而平衡查询精度和查询速度。
- 增大 nprobe 可以搜索更多簇,返回更多候选向量,提高结果的精确度,但查询时间也会增加。减少 nprobe 可以缩小搜索范围,降低计算时间,查询速度更快,但可能会牺牲一些精度
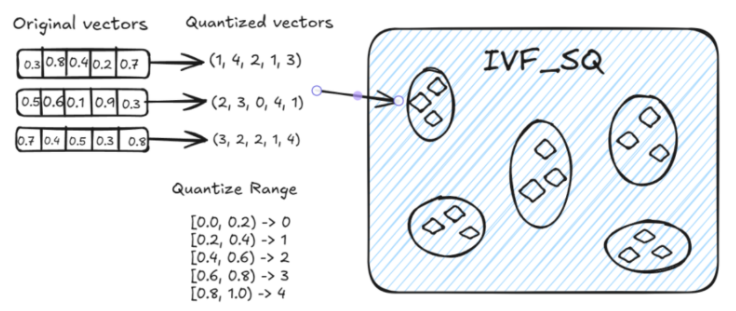
IVF_SQ8
IVF_SQ8是在 IVF_FLAT 基础上增加了量化步骤的一种索引方法,其核心思想与 IVF_FLAT 类似;IVF_SQ8通过标量量化 (Scalar Quantization)将每个维度的 4 字节浮点数表示压缩为 1 字节整数表示。
IVF_PQ
IVF_PQ是一种高效的向量索引方式,结合了倒排文件索引和乘积量化(Product Quantization)技术,旨在 加速大规模高维数据集的检索。
- 倒排文件索引:IVF_PQ首先将数据集划分为多个簇,每个簇由一个聚类中心表示。查询时,系统首先计算查询向量与这些聚类中心的距离,选择最接近的几个簇进行详细搜索,从而减少计算量。
- 乘积量化:在每个簇内,向量被进一步量化为多个子向量,这些子向量通过独立的量化过程进行编码。这样可以显著降低存储需求,并加快相似度计算。
- 存储与速度:IVF_PQ通过减少存储空间的占用,同时保持较高的查询速度和准确性,适用于处理大规模高维向量数据。
HNSW
HNSW:HNSW是基于图的索引,最适合对搜索效率有高要求的场景。
相似度度量
在 Milvus 中,相似度度量用于衡量向量之间的相似性。选择一个好的距离度量方法可以显著提高分类和聚类的性能。根据输入数据的形式,选择特定的相似度度量方法可以获得最优的性能。
对于浮点嵌入,通常使用以下指标:
- 欧几里得距离(L2)
- 内积(IP)
- 余弦相似度 (COSINE)
Milvus 数据库操作
这里我使用Milvus Lite演示,它是 pymilvus 中包含的一个 python 库,可以嵌入到客户端应用程序中。Milvus 还支持在Docker和Kubernetes上部署,适用于生产用例。
开始之前,请确保本地环境中有 Python 3.8+ 可用。安装 pymilvus 库,其中包含 python 客户端库和 Milvus Lite。
pip install pymilvus设置向量数据库
要创建本地的 Milvus 向量数据库,只需实例化一个MilvusClient,指定一个存储所有数据的文件名,如"milvus_demo.db"。
from pymilvus import MilvusClient, DataType
# 创建本地数据库
client = MilvusClient(uri="milvus_demo.db")
# 如果已存在则删除
if client.has_collection("demo"):
client.drop_collection("demo")
# 创建 Schema
schema = client.create_schema(auto_id=False, enable_dynamic_field=True)
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=5)
schema.add_field(field_name="scalar", datatype=DataType.VARCHAR, max_length=256)
# 创建集合
client.create_collection(collection_name="demo", schema=schema)
# 创建索引参数
index_params = client.prepare_index_params()
# 向量索引
index_params.add_index(field_name="vector", index_name="vector_index", index_type="AUTOINDEX", metric_type="COSINE")
# 创建索引
client.create_index(collection_name="demo", index_params=index_params)
# 查看索引
print("所有索引:")
print(client.list_indexes("demo"))
print("\n索引详情:")
print(client.describe_index(collection_name="demo", index_name="vector_index"))Collection 操作
在 Milvus 中,我们需要一个 Collections 来存储向量及其相关元数据。你可以把它想象成传统 SQL 数据库中的表格。创建 Collections 时,可以定义 Schema 和索引参数来配置向量规格,如维度、索引类型和远距离度量。此外,还有一些复杂的概念来优化索引以提高向量搜索性能。
| 操作类型 | 含义 | API | 示例 | 是否原地修改 | 说明 |
|---|---|---|---|---|---|
| 增(Insert) | 新增向量数据 | client.insert() | insert(data) | ❌ | 追加写入,不影响已有数据 |
| 增(分区插入) | 插入到指定 partition | client.insert(..., partition_name="p1") | insert(partition_name="p1") | ❌ | 逻辑隔离存储 |
| 删(Delete) | 条件删除数据 | client.delete() | filter="id in [1,2]" | ✔(逻辑删除) | 标记删除,非物理删除 |
| 改(Upsert) | 更新或插入 | client.upsert() | upsert(data) | ✔(逻辑覆盖) | 存在则覆盖,不存在则新增 |
| 查(Query) | 条件查询标量 | client.query() | filter="color=='red'" | - | 只查结构化字段 |
| 检索(Search) | 向量相似度搜索 | client.search() | data=[[...]] | - | ANN 最近邻搜索 |
import shutil
try:
shutil.rmtree("milvus_demo.db")
except:
pass
from pymilvus import MilvusClient, DataType
# 创建本地数据库
client = MilvusClient(uri="milvus_demo.db")
# 创建 Schema
schema = client.create_schema(auto_id=False, enable_dynamic_field=True)
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=5)
schema.add_field(field_name="scalar", datatype=DataType.VARCHAR, max_length=256)
# 创建集合
client.create_collection(collection_name="demo", schema=schema)
data = [
{"id": 1, "vector": [1.0, 2.0, 3.0, 4.0, 5.0], "scalar": "a", "color": "red"},
{"id": 2, "vector": [6.0, 7.0, 8.0, 9.0, 10.0], "scalar": "b", "color": "green"},
{"id": 3, "vector": [11.0, 12.0, 13.0, 14.0, 15.0], "scalar": "c", "color": "blue"},
{"id": 4, "vector": [16.0, 17.0, 18.0, 19.0, 20.0], "scalar": "d", "color": "yellow"},
{"id": 5, "vector": [21.0, 22.0, 23.0, 24.0, 25.0], "scalar": "e", "color": "orange"},
]
# 插入数据
res = client.insert(collection_name="demo", data=data)
print(res)
# 将数据插入到指定分区
data = [
{"id": 6, "vector": [21.0, 22.0, 23.0, 24.0, 25.0], "scalar": "f", "color": "orange"},
{"id": 7, "vector": [26.0, 27.0, 28.0, 29.0, 30.0], "scalar": "g", "color": "red"},
{"id": 8, "vector": [31.0, 32.0, 33.0, 34.0, 35.0], "scalar": "h", "color": "green"},
{"id": 9, "vector": [36.0, 37.0, 38.0, 39.0, 40.0], "scalar": "i", "color": "blue"},
{"id": 10, "vector": [41.0, 42.0, 43.0, 44.0, 45.0], "scalar": "j", "color": "yellow"},
]
# 创建分区
client.create_partition(collection_name="demo", partition_name="p1")
# client.create_partition(collection_name="demo", partition_name="p2")
# 插入数据
res = client.insert(collection_name="demo", data=data, partition_name="p1")
print(res)
# 更新插入数据
data = [{"id": 1, "vector": [-1.0, -2.0, -3.0, -4.0, -5.0], "scalar": "hello"}]
res = client.upsert(collection_name="demo", data=data)
print(res)
# 删除数据
res = client.delete(collection_name="demo", filter="id in [1, 2]")
print(res)Collection 查询
| 功能类型 | API 用法 | 核心参数 | 作用 | 示例特点 |
|---|---|---|---|---|
| 单向量检索 | search() | data=[[...]] | 单条 query 向量搜索 | 找最相似 TopK |
| 多向量检索 | search() | data=[[...],[...]] | 批量 query 搜索 | 一次查多条 |
| 相似度计算方式 | search_params={"metric_type": "COSINE"} | COSINE / IP / L2 | 决定相似度规则 | COSINE = 角度相似 |
| 返回字段控制 | output_fields=["id","scalar"] | output_fields | 返回附加 metadata | 类似 SQL select |
| 分区检索 | partition_names=["p1"](注意你代码写错参数名) | partition_names | 只在指定 partition 搜索 | 提升效率 |
| 条件过滤搜索 | filter="id in [2,3,4]" | filter | 标量过滤 + 向量搜索结合 | 类 SQL WHERE |
| metric_type | 含义 | 使用场景 |
|---|---|---|
| COSINE | 余弦相似度(角度) | NLP embedding(推荐) |
| IP | 内积(dot product) | 推荐系统 / embedding |
| L2 | 欧式距离 | 数值型向量 |
import shutil
try:
shutil.rmtree("milvus_demo.db")
except:
pass
from pymilvus import MilvusClient, DataType
# 创建本地数据库
client = MilvusClient(uri="milvus_demo.db")
# 创建 Schema
schema = client.create_schema(auto_id=False, enable_dynamic_field=True)
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=5)
schema.add_field(field_name="scalar", datatype=DataType.VARCHAR, max_length=256)
# 创建集合
client.create_collection(collection_name="demo", schema=schema)
data = [
{"id": 1, "vector": [1.0, 2.0, 3.0, 4.0, 5.0], "scalar": "a", "color": "red"},
{"id": 2, "vector": [6.0, 7.0, 8.0, 9.0, 10.0], "scalar": "b", "color": "green"},
{"id": 3, "vector": [11.0, 12.0, 13.0, 14.0, 15.0], "scalar": "c", "color": "blue"},
{"id": 4, "vector": [16.0, 17.0, 18.0, 19.0, 20.0], "scalar": "d", "color": "yellow"},
{"id": 5, "vector": [21.0, 22.0, 23.0, 24.0, 25.0], "scalar": "e", "color": "orange"},
]
# 插入数据
res = client.insert(collection_name="demo", data=data)
print(res)
# 将数据插入到指定分区
data = [
{"id": 6, "vector": [21.0, 22.0, 23.0, 24.0, 25.0], "scalar": "f", "color": "orange"},
{"id": 7, "vector": [26.0, 27.0, 28.0, 29.0, 30.0], "scalar": "g", "color": "red"},
{"id": 8, "vector": [31.0, 32.0, 33.0, 34.0, 35.0], "scalar": "h", "color": "green"},
{"id": 9, "vector": [36.0, 37.0, 38.0, 39.0, 40.0], "scalar": "i", "color": "blue"},
{"id": 10, "vector": [41.0, 42.0, 43.0, 44.0, 45.0], "scalar": "j", "color": "yellow"},
]
# 创建分区
client.create_partition(collection_name="demo", partition_name="p1")
# client.create_partition(collection_name="demo", partition_name="p2")
# 插入数据
res = client.insert(collection_name="demo", data=data, partition_name="p1")
print(res)
# 查询数据 - 单向量查询
res = client.search(collection_name="demo", data=[[1.0, 2.0, 3.0, 4.0, 6.0]], limit=2, search_params={"metric_type": "COSINE"}, output_fields=["id", "scalar", "color"])
print(res)
# 查询数据 - 多向量查询
res = client.search(collection_name="demo", data=[[1.0, 2.0, 3.0, 4.0, 6.0], [2.0, 3.0, 4.0, 5.0, 7.0]], limit=2, search_params={"metric_type": "COSINE"}, output_fields=["id", "scalar", "color"])
print(res)
# 查询数据 - 分区搜索
res = client.search(collection_name="demo", data=[[21.0, 22.0, 23.0, 24.0, 25.0]], limit=2, search_params={"metric_type": "COSINE"}, output_fields=["id", "scalar", "color"], partition_name="p1")
print(res)
# 查询数据 - 过滤搜索
res = client.search(collection_name="demo", data=[[1.0, 2.0, 3.0, 4.0, 6.0]], limit=2, search_params={"metric_type": "COSINE"}, output_fields=["id", "scalar", "color"], filter="id in [2,3,4,5]")
print(res)复杂查询
混合检索:要对两组 ANN 搜索结果进行合并和重新排序,有必要选择适当的重新排序策略。支持两种重排策略:加权排名策略(WeightedRanker)和重 排序策略(RRFRanker)。在选择重排策略时,需要考虑的一个问题是,在向量场中是否需要强调一个或多个基本 ANN 搜索。
加权排名:如果您要求结果强调特定的向量场,建议使用该策略。通过 WeightedRanker,您可以为某些向量场分配更高的权重,从而更加强调这些向量场。例如,在多模态搜索中,图片的文字描述可能比图片的颜色更重要。
使用 WeightedRanker 策略时,需要在WeightedRanker 函数中输入权重值。混合搜索中的基本 ANN 搜索次数与需要输入的值的次数相对应。输入值的范围应为 [0,1],数值越接近 1 表示重要性越高。
from pymilvus import WeightedRanker
rerank = WeightedRanker(0.8, 0.3)代码:
import random
from pymilvus import (
MilvusClient,
DataType,
AnnSearchRequest,
RRFRanker
)
# =========================================================
# 1. 连接本地 Milvus Lite(会生成 db 文件)
# =========================================================
client = MilvusClient(uri="milvus_demo.db")
# =========================================================
# 2. 创建 Schema(定义数据结构)
# =========================================================
schema = client.create_schema(enable_dynamic_field=False)
# 主键字段
schema.add_field(
field_name="film_id",
datatype=DataType.INT64,
is_primary=True
)
# 第一组向量(语义向量 / 文本向量)
schema.add_field(
field_name="filmVector",
datatype=DataType.FLOAT_VECTOR,
dim=5
)
# 第二组向量(图像 / poster 向量)
schema.add_field(
field_name="posterVector",
datatype=DataType.FLOAT_VECTOR,
dim=5
)
# =========================================================
# 3. 创建索引(每个向量字段独立索引)
# =========================================================
index_params = client.prepare_index_params()
# filmVector 使用 L2 距离
index_params.add_index(
field_name="filmVector",
index_type="IVF_FLAT",
metric_type="L2",
params={"nlist": 128}
)
# posterVector 使用 COSINE 相似度
index_params.add_index(
field_name="posterVector",
index_type="IVF_FLAT",
metric_type="COSINE"
)
# =========================================================
# 4. 创建 Collection
# =========================================================
client.create_collection(
collection_name="demo_v3",
schema=schema,
index_params=index_params
)
# =========================================================
# 5. 插入数据(模拟 1000 条数据)
# =========================================================
entities = []
for _ in range(1000):
entities.append({
"film_id": random.randint(1, 100000),
"filmVector": [random.random() for _ in range(5)],
"posterVector": [random.random() for _ in range(5)]
})
client.insert(
collection_name="demo_v3",
data=entities
)
# =========================================================
# 6. 创建分区(Partition)
# =========================================================
client.create_partition(
collection_name="demo_v3",
partition_name="p1"
)
# 插入部分数据到 p1
partition_data = [
{
"film_id": 100001,
"filmVector": [0.1, 0.2, 0.3, 0.4, 0.5],
"posterVector": [0.5, 0.4, 0.3, 0.2, 0.1]
}
]
client.insert(
collection_name="demo_v3",
data=partition_data,
partition_name="p1"
)
# =========================================================
# 7. 单向量搜索(基础 search)
# =========================================================
res = client.search(
collection_name="demo_v3",
data=[[0.1, 0.2, 0.3, 0.4, 0.5]],
limit=3,
search_params={"metric_type": "COSINE"},
output_fields=["film_id"]
)
print("单向量搜索结果:")
print(res)
# =========================================================
# 8. 多向量搜索(批量 query)
# =========================================================
res = client.search(
collection_name="demo_v3",
data=[
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1]
],
limit=3,
search_params={"metric_type": "COSINE"},
output_fields=["film_id"]
)
print("多向量搜索结果:")
print(res)
# =========================================================
# 9. 分区搜索(只搜索 p1)
# =========================================================
res = client.search(
collection_name="demo_v3",
data=[[0.1, 0.2, 0.3, 0.4, 0.5]],
limit=3,
search_params={"metric_type": "COSINE"},
partition_names=["p1"],
output_fields=["film_id"]
)
print("分区搜索结果:")
print(res)
# =========================================================
# 10. 过滤搜索(SQL-like filter)
# =========================================================
res = client.search(
collection_name="demo_v3",
data=[[0.1, 0.2, 0.3, 0.4, 0.5]],
limit=3,
search_params={"metric_type": "COSINE"},
filter="film_id in [1, 2, 3, 4, 5]",
output_fields=["film_id"]
)
print("过滤搜索结果:")
print(res)
# =========================================================
# 11. Hybrid Search(多向量融合检索)
# =========================================================
# --- 第一个向量检索请求(filmVector) ---
req1 = AnnSearchRequest(
data=[[0.9, 0.3, 0.2, 0.4, 0.5]],
anns_field="filmVector",
param={"metric_type": "L2", "nprobe": 10},
limit=3
)
# --- 第二个向量检索请求(posterVector) ---
req2 = AnnSearchRequest(
data=[[0.2, 0.1, 0.7, 0.6, 0.5]],
anns_field="posterVector",
param={"metric_type": "COSINE"},
limit=3
)
# RRFRanker:融合排序策略
ranker = RRFRanker(100)
res = client.hybrid_search(
collection_name="demo_v3",
reqs=[req1, req2],
ranker=ranker,
limit=5
)
print("Hybrid Search 结果:")
for hits in res:
for hit in hits:
print(hit)
# =========================================================
# 12. 加载已有数据(Milvus Lite 特性)
# =========================================================
client = MilvusClient("milvus_demo.db")
# =========================================================
# 13. 删除 Collection
# =========================================================
# client.drop_collection("demo_v3")